Sida golden mosaic Costa Rica virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000840525.1 |
| Release date |
2015/2/12 |
| Submitter |
Hofer,P., Engel,M., Jeske,H., Frischmuth,T., Hoefer,P. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
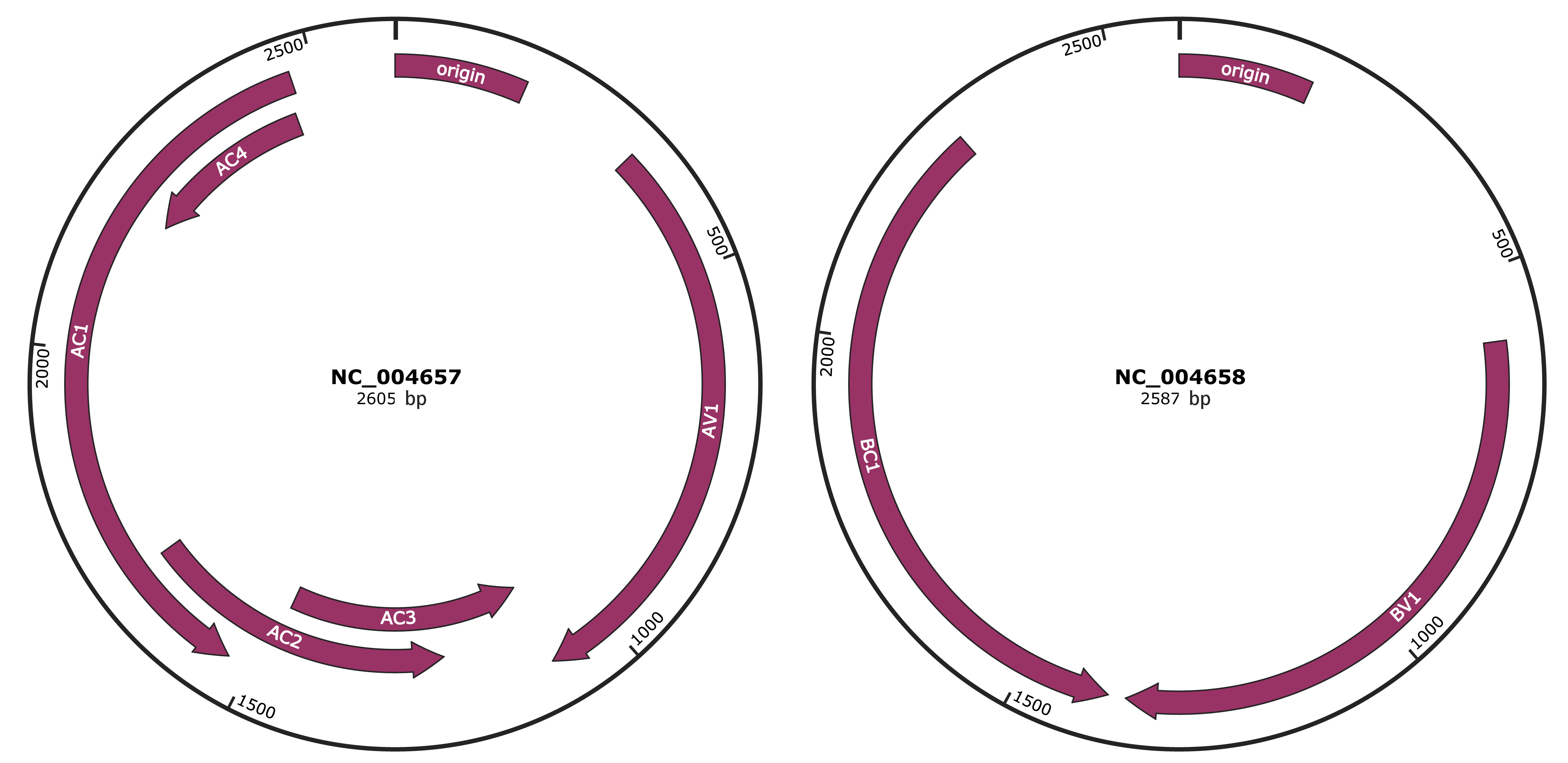
JBrowse
Genome
GGCGGTGGCATTTTTCTAATAAGAGGAAGTACTCTCTTTGGTTACTCCAGTTGAGCCCTCTCAAACTTGCTGATTCTATTGGAGTATTAGAGTATCCATATATACTACTAGTCTCAATCTTGGTTTTGATACACGTGGCGGCCATCCGTATAATATTACCGGATGGCCGCGCTTTGGAGTATGCTCTTTAATTTGAAAAGAGGCGCTCCGCTTTCGTCTGGTCCAATGAGGTAGCGCCTGACGAGCTTATTTATTTTAAACAACTTGGGCGCTAAGTTGTTGTATGTCGTTATAAATTAAAGATTGGCCCGGCCCACTGTCTTTATTTCAAAATGCCTAAGCGCGATGTCCCATGGCGCAATATAGCGGGCACCTCAAAGGTTAGCCGCTCGTCGAATGACTCCCCTCGTGCAGGCAGTGGGCCAAAATTTTATAAGGCCGCGAGATGGGTTGACAGGCCCATGTATAGGAAGCCCAGGATTTATCGGATCCTCCGCACGCCCGACGTTCCCAGAGGATGTGAAGGCCCTTGCAAGGTCCAATCCTATGAGCAGCGTCATGATATCTCACACGTGGGTAAGGTAATGTGTATATCTGATGTCACACGCGGTAATGGTATCACCCACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGGAAGATCTGGATGGATGAGAATATTAAGCTGAAGAACCACACGAATAGTGTTATGTTCTGGTTGGTCAGGGACCGTAGACCCTATGGCACGCCTATGGACTTTGGCCAGGTGTTCAACATGTTCGATAATGAGCCCAGTACTGCCACTGTGAAGAACGATCTAAGGGATCGTTACCAGGTCATGCACAAGTTCTACGCCAAGGTTACTGGTGGACAGTACGCGAGTAACGAGCAAGCCTTGGTGAAGAGATTCTGGAAGGTCAACAATCATGTGGTCTACAACCACCAGGAAGCTGGAAAGTACGAGAATCACACCGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCAGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAATAAATTATGAATTTTATTGAATGATCTTGGAGTACATAATTTACATATGATCGGTCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAAGTGAAATCACACCTAATTGATCTAAATACATATGAACTAAACGTCTAAACCTACTTAAATAAGTCGACCCAGAAGCTGTCAGGGATGTCGTCCAGACTTGGAAGTTCAGGTACGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGGATTTGGATACTGTATATCCTGGTGTTCGTGAACGGTGGATCCTCTACCTTGTATATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATAAACGCCATTCTCTGAATGAGGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGCCCGTACAGCCGATATGGAAGTATATGGAGCACCCGCACTCTAAATCAATGCGGCGTCGCCTGACCGACCTCTTCTTGGCTTGCCTGTGTGTCTTCTTGATAGAGGGGGGAGTCGATGGTGATGAAGACCGCATTCTTGAGGGTCCAGTTTTTGAGTGCTGTGTTCTCCTCTTTGTCCAGGAAATCTTTATAACTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATTCCTCCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTTGACTGCCAGTCCCTTTGGGACCCGATTAATTCTTTCCAGTGCTTTAACTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATATTCCACTTCGTTTGAGAACACTCTGGAATTGAAGTCTAGGTGTCCACTAAGATAATTATGTGGGCCTAATGCCCGAGCCCACATCGTCTTCCCTGTTCTTGAATCACCTTCTACTATGAGACTTACTGGTCTATCTGGGCGCGCAGCGGAACCTCTTCCAAAATAATGATCTGCCCATACTTGCATCTGCTCTGGAACGTTAGTGAACGAGGAGAGGGGAAACGGAGGAGCCCACGGTGACGGAGCCTTTTGAAATATTCTGGTTGCGTTTGCAACCAGGTTGTGATGTTGAAGGAAGAAATGTTGGGGTTGTTCTTCCTTGATTATCCGTAGAGCTTCCTCCGCCGACGATGCATTTAACGCCTTGGCATATGAGTCGTTAGCCGATTGCTGGCCTCCTCTAGCAGACCTACCGTCGATTTGAAACTCCCACCACTCAACGGTGTCGCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGTATGTTCGGATGGAAATGTACTGACCTGGTTGGGGACACCAGATCGAAGAATCTCTGATTCGTGCATTGGTATTTCCCTTCGAATTGGATAAGCACATGCAGATGAGGTTGCCCATCTTCGTGCAATTCTCTGCAGATCTTGATGAATTTCTTGTTAACTGGTGTTGCTAGGTTTTGTAATTGGGAAAGTGCTTCTTCTTTAGTAAGAGAGCACTGGGGATAAGTGAGGAAATGGTTCTTCGATTGAACTCTAAATTTCTTA
GGCGGTGGCATTTTTGTAATAAGAATGGGTACTCTAGTTGGAGTACTCCAGTTGAGCCCTCTCAAACTTGCTCATTCTATTGGAGTATTAGAGTACCATATATACTACTTGTGTTTATCTTGGTTTTGGTACACGTGGCGGCCATCCGTATAATATTACCGGATGGCCGCGCGGAGTATGCTATGTGTCCGTACTCTACAGCTGGTGCGCATTACTCCGCTCCCCTCTCTCCTGGTGTCTTTGCCACCTGGCGCTCTCTCCGCCCTCGATTTATCTTTCCTTTCGTTGATTGGCGTCTCTTTATTGACCAGCCTTTAATTTAAATTAAAGTTTAGTCCTTTTATGTCGGCGCGATATCAATTCAATTTTGAATTATTGATTCGCGATTCCTGTTTATGGCCCCCATTGTACTACATGGTCGACGTGGACGATTTGAGACCATGCTGCTGAGTCAGGTTACGTTCTATTGCTAATTAGCCTTTTCTATATATTGGGGCCGGTTTGTATATTTTGATCGATGTGACTCAGCTCTCGACCACGTATATATTATTAGCCACTTATTATCTGCCCGATCAAGTATTACTATATGATCATGTATCCTTACAGGTATAAGCGTGGTCCCTCGTTCGCTGCACGACGATCTTATACACGTAATTATGCGTTTAAGCGTCCTACTAATTCCAAACGAGATGATGGGAAACGTAGGCCTGTTAACAATAATAAGGCCCATGATGAACCCAAGATGTCAGCCCAGCGGATGCACGAGAATCAGTTCGGTCCGGACTTTGTTATGGCCCATAATTCAGCCATTTCAACGTTCATCAGTTACCCCAGTCTTTGTAAGACTGAACCGAATCGGAGCAGGTCCTATATCAAGTTGAAACGACTGCGTTTCAAAGGCACTGTGAAGATTGAACGTGTTCAGGCAGATGTTAGCATGGACGGTGCTATCCCTAAAGTGGAAGGTGTGTTCTCCTTCGTTATTGTTGTGGATCGTAAACCACACTTGGGTACCTCTGGTTGTCTCCACACGTTCGACGAGCTCTTCGGTGCTAGGATCCACAGCCATGGTAACCTGAGCATAACCCCTTCATTGAAAGAGCGGTTCTACATAAGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAGGATACGTTAATGGTTGACGTGGAAGGGTCCACTACGCTCTCTAACAGACGCTATAATTGTTGGTCTACGTTTAAGGATCTAGATCGTGACTCGTGTAATGGTGTCTATGGCAATATTAGCAAGAACGCCGTCTTAGTTTATTATTGTTGGATGTCAGATGCTATGTCCAAGGCATCTACATTTGTATCGTTTGACCTTGACTATGTTGGATGATTAATGAATAAAAATAAAAAGTTTTATTGCAATGATTTGGGCTGTGACGGTTTACAATTACTGTTAATACATTCTTGGACCGTAGTCCTAACTAGCTCGTTTAATTGGCCCATTGACATTGTTATATTGGATTCTGCTCTCTGGGCTCCTACTATTGAAGCAGACTCTCCCGGATCCAAAACGCTGGTCCCCAGCCTACTTAGGTGCCTGTAAGGATGCAACTCGTTTTCCACCTCGGAGTCCGCATCTGAATGCCCCGTTCCCACCGCACTCCTGGAAGCCCACGATTCACCGGGCTTGATCTCAAGTGGGCCTCTGAGCCCAACCCTGGACATGGAGGCGCATCTGATGGGCTTCCTTTCCCATCTTCCGTAGTCGACGTGGGAGAAGTCCACATCCTTGTCGGTGAACTGTTTGGACAGGATCCTGACTGTCGGTGCCCGGAATGGTATATCCACCGAGTGTTTCGCCGTCGACAGCTTCAGCTTCCCCTTGAACTTGGCGAAGTGGGTCCTCTGATGAACATTGGTATCGGAAACTTTGTAATACAGTTTCCATGGAATTGGGTCCTTGAGAGAGAAAAAGGAAGCTGAGAAGTAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCATGACGCCTGTAAGGATTCGTTGTCCGTCATCCTCTTGTCGTGTATCTCCACGATTACCGACCCGGTGGCGTTAATCGGCACCTGTTGCCTGTACTCTATGACGCAATGGTCAATCTTCATGCAGCTCCGGCTGAATCTCGCCGTTAACTGAGACGCCGTCGATGGAAATTGCAGAAATATCTCAGTTAGGTCATGGGAAAGCTGATATTCTTCTCTGTGAGACTCCATGTAGTTAAAGGCGTTTGGAGGATTAACTAACTGAGAATCCATATGGTAAAGAAAGGCGCGCAGCGGAACCGATTGCTGAAGTTGAATCGGTAACTGGGTTGTTAGGGTTCTTTTTGAAGAACAGTTGTTGAACTACTCTTGAATATGAAAGTGTTTCTGGGTTTCCCAGAAATTTGATGAACAAGCTGAAGAACTCTTGTTTAATCTCTCTTGAATGTGAAATTGTTTTTGAGAAAAAGGAGAAATCTGGTGAAGAAACTGAAGATGGTAGTCAGTTAGATCTGACATTAGTTATTTATAGACATCTTTCTTTTGTTTGTGAGCTCTTTGTTTTAGAGCTTTCAGGATACGTTTTTGCTAA
Gene Information
|
NCBI Accession
|
NP_808891.1
|
|
Location
|
333-1088 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGTCCCATGGCGCAATATAGCGGGCACCTCAAAGGTTAGCCGCTCGTCGAATGACTCCCCTCGTGCAGGCAGTGGGCCAAAATTTTATAAGGCCGCGAGATGGGTTGACAGGCCCATGTATAGGAAGCCCAGGATTTATCGGATCCTCCGCACGCCCGACGTTCCCAGAGGATGTGAAGGCCCTTGCAAGGTCCAATCCTATGAGCAGCGTCATGATATCTCACACGTGGGTAAGGTAATGTGTATATCTGATGTCACACGCGGTAATGGTATCACCCACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGGAAGATCTGGATGGATGAGAATATTAAGCTGAAGAACCACACGAATAGTGTTATGTTCTGGTTGGTCAGGGACCGTAGACCCTATGGCACGCCTATGGACTTTGGCCAGGTGTTCAACATGTTCGATAATGAGCCCAGTACTGCCACTGTGAAGAACGATCTAAGGGATCGTTACCAGGTCATGCACAAGTTCTACGCCAAGGTTACTGGTGGACAGTACGCGAGTAACGAGCAAGCCTTGGTGAAGAGATTCTGGAAGGTCAACAATCATGTGGTCTACAACCACCAGGAAGCTGGAAAGTACGAGAATCACACCGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCAGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDVPWRNIAGTSKVSRSSNDSPRAGSGPKFYKAARWVDRPMYRKPRIYRILRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
NP_808909.1
|
|
Location
|
1085-1483 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCATTCAGAGAATGGCGTTTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAAGGTAGAGGATCCACCGTTCACGAACACCAGGATATACAGTATCCAAATCCGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCGTACCTGAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGTCGACTTATTTAAGTAGGTTTAGACGTTTAGTTCATATGTATTTAGATCAATTAGGTGTGATTTCACTTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACCGATCATATGTAAATTATGTACTCCAAGATCATTCAATAAAATTCATAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPHSENGVYIWEIENPLYFKIYKVEDPPFTNTRIYSIQIRFNHNLRRALHLHKAYLNFQVWTTSLTASGSTYLSRFRRLVHMYLDQLGVISLNNVIRAVRFATDRSYVNYVLQDHSIKFIIY |
|
NCBI Accession
|
NP_808910.1
|
|
Location
|
1230-1694 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
CTGGTGAGGGTGCCAGTTATAAAGATTTCCTGGACAAAGAGGAGAACACAGCACTCAAAAACTGGACCCTCAAGAATGCGGTCTTCATCACCATCGACTCCCCCCTCTATCAAGAAGACACACAGGCAAGCCAAGAAGAGGTCGGTCAGGCGACGCCGCATTGATTTAGAGTGCGGGTGCTCCATATACTTCCATATCGGCTGTACGGGCCATGGATTCACGCACAGGGGAACTCATCACTGCACCTCATTCAGAGAATGGCGTTTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAAGGTAGAGGATCCACCGTTCACGAACACCAGGATATACAGTATCCAAATCCGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCGTACCTGAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGTCGACTTATTTAAGTAG |
|
Protein Sequence
|
MVRVPVIKISWTKRRTQHSKTGPSRMRSSSPSTPPSIKKTHRQAKKRSVRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSFREWRLYLGDRKSPLFQDIQGRGSTVHEHQDIQYPNPVQPQPEESVASPQSVPELPSLDDIPDSFWVDLFK |
|
NCBI Accession
|
NP_808911.1
|
|
Location
|
1531-2469 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
TTGCACGAAGATGGGCAACCTCATCTGCATGTGCTTATCCAATTCGAAGGGAAATACCAATGCACGAATCAGAGATTCTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGCGACACCGTTGAGTGGTGGGAGTTTCAAATCGACGGTAGGTCTGCTAGAGGAGGCCAGCAATCGGCTAACGACTCATATGCCAAGGCGTTAAATGCATCGTCGGCGGAGGAAGCTCTACGGATAATCAAGGAAGAACAACCCCAACATTTCTTCCTTCAACATCACAACCTGGTTGCAAACGCAACCAGAATATTTCAAAAGGCTCCGTCACCGTGGGCTCCTCCGTTTCCCCTCTCCTCGTTCACTAACGTTCCAGAGCAGATGCAAGTATGGGCAGATCATTATTTTGGAAGAGGTTCCGCTGCGCGCCCAGATAGACCAGTAAGTCTCATAGTAGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCTCGGGCATTAGGCCCACATAATTATCTTAGTGGACACCTAGACTTCAATTCCAGAGTGTTCTCAAACGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGTTAAAGCACTGGAAAGAATTAATCGGGTCCCAAAGGGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGAATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGTTATAAAGATTTCCTGGACAAAGAGGAGAACACAGCACTCAAAAACTGGACCCTCAAGAATGCGGTCTTCATCACCATCGACTCCCCCCTCTATCAAGAAGACACACAGGCAAGCCAAGAAGAGGTCGGTCAGGCGACGCCGCATTGA |
|
Protein Sequence
|
MHEDGQPHLHVLIQFEGKYQCTNQRFFDLVSPTRSVHFHPNIQGAKSSSDVKSYIDKDGDTVEWWEFQIDGRSARGGQQSANDSYAKALNASSAEEALRIIKEEQPQHFFLQHHNLVANATRIFQKAPSPWAPPFPLSSFTNVPEQMQVWADHYFGRGSAARPDRPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEVEYNVIDDVAPHYLKLKHWKELIGSQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENTALKNWTLKNAVFITIDSPLYQEDTQASQEEVGQATPH |
|
NCBI Accession
|
NP_808912.1
|
|
Location
|
2202-2459 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCATCTGCATGTGCTTATCCAATTCGAAGGGAAATACCAATGCACGAATCAGAGATTCTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGCGACACCGTTGAGTGGTGGGAGTTTCAAATCGACGGTAGGTCTGCTAGAGGAGGCCAGCAATCGGCTAACGACTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MGNLICMCLSNSKGNTNARIRDSSIWCPQPGQYISIRTYRELNQAPTSSPTSTRTATPLSGGSFKSTVGLLEEASNRLTTHMPRR |
|
NCBI Accession
|
NP_808892.1
|
|
Location
|
593-1363 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTATCCTTACAGGTATAAGCGTGGTCCCTCGTTCGCTGCACGACGATCTTATACACGTAATTATGCGTTTAAGCGTCCTACTAATTCCAAACGAGATGATGGGAAACGTAGGCCTGTTAACAATAATAAGGCCCATGATGAACCCAAGATGTCAGCCCAGCGGATGCACGAGAATCAGTTCGGTCCGGACTTTGTTATGGCCCATAATTCAGCCATTTCAACGTTCATCAGTTACCCCAGTCTTTGTAAGACTGAACCGAATCGGAGCAGGTCCTATATCAAGTTGAAACGACTGCGTTTCAAAGGCACTGTGAAGATTGAACGTGTTCAGGCAGATGTTAGCATGGACGGTGCTATCCCTAAAGTGGAAGGTGTGTTCTCCTTCGTTATTGTTGTGGATCGTAAACCACACTTGGGTACCTCTGGTTGTCTCCACACGTTCGACGAGCTCTTCGGTGCTAGGATCCACAGCCATGGTAACCTGAGCATAACCCCTTCATTGAAAGAGCGGTTCTACATAAGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAGGATACGTTAATGGTTGACGTGGAAGGGTCCACTACGCTCTCTAACAGACGCTATAATTGTTGGTCTACGTTTAAGGATCTAGATCGTGACTCGTGTAATGGTGTCTATGGCAATATTAGCAAGAACGCCGTCTTAGTTTATTATTGTTGGATGTCAGATGCTATGTCCAAGGCATCTACATTTGTATCGTTTGACCTTGACTATGTTGGATGA |
|
Protein Sequence
|
MYPYRYKRGPSFAARRSYTRNYAFKRPTNSKRDDGKRRPVNNNKAHDEPKMSAQRMHENQFGPDFVMAHNSAISTFISYPSLCKTEPNRSRSYIKLKRLRFKGTVKIERVQADVSMDGAIPKVEGVFSFVIVVDRKPHLGTSGCLHTFDELFGARIHSHGNLSITPSLKERFYIRHVFKRVLSVEKDTLMVDVEGSTTLSNRRYNCWSTFKDLDRDSCNGVYGNISKNAVLVYYCWMSDAMSKASTFVSFDLDYVG |
|
NCBI Accession
|
NP_808913.1
|
|
Location
|
1387-2289 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
CTGCGCGCCTTTCTTTACCATATGGATTCTCAGTTAGTTAATCCTCCAAACGCCTTTAACTACATGGAGTCTCACAGAGAAGAATATCAGCTTTCCCATGACCTAACTGAGATATTTCTGCAATTTCCATCGACGGCGTCTCAGTTAACGGCGAGATTCAGCCGGAGCTGCATGAAGATTGACCATTGCGTCATAGAGTACAGGCAACAGGTGCCGATTAACGCCACCGGGTCGGTAATCGTGGAGATACACGACAAGAGGATGACGGACAACGAATCCTTACAGGCGTCATGGACTTTTCCGATCAGATGCAACATAGATCTCCACTACTTCTCAGCTTCCTTTTTCTCTCTCAAGGACCCAATTCCATGGAAACTGTATTACAAAGTTTCCGATACCAATGTTCATCAGAGGACCCACTTCGCCAAGTTCAAGGGGAAGCTGAAGCTGTCGACGGCGAAACACTCGGTGGATATACCATTCCGGGCACCGACAGTCAGGATCCTGTCCAAACAGTTCACCGACAAGGATGTGGACTTCTCCCACGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGCGCCTCCATGTCCAGGGTTGGGCTCAGAGGCCCACTTGAGATCAAGCCCGGTGAATCGTGGGCTTCCAGGAGTGCGGTGGGAACGGGGCATTCAGATGCGGACTCCGAGGTGGAAAACGAGTTGCATCCTTACAGGCACCTAAGTAGGCTGGGGACCAGCGTTTTGGATCCGGGAGAGTCTGCTTCAATAGTAGGAGCCCAGAGAGCAGAATCCAATATAACAATGTCAATGGGCCAATTAAACGAGCTAGTTAGGACTACGGTCCAAGAATGTATTAACAGTAATTGTAAACCGTCACAGCCCAAATCATTGCAATAA |
|
Protein Sequence
|
MRAFLYHMDSQLVNPPNAFNYMESHREEYQLSHDLTEIFLQFPSTASQLTARFSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYKVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVRILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRVGLRGPLEIKPGESWASRSAVGTGHSDADSEVENELHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVRTTVQECINSNCKPSQPKSLQ |