Sida golden mosaic Florida virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000888515.1 |
| Isolate |
Cuba: Havana |
| Release date |
2015/2/22 |
| Submitter |
Fiallo-Olive,E., Martinez-Zubiaur,Y., Moriones,E., Navas-Castillo,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
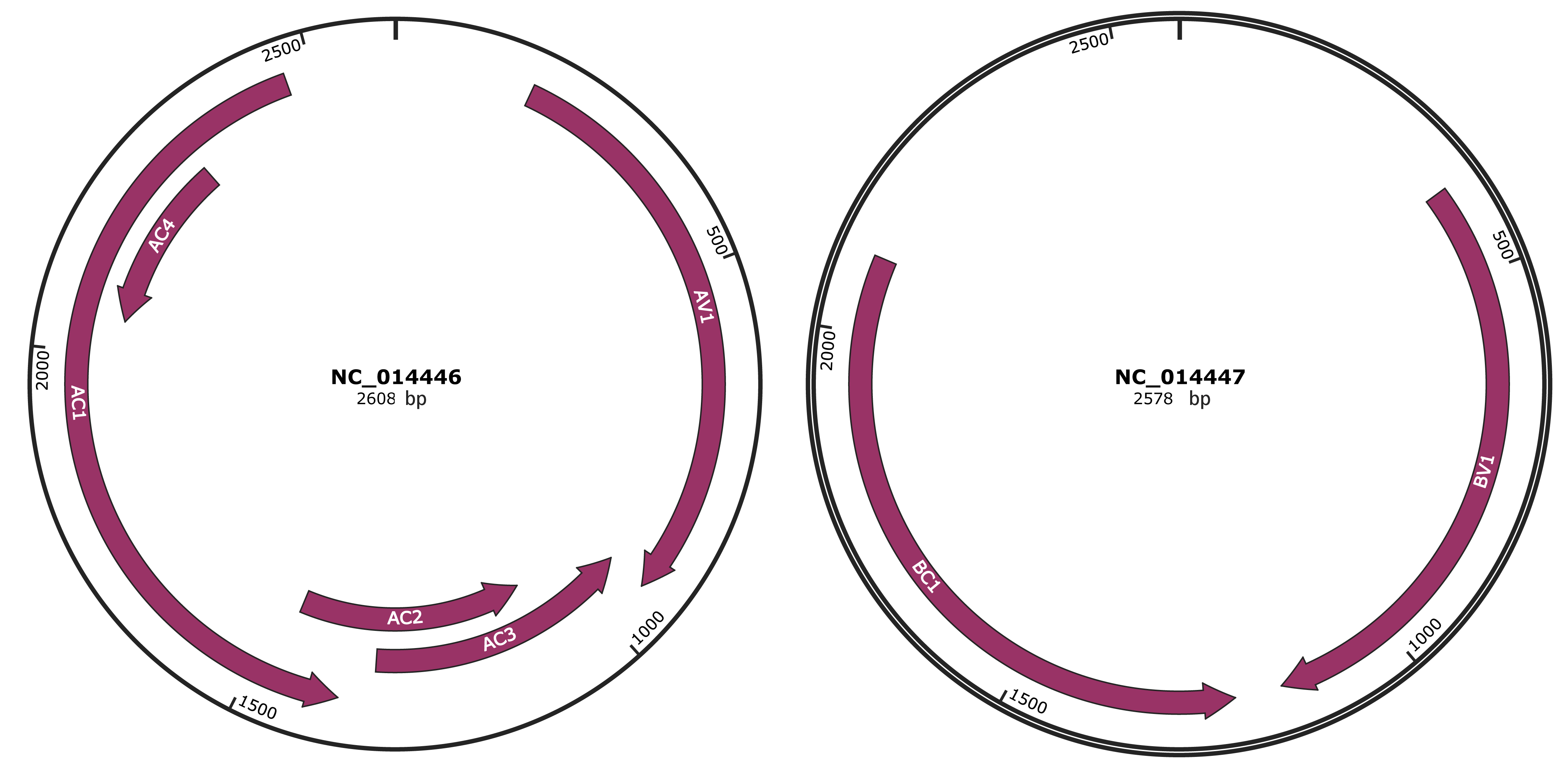
JBrowse
Genome
ACCGGATGGCCGCGCTTTGGTGCCCGCTCCCCTGCGCTTTAATTTGAATTAAAGCTTGCCGCTTTTCCTTTGTCCAATGATATTGCGCCTGGCGAGCCTAAATAATTCAAACAACTTGGGCTCTAAGTTGTTTTGGGCCTATTAAAGGAAAAGCTTGTTGGGCCACCCATAACAGTCCATTATGTCTAAGCGCGATGGTTCCTGGCGCTCTATCGCGGGAATGTCAAAAGTGAAACGCACTATGAATTTCTCTCCTCGTGGAGGTGGTGGCCCAAAAATGACAAGGGCCGCTGAATGGGTTAACAGGCCTATGTACAGGAAGCCTAGGATTTATCGGACTCTGAGGACGCCTGATATTCCGAGAGGCTGTGAAGGCCCTTGCAAGGTGCAGTCTTATGAACAACGGCATGATATCTCACATGTCGGGAAGGTCATGTGTATTTCAGATGTGACACGTGGTAACGGCATTACTCATCGTGTTGGTAAGCGATTCTGTGTTAAGTCTGTGTATATTTTAGGTAAGGTATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTCGACCGTATGGCACTCCGATGGATTTCGGTCAGGTGTTCAACATGTTCGATAACGAGCCTAGCACTGCGACTGTGAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAGCAAGCTCTCGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCACCAGGAAGCTGGCAAGTACGAGAATCATACGGAGAATGCGTTACTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAACATTTATATTTTATTATATGATTCTCAAGCACATAATTTACATATGGTTTGGCTGTTGCAAATCTAACAGCTCTAATTACATTGTTTATCCCAATTACACCTAATTGGTACAAGTACATGTTAACTAAATGTCTAAATCTAGCTAAATAAGTTAACCCAGAAACTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGACCCAACGCTTTCCTCAGGTTGTGGTTGAATCTTATCTGTATGTGGTACACTCTGGTTCTGGTGTATAGCTGGTCCTCTGCGCTGTATATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGACGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGCCCGTGCAGCCGATGTGGAAGTAAATGGAGCACCCGCAATCTAGATCAATCCTGCGTCTCCTGATTGCCCGCCTCTTGGCTTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAATATGGCATTCTTGTTGGTCCAATTCTTTAGACCTGTGTTTTCCTCTTTGGCTAGGAAATCTTTATAGCTAGCACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATCCCGCCTTTAATTTGAACTGGCTTGCCGTACTTGCAATTTGATTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAACTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACGTCATTTGAAAATACTCGAGGGTTGAAGTCCAGATGTCCACTAAGATAATTATGTGGGCCTAACGAACGAGCCCACATCGTCTTCCCTGTCCTCGAGTCACCTTCTACTATGATACTCATAGGTCTCTCCGGCCGCGCAGCGGCACCTCTTCCAAAATTCTCATCGGCCCATTCTTGCATCTCGTCGGGAACGGCTGTGAAAGAAGAGAGGGGAAACGGAGGAGCCCATGGCTCAGGAGCCTTACTGAAAATCCGATGAGCATTGGCAACCAGATTGTGATGCTGAAGAAAGAAATGTTGAGGCTGTTCCTCCTTGATTATTTGCAGAGCCTCTTCTGCAGAAGAGGCATTCAACGCCTTGGCATATGTATCGTTAACCGATTGGCAGCCTCCTCTAGCACTTCTCCCGTCGATCTGGAATTCACCCCATTCCAGTGTGTCTCCGTCCTTGTTGATGTAGGACTTGACATCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAATGGGACTGACATGGATGGTGAGACCAGGTCGAAGAATCTGTAATTCGTGCATGCATATTTCCCCTCGAATTGTATAAGCACGTGGAGATGAGGCTTCCCATTCTGATGGAACTCTCTGCAGATCTTGATGAACTTCTTGTTCACAGGAGTGGACAGGTTTTGTAATTGAGAAAGTGCTTCTTCTTTGCTCAGGGAGCAGTCGGGATATGTGATGAAATAGTTTTTGGCATTTATTTTAAAACGTTTAACTGATGGCATTTTTGTAATAATGAGAGTGTTCCCCAATTGAGACTCTCTCAAACTTTCTCATACAATTGGGGAATGGGGAACAATATATACTAGAACCCTCAATAGAACTTTGGATCTCGTTCACACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCTTTGGTGCCCGCTCCCTCTCACGCGCGCTCCCCTGGTGTGGTGCTGCCACTCGCCCTCTTATTGGTGGTTGTCCTTCACGCCCCGTCTTTTTGACTGGCCTTTAATTCAAATTAAAGGATAATGCTTTCTCGCGCGATTTGCTTTTATTTTTTGAATTATTGTCGCGCGACGACTGAGTATGGCCCATTGTGTCAGGTGAAGGACGTGGCTAAATTTTGACCATGCTGCTGGGTCTATTTGCGTCTAAATGTAAACGAATTATTTATATAAATAATTTTTCAAGTATGTCATGTTTAGCCTACTCAGATTCTAACCACGTTTATATTGTTGGCTGTAATTGTGTTTAATCTGCCTTTTATCATTTGATAATGTATCCTTTTAGAAGTAAACGTGGTTATTGCTTTAGTCATCGACGATCTACCACACGTAACTTTTTGTTTAACCGTTCAACCTCAATTAAGAGACATGATGGGAAACGTCGAGGAGGTCGATTTGTAAAGCCCATTGATGAACCCAAAATGTCAGCCCAATCCATACATGAAAATCAGTATGGGCCTGATTTTGTTATGGCCCAAAATTCGGCTATATCTACGTTTATCAGTTACCCAGACATGGGCAAGGTAGAACCTAGTCGAAGCAGATCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTGAATATCAAACGTGTTCAATCGGATGTGAACATGGATGGGTCTATCTCCAAAGTGGAAGGAGTGTTCTCTCTTATTATTGTTGTAGATCGGAAACCTCACTTGGGTCCTAGTGGTTGTCTGCATACATTCGACGAGCTGTTCGGAGCAATGATTCACAGTCATGGCAATCTCAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCATGTGTTCAAACGTGTACTGTCCGTTGATAACGAGACGCTGATAGTAGACGTGGAAGGATCCACTACCCTATCTAATAGGCGTTTTAATATTTGGTCCAGTTTCAAGGACGTTGATCGTGATTCATGCAAGGGTGTTTATGATAACATAAGCAAGAACGCCCTTTTAATTTATTATTGCTGGATGTCAGATATGCCTTCAAAGGCCTCCACTTATGTATCTTTTGATCTTGACTATGTTGGTTAAATCAATAAAATTTGTTTATCCAAATTTGTTTAGCTGTTTATGATATAGCAAAAGATAACATTTATTTCAACGACTTGGCCTGAGAAGCCTGACAATTATTATTAATACATTCTTGGACTGTTGTCCTAACTAACTCGTTCAACTGGCCCAAAGACATTGTAATGTTGGATTCCGCTCTCTGGGCTCCCACTATTGAAGCAGACTCTCCTGGGTCCAGAACGCTGGTTCCAAGCCTGCTCAGATGTCTGTATGGGTGGAGTCCGTTTTCTATTTCCGAGTCCACATCTGATTGGGCCGTTCCTATCGTACTTCTGGAAGCCCATGATTCTCCAGGCCCAAGCTCAATTGGACATTTAGACCCAATTCTAGACATCGATGCACATCTTATGGGCTTCCTCTCCCATTTCCCATAGTCCACATGCGAAAAGTCTACATCTTTGTCTGTGAACTGTTTTGACAGTATTTTGACCGTCGGTGCCCGGAAGGGGATATCTACTGAGTGTTTCGCTGTGGACAATTTCAGCTTCCCTTTAAACTTGGCGAAGTGGGTTCGCTGGTGAACATTGGTATCTGAAACTCTGTAATAGAGTTTCCATGGAATCGGGTCTTTGAGAGAGAAGAATGAAGCTGAAAAATAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCACGACGCCTGCAAAGACTCATTGTCTGTCATCCTCTTGTCATGGATCTCCACAATTACCGTCCCAGTTGCGTTAATTGGAACCTGTTGCCTGTACTCTATGACACAATGATCTATCTTCATGCAGCTACGGCTGAGTCTTGCCGTCAACTGGGACGCCGTCGATGGAAATTGCAAGATTATCTCAGTTAGGTCATGGCAGAGCTGATATTCGTCTCTGTGAGACTCTATGTAATTGAAGGCGCTTGGAGGATATGCTAACTGAGAATTCATCTGAAAAATAAAGGCCGCGCAGCGGCTTTGCAGGTTGAATATGAAATGAGTACTAAAAACCTAGGGTTTTTGAATATGAACAACTTATGAACTCCGCGTGTACTTGTATGAATTTTCTGTGAAACCTAGTGATATAAATGAGGAATTGGAGGATAATCGCTTAAGTTTTCCAGAAAATTAAGAACAGTCGTTATACCTTTCCAGAAATTGAAAGCTTTTTGAAAAATGGGAGAAATATGAAGTGTAAATAATTATGGGAAATATGTTAGATGTGAAAGAGTTTATATAGACATTCTCTTTTTTGTTGATTTATTTGCAGTCTTTCTATCAATGGCATTTTTGTAATAATGAGAGTGTTCCCCAATTGAGACTCTCTCAAACTTTCTCATACAATTGGGGAATGGGGAACAATATATACTAGAACCCTCAATAGAACTTTGGATCTCGTTCACACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_003856008.1
|
|
Location
|
182-937 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCTAAGCGCGATGGTTCCTGGCGCTCTATCGCGGGAATGTCAAAAGTGAAACGCACTATGAATTTCTCTCCTCGTGGAGGTGGTGGCCCAAAAATGACAAGGGCCGCTGAATGGGTTAACAGGCCTATGTACAGGAAGCCTAGGATTTATCGGACTCTGAGGACGCCTGATATTCCGAGAGGCTGTGAAGGCCCTTGCAAGGTGCAGTCTTATGAACAACGGCATGATATCTCACATGTCGGGAAGGTCATGTGTATTTCAGATGTGACACGTGGTAACGGCATTACTCATCGTGTTGGTAAGCGATTCTGTGTTAAGTCTGTGTATATTTTAGGTAAGGTATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTCGACCGTATGGCACTCCGATGGATTTCGGTCAGGTGTTCAACATGTTCGATAACGAGCCTAGCACTGCGACTGTGAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAGCAAGCTCTCGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCACCAGGAAGCTGGCAAGTACGAGAATCATACGGAGAATGCGTTACTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MSKRDGSWRSIAGMSKVKRTMNFSPRGGGGPKMTRAAEWVNRPMYRKPRIYRTLRTPDIPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_003856009.1
|
|
Location
|
934-1332 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAGCGCAGAGGACCAGCTATACACCAGAACCAGAGTGTACCACATACAGATAAGATTCAACCACAACCTGAGGAAAGCGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGTTTCTGGGTTAACTTATTTAGCTAGATTTAGACATTTAGTTAACATGTACTTGTACCAATTAGGTGTAATTGGGATAAACAATGTAATTAGAGCTGTTAGATTTGCAACAGCCAAACCATATGTAAATTATGTGCTTGAGAATCATATAATAAAATATAAATGTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVYIWEIENPLYFKIYSAEDQLYTRTRVYHIQIRFNHNLRKALGLHKAYLNFQVWTTSMTVSGLTYLARFRHLVNMYLYQLGVIGINNVIRAVRFATAKPYVNYVLENHIIKYKCY |
|
NCBI Accession
|
YP_003856010.1
|
|
Location
|
1079-1468 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCCATATTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGCGGGCAATCAGGAGACGCAGGATTGATCTAGATTGCGGGTGCTCCATTTACTTCCACATCGGCTGCACGGGCCATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAGCGCAGAGGACCAGCTATACACCAGAACCAGAGTGTACCACATACAGATAAGATTCAACCACAACCTGAGGAAAGCGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGTTTCTGGGTTAACTTATTTAGCTAG |
|
Protein Sequence
|
MPYSSPSQPPSIKKAHRQAKRRAIRRRRIDLDCGCSIYFHIGCTGHGFTHRGTHHCTSGREWRVYLGDRKSPLFQDIQRRGPAIHQNQSVPHTDKIQPQPEESVGSPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
YP_003856011.1
|
|
Location
|
1380-2465 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCAGTTAAACGTTTTAAAATAAATGCCAAAAACTATTTCATCACATATCCCGACTGCTCCCTGAGCAAAGAAGAAGCACTTTCTCAATTACAAAACCTGTCCACTCCTGTGAACAAGAAGTTCATCAAGATCTGCAGAGAGTTCCATCAGAATGGGAAGCCTCATCTCCACGTGCTTATACAATTCGAGGGGAAATATGCATGCACGAATTACAGATTCTTCGACCTGGTCTCACCATCCATGTCAGTCCCATTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCAACAAGGACGGAGACACACTGGAATGGGGTGAATTCCAGATCGACGGGAGAAGTGCTAGAGGAGGCTGCCAATCGGTTAACGATACATATGCCAAGGCGTTGAATGCCTCTTCTGCAGAAGAGGCTCTGCAAATAATCAAGGAGGAACAGCCTCAACATTTCTTTCTTCAGCATCACAATCTGGTTGCCAATGCTCATCGGATTTTCAGTAAGGCTCCTGAGCCATGGGCTCCTCCGTTTCCCCTCTCTTCTTTCACAGCCGTTCCCGACGAGATGCAAGAATGGGCCGATGAGAATTTTGGAAGAGGTGCCGCTGCGCGGCCGGAGAGACCTATGAGTATCATAGTAGAAGGTGACTCGAGGACAGGGAAGACGATGTGGGCTCGTTCGTTAGGCCCACATAATTATCTTAGTGGACATCTGGACTTCAACCCTCGAGTATTTTCAAATGACGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGTTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAATCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGCGGGATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCTAGCTATAAAGATTTCCTAGCCAAAGAGGAAAACACAGGTCTAAAGAATTGGACCAACAAGAATGCCATATTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGCGGGCAATCAGGAGACGCAGGATTGA |
|
Protein Sequence
|
MPSVKRFKINAKNYFITYPDCSLSKEEALSQLQNLSTPVNKKFIKICREFHQNGKPHLHVLIQFEGKYACTNYRFFDLVSPSMSVPFHPNIQGAKSSSDVKSYINKDGDTLEWGEFQIDGRSARGGCQSVNDTYAKALNASSAEEALQIIKEEQPQHFFLQHHNLVANAHRIFSKAPEPWAPPFPLSSFTAVPDEMQEWADENFGRGAAARPERPMSIIVEGDSRTGKTMWARSLGPHNYLSGHLDFNPRVFSNDVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLAKEENTGLKNWTNKNAIFITLTAPLYQEGTQASQEAGNQETQD |
|
NCBI Accession
|
YP_003856012.1
|
|
Location
|
2051-2308 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAAGCCTCATCTCCACGTGCTTATACAATTCGAGGGGAAATATGCATGCACGAATTACAGATTCTTCGACCTGGTCTCACCATCCATGTCAGTCCCATTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCAACAAGGACGGAGACACACTGGAATGGGGTGAATTCCAGATCGACGGGAGAAGTGCTAGAGGAGGCTGCCAATCGGTTAACGATACATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGSLISTCLYNSRGNMHARITDSSTWSHHPCQSHSIQTYRELNPAPMSSPTSTRTETHWNGVNSRSTGEVLEEAANRLTIHMPRR |
|
NCBI Accession
|
YP_003856013.1
|
|
Location
|
385-1155 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shutting protein |
|
Coding Region
|
ATGTATCCTTTTAGAAGTAAACGTGGTTATTGCTTTAGTCATCGACGATCTACCACACGTAACTTTTTGTTTAACCGTTCAACCTCAATTAAGAGACATGATGGGAAACGTCGAGGAGGTCGATTTGTAAAGCCCATTGATGAACCCAAAATGTCAGCCCAATCCATACATGAAAATCAGTATGGGCCTGATTTTGTTATGGCCCAAAATTCGGCTATATCTACGTTTATCAGTTACCCAGACATGGGCAAGGTAGAACCTAGTCGAAGCAGATCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTGAATATCAAACGTGTTCAATCGGATGTGAACATGGATGGGTCTATCTCCAAAGTGGAAGGAGTGTTCTCTCTTATTATTGTTGTAGATCGGAAACCTCACTTGGGTCCTAGTGGTTGTCTGCATACATTCGACGAGCTGTTCGGAGCAATGATTCACAGTCATGGCAATCTCAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCATGTGTTCAAACGTGTACTGTCCGTTGATAACGAGACGCTGATAGTAGACGTGGAAGGATCCACTACCCTATCTAATAGGCGTTTTAATATTTGGTCCAGTTTCAAGGACGTTGATCGTGATTCATGCAAGGGTGTTTATGATAACATAAGCAAGAACGCCCTTTTAATTTATTATTGCTGGATGTCAGATATGCCTTCAAAGGCCTCCACTTATGTATCTTTTGATCTTGACTATGTTGGTTAA |
|
Protein Sequence
|
MYPFRSKRGYCFSHRRSTTRNFLFNRSTSIKRHDGKRRGGRFVKPIDEPKMSAQSIHENQYGPDFVMAQNSAISTFISYPDMGKVEPSRSRSYIKLKRLRFKGTVNIKRVQSDVNMDGSISKVEGVFSLIIVVDRKPHLGPSGCLHTFDELFGAMIHSHGNLSIVPSLKDRYYIRHVFKRVLSVDNETLIVDVEGSTTLSNRRFNIWSSFKDVDRDSCKGVYDNISKNALLIYYCWMSDMPSKASTYVSFDLDYVG |
|
NCBI Accession
|
YP_003856014.1
|
|
Location
|
1217-2098 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGAATTCTCAGTTAGCATATCCTCCAAGCGCCTTCAATTACATAGAGTCTCACAGAGACGAATATCAGCTCTGCCATGACCTAACTGAGATAATCTTGCAATTTCCATCGACGGCGTCCCAGTTGACGGCAAGACTCAGCCGTAGCTGCATGAAGATAGATCATTGTGTCATAGAGTACAGGCAACAGGTTCCAATTAACGCAACTGGGACGGTAATTGTGGAGATCCATGACAAGAGGATGACAGACAATGAGTCTTTGCAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTATTTTTCAGCTTCATTCTTCTCTCTCAAAGACCCGATTCCATGGAAACTCTATTACAGAGTTTCAGATACCAATGTTCACCAGCGAACCCACTTCGCCAAGTTTAAAGGGAAGCTGAAATTGTCCACAGCGAAACACTCAGTAGATATCCCCTTCCGGGCACCGACGGTCAAAATACTGTCAAAACAGTTCACAGACAAAGATGTAGACTTTTCGCATGTGGACTATGGGAAATGGGAGAGGAAGCCCATAAGATGTGCATCGATGTCTAGAATTGGGTCTAAATGTCCAATTGAGCTTGGGCCTGGAGAATCATGGGCTTCCAGAAGTACGATAGGAACGGCCCAATCAGATGTGGACTCGGAAATAGAAAACGGACTCCACCCATACAGACATCTGAGCAGGCTTGGAACCAGCGTTCTGGACCCAGGAGAGTCTGCTTCAATAGTGGGAGCCCAGAGAGCGGAATCCAACATTACAATGTCTTTGGGCCAGTTGAACGAGTTAGTTAGGACAACAGTCCAAGAATGTATTAATAATAATTGTCAGGCTTCTCAGGCCAAGTCGTTGAAATAA |
|
Protein Sequence
|
MNSQLAYPPSAFNYIESHRDEYQLCHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRIGSKCPIELGPGESWASRSTIGTAQSDVDSEIENGLHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMSLGQLNELVRTTVQECINNNCQASQAKSLK |