Sida ciliaris golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002823305.2 |
| Isolate |
Venezuela:Lara |
| Release date |
2020/7/3 |
| Submitter |
Zambrano,K.A., Marys,E.E., Mendez,N. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
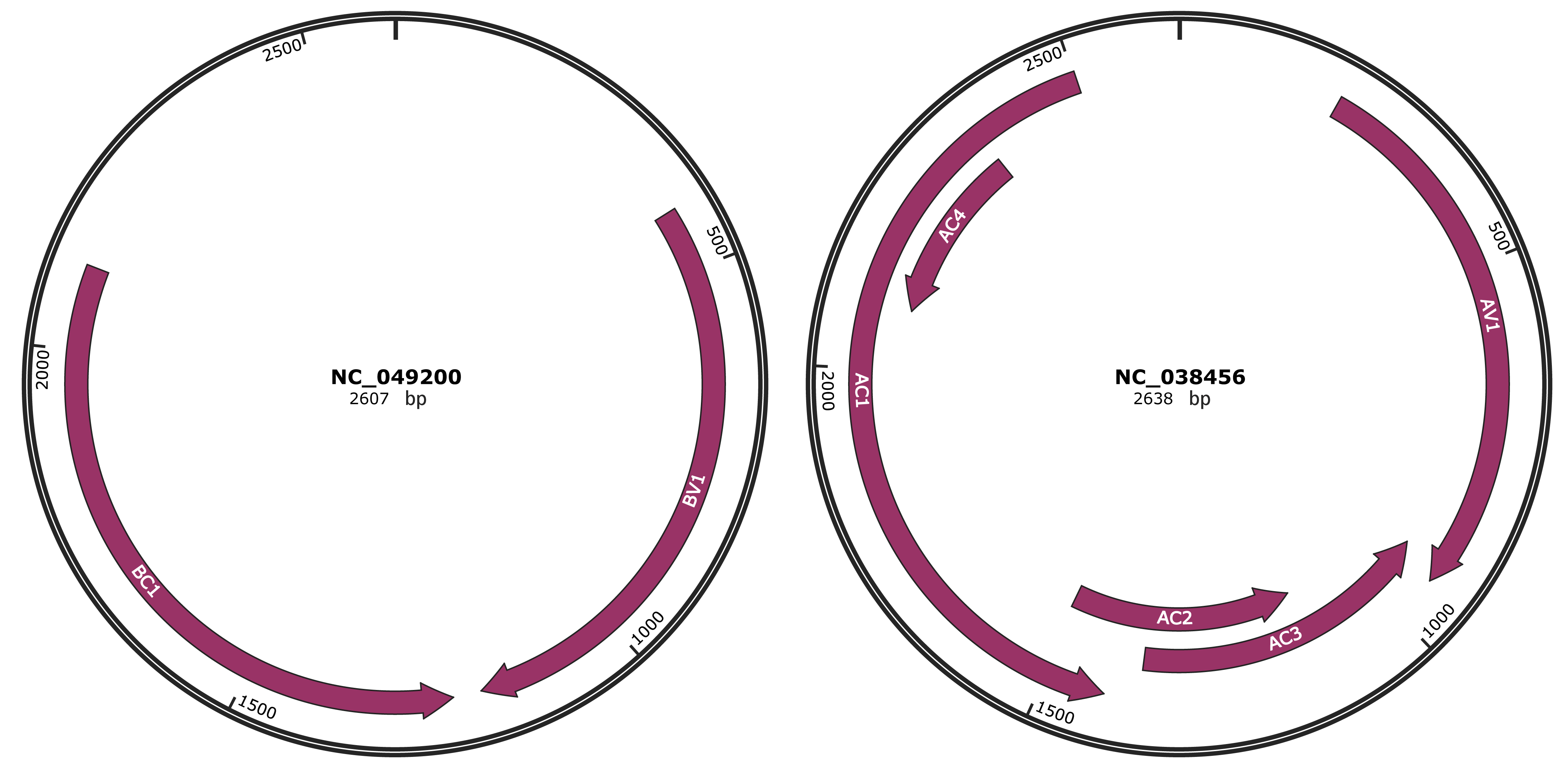
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTCCCCCCCCCCCTACGTGGAGCTCTGGTGGCCGTTCGATCCCTGGTGCTGGTGTTCCCAACGCTCCCACCCGCTCCTACGCGCGCTCCCATTGGTGCGGGTAACTCACTCACGCTTTTGAGTCTGGACTTTAATTTGAATTAAAGTCTACAACTTTATGTCGCGCGACTTGATTTGAAGTGTGAATCTTCACCCCGCGACGACTAAGTATGGCCCATTGTACCCCCTTAAGTACGTGGCGGATTTCTGTCCAAGTTGCTGAGTCAGTATAAGTTCCCAGTCTAACGACCCTTGTCTATATAATTGATGTGTATGATATATTATATTCAAGTGACTCAGCTGTTTACCACGTTTATTTTATCAACTGCATTTATTATTTAGCCAGTGTTATCTCGGGATAATGTATATTATTAGGAATAAACGTGGTTCCTCTTCTACCCAGCGACGGTATTATCCACGTAACTCAGTGTCTAATCGTTCAACCATTTCCCGAAGACATGACTTCAAGCGTCGAGCTGGGTATGGTAGCAAGCCCACTGATGAGCCCAAGATGACAAGCCAACGCATCCATGAGAATCAGTATGGCACTGATTTTGCTATGGCCCATAACACAGCTGTCCAAACATTCATCAGCTACCCTTCTATCTCCAAGTCTCTACCGAACAGAACCCGGTCATACATCAAGTTGAAACGACTTCGTTTCAAGGGAACGGTGAAGATTGAACGCGTCCCGACTGACGTTAACATGGACTGTTCAGCCCCGAAGACCGAAGGTGTCTTCTCCTTGGTTGTAGTCGTTGATCGGAAGCCCCACTTGACACCTGCTGGTGGTCTACATACGTTCGATGAACTGTTCGGTGCAAGGATCAACAGCCACGGTAATTTATGTATAAGTCCCTCATTGAAGGACCGTTTCTACATACGCCACGTGTTGAAACGCGTGTTGTCAGTCGAGAAGGATACGGTTATGGTGGACATCGAAGGATCCACTCCTCTCTCTAACAGGCGTTTTAATTGCTGGGCTACGTTTAAGGATCTAGATATTGAGACACGCAAGGGTGTTTATGACAACATAAGCAAGAACGCCCTGTTAGTTTATTATTGCTGGATGTCGGATACTGTATCTAAGGCATCGATATTTGTATCGTATGACCTCGATTATATTGGATAGTTAATAATGACAGGCAATAATTATAATCATAAAAAATTTATTTAAAATTTTTTGGCTCTGATCGACTACAATTACTCTTAATACATTCCTGCACCGTTGTCCTGACAAGGTCGTTTAATTGGGCAACTGACATTGTAATGTTGGACTCGGCCCTCTTTGCCCCAACTATTGAAGCAGACTCCCCTGGATCCAGTGCGCTGGTTCCCAATCTGTGAAGCTCTCTGTACGGATGGATCTCGTTCTCCACCTCTGAATCCGCGTCTGATGGCCCAAGTCCAATGGTGCTTCTTGAAGCCCAAGACTCGCCAGGCTTGATCTCAATTGGGCCTCTGAGCCCAAGTCTGGACATAGACGCGCATCTCAAGGCCTTCCTTTCCCATCGTCCGTAATCCACGTGGGAGAAATCTACATCCTTCTCCGAGAACTGTTTGGAAAGGATTTTGACAGTCGGCGCTTTGAAGGGGATATCGACTGAGTGTTTCGCCGTCGATAATTTCAGTTTCCCTTTGAATTTCGCGAAGTGGGTCCTTTGGTGAACATTCGTGTCGGAAACTCTGTAATAGAGTTTCCATGGAATTGGGTCTTTGAGGGAGAAGAAGGACGATGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCACGACGCTTGTAGCGACTCGTTGTCGGTCATTCTCTGGTCATGAATCTCCACTATAACAGTACCGGCGGCGTTGATAGGCACTTGCTGCCTGTACTCTATGACGCAGTGGTCAATCTTCATACAGCTACGACTGAGCCTTGCAGTCAACTGAGCCGCCGTTGAAGGAAATTGGAGGATGATCTCAGTTAGGTCATGAGAAAGCTGATACTCATCCCGATGAGACTCTATGTAGTTGAAGGCACTTGGAGGATTAACTAACTGAGACTCCATTTGAAGAAAATGGCCGCGCAGCGGAACGGAATCTGAAGTTGAACAAGGAATAAGGTGAACAAGAGAAAGATGAACAAGGAAAAGGTGAACAAGGAAGAAAATGAACCAAAACAGCTGTTTTGGGTGGTTATGAGATCTACGAGATGGATATCGTCTAAGTTTTCTTATTTTGAGAAAGAAAAGGGAGTTGAGGAAGAAGTTGAGGATGATGATAATCTATTTCTGAAGGTGTTTATATAGGAACCCAGATGTTCTGGGAAATTAGGTTTTGGAATTGGGAAAGTGCTTTTCTTTGCTAAGAGAGCACTTTGGATATGTTAGGAAATAGTTTTTCTGATTTATCTGGAAACGCTTCGATGGCATTTTTGTAATAAGAGGGGTGTGTACCAATTGAGCTCTCTCTCAAAACTCCATATGAATTGGTACACAGGTACACAATATATAGTAGAACCCTCATTCACGGATTTGCACCACGTGGCGGCCATCCGATCTAATATT
ACCGGATGGCCGCGCGATTTTTCCCCCCCCTACGTGGAGCTCTGGTGGCCGCGCGATCCCCTCGCGCTTTTCCTTTAATTTGAATTAAAGCGGACAGCTTTCGTCTTGTCCAATGATATTGCGCCTGTCGCATCTAGATATCTGCAACAACTTGGGCCCTAAGTTGTTGGCCGGTTATAAATTAAAGGTTTATTGGGCCACATTCTTTAAGTCAAAATGCCTAAGCGGGAAGCCCCATGGCGTTCTATGGAGGGAACCTCAAAGGTTAGCCGCAACGNTAATGACTCTCCTCGTGCAGGAATTGGTGGCCCAAAGATCACACGGGCCTCAGAATGGGTCAACAGGCCTAGGGACAGGAAGCCCAGGATCTTCCGGACTTTGAGGACTTCAGATGTCCCTCGAGGGTGTGAAGGCCCGTGTAAGGTACAGTCATTCGAACAGCGCCACGACATCTCACATGTCGGGAAGGTAATGTGCATCTCTGACGTTACACGTGGTAATGGTATTACCCACCGTGTCGGCAAGCGTTTTTGTGTCAAGTCTGTATATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAATCACACAAACAGTGTGATGTTCTGGTTGGTTAGAGACCGTAGACCGTATGGAACCCCTATGGATTTCGGGCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACGGTGAAGAACGATCTCCGTGATCGTTTCCAGGTCATGCACAAGTTCTATGGCAAGGTCACAGGTGGACAGTACGCCAGCAATGAACAGGCTATTGTTAAGAGGTTCTGGAAAGTCAACAACTACGTTGTCTACAATCATCAAGAGGCTGCAAAATACGAGAATCATACGGAGAACGCGTTATTATTGTACATGGCATGTACACATGCCTCTAAACCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTCTATGATTCGATTCTGAATTAATAAAATTTGAATTTTATTGAATGATCTTTCCAGTACATGACTTACATACGGTTTGGCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAATCGAGATCACGCCTAACTGATCAAGATACATATTAACTAAGTGCCTAAATCTAGCTAAATAGGTCGACCCAGAAGCTGTCAGGGATCTCGTCCAGACTTGGAAGTTCAGGAAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGGATTTGTATGCTGTACACCCTGCTCGTGGTGTATAGTGGATCCTCTACTCTGTACATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGACGTGCAGTGATGATTTCCCCTGTGCGTGAATCCATGGCCCGTGCAGTCTATGTGGAAGTAGATGGAGCAACCGCACTGAAGATCAATCCTCCTTCTCCTGATTGCCCTCCTCTTGGCTCGTCTGTGTGCTTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGACCGCATTCTTTAGAGTCCAGTTCCTGAGGGAGGTGTTTTCCTCCTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAGAGCACGATTGCTGGGATCCCACCTTTAATTTGAACTGGCTTGCCGTACTTGCAATTTGACTGCCAATCCTTTTGGGCCCCGAGTAGTTCTTTCCAGTGCTTTAGCTTTAGGTAATGCGGAGCGACGTCATCAATGACGTTATAATCCACATCGTTCGAGAACACTCGGGCATTGAAGTCAAGGTGACCGCTGAGATAATTATGTGGACCCAACGCACGAGCCCACATCGTCTTCCCCGTCCTCGAGTCACCTTCAACAATCAAACTTACTGGTCTTACTGGCCGCGCAGCGGGACTGCTCCCAAAATAATCATCCGCCCACTCTTGCATCTCGTCGGGCACGTTAGTGAAAGAGGAGAGTTGAAACGGAGGAACCCATGGCTCCGGAGCCTTTGCGAATATCCTTTCGAGGTTGGAGCGGATGTTATGATTCTGCAGGACAAAGTCTTTTGGCTGCTCCTCCTTTAACACCCGCATGGCAGATTCAACAGAATCTGCATTTAACGCCTTGGCATATGAATCATTAGCAGACTGCTGGCCTCCTCTAGCAGATCTGCCGTCGATCTGGAATTCTCCCCATTCAACTGTGTCTCCGTCCTTCTCGAGATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCGGGTTGGGGAGACCAGATCGAAGAATCTGCTATTCGTGCACCTGTATTTGCCCTCGAACTGGATAAGTACATGGAGATGAGGCTCACCATTTTCATGCAGTTCTCGGCAGATCTTGATGAACTTCTTGTTCACCGGAGTGGATAGGTTTTTAATTTGGGAAAGTGCTTCTTCTTTGCTAAGAGAGCACTTTGGATATGTTAGGAAATAGTTTTTCTGATTTACCTGGAAACGCTTCGATGGCATTTTTGTAATAAGAGGGGTGTGTACCAATTGAGCTCTCTCTCAAAACTCCATATGAATTGGTACACAGGTACACAATATATAGTAGAACCCTCATTCACCGATTTGCACCACCGTGGCGGCCATCCGCTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009873670.1
|
|
Location
|
420-1190 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATATTATTAGGAATAAACGTGGTTCCTCTTCTACCCAGCGACGGTATTATCCACGTAACTCAGTGTCTAATCGTTCAACCATTTCCCGAAGACATGACTTCAAGCGTCGAGCTGGGTATGGTAGCAAGCCCACTGATGAGCCCAAGATGACAAGCCAACGCATCCATGAGAATCAGTATGGCACTGATTTTGCTATGGCCCATAACACAGCTGTCCAAACATTCATCAGCTACCCTTCTATCTCCAAGTCTCTACCGAACAGAACCCGGTCATACATCAAGTTGAAACGACTTCGTTTCAAGGGAACGGTGAAGATTGAACGCGTCCCGACTGACGTTAACATGGACTGTTCAGCCCCGAAGACCGAAGGTGTCTTCTCCTTGGTTGTAGTCGTTGATCGGAAGCCCCACTTGACACCTGCTGGTGGTCTACATACGTTCGATGAACTGTTCGGTGCAAGGATCAACAGCCACGGTAATTTATGTATAAGTCCCTCATTGAAGGACCGTTTCTACATACGCCACGTGTTGAAACGCGTGTTGTCAGTCGAGAAGGATACGGTTATGGTGGACATCGAAGGATCCACTCCTCTCTCTAACAGGCGTTTTAATTGCTGGGCTACGTTTAAGGATCTAGATATTGAGACACGCAAGGGTGTTTATGACAACATAAGCAAGAACGCCCTGTTAGTTTATTATTGCTGGATGTCGGATACTGTATCTAAGGCATCGATATTTGTATCGTATGACCTCGATTATATTGGATAG |
|
Protein Sequence
|
MYIIRNKRGSSSTQRRYYPRNSVSNRSTISRRHDFKRRAGYGSKPTDEPKMTSQRIHENQYGTDFAMAHNTAVQTFISYPSISKSLPNRTRSYIKLKRLRFKGTVKIERVPTDVNMDCSAPKTEGVFSLVVVVDRKPHLTPAGGLHTFDELFGARINSHGNLCISPSLKDRFYIRHVLKRVLSVEKDTVMVDIEGSTPLSNRRFNCWATFKDLDIETRKGVYDNISKNALLVYYCWMSDTVSKASIFVSYDLDYIG |
|
NCBI Accession
|
YP_009873671.1
|
|
Location
|
1228-2109 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGAGTCTCAGTTAGTTAATCCTCCAAGTGCCTTCAACTACATAGAGTCTCATCGGGATGAGTATCAGCTTTCTCATGACCTAACTGAGATCATCCTCCAATTTCCTTCAACGGCGGCTCAGTTGACTGCAAGGCTCAGTCGTAGCTGTATGAAGATTGACCACTGCGTCATAGAGTACAGGCAGCAAGTGCCTATCAACGCCGCCGGTACTGTTATAGTGGAGATTCATGACCAGAGAATGACCGACAACGAGTCGCTACAAGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCATCGTCCTTCTTCTCCCTCAAAGACCCAATTCCATGGAAACTCTATTACAGAGTTTCCGACACGAATGTTCACCAAAGGACCCACTTCGCGAAATTCAAAGGGAAACTGAAATTATCGACGGCGAAACACTCAGTCGATATCCCCTTCAAAGCGCCGACTGTCAAAATCCTTTCCAAACAGTTCTCGGAGAAGGATGTAGATTTCTCCCACGTGGATTACGGACGATGGGAAAGGAAGGCCTTGAGATGCGCGTCTATGTCCAGACTTGGGCTCAGAGGCCCAATTGAGATCAAGCCTGGCGAGTCTTGGGCTTCAAGAAGCACCATTGGACTTGGGCCATCAGACGCGGATTCAGAGGTGGAGAACGAGATCCATCCGTACAGAGAGCTTCACAGATTGGGAACCAGCGCACTGGATCCAGGGGAGTCTGCTTCAATAGTTGGGGCAAAGAGGGCCGAGTCCAACATTACAATGTCAGTTGCCCAATTAAACGACCTTGTCAGGACAACGGTGCAGGAATGTATTAAGAGTAATTGTAGTCGATCAGAGCCAAAAAATTTTAAATAA |
|
Protein Sequence
|
MESQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDQRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFKAPTVKILSKQFSEKDVDFSHVDYGRWERKALRCASMSRLGLRGPIEIKPGESWASRSTIGLGPSDADSEVENEIHPYRELHRLGTSALDPGESASIVGAKRAESNITMSVAQLNDLVRTTVQECIKSNCSRSEPKNFK |
|
NCBI Accession
|
YP_009506461.1
|
|
Location
|
217-939 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCTAAGCGGGAAGCCCCATGGCGTTCTATGGAGGGAACCTCAAAGGTTAGCCGCAACGNTAATGACTCTCCTCGTGCAGGAATTGGTGGCCCAAAGATCACACGGGCCTCAGAATGGGTCAACAGGCCTAGGGACAGGAAGCCCAGGATCTTCCGGACTTTGAGGACTTCAGATGTCCCTCGAGGGTGTGAAGGCCCGTGTAAGGTACAGTCATTCGAACAGCGCCACGACATCTCACATGTCGGGAAGGTAATGTGCATCTCTGACGTTACACGTGGTAATGGTATTACCCACCGTGTCGGCAAGCGTTTTTGTGTCAAGTCTGTATATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAATCACACAAACAGTGTGATGTTCTGGTTGGTTAGAGACCGTAGACCGTATGGAACCCCTATGGATTTCGGGCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACGGTGAAGAACGATCTCCGTGATCGTTTCCAGGTCATGCACAAGTTCTATGGCAAGGTCACAGGTGGACAGTACGCCAGCAATGAACAGGCTATTGTTAAGAGGTTCTGGAAAGTCAACAACTACGTTGTCTACAATCATCAAGAGGCTGCAAAATACGAGAATCATACGGAGAACGCGTTATTATTGTACATGGCATGTACACATGCCTCTAAACCCTGTGTATGCAACGCTTAA |
|
Protein Sequence
|
MPKREAPWRSMEGTSKVSRNXNDSPRAGIGGPKITRASEWVNRPRDRKPRIFRTLRTSDVPRGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASKPCVCNA |
|
NCBI Accession
|
YP_009506462.1
|
|
Location
|
914-1372 |
|
Gene Name
|
AC3 |
|
Protein Name
|
Ren |
|
Coding Region
|
ATGGATTCACGCACAGGGGAAATCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATGTACAGAGTAGAGGATCCACTATACACCACGAGCAGGGTGTACAGCATACAAATCCGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGAGATCCCTGACAGCTTCTGGGTCGACCTATTTAGCTAGATTTAGGCACTTAGTTAATATGTATCTTGATCAGTTAGGCGTGATCTCGATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGCCAAACCGTATGTAAGTCATGTACTGGAAAGATCATTCAATAAAATTCAAATTTTATTAATTCAGAATCGAATCATAGAAATAGATCCGAATCTTAAGCGTTGCATACACAGGGTTTAG |
|
Protein Sequence
|
MDSRTGEIITARQAENGVYIWEIENPLYFKMYRVEDPLYTTSRVYSIQIRFNHNLRRALHLHKAFLNFQVWTRSLTASGSTYLARFRHLVNMYLDQLGVISINNVIRAVRFATAKPYVSHVLERSFNKIQILLIQNRIIEIDPNLKRCIHRV |
|
NCBI Accession
|
YP_009506463.1
|
|
Location
|
1119-1508 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAAGCACACAGACGAGCCAAGAGGAGGGCAATCAGGAGAAGGAGGATTGATCTTCAGTGCGGTTGCTCCATCTACTTCCACATAGACTGCACGGGCCATGGATTCACGCACAGGGGAAATCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATGTACAGAGTAGAGGATCCACTATACACCACGAGCAGGGTGTACAGCATACAAATCCGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGAGATCCCTGACAGCTTCTGGGTCGACCTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKKAHRRAKRRAIRRRRIDLQCGCSIYFHIDCTGHGFTHRGNHHCTSGREWRVYLGDRKSPLFQDVQSRGSTIHHEQGVQHTNPVQPQPEESVASPQSLPELPSLDEIPDSFWVDLFS |
|
NCBI Accession
|
YP_009506464.1
|
|
Location
|
1420-2502 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCATCGAAGCGTTTCCAGGTAAATCAGAAAAACTATTTCCTAACATATCCAAAGTGCTCTCTTAGCAAAGAAGAAGCACTTTCCCAAATTAAAAACCTATCCACTCCGGTGAACAAGAAGTTCATCAAGATCTGCCGAGAACTGCATGAAAATGGTGAGCCTCATCTCCATGTACTTATCCAGTTCGAGGGCAAATACAGGTGCACGAATAGCAGATTCTTCGATCTGGTCTCCCCAACCCGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATCTCGAGAAGGACGGAGACACAGTTGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCTGTTGAATCTGCCATGCGGGTGTTAAAGGAGGAGCAGCCAAAAGACTTTGTCCTGCAGAATCATAACATCCGCTCCAACCTCGAAAGGATATTCGCAAAGGCTCCGGAGCCATGGGTTCCTCCGTTTCAACTCTCCTCTTTCACTAACGTGCCCGACGAGATGCAAGAGTGGGCGGATGATTATTTTGGGAGCAGTCCCGCTGCGCGGCCAGTAAGACCAGTAAGTTTGATTGTTGAAGGTGACTCGAGGACGGGGAAGACGATGTGGGCTCGTGCGTTGGGTCCACATAATTATCTCAGCGGTCACCTTGACTTCAATGCCCGAGTGTTCTCGAACGATGTGGATTATAACGTCATTGATGACGTCGCTCCGCATTACCTAAAGCTAAAGCACTGGAAAGAACTACTCGGGGCCCAAAAGGATTGGCAGTCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGTGGGATCCCAGCAATCGTGCTCTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAGGAGGAAAACACCTCCCTCAGGAACTGGACTCTAAAGAATGCGGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAAGCACACAGACGAGCCAAGAGGAGGGCAATCAGGAGAAGGAGGATTGA |
|
Protein Sequence
|
MPSKRFQVNQKNYFLTYPKCSLSKEEALSQIKNLSTPVNKKFIKICRELHENGEPHLHVLIQFEGKYRCTNSRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYLEKDGDTVEWGEFQIDGRSARGGQQSANDSYAKALNADSVESAMRVLKEEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFQLSSFTNVPDEMQEWADDYFGSSPAARPVRPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNARVFSNDVDYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLNKEENTSLRNWTLKNAVFITLTAPLYQESTQTSQEEGNQEKED |
|
NCBI Accession
|
YP_009506465.1
|
|
Location
|
2091-2354 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAAAATGGTGAGCCTCATCTCCATGTACTTATCCAGTTCGAGGGCAAATACAGGTGCACGAATAGCAGATTCTTCGATCTGGTCTCCCCAACCCGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATCTCGAGAAGGACGGAGACACAGTTGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MKMVSLISMYLSSSRANTGARIADSSIWSPQPGQHISIQTYRELNPAPTSSPISRRTETQLNGENSRSTADLLEEASSLLMIHMPRR |