Sida golden mosaic Buckup virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000889555.1 |
| Isolate |
Jamaica |
| Release date |
2015/2/22 |
| Submitter |
Stewart,C.S., Kon,T., Gilbertson,R.L., Roye,M.E., Gilbertson,B.L. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
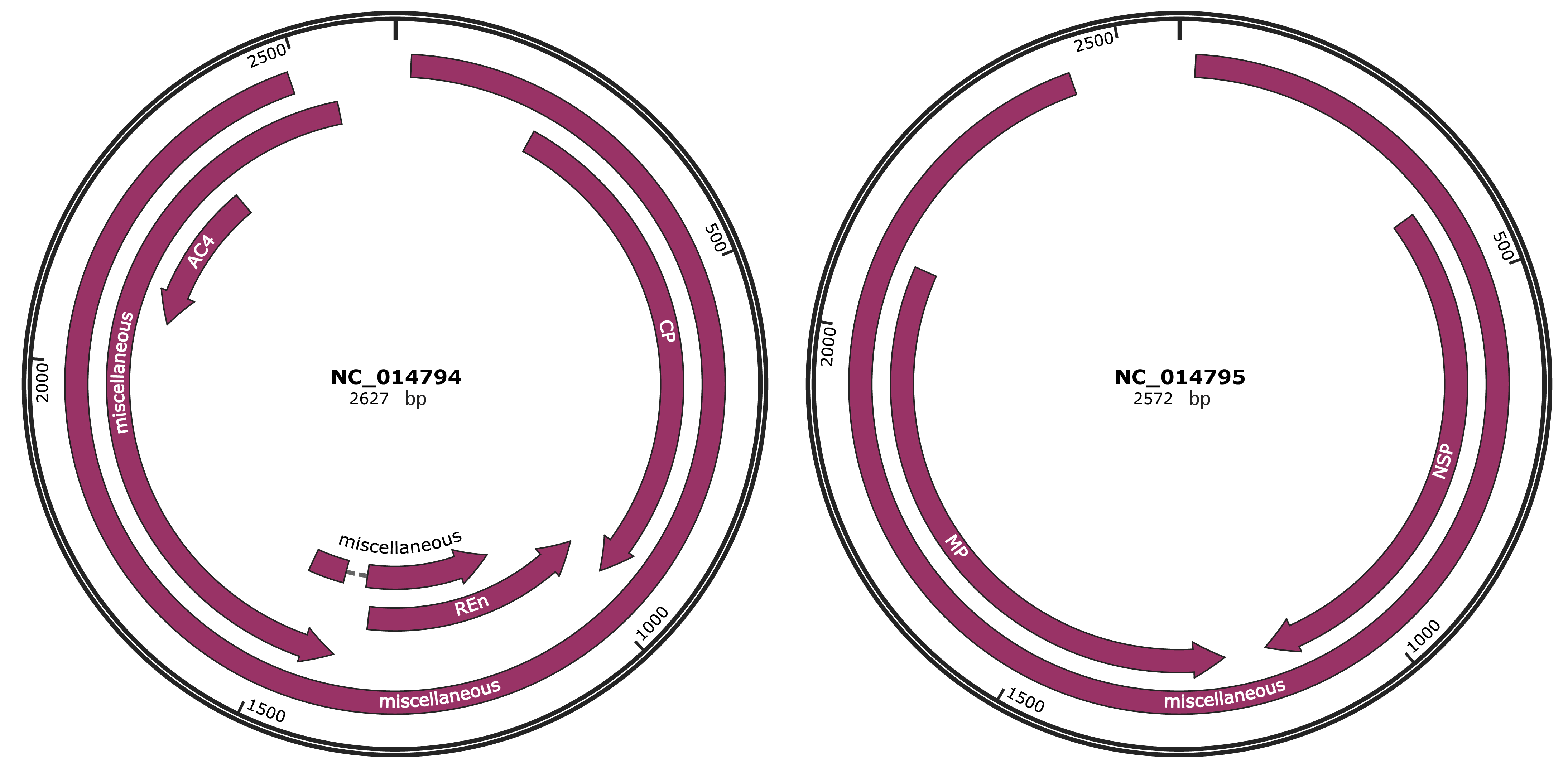
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCATCGGTGTACGCCCCCCCCCCCCCGCGGTCCCCCCCCTCCCGCGCGATCTTTAATTTGAATTAAAGATGGACCAGACGCTCTCGTCCAATCATAACGCGTCTGACGAGTCTATATATTTTAAACAACTTGGGCGCTAAGTTGTTGTGTGACCGTTATAAATTAAATATGATTTGGCCCACTGTCTTTAACTCAAAATGTCTAAGCGCGATGGCTCTTGGCGCTCTATCGCGGGAATGTCAAAAGTGAAACGCACTTTGAATTTCTCCCCTCGTGGAGGTGGTGGGCCGACAAGTTCAAGGGCCGCTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGCTAAAAACACCCGGAGTGCCCAGAGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTATGAGCAACGCCACGACATCTCTCATGTGGGAAAGGTCATGTGCATCTCCGATGTGACACGTGGTAATGGCATTACCCATCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGCACGCCAATGGATTTTGGCCAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACGGTGAAGAACGATCTTCGTGATCGTTATCAAGTGATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAACGATTCTGGAAGGTCTACAATCATGTGGTCTACAACCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAATCCCGTGTATGCAACTTTGAAGATCAGAATCTATTTCTACGATTCGATCACTAATTAATAAATTTTGAATTTTATTGAATGATTTTCCAGTACATGTTCGATATACGATCTGTTTGTCGCGAATCGTACAGCTCTAATTACATTGTTAATTGAAATCACGCCTAATCTATCTAAATATAAATTAACTAAGCGACTAAATCTAGCTAAATAAGTCGACCCAGAAGCTGTCATCGATATCGTCCAGACTTGGAAGTTCAGGAAGGCTTTGTGGAGATGCAACGCTTTCCTCAGGTTGTGGTTGAACCGTATTTGTATGGTGTATATCCTGGTGTTCGTGTACAACGGGTCCTCTACTTGGTACATCCTGAAATGTAGGGGATTTTCTATCTCCCAGGTATATACGCCATTCTCTGCCTGAGGTACAGTGATGAGTTCCCCGGTGCGTGAATCCATGACCGGTGCAGCTATGTGGAAGTATATGGAGCAACCGCACTCCAGATCAATCCGCCGTCTCTGATGGCCCTCTTCTTGGCTTGCTTGTGTTTCTGTTTGATAGAGGGCGGATGTGAGGGTGATGAAGAGCGCATTCTTCAATGTCCAGTTCTTGAGACCTGTATTTTCCTCTTTGTCTAGGAAGTCTTTATAACTGGCACCCTCACCTGGATTGCAAAGCACGATTGATGGAATCCCTCCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTTGACTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAGCTTTAAATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTTGAAAAAACTCGGGAATTGAAGTCCAGGTGTCCACTAAGGTAATTGTGTGGGCCTAATGCACGTGCCCACATCGTCTTCCCTGTCCTCGAATCACCTTCCACTATGATACTAACTGGTCTGTCCGGCCGCGCAGCGGAACCTCCTCCAAAATAACCGTCCGCCCACTCTTGCATCTCATCGGGAACGTTAGTGAATGACGAGAGTTGAAACGGAGGGACCCACGGTTCCGGAGCCTTTTGAAATATTCTGGTTGCGTTAGCAACCAGGTTGTGGTTCTGGAGGAAGAAATGTTGCGGTTGTTCTTCCCTTATTATTTGCAGAGCTGCCTCTGCTGAACCGGCGTTCAACGCCTTGGCATATGAATCGTTAGCTGACTGCTGACCTCCTCTAGCAGATCTGCCGTCGATTTGGAATTGCCCCCATTCGATGGTGTCTCCGTCCTTCTCGACGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTACTGACCTGGTTGGGGACACCATATCGAAGAATCTGTTATTCGTGCACTGGTACTTGCCTTCGAACTGTATGAGAACGTGGAGATGAGGCTCCCCATTTTCGTGTAATTCTCTGCAAACCTTGATGAACTTCTTGTTTACTGGAGTTGTTAGGTTTTGTAATTGGGAAAGTGCTTCTTCTTTAGTAAGAGAGCACTGGGGATATGTGAGGAAATAGTTTTTAGCTGAGACTTTGAAACGTTTAATCGATGGCATTTTTGTAATAATAAGGGTGTACCCCGGTTGAGCTCTCTCAAACTTTCTCATTCAATTGGGGTAATGGGTTACAATATATAGTATAACCCTCATTTACTGATTTGCTACACCGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCATTGGTGACCCCCCCCTGGTGGTGGTGCCCGCGCCCCCCCTGGTGCTGTTCTCCCACGCGCTCCCTCATTGGTGCTGGTGCTCAGGTTTCTTTTTTGACCACTCTTTAATTTGAATTAAAGAGAGTATAGGTACTCGCGCGCGTATAATCGAAATTTGAATAATTTCCGCGCGTCTCATGAACATGGCCCATTGTACTACATGGTCGACGTGTCTGATTCTGGACCATGTTGCTGAGTCTGTTTAACCATTTTGAACAACTATATCTATATAATTGAGGAGTTTGATATAATATATTCGATCTGACTCAGCTTTCTACCACGTTTATAGTTTTATCTATATTTTTGATTTAACATTTTTTATTGTCTAACCATGTATTATTTTAGAGGTAAACGTGGTGGTTATTTCCCTAATCGAAGATTTATCTCACGTAATAATATGTTTAATCGTTCAACCGCTGGGAAGCGATATGATGGGAAACGTCGAGGAGGTCGATCTGTCAGGCCCAGTGAGGAACCCAAGATGTCAGCCCAAACCATACATGAAAATCAGTACGGCACTGATTTTGTCATGGCCCATAATTCAGCTATCTCGACGTTCATCAGTTATCCAGACTTGGGCAAGATAGAACCGGGACGAAGCAGGTCATATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAATCGGATTTGAACATGGACGGGACTGTCTCCAAAATAGAAGGAGTATTATCGCTTGTTGTTGTTGTGGATCGGAAACCCCACTTGGGTCCAAGTGGTTGTCTGCATACATTCGACGAGCTGTTTGGATCAATCATTCACAGTCATGGCAATCTTAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCACGTGTTCAAACGTGTTTTGTCATTGGAGAATGATACACATATGGTCGACATCGAAGGATCTACATGGTTATCTAACAGGCGTTTTACGTGTTGGTCCTCTTTCAAAGACGTGGATCGTGATTCATGCAAGGGTGTTTATGATAATATAAGCAAGAACGCCTTGTTAATCTATTATTGCTGGATGTCCGATACGCCCTCTAAGGCATCCAATTATGTATCTTTTGATCTTGATTATGTTGGTTAACTTAATAAATTGTGTTTATCCAAAAATGACTAATTTAATACGATAAATCAAAAGATATCGTTCATTTCAATGATTTGGCTTGAGAAGCCTGACAGTTATGATTAATACATTCTTGGACCGTAGTCCTGACTAACTCGTTCAACTGTCCCATTGATATCGTGATATTGGACCCCGCTCTCTGGTCTCCCACAATAGAAGCAGACTCTCCTGGATCCATAACGCTGGTCCCCAGCCTGTTCAGGTGTCTGTATGGGTGGATCTCGTTCTCCACCGCTGAGTCCGCATCTGATTGGCCCATACCTATGGTACTCCTGGAAGCCCATGACTCGCCAGGCCTTATTTCAATTGGGCCTCGTAATCCAACCCTTGACATGGACGCGCATCTGATGGGCTTCCTTTCCCATTTCCCATAATCCACATGGGAAAAGTCCACATCCTTGTCTGTGAACTGTTTGGATAGTATCTTCACTGTTGGTGCCCGGAAGGGGATGTCGACGGAGTGTTTGGCTGTGGACAATTTCAGTTTCCCTTTGAACTTGGCGAAGTGGGTCCGTTGATGAACATTCGTATCGCACACTCTGTAGTACAACTTCCATGGAATTGGGTCCTTCAACGAGAAGAACGAAGCCGAGAAATAATGGAGATCTATGTTGCACCTGATCGGAAAAGTCCATGACGCCTGTAATGACTCGTTGTCCGTCATCCTTTTGTCGTGGATCTCCACAATTACTGATCCTGTGGCGTTGATTGGTACCTGTTGCCTGTATTCTATGACGCAGTGGTCGATCTTCATGCAGCTACGACTGAGTCGAGCTGTTAATTGAGAAGCCGTTGAAGGGAATTGCAGTATTATCTCAGTTAGGTCATGAGAAAGCTGATATTCATCACGGTGAGATTCTATGTAATTGAAGGCATGTGGAGGATTTACTAACTGAGAATCCATATGAAGAAGAAAGGCCGCGCAGCGGAACCGATTGCTGAAGTTGAATCGGGAAGAAGATGAACAACTCTGGAAAGCTCTCCTTTGATCTCGAAGAAGGTAAAGATTTTCTTTTCTTTCTGTGTTTGAGAATGCTTTTTGTGTTAATTTTATTCTGGGAACTATGTGATAATGTATAACTGTTTAATGATTATGATTTTGAGAAAGAAAAGAGAGTTGATGAAGAATTTAAGAAAACCCAGAAAATGGAATAGGTTGTGTGTGAACCCATACTTGCTGGGATTCTGGTATTTAAATTGGTAAAGCGTTCATGAGAAGTTCTTACTTCCGGTGAATGGCATTTTTGTAATAAGAAGTGTGTACCCCGGTTGAGCTCTCTCAAACTTTCTCATTCAATTGGGGTAATGGGTTACAATATATAGTATAACCTTCATTTATGGATTTGCTACACGTGTCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_004063987.1
|
|
Location
|
211-966 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCTAAGCGCGATGGCTCTTGGCGCTCTATCGCGGGAATGTCAAAAGTGAAACGCACTTTGAATTTCTCCCCTCGTGGAGGTGGTGGGCCGACAAGTTCAAGGGCCGCTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGCTAAAAACACCCGGAGTGCCCAGAGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTATGAGCAACGCCACGACATCTCTCATGTGGGAAAGGTCATGTGCATCTCCGATGTGACACGTGGTAATGGCATTACCCATCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGCACGCCAATGGATTTTGGCCAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACGGTGAAGAACGATCTTCGTGATCGTTATCAAGTGATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAACGATTCTGGAAGGTCTACAATCATGTGGTCTACAACCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAATCCCGTGTATGCAACTTTGAAGATCAGAATCTATTTCTACGATTCGATCACTAATTAA |
|
Protein Sequence
|
MSKRDGSWRSIAGMSKVKRTLNFSPRGGGGPTSSRAAEWVNRPMYRKPRIYRTLKTPGVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVYNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_004063988.1
|
|
Location
|
963-1361 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGTACCTCAGGCAGAGAATGGCGTATATACCTGGGAGATAGAAAATCCCCTACATTTCAGGATGTACCAAGTAGAGGACCCGTTGTACACGAACACCAGGATATACACCATACAAATACGGTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAGATTTAGTCGCTTAGTTAATTTATATTTAGATAGATTAGGCGTGATTTCAATTAACAATGTAATTAGAGCTGTACGATTCGCGACAAACAGATCGTATATCGAACATGTACTGGAAAATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITVPQAENGVYTWEIENPLHFRMYQVEDPLYTNTRIYTIQIRFNHNLRKALHLHKAFLNFQVWTISMTASGSTYLARFSRLVNLYLDRLGVISINNVIRAVRFATNRSYIEHVLENHSIKFKIY |
|
NCBI Accession
|
YP_004063989.1
|
|
Location
|
2078-2335 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTTCTCATACAGTTCGAAGGCAAGTACCAGTGCACGAATAACAGATTCTTCGATATGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAGGACGGAGACACCATCGAATGGGGGCAATTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGTCAGCTAACGATTCATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGSLISTFSYSSKASTSARITDSSIWCPQPGQYISIRTYRELNPAPTSSPTSRRTETPSNGGNSKSTADLLEEVSSQLTIHMPRR |
|
NCBI Accession
|
YP_004063990.1
|
|
Location
|
387-1157 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTATTTTAGAGGTAAACGTGGTGGTTATTTCCCTAATCGAAGATTTATCTCACGTAATAATATGTTTAATCGTTCAACCGCTGGGAAGCGATATGATGGGAAACGTCGAGGAGGTCGATCTGTCAGGCCCAGTGAGGAACCCAAGATGTCAGCCCAAACCATACATGAAAATCAGTACGGCACTGATTTTGTCATGGCCCATAATTCAGCTATCTCGACGTTCATCAGTTATCCAGACTTGGGCAAGATAGAACCGGGACGAAGCAGGTCATATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAATCGGATTTGAACATGGACGGGACTGTCTCCAAAATAGAAGGAGTATTATCGCTTGTTGTTGTTGTGGATCGGAAACCCCACTTGGGTCCAAGTGGTTGTCTGCATACATTCGACGAGCTGTTTGGATCAATCATTCACAGTCATGGCAATCTTAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCACGTGTTCAAACGTGTTTTGTCATTGGAGAATGATACACATATGGTCGACATCGAAGGATCTACATGGTTATCTAACAGGCGTTTTACGTGTTGGTCCTCTTTCAAAGACGTGGATCGTGATTCATGCAAGGGTGTTTATGATAATATAAGCAAGAACGCCTTGTTAATCTATTATTGCTGGATGTCCGATACGCCCTCTAAGGCATCCAATTATGTATCTTTTGATCTTGATTATGTTGGTTAA |
|
Protein Sequence
|
MYYFRGKRGGYFPNRRFISRNNMFNRSTAGKRYDGKRRGGRSVRPSEEPKMSAQTIHENQYGTDFVMAHNSAISTFISYPDLGKIEPGRSRSYIKLKRLRFKGTVKIERVQSDLNMDGTVSKIEGVLSLVVVVDRKPHLGPSGCLHTFDELFGSIIHSHGNLSIVPSLKDRYYIRHVFKRVLSLENDTHMVDIEGSTWLSNRRFTCWSSFKDVDRDSCKGVYDNISKNALLIYYCWMSDTPSKASNYVSFDLDYVG |
|
NCBI Accession
|
YP_004063991.1
|
|
Location
|
1219-2100 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGTAAATCCTCCACATGCCTTCAATTACATAGAATCTCACCGTGATGAATATCAGCTTTCTCATGACCTAACTGAGATAATACTGCAATTCCCTTCAACGGCTTCTCAATTAACAGCTCGACTCAGTCGTAGCTGCATGAAGATCGACCACTGCGTCATAGAATACAGGCAACAGGTACCAATCAACGCCACAGGATCAGTAATTGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTCATTACAGGCGTCATGGACTTTTCCGATCAGGTGCAACATAGATCTCCATTATTTCTCGGCTTCGTTCTTCTCGTTGAAGGACCCAATTCCATGGAAGTTGTACTACAGAGTGTGCGATACGAATGTTCATCAACGGACCCACTTCGCCAAGTTCAAAGGGAAACTGAAATTGTCCACAGCCAAACACTCCGTCGACATCCCCTTCCGGGCACCAACAGTGAAGATACTATCCAAACAGTTCACAGACAAGGATGTGGACTTTTCCCATGTGGATTATGGGAAATGGGAAAGGAAGCCCATCAGATGCGCGTCCATGTCAAGGGTTGGATTACGAGGCCCAATTGAAATAAGGCCTGGCGAGTCATGGGCTTCCAGGAGTACCATAGGTATGGGCCAATCAGATGCGGACTCAGCGGTGGAGAACGAGATCCACCCATACAGACACCTGAACAGGCTGGGGACCAGCGTTATGGATCCAGGAGAGTCTGCTTCTATTGTGGGAGACCAGAGAGCGGGGTCCAATATCACGATATCAATGGGACAGTTGAACGAGTTAGTCAGGACTACGGTCCAAGAATGTATTAATCATAACTGTCAGGCTTCTCAAGCCAAATCATTGAAATGA |
|
Protein Sequence
|
MDSQLVNPPHAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGMGQSDADSAVENEIHPYRHLNRLGTSVMDPGESASIVGDQRAGSNITISMGQLNELVRTTVQECINHNCQASQAKSLK |