Sida golden mosaic Brazil virus
Basic Information
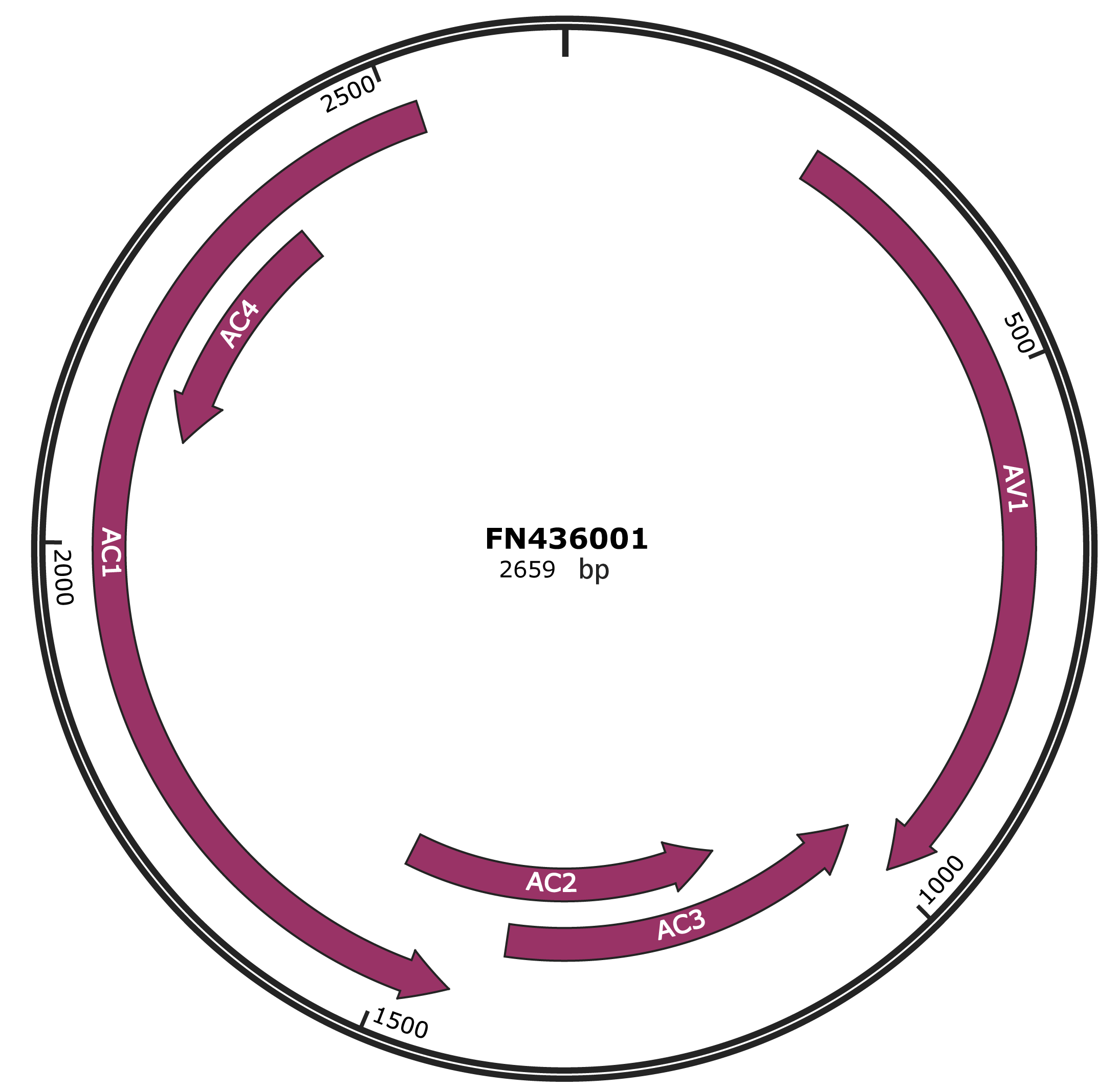
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTCGCCCCCCCCCACGTGGCGCTCTCTCCATCGCGCGATTTTCTTTTCCTTCCCCCTTTCTCGCGCGCGTGTCTCCTTTAATTTCAATTAAAGGAAAGTACTTTTGGTTCTACCAATGGTATTGCGCCTGGGGAGCCTAGATATTTGTGTTTAGACTTGGTCACTAAGTTTTATAGTCCCTATAAAACTAAAGCAAGCCTGACGTCAGACTTTAATTCAGAATGCCAAAGCGGGATCCCTCATGGCGCATGGTGGTGGGAACCTCAAAGGTTAGCCGCTCCTCCAATTTTTCACCTCGTGGAGGTGGAGGCCCAAGAGTCAACAAGGCCTCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATAGGACGCTGAGGACGCCTGATGTTCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAGCGTCATGACATTTCTCATGTCGGCAAGGTGATGTGTATATCTGATGTGACACGAGGTAATGGTATTACCCATCGTGTTGGTAAGCGTTTCTGTGTTAAATCTGTATATATTTTAGGGAAGATATGGATGGACGAGAACATCAAGTTAAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCTTATGGCACCCCGATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCAACCGTCAAGAACGATCTCCGTGATCGTTTCCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGGCAATATGCGAGCAACGAGCAGGCTCTGGTCAAGCGTTTCTGGAAGGTCAACAACCATGTTGTCTACAACCACCAGGAAGCTGGGAAATATGAGAATCATACTGAGAATGCATTGCTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCTACGCTTAAGATTCGGATCTATTTTTACGATTCGATCACCAATTAATAAATATTGAATTTTATTGAGTAATGTTCAAGTACATAGTTGACATATGATCTGTCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAATGGTAATAACCCCTAGGTTATCTAAATACAACATGACTAAATGTCTAAACCTATTCAAATAAGTCGTTCCAGAAGCTCGAATCGATGTCGTCCAGACTTGGAAGGTCATGTAAGCCTTGTGGAGACCCAACGCTCTCCTGAGGTTGTGATTGAACCTGATCTGGACGTGATATACTCTGGTCGTTGTGTATGGTAGATCCTCTACCTCGTATATCTTGAAATAGAGGGGATTTGTTATCTCCCAGATATAAACGCCATTCTCTGCCTGATGTGCAGTGATGAGTGCCCCTGTGCGTGAATCCATGTCCCGTGCAGTTCAGGTGCTGATATATCGTGCACCCGCACTCTAGATCAACTCGCCGTCGTCTGATCGCTCTCCTCTTGGCGATCCTGTGCTGTCGTTTGATAGAGGGGGGAGTCGAGGAAGATGAATTTAGCATTATGGAGTGTCCACGACCTCAAGGCTGCATTTTCCTGCTTGTCTAGGAATTCTTTATAGCTGGCCCCCTCTCCTGGATTGCAAAGCACGATTGATGGGATTCCCCCTTTAATTTGAACTGGCTTTCCGTACTTGCAGTTGCTTTGCCAGTCCCTCTGGGCTCCAATCAATTCTTTCCAGTGCTTTAGCTTTAGGTAGTGCGGGCTAACGTCATCAATGACGTTATATTCCACTTCATTTGAGAAGACTCTAGAATTGAAGTCCAGATGTCCACTCAAGTAATTATGTGGGCCTAAAGCACGAGCCCACATCGTCTTCCCTGTTCTTGAATCACCCTCAACAATCAAACTGATAGGTCTGTCTGGCCGCGCAGCGACAACCCTTCCAAAATAATCATCAGCCCACTCTTGCATCTCATGAGGAACGTTAGTGAATGTTGAGAGTTGAAACGGAGGAACCCATGGTTCTGGAGCCTTCTTGAAGAGCTTATCCAGGTTGGTTGAGAGGTTATGGTACTGGAAGAGAAACTTCTCTGGTAGTTTCTCCTTTATTATCTGCATAGCTTCTTCCTTTGAAGAAGAATTCAACGCCTCTGATGCTGCGTCATTAGCTGTCTGCTGACCTCCTCTAGCAGATCTTCCGTCGATCTGAAAAGTACCCCAGTCGATGTAATCACCGTCCTTCTTGATGTAGGACTTGACATCAGATGATGACTTTGCACCCTGTATATTGGCATGGGCGACGGAAGAGGTGTTTGGGTGTTTAAGATCGAAGAATCTGCAATTTGTGCACTGGAACTTGCCTTCAAATTGAACAAGGGCATGCAGATGTGGTTTCCCATTCTCGTGGAACTCTCTACATACCCTGATATATTTCTTCTTGCTGGGTGTTTCTAGGTTTATGAGTTGTTCAAGTGCAGTTTCTTTAGCAATCGAACAATCAGGGTATGTTAGGAAATAGTTTTTGGCATTGACCTTAAAACGCTTCGGTGGTGGCATATTTGTAAATAAGAGGGTGTACCCCGAACTAGCTCTCTCTCAAAGTCTATATTATTTGGTGTAAGGGTGCCAATATATACTAGAAGTTCCTAAGGTAACAATTGGTACCCCAATAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
CBA18086.1
|
|
Location
|
241-996 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCAAAGCGGGATCCCTCATGGCGCATGGTGGTGGGAACCTCAAAGGTTAGCCGCTCCTCCAATTTTTCACCTCGTGGAGGTGGAGGCCCAAGAGTCAACAAGGCCTCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATAGGACGCTGAGGACGCCTGATGTTCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAGCGTCATGACATTTCTCATGTCGGCAAGGTGATGTGTATATCTGATGTGACACGAGGTAATGGTATTACCCATCGTGTTGGTAAGCGTTTCTGTGTTAAATCTGTATATATTTTAGGGAAGATATGGATGGACGAGAACATCAAGTTAAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCTTATGGCACCCCGATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCAACCGTCAAGAACGATCTCCGTGATCGTTTCCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGGCAATATGCGAGCAACGAGCAGGCTCTGGTCAAGCGTTTCTGGAAGGTCAACAACCATGTTGTCTACAACCACCAGGAAGCTGGGAAATATGAGAATCATACTGAGAATGCATTGCTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCTACGCTTAAGATTCGGATCTATTTTTACGATTCGATCACCAATTAA |
|
Protein Sequence
|
MPKRDPSWRMVVGTSKVSRSSNFSPRGGGGPRVNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
CBA18087.1
|
|
Location
|
993-1391 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGCACTCATCACTGCACATCAGGCAGAGAATGGCGTTTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATATACGAGGTAGAGGATCTACCATACACAACGACCAGAGTATATCACGTCCAGATCAGGTTCAATCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCTTACATGACCTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGAACGACTTATTTGAATAGGTTTAGACATTTAGTCATGTTGTATTTAGATAACCTAGGGGTTATTACCATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGATCATATGTCAACTATGTACTTGAACATTACTCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGALITAHQAENGVYIWEITNPLYFKIYEVEDLPYTTTRVYHVQIRFNHNLRRALGLHKAYMTFQVWTTSIRASGTTYLNRFRHLVMLYLDNLGVITINNVIRAVRFATDRSYVNYVLEHYSIKFNIY |
|
NCBI Accession
|
CBA18088.1
|
|
Location
|
1138-1527 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACGACAGCACAGGATCGCCAAGAGGAGAGCGATCAGACGACGGCGAGTTGATCTAGAGTGCGGGTGCACGATATATCAGCACCTGAACTGCACGGGACATGGATTCACGCACAGGGGCACTCATCACTGCACATCAGGCAGAGAATGGCGTTTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATATACGAGGTAGAGGATCTACCATACACAACGACCAGAGTATATCACGTCCAGATCAGGTTCAATCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCTTACATGACCTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGAACGACTTATTTGAATAG |
|
Protein Sequence
|
MLNSSSSTPPSIKRQHRIAKRRAIRRRRVDLECGCTIYQHLNCTGHGFTHRGTHHCTSGREWRLYLGDNKSPLFQDIRGRGSTIHNDQSISRPDQVQSQPQESVGSPQGLHDLPSLDDIDSSFWNDLFE |
|
NCBI Accession
|
CBA18089.1
|
|
Location
|
1439-2524 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCACCGAAGCGTTTTAAGGTCAATGCCAAAAACTATTTCCTAACATACCCTGATTGTTCGATTGCTAAAGAAACTGCACTTGAACAACTCATAAACCTAGAAACACCCAGCAAGAAGAAATATATCAGGGTATGTAGAGAGTTCCACGAGAATGGGAAACCACATCTGCATGCCCTTGTTCAATTTGAAGGCAAGTTCCAGTGCACAAATTGCAGATTCTTCGATCTTAAACACCCAAACACCTCTTCCGTCGCCCATGCCAATATACAGGGTGCAAAGTCATCATCTGATGTCAAGTCCTACATCAAGAAGGACGGTGATTACATCGACTGGGGTACTTTTCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAGCTAATGACGCAGCATCAGAGGCGTTGAATTCTTCTTCAAAGGAAGAAGCTATGCAGATAATAAAGGAGAAACTACCAGAGAAGTTTCTCTTCCAGTACCATAACCTCTCAACCAACCTGGATAAGCTCTTCAAGAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCAACATTCACTAACGTTCCTCATGAGATGCAAGAGTGGGCTGATGATTATTTTGGAAGGGTTGTCGCTGCGCGGCCAGACAGACCTATCAGTTTGATTGTTGAGGGTGATTCAAGAACAGGGAAGACGATGTGGGCTCGTGCTTTAGGCCCACATAATTACTTGAGTGGACATCTGGACTTCAATTCTAGAGTCTTCTCAAATGAAGTGGAATATAACGTCATTGATGACGTTAGCCCGCACTACCTAAAGCTAAAGCACTGGAAAGAATTGATTGGAGCCCAGAGGGACTGGCAAAGCAACTGCAAGTACGGAAAGCCAGTTCAAATTAAAGGGGGAATCCCATCAATCGTGCTTTGCAATCCAGGAGAGGGGGCCAGCTATAAAGAATTCCTAGACAAGCAGGAAAATGCAGCCTTGAGGTCGTGGACACTCCATAATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACGACAGCACAGGATCGCCAAGAGGAGAGCGATCAGACGACGGCGAGTTGA |
|
Protein Sequence
|
MPPPKRFKVNAKNYFLTYPDCSIAKETALEQLINLETPSKKKYIRVCREFHENGKPHLHALVQFEGKFQCTNCRFFDLKHPNTSSVAHANIQGAKSSSDVKSYIKKDGDYIDWGTFQIDGRSARGGQQTANDAASEALNSSSKEEAMQIIKEKLPEKFLFQYHNLSTNLDKLFKKAPEPWVPPFQLSTFTNVPHEMQEWADDYFGRVVAARPDRPISLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEVEYNVIDDVSPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKEFLDKQENAALRSWTLHNAKFIFLDSPLYQTTAQDRQEESDQTTAS |
|
NCBI Accession
|
CBA18090.1
|
|
Location
|
2110-2367 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAAACCACATCTGCATGCCCTTGTTCAATTTGAAGGCAAGTTCCAGTGCACAAATTGCAGATTCTTCGATCTTAAACACCCAAACACCTCTTCCGTCGCCCATGCCAATATACAGGGTGCAAAGTCATCATCTGATGTCAAGTCCTACATCAAGAAGGACGGTGATTACATCGACTGGGGTACTTTTCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAGCTAATGACGCAGCATCAGAGGCGTTGA |
|
Protein Sequence
|
MGNHICMPLFNLKASSSAQIADSSILNTQTPLPSPMPIYRVQSHHLMSSPTSRRTVITSTGVLFRSTEDLLEEVSRQLMTQHQRR |