Sida chlorotic vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001777265.1 |
| Isolate |
Brazil |
| Release date |
2016/10/19 |
| Submitter |
Passos,L.S., Teixeira,J.W.M., Lima,K.J., Rodrigues,J.S., Soares,E.C.S., Xavier,C.A.D., Araujo,A.S.F., Zerbini,F.M., Beserra,J.E.A. Jr. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
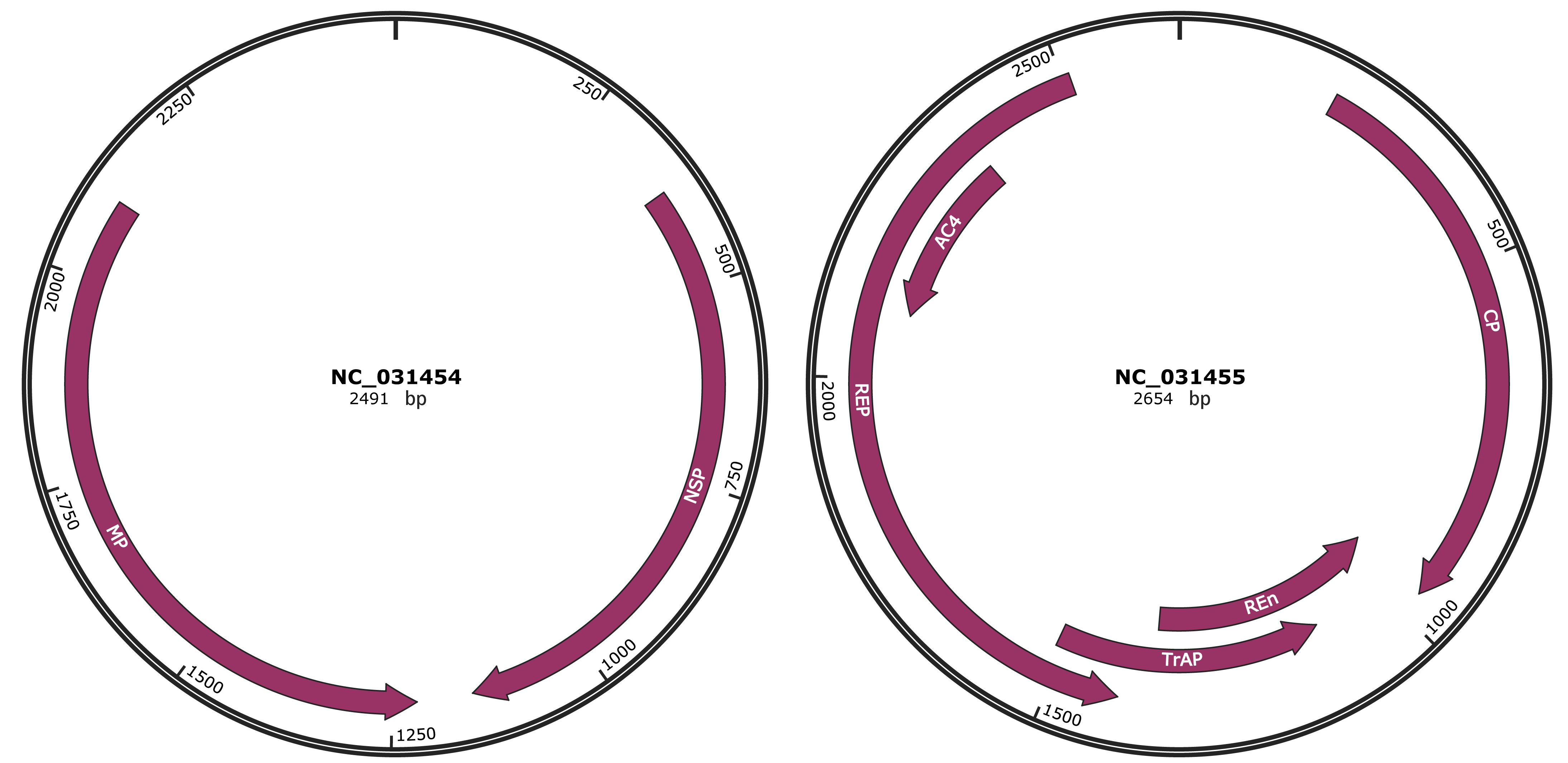
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCCCCTACGTGGCGGCGGGAAGGCCGCCCGATTCCCTCCCCTCCCCACGTGGCGCTCTGGTGTCCTCAGGATGTAACGCTCCGAATTCACGCCCAGGACCATTGGATAAAAATAAGGTGTGATCGAACGGGGATTGAAAATTTGAATTGACATGGCGCGTCCCGTCACCATGAGTCATTTTACATAACCCTTGAATGATACGTGGAGCTGTACTATGTATAAGTGACGTGGACCAGTTACATTTCAAATGCGGAGTTATTTAAGGTTATATATTGAACCAGGAAATTATATTTAAATTTCTTATTGAACGAGCTGGATACCTCATCCAGTATTAGATTAATCCATTTGAACATGTACTCGGTTAAATATAGACGTGGATCGTCCTATACTCAGCGACGAGGTTATTCAAGGAAGACGGTATTTAGACGATCGTATGGTGTTAAACGAAGCGATGATAAGCGACGTGCGAGTCAATCGTCAAAGGGTCACGATGATGGGAAGATTTCAGCCCAACGGATACATGAGAACCAGTTTGGGCCTGAATTTGTTATGGCCCATAATTCAGCCATATCAACGTTCATTAGCTTCCCCAATCTCGGGAAGACCGAACCGAACCGGTCAAGGTCCTATATTAAGTTGAAACGGTTACGTTTCAAGGGTACTGTGAAGATCGAACGTGTTCATGCCGATGTCAACATGGACGGTTCAACCCCAAAGACCGAAGGAGTCTTCTCTCTTGTTGTCGTTGTCGACCGTAAACCTCATCTGAGCTCGTCTGGATGTCTGCACACATTTGACGAGTTATTCGGTGCAAGGATCCACAGCCATGGTAATTTAGCGATCGCACCGTCGTTGAAGGATCGTTTCTACATAAGGCACGTGTCGAAACATGTGTTATCGGCAGAGAAAGACACGATGATGGTGGACCTGGAGGGAGCGACGTGGTTGTCTAACAGGCGTTTTAATTGTTGGTCTAGTTTTAAGGACCTTGATCATGACACGTGTAATGGGGTTTATGCGAACATTAGCAAGAACGCCCTGTTAGTTTATTACTGCTGGATGTCGGATATTATGTCCAAGGCATCGACATTTGTATCGTTTGATCTCGACTATGTCGGGTGATTAAGAATATTAATATGCAATTAATACAACTCGTACTCATCTCTAATAATAATTATCAATTTATTTATAATTATTTCAAAGATTTGGGTTGGGAGGGAATACAGTTGGTGTTAATACATTCTTGGACCGTGGACCTGACAATGTCGTTTAATTGGGCCAGCGACAGCGTTATGTTCGATTGAGACCTCTGGGTCCCTACGATCGAGGCTGAGTCACCTGGGTCCAAGACTGTAGTCTGTAGCCTGTTAAGCTCTCGGTACGGGTGTAAGGCCTCTCCCAAGTCCGATCCCGCATCGGATTGATTGGGCCCTATCATGCTCCTGATAGCCCAGGACTCTCCTGGCCTTATTTCGATTGGGCTTGGAAGCCCAACTCTTGATGTGGATGCGGATCGGACTGGTTTCCTCTCCCATCTCCCGTAGTCGACGTGGCAAAAGTCCACATCTTTATCGGTGAACTGTTTCGACAGGATCTTCACCGTCGGAGCCCTGAAAGGAATATCCACAGAGTGTTTGGCCGTCGACAGCTTCAATTTCCCCTTGAACTTGGCGAAATGCGTCCTCTGATGAACATTCGTATCGCAGACCTTGTAATAGAGCTTCCATGGAATTGGGTCTTTCAAGGAGAAGAAAGAGGACGAGAAGTAGTGGAGATCTATGTTGCATCTGATCGGGAAAGTCCACGACGCCTGTAAAGACTCGTTGTCCGTCATCCTCTTGTCGTGAATCTCCACTACCACCGACCCTGTGGCGTTGATTGGGACCTGCTGACGGTATTCGATCACGCAATGATCGATCTTCATACAGCTCCGACTTAGCCTGGCGCTTATTTGTGACGCCGTCGAAGGAAATTGCAGGATGATCTCTGTCAGATCATGTGACAACTGATACTCGTCACGGTGCGATTCTATATAATTAAAGGCACTGGGAGCATTCATCAGCTGAGATTCCATTGAGAAAGAAGGGAGCGCAGCGACCGCGTCTGAGTGAAGTGAAACAGATGAGATACTGATTGAGGAAGAAGATGGTAGCTGAATTAGGGATTCAGATATACAAGAGGAAAGTTGAACCCTATTAACGAGAGCAGTACTGTTTATGATAGGAAGGGGAAATTGAATTAGGGATTGAAATAGTGAATAAGTGAAGTAAATGAGTAAAGTGAACCGCGGGTTATTTATAGAGAAGTCAGTTCAGTGGCATATTTGTACATATGAGGGTTTACTCCAATGGACCTGTTATATAAAACTCCCTATGAATGGGCCTAAAAGAGTACAATTTATAGTGGAAGTTCATATGGAACTTTGGAGGATACGCACATAAGTGGCGTCCATCCGTTATAATATT
ACCGGATGGCCGCGCGATTTTTCCCCCCCCCCACGTGGCGCTCTGGTGGCCGCGCGATCTCCCCTCCTGCCGCTCGCGCGAATTTAAATTAAAGCCCTGCCCAATCATATTGGGCCTGAGTAGCTTATTTAATTTGCAACAACTTCCGGCCCAAGTTGTTGTTTGAGGGCTATAAATTTATAGCCTAATTGTTATGAGGCTTTAATTCAAGATGCCTAAACGGGAAGCCCCATGGCGCCTGATGGCGGGAACGACCAAGGTTAGTCGATCTACTGGCTATTCATCTCGTTTAGCTTCCCAGCCCAGAGTCAACAAGGCCCAAGAATGGGTGAACAGGCCTATGTACAGGAAGCCCAGGATATATAGGGCTATGAGGACACCTGATGTCCCTAGAGGGTGTGAGGGGCCTTGTAAGGTCCAGTCCTACGAGCAGCGGCATGATATCTCTCATGCCGGGAAGGTGATCTGTATATCTGATGTCACACGTGGCAGTGGTATCACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCTGTATACATATTAGGCAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACAGACGACCGAACGGTACGCCCATGGATTTCGGACATTTATTTAACATGTTCGACAACGAGCCCAGCACCGCTACGGTCAAGAACGATCTCCGTGATCGTTTCCAGGTTTTGCACAGGTTCTATGCTAAGGTCACAGGTGGTCAGTATGCCAGCAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAACAACCATGTGGTGTACAACAACCAGGAAGCCGCTCGATACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCCGTGTATGCTACGCTTAAGATTCGAATCTACTTCTACGATTCGATAACAAATTAATAAATTTTGAATTTTATTGAATGATTCTCGAGCACATAATTTACATAAGACTTATCCGTTGCGAAACGAACAGCTCTAATTACATTGTTAAGACAAATTACACCTAATTGATCAAGATACAACAAGACAAGGTGCCTAAACCTACTTAAATAAGTCTTCCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAATTCAAATAGGCCTTGTGGAGATGCAACGCTTTCCGCAGGTTGTAGTTGAACCGTATTTGGATGTGATACACTCGGGTCCTTGTGAACAGGAGGTCTTCGACCCTGTATATCTTGAAATACAGGGGATTTGTTATTTCCCAGGTATAGACGCCACTCTCCGCCTGATGTGCAGTGATGCTCTCCCCGGTGCGTGAATCCATGCCCCGTGCAGTTTATGTGGACGTATATGGAGCAGCCGCACTCGATGTCAATGCGTCGCCTCCTGATGGCCCTCGTCTTGGCCTGCCTCTTCTTGGCAATCCTGTGTTGCTGCTTGATAGAGGGGGGAGTCGAGGAAGATGAATTTAACATTGTGGAGTGTCCACGACCTCAAGGCTGCATTTTCCTCTTTGTCCAGGAAGTCTTTATAACTGGCCCCCTCTCCAGGATTGCAGAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCTCTTTGGGACCCGAGGAGCTCTTTCCAGTGCTTTAGCTTTAGGTAGTGCGGAGGGACGTCATCAATGACGTTATACTCAGCCTCGTTGGAAAAGACCCTGGAATTGAAATCCAGGTGTCCACTGAGATAATTGTGGGACCCTAAAGCACGTGCCCACATCGTCTTCCCCGTTCGACTGTCACCTTCGACGATGATACTAACAGGCCTGACAGGCCGCGCAGCGGCATCTCTCGCAAAATAGTCATCGGCCCACTCCTGCATCTCGTCCGGGACGTTAGTGAACGAGGACAGTCGAAAAGGAGGAGTCCATGGCTCCGGCGCCTTTTTGAAAATCCTGTCCAGGTTGCTCGACAGATTATGGTACTGGAACAGGAACTTTTCCGGCAACTTTTCTTTGATGATTTTCATGGCCTCCTCCTTCGACGGAGCGTTCAGTGCCTCGGCGGCTGCGTCGTTAGCTGTCTGCTGGCCGCCTCTAGCACTTCGACCGTCGACCTGGAACTCTCCCCATTCGATGGTGTCCCCGTCCTTCTCGACATAGGACTTGACGTCGGAGCTGGATTTAGCTCTCTGTATGTTCGGATGGAAATGTGCTGACCGGGAAGGGGACACCAGATCGAACAGTCTGTTATTTGTGATCTGGACTTTCCCTTCGAGTTGTAGGAGAATATGGAGGTGAGGTTGCCCATCGTCGTGAAGCTCTCTGGCGATTTTGATGAACTTCTTGTTCGAAGGGAGATGGATACTCTGTAATTGGGAAAGTGCTTCTTCTTTTGACAGAGAGCACTGTGGATAAGTGAGGAAGATATTTTTAGCCTGGAGTCTAAATCGTTTGGGCGGTGGCATTTTTGTAAATAAGAGGTGTACTCCAATTGAGCTCCTCTCTCAAACTCTCATATCAATTGGAGTAAAAGAGTACAATTTATACTAGAAGTGCTTATAGAACTTTGAAGGATCTGCACACACGTGGCGGCCATCCGTAATAATATT
Gene Information
|
NCBI Accession
|
YP_009310075.1
|
|
Location
|
378-1148 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTACTCGGTTAAATATAGACGTGGATCGTCCTATACTCAGCGACGAGGTTATTCAAGGAAGACGGTATTTAGACGATCGTATGGTGTTAAACGAAGCGATGATAAGCGACGTGCGAGTCAATCGTCAAAGGGTCACGATGATGGGAAGATTTCAGCCCAACGGATACATGAGAACCAGTTTGGGCCTGAATTTGTTATGGCCCATAATTCAGCCATATCAACGTTCATTAGCTTCCCCAATCTCGGGAAGACCGAACCGAACCGGTCAAGGTCCTATATTAAGTTGAAACGGTTACGTTTCAAGGGTACTGTGAAGATCGAACGTGTTCATGCCGATGTCAACATGGACGGTTCAACCCCAAAGACCGAAGGAGTCTTCTCTCTTGTTGTCGTTGTCGACCGTAAACCTCATCTGAGCTCGTCTGGATGTCTGCACACATTTGACGAGTTATTCGGTGCAAGGATCCACAGCCATGGTAATTTAGCGATCGCACCGTCGTTGAAGGATCGTTTCTACATAAGGCACGTGTCGAAACATGTGTTATCGGCAGAGAAAGACACGATGATGGTGGACCTGGAGGGAGCGACGTGGTTGTCTAACAGGCGTTTTAATTGTTGGTCTAGTTTTAAGGACCTTGATCATGACACGTGTAATGGGGTTTATGCGAACATTAGCAAGAACGCCCTGTTAGTTTATTACTGCTGGATGTCGGATATTATGTCCAAGGCATCGACATTTGTATCGTTTGATCTCGACTATGTCGGGTGA |
|
Protein Sequence
|
MYSVKYRRGSSYTQRRGYSRKTVFRRSYGVKRSDDKRRASQSSKGHDDGKISAQRIHENQFGPEFVMAHNSAISTFISFPNLGKTEPNRSRSYIKLKRLRFKGTVKIERVHADVNMDGSTPKTEGVFSLVVVVDRKPHLSSSGCLHTFDELFGARIHSHGNLAIAPSLKDRFYIRHVSKHVLSAEKDTMMVDLEGATWLSNRRFNCWSSFKDLDHDTCNGVYANISKNALLVYYCWMSDIMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009310076.1
|
|
Location
|
1219-2100 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGCTGATGAATGCTCCCAGTGCCTTTAATTATATAGAATCGCACCGTGACGAGTATCAGTTGTCACATGATCTGACAGAGATCATCCTGCAATTTCCTTCGACGGCGTCACAAATAAGCGCCAGGCTAAGTCGGAGCTGTATGAAGATCGATCATTGCGTGATCGAATACCGTCAGCAGGTCCCAATCAACGCCACAGGGTCGGTGGTAGTGGAGATTCACGACAAGAGGATGACGGACAACGAGTCTTTACAGGCGTCGTGGACTTTCCCGATCAGATGCAACATAGATCTCCACTACTTCTCGTCCTCTTTCTTCTCCTTGAAAGACCCAATTCCATGGAAGCTCTATTACAAGGTCTGCGATACGAATGTTCATCAGAGGACGCATTTCGCCAAGTTCAAGGGGAAATTGAAGCTGTCGACGGCCAAACACTCTGTGGATATTCCTTTCAGGGCTCCGACGGTGAAGATCCTGTCGAAACAGTTCACCGATAAAGATGTGGACTTTTGCCACGTCGACTACGGGAGATGGGAGAGGAAACCAGTCCGATCCGCATCCACATCAAGAGTTGGGCTTCCAAGCCCAATCGAAATAAGGCCAGGAGAGTCCTGGGCTATCAGGAGCATGATAGGGCCCAATCAATCCGATGCGGGATCGGACTTGGGAGAGGCCTTACACCCGTACCGAGAGCTTAACAGGCTACAGACTACAGTCTTGGACCCAGGTGACTCAGCCTCGATCGTAGGGACCCAGAGGTCTCAATCGAACATAACGCTGTCGCTGGCCCAATTAAACGACATTGTCAGGTCCACGGTCCAAGAATGTATTAACACCAACTGTATTCCCTCCCAACCCAAATCTTTGAAATAA |
|
Protein Sequence
|
MESQLMNAPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQISARLSRSCMKIDHCVIEYRQQVPINATGSVVVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFCHVDYGRWERKPVRSASTSRVGLPSPIEIRPGESWAIRSMIGPNQSDAGSDLGEALHPYRELNRLQTTVLDPGDSASIVGTQRSQSNITLSLAQLNDIVRSTVQECINTNCIPSQPKSLK |
|
NCBI Accession
|
YP_009310077.1
|
|
Location
|
212-967 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAACGGGAAGCCCCATGGCGCCTGATGGCGGGAACGACCAAGGTTAGTCGATCTACTGGCTATTCATCTCGTTTAGCTTCCCAGCCCAGAGTCAACAAGGCCCAAGAATGGGTGAACAGGCCTATGTACAGGAAGCCCAGGATATATAGGGCTATGAGGACACCTGATGTCCCTAGAGGGTGTGAGGGGCCTTGTAAGGTCCAGTCCTACGAGCAGCGGCATGATATCTCTCATGCCGGGAAGGTGATCTGTATATCTGATGTCACACGTGGCAGTGGTATCACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCTGTATACATATTAGGCAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACAGACGACCGAACGGTACGCCCATGGATTTCGGACATTTATTTAACATGTTCGACAACGAGCCCAGCACCGCTACGGTCAAGAACGATCTCCGTGATCGTTTCCAGGTTTTGCACAGGTTCTATGCTAAGGTCACAGGTGGTCAGTATGCCAGCAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAACAACCATGTGGTGTACAACAACCAGGAAGCCGCTCGATACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCCGTGTATGCTACGCTTAAGATTCGAATCTACTTCTACGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKREAPWRLMAGTTKVSRSTGYSSRLASQPRVNKAQEWVNRPMYRKPRIYRAMRTPDVPRGCEGPCKVQSYEQRHDISHAGKVICISDVTRGSGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPNGTPMDFGHLFNMFDNEPSTATVKNDLRDRFQVLHRFYAKVTGGQYASNEQALVKRFWKVNNHVVYNNQEAARYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009310078.1
|
|
Location
|
964-1362 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAGCATCACTGCACATCAGGCGGAGAGTGGCGTCTATACCTGGGAAATAACAAATCCCCTGTATTTCAAGATATACAGGGTCGAAGACCTCCTGTTCACAAGGACCCGAGTGTATCACATCCAAATACGGTTCAACTACAACCTGCGGAAAGCGTTGCATCTCCACAAGGCCTATTTGAATTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGAAGACTTATTTAAGTAGGTTTAGGCACCTTGTCTTGTTGTATCTTGATCAATTAGGTGTAATTTGTCTTAACAATGTAATTAGAGCTGTTCGTTTCGCAACGGATAAGTCTTATGTAAATTATGTGCTCGAGAATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGESITAHQAESGVYTWEITNPLYFKIYRVEDLLFTRTRVYHIQIRFNYNLRKALHLHKAYLNFQVWTTSMTASGKTYLSRFRHLVLLYLDQLGVICLNNVIRAVRFATDKSYVNYVLENHSIKFKIY |
|
NCBI Accession
|
YP_009310079.1
|
|
Location
|
1109-1513 |
|
Gene Name
|
TrAP |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGTTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAGCAGCAACACAGGATTGCCAAGAAGAGGCAGGCCAAGACGAGGGCCATCAGGAGGCGACGCATTGACATCGAGTGCGGCTGCTCCATATACGTCCACATAAACTGCACGGGGCATGGATTCACGCACCGGGGAGAGCATCACTGCACATCAGGCGGAGAGTGGCGTCTATACCTGGGAAATAACAAATCCCCTGTATTTCAAGATATACAGGGTCGAAGACCTCCTGTTCACAAGGACCCGAGTGTATCACATCCAAATACGGTTCAACTACAACCTGCGGAAAGCGTTGCATCTCCACAAGGCCTATTTGAATTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGAAGACTTATTTAAGTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKQQHRIAKKRQAKTRAIRRRRIDIECGCSIYVHINCTGHGFTHRGEHHCTSGGEWRLYLGNNKSPVFQDIQGRRPPVHKDPSVSHPNTVQLQPAESVASPQGLFEFPSLDDIDDSFWEDLFK |
|
NCBI Accession
|
YP_009310080.1
|
|
Location
|
1410-2510 |
|
Gene Name
|
REP |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCGCCCAAACGATTTAGACTCCAGGCTAAAAATATCTTCCTCACTTATCCACAGTGCTCTCTGTCAAAAGAAGAAGCACTTTCCCAATTACAGAGTATCCATCTCCCTTCGAACAAGAAGTTCATCAAAATCGCCAGAGAGCTTCACGACGATGGGCAACCTCACCTCCATATTCTCCTACAACTCGAAGGGAAAGTCCAGATCACAAATAACAGACTGTTCGATCTGGTGTCCCCTTCCCGGTCAGCACATTTCCATCCGAACATACAGAGAGCTAAATCCAGCTCCGACGTCAAGTCCTATGTCGAGAAGGACGGGGACACCATCGAATGGGGAGAGTTCCAGGTCGACGGTCGAAGTGCTAGAGGCGGCCAGCAGACAGCTAACGACGCAGCCGCCGAGGCACTGAACGCTCCGTCGAAGGAGGAGGCCATGAAAATCATCAAAGAAAAGTTGCCGGAAAAGTTCCTGTTCCAGTACCATAATCTGTCGAGCAACCTGGACAGGATTTTCAAAAAGGCGCCGGAGCCATGGACTCCTCCTTTTCGACTGTCCTCGTTCACTAACGTCCCGGACGAGATGCAGGAGTGGGCCGATGACTATTTTGCGAGAGATGCCGCTGCGCGGCCTGTCAGGCCTGTTAGTATCATCGTCGAAGGTGACAGTCGAACGGGGAAGACGATGTGGGCACGTGCTTTAGGGTCCCACAATTATCTCAGTGGACACCTGGATTTCAATTCCAGGGTCTTTTCCAACGAGGCTGAGTATAACGTCATTGATGACGTCCCTCCGCACTACCTAAAGCTAAAGCACTGGAAAGAGCTCCTCGGGTCCCAAAGAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTCTGCAATCCTGGAGAGGGGGCCAGTTATAAAGACTTCCTGGACAAAGAGGAAAATGCAGCCTTGAGGTCGTGGACACTCCACAATGTTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAGCAGCAACACAGGATTGCCAAGAAGAGGCAGGCCAAGACGAGGGCCATCAGGAGGCGACGCATTGA |
|
Protein Sequence
|
MPPPKRFRLQAKNIFLTYPQCSLSKEEALSQLQSIHLPSNKKFIKIARELHDDGQPHLHILLQLEGKVQITNNRLFDLVSPSRSAHFHPNIQRAKSSSDVKSYVEKDGDTIEWGEFQVDGRSARGGQQTANDAAAEALNAPSKEEAMKIIKEKLPEKFLFQYHNLSSNLDRIFKKAPEPWTPPFRLSSFTNVPDEMQEWADDYFARDAAARPVRPVSIIVEGDSRTGKTMWARALGSHNYLSGHLDFNSRVFSNEAEYNVIDDVPPHYLKLKHWKELLGSQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENAALRSWTLHNVKFIFLDSPLYQAATQDCQEEAGQDEGHQEATH |
|
NCBI Accession
|
YP_009310081.1
|
|
Location
|
2096-2353 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGCAACCTCACCTCCATATTCTCCTACAACTCGAAGGGAAAGTCCAGATCACAAATAACAGACTGTTCGATCTGGTGTCCCCTTCCCGGTCAGCACATTTCCATCCGAACATACAGAGAGCTAAATCCAGCTCCGACGTCAAGTCCTATGTCGAGAAGGACGGGGACACCATCGAATGGGGAGAGTTCCAGGTCGACGGTCGAAGTGCTAGAGGCGGCCAGCAGACAGCTAACGACGCAGCCGCCGAGGCACTGA |
|
Protein Sequence
|
MGNLTSIFSYNSKGKSRSQITDCSIWCPLPGQHISIRTYRELNPAPTSSPMSRRTGTPSNGESSRSTVEVLEAASRQLTTQPPRH |