Sida chlorotic leaf virus
Basic Information
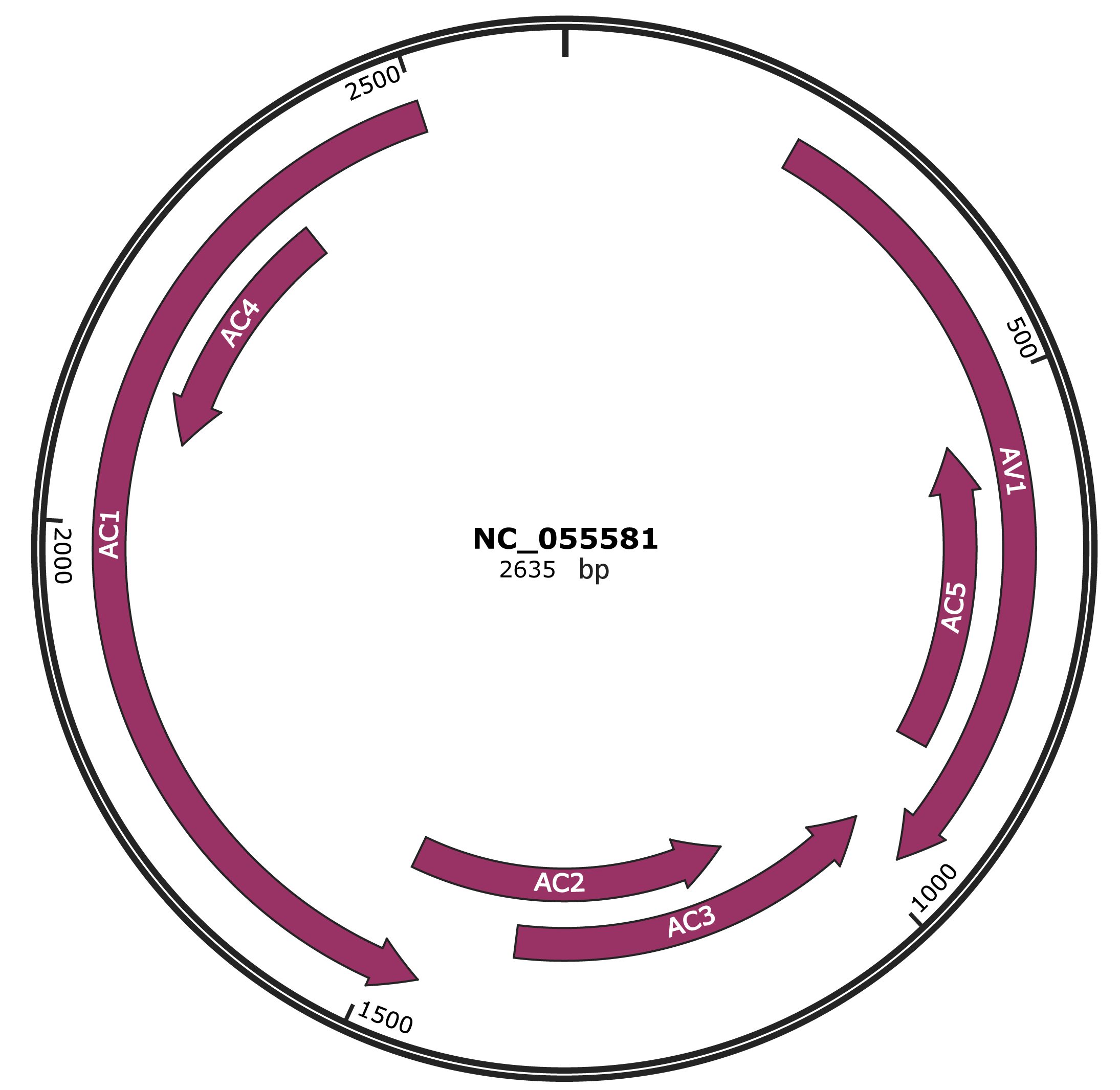
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTCCCCCTCCTACGTGTCGCAATCTCCACCCTCCAAATCCCCCGCTCCCAATCCCCGCAAATTTCGGCCATGTGATTTAAAAATGACAAATAAAGGTGACCAATCACGTCTCGTCCTACGATACTAGATATTTGTGACTTTGGGACCAAGTTGTCGTATAAATGTACGTGCAATGTCATTTTTTCCTTTAATTCAAAATGCCTAAGCGGGACGCCCCATGGCGTACTATGGCGGGGACCTCAAAGGTTTCTCGCTCCGCCAATTATTCACCTCGTGGTGGATATGGGCCGAAATTCGACAAGGCCGCTGCTTGGGTTAACAGACCCATGTATAGGAAGCCCAGAATCTATCGGGCGCTTAGAGGACCTGACGTGCCTAAGGGTTGTGAAGGGCCTTGTAAGGTTCAATCCTTTGAACAGCGTCATGATATTTCCCATGTTGGTAAGGTCATGTGTATATCTGATGTCACACGTGGTAATGGTATTACCCATCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTCTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACGAACAGCGTCATGTTTTGGTTGGTCAGAGACAGAAGACCCTATGGCACCCCTATGGATTTTGGTCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACGGTGAAGAACGATCTTCGTGATCGTTTTCAGGTCATGCACAGGTTCTATGCTAAGGTGACTGGTGGTCAATATGCTAGCAACGAGCAGGCATTGGTTAGGCGATTCTGGAGAGTCAACACTCATGTTGTCTATAACCACCAGGAAGCCGCTAAGTACGAGAATCATACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACATTGAAAATTCGGATCTATTTTTATGATTCGATCAGCAATTAATAAAATAAGAATTTTATTTCATGATTCTCAAGTACATCATTTACATATGATCTGTCTGTCGCGAAGCGAACAGCTCGAATAACATTATTAATTGAAATAACGCCTATATTGTCTAAGTACAACATGACTAAGCGACTAAATCTATTTAAATACGTCGTCCCAGAAACTCGAAGCAATGTCGTCCAGACTTGGAAATTCAGGAAGGCTTTGTGTAGACCCAGTGCCCTCCTCAGGTTGTGGTTGAACCTTATCTGGACATGATATATTGTGATCAGGGAGAACGGTGGAACCTCCACCTGGTTTATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATAAAAACGCCACTCTCTGCTTGATGCGCAGTGATGGGTTCCCCGGTGCGTGAATCCATGATTGACGCAATTGATGTGCAGGAATATGGAACAGCCGCAGTTCAGGTCCAACCGTCTACGACGAACAGCCCTTCTCTTGGCTCGTCTATGTTGTGCTTTGATAGAGGGGGGCGTTGATGGTGACGAATTTCGCATTATGAAGCGTCCACGCTTTTAGTGATGCGTTTTCTTCTTTGTCTAGGAAGTGTTTATAAGAAGCCCCCTCTCCCGGGTTACAAAGCACAATTGATGGGATACCTCCTTTAATTTGAACCGGCTTTCCATATTTACAGTTGGACTGCCAGTCTCTTTGGGACCCTATTAGCTCTTTCCAGTGCTTTAGTTTGAGATAATGTGGACTAACGTCATCAATGACGTTATACTCCACTTCATTTGAATAGACTCGAGGATTGAAGTCCAGGTGTCCAGACAAGTAATTATGAGAACCTAAAGCACGAGCCCACATCGTTTTTCCCGTCCTTGAATCACCTTCAATGATGATGCTAATAGGTCTCTCCGGCCGCGCAGCGGCATCTTTCCCGAAATAGTCATCTGCCCACCTTTGCATCTCCACTGGGACGTTAGTGAATGTGGAGAGTTGAAACGGAGGAGTCCATGGCTCCGGAGCCTTACTGAATATCCTGTCGAGGTTACTCGATAGGTTATGAAACTGAAATAAAAACTTTTCCGGAAGTTTTTCTTTGATTATCCTCATTGCCTCCTCCTTTGTTCCAGAATTTAACGCCTCGGCGGCTGCGTCGTTAGATGTCTGCTGACCGCCGCGAGCACTTCTTCCGTCGATCTGGAACACCCCCCATTCGATGGTGTCACCGTCTTTCTCGACGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCTTGTATGTTTGGGTGGAAATGGGCAGACCTGGTTGAGGACACCATATCGAATAATCTGTTATTTGTGCAGTTGAACTTCCCTTCGAACTGTATAAGCACATGGATATGAGGCTGCCCATCTTCATGAAACTCCCTGCAGACCTTGATAAATTTCTTATTCGTGGGAGTTTTGATGTTCCTGAGTTGTTCCAGTGCCTCCTCTTTCTTAAGAGAGCACTGGGGATAAGTGAGAAAATAGTTTTTGGCTTTAATAGAGAAAGAACCCTTCCGTGGCATTGTCGTAAATAATGATGTTCCCCCGATAGCTCTCTCGCTCAAAACTTCCTATGAATCGGGGGAACTGGGGGAACTTATATAGTAGAGCTCCTTAAAGCCAAATCAACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087776.1
|
|
Location
|
219-974 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGACGCCCCATGGCGTACTATGGCGGGGACCTCAAAGGTTTCTCGCTCCGCCAATTATTCACCTCGTGGTGGATATGGGCCGAAATTCGACAAGGCCGCTGCTTGGGTTAACAGACCCATGTATAGGAAGCCCAGAATCTATCGGGCGCTTAGAGGACCTGACGTGCCTAAGGGTTGTGAAGGGCCTTGTAAGGTTCAATCCTTTGAACAGCGTCATGATATTTCCCATGTTGGTAAGGTCATGTGTATATCTGATGTCACACGTGGTAATGGTATTACCCATCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTCTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACGAACAGCGTCATGTTTTGGTTGGTCAGAGACAGAAGACCCTATGGCACCCCTATGGATTTTGGTCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACGGTGAAGAACGATCTTCGTGATCGTTTTCAGGTCATGCACAGGTTCTATGCTAAGGTGACTGGTGGTCAATATGCTAGCAACGAGCAGGCATTGGTTAGGCGATTCTGGAGAGTCAACACTCATGTTGTCTATAACCACCAGGAAGCCGCTAAGTACGAGAATCATACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACATTGAAAATTCGGATCTATTTTTATGATTCGATCAGCAATTAA |
|
Protein Sequence
|
MPKRDAPWRTMAGTSKVSRSANYSPRGGYGPKFDKAAAWVNRPMYRKPRIYRALRGPDVPKGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWRVNTHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_010087777.1
|
|
Location
|
552-869 |
|
Gene Name
|
AC5 |
|
Protein Name
|
putative AC5 protein |
|
Coding Region
|
ATGATTCTCGTACTTAGCGGCTTCCTGGTGGTTATAGACAACATGAGTGTTGACTCTCCAGAATCGCCTAACCAATGCCTGCTCGTTGCTAGCATATTGACCACCAGTCACCTTAGCATAGAACCTGTGCATGACCTGAAAACGATCACGAAGATCGTTCTTCACCGTAGCAGTACTGGGCTCGTTGTCGAACATGTTGAACACTTGACCAAAATCCATAGGGGTGCCATAGGGTCTTCTGTCTCTGACCAACCAAAACATGACGCTGTTCGTGTGGTTCTTCAGCTTGATGTTCTCGTCCATCCATATCTTACCTAG |
|
Protein Sequence
|
MILVLSGFLVVIDNMSVDSPESPNQCLLVASILTTSHLSIEPVHDLKTITKIVLHRSSTGLVVEHVEHLTKIHRGAIGSSVSDQPKHDAVRVVLQLDVLVHPYLT |
|
NCBI Accession
|
YP_010087778.1
|
|
Location
|
971-1369 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACCCATCACTGCGCATCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAAACCAGGTGGAGGTTCCACCGTTCTCCCTGATCACAATATATCATGTCCAGATAAGGTTCAACCACAACCTGAGGAGGGCACTGGGTCTACACAAAGCCTTCCTGAATTTCCAAGTCTGGACGACATTGCTTCGAGTTTCTGGGACGACGTATTTAAATAGATTTAGTCGCTTAGTCATGTTGTACTTAGACAATATAGGCGTTATTTCAATTAATAATGTTATTCGAGCTGTTCGCTTCGCGACAGACAGATCATATGTAAATGATGTACTTGAGAATCATGAAATAAAATTCTTATTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAHQAESGVFIWEVPNPLYFKINQVEVPPFSLITIYHVQIRFNHNLRRALGLHKAFLNFQVWTTLLRVSGTTYLNRFSRLVMLYLDNIGVISINNVIRAVRFATDRSYVNDVLENHEIKFLFY |
|
NCBI Accession
|
YP_010087779.1
|
|
Location
|
1116-1505 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGAAATTCGTCACCATCAACGCCCCCCTCTATCAAAGCACAACATAGACGAGCCAAGAGAAGGGCTGTTCGTCGTAGACGGTTGGACCTGAACTGCGGCTGTTCCATATTCCTGCACATCAATTGCGTCAATCATGGATTCACGCACCGGGGAACCCATCACTGCGCATCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAAACCAGGTGGAGGTTCCACCGTTCTCCCTGATCACAATATATCATGTCCAGATAAGGTTCAACCACAACCTGAGGAGGGCACTGGGTCTACACAAAGCCTTCCTGAATTTCCAAGTCTGGACGACATTGCTTCGAGTTTCTGGGACGACGTATTTAAATAG |
|
Protein Sequence
|
MRNSSPSTPPSIKAQHRRAKRRAVRRRRLDLNCGCSIFLHINCVNHGFTHRGTHHCASSREWRFYLGGSKSPLFQDKPGGGSTVLPDHNISCPDKVQPQPEEGTGSTQSLPEFPSLDDIASSFWDDVFK |
|
NCBI Accession
|
YP_010087780.1
|
|
Location
|
1456-2502 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGGAAGGGTTCTTTCTCTATTAAAGCCAAAAACTATTTTCTCACTTATCCCCAGTGCTCTCTTAAGAAAGAGGAGGCACTGGAACAACTCAGGAACATCAAAACTCCCACGAATAAGAAATTTATCAAGGTCTGCAGGGAGTTTCATGAAGATGGGCAGCCTCATATCCATGTGCTTATACAGTTCGAAGGGAAGTTCAACTGCACAAATAACAGATTATTCGATATGGTGTCCTCAACCAGGTCTGCCCATTTCCACCCAAACATACAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGTGACACCATCGAATGGGGGGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGCGGTCAGCAGACATCTAACGACGCAGCCGCCGAGGCGTTAAATTCTGGAACAAAGGAGGAGGCAATGAGGATAATCAAAGAAAAACTTCCGGAAAAGTTTTTATTTCAGTTTCATAACCTATCGAGTAACCTCGACAGGATATTCAGTAAGGCTCCGGAGCCATGGACTCCTCCGTTTCAACTCTCCACATTCACTAACGTCCCAGTGGAGATGCAAAGGTGGGCAGATGACTATTTCGGGAAAGATGCCGCTGCGCGGCCGGAGAGACCTATTAGCATCATCATTGAAGGTGATTCAAGGACGGGAAAAACGATGTGGGCTCGTGCTTTAGGTTCTCATAATTACTTGTCTGGACACCTGGACTTCAATCCTCGAGTCTATTCAAATGAAGTGGAGTATAACGTCATTGATGACGTTAGTCCACATTATCTCAAACTAAAGCACTGGAAAGAGCTAATAGGGTCCCAAAGAGACTGGCAGTCCAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGAGGTATCCCATCAATTGTGCTTTGTAACCCGGGAGAGGGGGCTTCTTATAAACACTTCCTAGACAAAGAAGAAAACGCATCACTAAAAGCGTGGACGCTTCATAATGCGAAATTCGTCACCATCAACGCCCCCCTCTATCAAAGCACAACATAG |
|
Protein Sequence
|
MPRKGSFSIKAKNYFLTYPQCSLKKEEALEQLRNIKTPTNKKFIKVCREFHEDGQPHIHVLIQFEGKFNCTNNRLFDMVSSTRSAHFHPNIQGAKSSSDVKSYVEKDGDTIEWGVFQIDGRSARGGQQTSNDAAAEALNSGTKEEAMRIIKEKLPEKFLFQFHNLSSNLDRIFSKAPEPWTPPFQLSTFTNVPVEMQRWADDYFGKDAAARPERPISIIIEGDSRTGKTMWARALGSHNYLSGHLDFNPRVYSNEVEYNVIDDVSPHYLKLKHWKELIGSQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKHFLDKEENASLKAWTLHNAKFVTINAPLYQSTT |
|
NCBI Accession
|
YP_010087781.1
|
|
Location
|
2088-2351 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAGATGGGCAGCCTCATATCCATGTGCTTATACAGTTCGAAGGGAAGTTCAACTGCACAAATAACAGATTATTCGATATGGTGTCCTCAACCAGGTCTGCCCATTTCCACCCAAACATACAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGTGACACCATCGAATGGGGGGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGCGGTCAGCAGACATCTAACGACGCAGCCGCCGAGGCGTTAA |
|
Protein Sequence
|
MKMGSLISMCLYSSKGSSTAQITDYSIWCPQPGLPISTQTYKELNPAPTSSPTSRKTVTPSNGGCSRSTEEVLAAVSRHLTTQPPRR |