Sida common mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002823325.1 |
| Isolate |
Brazil |
| Release date |
2018/8/25 |
| Submitter |
Castillo-Urquiza,G.P., Beserra,J.E. Jr., Bruckner,F.P., Lima,A.T., Varsani,A., Alfenas-Zerbini,P., Murilo Zerbini,F., Beserra,J.E.A. Jr., Lima,A.T.M., Zerbini,P.A., Zerbini,F.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
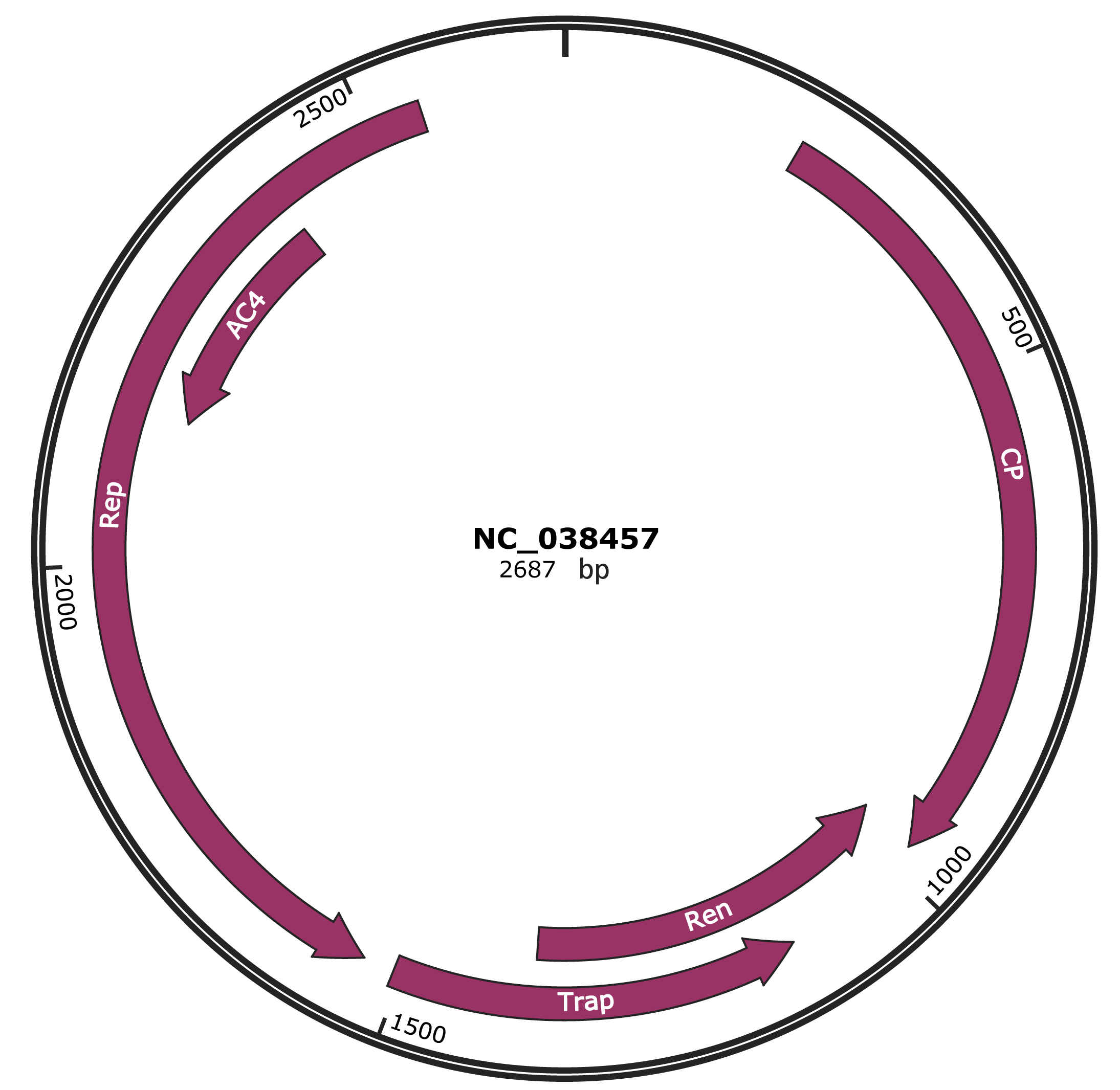
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCCCGACGGGGCGCTATGGTGGCCGCTCGATCTCTCTCTCCCGCGCGCTGTACTCCTTTAATTCTAATTAAAGGGCTAACTTTAGTTGGGACCAATGATAGTGCGCCTGGGAAGCCTAGATATCTGCGCGAGACTGGGGGCGGAAGTTGTTGATCAACGGCTATAAATTAAAGGAAGACGGATCACAGTCTTTTATTCAAAATGCCTAAGCGGGATCCCTCATGGCGTTCGATGGCGGGAACCTCAAAGGTAAGCCGCTCCTCCAATTTCTCTCCTCGTGGAGGCCCAAAGATCAACAAGGCCTCCGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATATACAGGACGCTGAGAACTCCTGATGTTCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCTTACGAGCAACGTCACGATATTTCCCATGTGGGGAAAGTGATGTGTATATCTGATGTGACACGAGGTAACGGTATCACTCACCGTGTCGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTATAGGTAAGGTATGGATGGACGAGAACATCAAGCTCAAAAACCACACGAACAGTTGTATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGTACACCGATGGACTTTGGCCAAGTTTTCAACATGTTCGACAACGAGCCCAGTACTGCAACAGTAAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTACGCCAAGGTCACTGGTGGTCAATATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAGGCAGGGAAATACGAGAACCACACTGAAAACGCTCTGTTACTGTATATGGCATGTACACATGCCTCTAATCCTGTGTATGCGACCCTTAAAATCCGGATCTATTTTTATGATTCGGTTTCAAATTAATAAATTTTGAATTTTATTGAATGCTTCTCCAGTACATGATTTACATAAGGCCTGTTCGTCGCGAAACGAACAGCTCTAATAACATTATTTATTGAGATTACACCTAATTGATCTAAATACAACATGACTAAATGCCTAAATCTATGTAAATATGTCATCCCAGAAGCCTTCACTGATGTCGTCCAGACTTGGAAGTTCAGGAATGCCTTGTGGAGACCCAACGCTCTCCTGAGGTTGTGGTTGAACCGTATCTGGTTGTGATACACTCTGGTCCCTGTGAACAGGATGTCTTCTACATGGTTGATCTTGAAATATAGGGGATTTGTTATCTCCCAGATATACACGCCATTCTCTGCTTGAGGAGCAGTGATGAACTCCCCTGTGCGTGAATCCATGGCTGTGGCAGTTGATGTGGACGTATATGGAGCACCCGCAATTTAGGTCGATCCTTCTACGGCGAGTTGCCCTCTTCTTCGCCGCTCTGTGTTGAACCTTGATAGAGAGGGGTTGTGAGGTTGACCAAAATACCATTATCCATGGCCCAACTCAATAAACCAAATATTACCTCTTTGCCCAAAAAACTCCTTTCTCTCGTAACCTCCCTTGATTCCTAAACATTATTGAGATTTTATAGCTGGAACCCTCACCTGGATTGCAGAGCACGATTGATGGGATACCACCTTTAATTTGAACTGGCTTTCCGTATTTACAATTTGATTGCCAGTCTTTTTGGGCCCCAATCAACTCTTTCCAGTGCTTTAGCTTTAGGTAATGCGGAGGGACGTCATCAATGACGTTATAATCCACTTCGTTCGAGTAAACCCTGGAATTGAAATCCAGGTGTCCACTAAGATAATTATGGGCCCCTAAAGCTCTAGCCCACATCGTCTTCCCCGTCCGACTATCACCTTCGATTATGATACTCACAGGCCTCTCTGGCCGCGCAGCGGAAACGACAAGCCCAAAATAGTCATCAGCCCAAGACTGCATCTCGTCCGGAACGTTAGTGAAAGAAGAGAGGGGAAACGGAGGAGTCCATGGCTCCGGAGCCTTTTTGAAAATTCTATCCAGGTTACTGGATAGGTTATGGTACTGGAAGAGGAACTTTTCCGGCATCTTTTCTTTGATAATCATCATCGCCTCCTCCTTTGTTCCAGCATTCAACGCTTCGGCGGCTACGTCGTTAGCCGTCTGCTGACCTCCTCTAGCACTTCTTCCGTCGATCTGGAACGTCCCCCATTCGACTGTATCACCATCTTTCTCGACGTAGGACTTGACGTCGGAGCTGGATTTAGCACCCTGTATGTTCGGATGGAAATGTGTTGACCTGGATGGGGATACCAAGTCGAACAGTCTGCTATTTGTGCAGTTGAACTTCCCTTCGAACTGAACGAGAACGTGGAGATGTGGCTGCCCATCTTCGTGTAGCTCTCTTGCAACCTTGATGAATTTCTTGTTGACCGGCGTTTGGATAACCCTAATTTGTTCGAGAGCTTCTTCTTTAGGAAGAGAGCACTGAGGATATGTAAGAAAATAATTTTTAGCTTTAATAGAGAAAGACCCCTTTCGTGGCATTTTTGTAAATATAGGTATGTACCCCCAATTGCTCTCGCCTCTAAAACTCTCATGAATTGGGGGAACTGGGGGAACTTATATATGAGAAGTTCCTAAGGTTAGATCTGCCACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506466.1
|
|
Location
|
228-977 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATCCCTCATGGCGTTCGATGGCGGGAACCTCAAAGGTAAGCCGCTCCTCCAATTTCTCTCCTCGTGGAGGCCCAAAGATCAACAAGGCCTCCGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATATACAGGACGCTGAGAACTCCTGATGTTCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCTTACGAGCAACGTCACGATATTTCCCATGTGGGGAAAGTGATGTGTATATCTGATGTGACACGAGGTAACGGTATCACTCACCGTGTCGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTATAGGTAAGGTATGGATGGACGAGAACATCAAGCTCAAAAACCACACGAACAGTTGTATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGTACACCGATGGACTTTGGCCAAGTTTTCAACATGTTCGACAACGAGCCCAGTACTGCAACAGTAAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTACGCCAAGGTCACTGGTGGTCAATATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAGGCAGGGAAATACGAGAACCACACTGAAAACGCTCTGTTACTGTATATGGCATGTACACATGCCTCTAATCCTGTGTATGCGACCCTTAAAATCCGGATCTATTTTTATGATTCGGTTTCAAATTAA |
|
Protein Sequence
|
MPKRDPSWRSMAGTSKVSRSSNFSPRGGPKINKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYIIGKVWMDENIKLKNHTNSCMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009506467.1
|
|
Location
|
974-1372 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTTCATCACTGCTCCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATAACAAATCCCCTATATTTCAAGATCAACCATGTAGAAGACATCCTGTTCACAGGGACCAGAGTGTATCACAACCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCAGTGAAGGCTTCTGGGATGACATATTTACATAGATTTAGGCATTTAGTCATGTTGTATTTAGATCAATTAGGTGTAATCTCAATAAATAATGTTATTAGAGCTGTTCGTTTCGCGACGAACAGGCCTTATGTAAATCATGTACTGGAGAAGCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEFITAPQAENGVYIWEITNPLYFKINHVEDILFTGTRVYHNQIRFNHNLRRALGLHKAFLNFQVWTTSVKASGMTYLHRFRHLVMLYLDQLGVISINNVIRAVRFATNRPYVNHVLEKHSIKFKIY |
|
NCBI Accession
|
YP_009506468.1
|
|
Location
|
1119-1508 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGGTATTTTGGTCAACCTCACAACCCCTCTCTATCAAGGTTCAACACAGAGCGGCGAAGAAGAGGGCAACTCGCCGTAGAAGGATCGACCTAAATTGCGGGTGCTCCATATACGTCCACATCAACTGCCACAGCCATGGATTCACGCACAGGGGAGTTCATCACTGCTCCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATAACAAATCCCCTATATTTCAAGATCAACCATGTAGAAGACATCCTGTTCACAGGGACCAGAGTGTATCACAACCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCAGTGAAGGCTTCTGGGATGACATATTTACATAG |
|
Protein Sequence
|
MVFWSTSQPLSIKVQHRAAKKRATRRRRIDLNCGCSIYVHINCHSHGFTHRGVHHCSSSREWRVYLGDNKSPIFQDQPCRRHPVHRDQSVSQPDTVQPQPQESVGSPQGIPELPSLDDISEGFWDDIFT |
|
NCBI Accession
|
YP_009506469.1
|
|
Location
|
1539-2552 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGAAAGGGGTCTTTCTCTATTAAAGCTAAAAATTATTTTCTTACATATCCTCAGTGCTCTCTTCCTAAAGAAGAAGCTCTCGAACAAATTAGGGTTATCCAAACGCCGGTCAACAAGAAATTCATCAAGGTTGCAAGAGAGCTACACGAAGATGGGCAGCCACATCTCCACGTTCTCGTTCAGTTCGAAGGGAAGTTCAACTGCACAAATAGCAGACTGTTCGACTTGGTATCCCCATCCAGGTCAACACATTTCCATCCGAACATACAGGGTGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGATGGTGATACAGTCGAATGGGGGACGTTCCAGATCGACGGAAGAAGTGCTAGAGGAGGTCAGCAGACGGCTAACGACGTAGCCGCCGAAGCGTTGAATGCTGGAACAAAGGAGGAGGCGATGATGATTATCAAAGAAAAGATGCCGGAAAAGTTCCTCTTCCAGTACCATAACCTATCCAGTAACCTGGATAGAATTTTCAAAAAGGCTCCGGAGCCATGGACTCCTCCGTTTCCCCTCTCTTCTTTCACTAACGTTCCGGACGAGATGCAGTCTTGGGCTGATGACTATTTTGGGCTTGTCGTTTCCGCTGCGCGGCCAGAGAGGCCTGTGAGTATCATAATCGAAGGTGATAGTCGGACGGGGAAGACGATGTGGGCTAGAGCTTTAGGGGCCCATAATTATCTTAGTGGACACCTGGATTTCAATTCCAGGGTTTACTCGAACGAAGTGGATTATAACGTCATTGATGACGTCCCTCCGCATTACCTAAAGCTAAAGCACTGGAAAGAGTTGATTGGGGCCCAAAAAGACTGGCAATCAAATTGTAAATACGGAAAGCCAGTTCAAATTAAAGGTGGTATCCCATCAATCGTGCTCTGCAATCCAGGTGAGGGTTCCAGCTATAAAATCTCAATAATGTTTAGGAATCAAGGGAGGTTACGAGAGAAAGGAGTTTTTTGGGCAAAGAGGTAA |
|
Protein Sequence
|
MPRKGSFSIKAKNYFLTYPQCSLPKEEALEQIRVIQTPVNKKFIKVARELHEDGQPHLHVLVQFEGKFNCTNSRLFDLVSPSRSTHFHPNIQGAKSSSDVKSYVEKDGDTVEWGTFQIDGRSARGGQQTANDVAAEALNAGTKEEAMMIIKEKMPEKFLFQYHNLSSNLDRIFKKAPEPWTPPFPLSSFTNVPDEMQSWADDYFGLVVSAARPERPVSIIIEGDSRTGKTMWARALGAHNYLSGHLDFNSRVYSNEVDYNVIDDVPPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKISIMFRNQGRLREKGVFWAKR |
|
NCBI Accession
|
YP_009506470.1
|
|
Location
|
2153-2395 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGCAGCCACATCTCCACGTTCTCGTTCAGTTCGAAGGGAAGTTCAACTGCACAAATAGCAGACTGTTCGACTTGGTATCCCCATCCAGGTCAACACATTTCCATCCGAACATACAGGGTGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGATGGTGATACAGTCGAATGGGGGACGTTCCAGATCGACGGAAGAAGTGCTAGAGGAGGTCAGCAGACGGCTAACGACGTAG |
|
Protein Sequence
|
MGSHISTFSFSSKGSSTAQIADCSTWYPHPGQHISIRTYRVLNPAPTSSPTSRKMVIQSNGGRSRSTEEVLEEVSRRLTT |