Sida bright yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029405.2 |
| Isolate |
Brazil |
| Release date |
2018/12/27 |
| Submitter |
Ferro,C.G., Silva,J.P., Xavier,C.A.D., Godinho,M.T., Lima,A.T.M., Mar,T.B., Lau,D., Zerbini,F.M. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
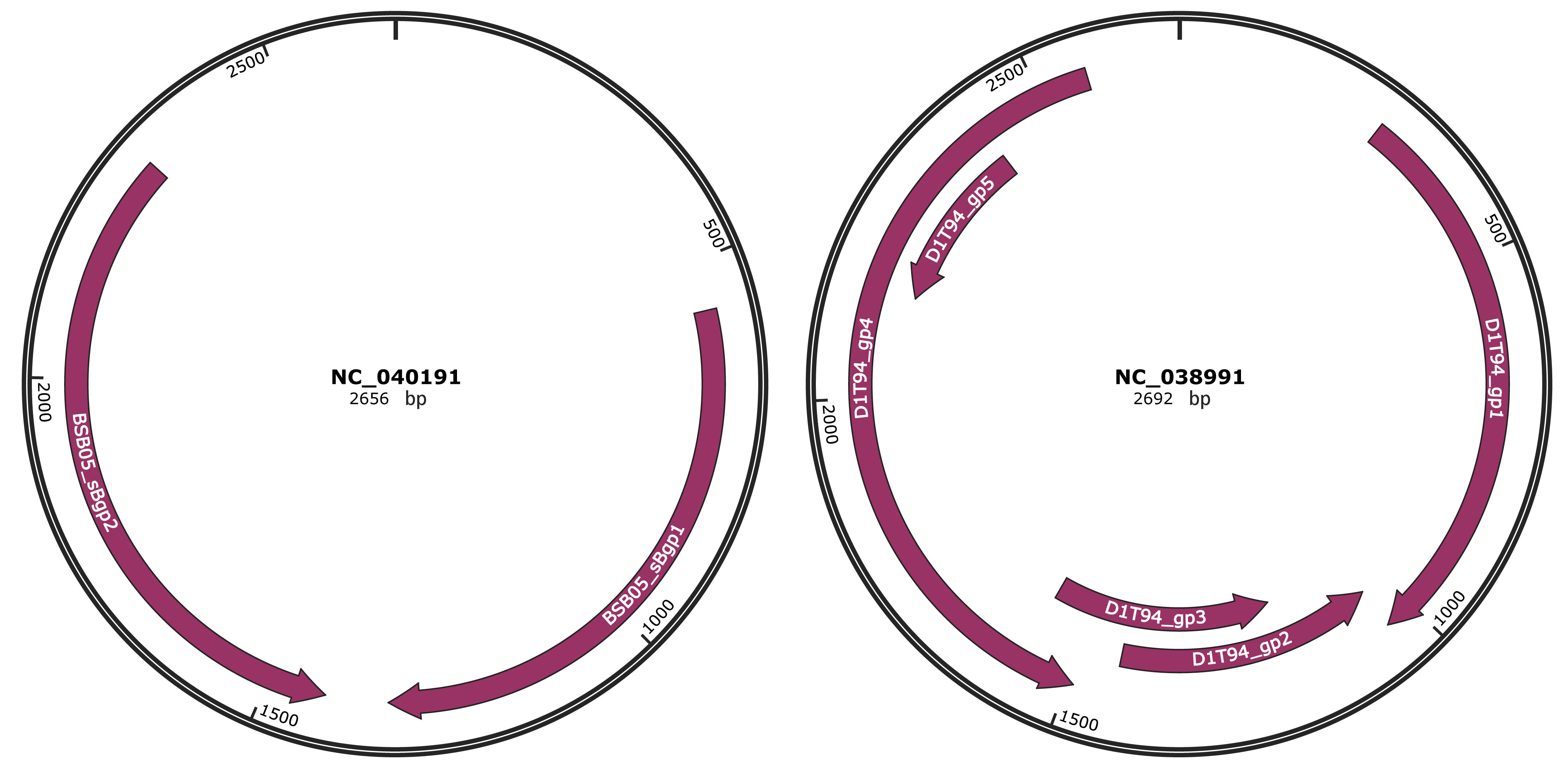
JBrowse
Genome
ACCGGATGGCCGCGCGATTTCCCCCCCCCCTGACGTGGCGCTCTGGTGTCCGTGTGATCTCTCCCCCTGGCGCTCCCTTGGTGCTCTCTTCGCGCTCCGCAATTCAGTTTAGCGCTTTTTTTGGAGTCCGCGAAATGAGTTAACCGCATTTTTTGAGTTCCGCCCCACTCAGACAGCTCCCTTTAATTTGAATTAAAGGGGTTCTATTTTGTGTAGCCAATCATTTCGGCGAGTATGGAGTTTACTTATGAAGTGTATACTTTTTGTCGAAGTTTTCGAGTGACCGTTTAACTGCTGACATGCAATCTCAGATTGCATGTGTTATTCGAATTATTATGGCGGGCATGTTGTTTGAGGCCCATATTTACAGTGACTATTTGGGCTGTCCCACTGTACAATATGTGTGACTTGGACCAGTTATATCTTCTCCATGGAGTCAGTTTAAGATATATAATTGATCAAGGGGGCTATATATCGGGACGGAATTTCATATTTAAATTCCGTATATGATTAGTTCTTCTTAACAGCTATATACATTTAACATATCTTAAACCTGTTTGCTTGATATGTATCTGTTTAAGTACAGGCGTGGCAGTTTCTCTGGCCAACGACGTGGTTATTCTCGCAATCACGTGTTCAGACGTCCATCATCTACGAGACGTGTGGACGGGAAACGACGATATAATATATCTAGCAAGACCCCTGACGATGCCAAGATGTCGGCCCAGAGGATACATGAGAACCAGTTTGGGCCTGATTATGTATTGGCCCAGAATTCAGTATTGGCCACCTTCATCACCTTCCCCCAGCTTGGCAAGACCGAGCCTAACCGATCAAGGTCATATATTAAGTTGAAACGCCTCCGTTTCAAGGGTACGGTTAAGATTGAACGTGTGCAAGGTGATGTGAACATGGATGGGCCCGGCCCAAAGACGGAAGGCGTCTTCTCCTTAGTGGTCGTTGTGGATCGAAAACCTCATCTTAGCCCAACTGGATGTCTACATACCTTCGACGAGTTATTTGGTGCAAGGATCCACAGCCATGGTAACCTGGCGATAGTCCCTGCTTTGAAGGACCGTTTCTACGTACGTCATGTTCTCAAACGAGTGATATCGGTCGAGAAGGATACGTTAATGGTCGACCTTGAAGGAACGACGTCGTTCTCTAATAAGCGATTTAGTTGTTGGTCCTCTTTCAAGGACCTTGAGCGTGACTCATGTAATGGCGTTTATGGCAACATAAGCAAGAACGCCCTGTTAGTCTATTACTGTTGGATGTCGGATATTGTGTCCAAGGCATCGACATTTGTATCATATGACCTTGATTACGTTGGTTAATCAACAATTATATTATAACTGCCGTATATTAACTGAATTGCTCGTTCTCGTATTCCTCGTTTTCCAAACTCAGCAACTTAAAATTTATTTTAATGTTTTGGGCTGGGCCGTGCTACAATTACTACTGATACACTCATTGACAGTGGCCCTGACTAGCTCGTTTAATTGGGCCACTGACATTGTTATGTTCGACTGGGCCCTCTGAGCCCCAACTATGGAGGCCGAGTCACCTGGGTCTAGGGCGCTGGTGCCTAGTCTGTGGAGCTCTCTGTATGGATGGATCTCGTTCGCGAGCTCAGAGTCCGCATCTGATTGACCCAGTTCAACTGTACTCCTGGTAGCCCATGATTCACCAGGCCGGATTTCTATTGGGCCTTGACGACCCACTGTCGATATGGATGCTGACCTGATCAGCTTCCTTCCCCATCTCCCGTAGCCCACATGGCAGAAGTCGACGTCTTTCTCCGTGAACTGTTTCGACAGTATCTTGACCGTGGGAGCTTTGAAAGGGATGTCGACGGAATGTTTCGCCGTCGACAATTTCAGTTTACCTTTGAACTTGGCGAAGTGTGTGTTCTGGTGTACGTTCGTGTCGGAAACCCTGTAGTACAGCTTCCATGGAATGGGATCTTTCATGGAGAAGAAAGACGACGAGAAGTAGTGGAGATCGATGTTACATCTGACCGGGAAAGTCCACGACGCCTGCAAGGACTCGTTGTCAGTCATCCTTTTGTCATGAATCTCCACTACCACTGTGCCGGTGGCGTTAATTGGCACCTGTTGCCTGTATTCTATGACGCAGTGATCTATCTTCATACAACTACGACTGATTCTGGCACTCAATTGAGCCGCCGTTGACGGAAATTGCAGAATGATCTCTGTTAGGTCATGTGACAGTTGATATTCATCACGTCGAGACTCGATATAGTTGAACGCACTTGGAGGATTCACTAGCTGAGAATCCATTTGAGAATTCTAATAGCAGCGAAGGCCGCGCAGCGGAATCGTCTTCCTGAGATCAACAGTTGAAGAAGAGACGACGACCGTCGTCCACTGTTTAGGAATTTGGTAAAGTTAAGGGGAAGATGATAATGAAGACGATTTTAGTACGGATTGAGAGGAGATATTGTTTAATTGGTGTGTTATGACTAGCTGATATCGTCTTTAAATAGGATTTGATTGGCCAATGGCATTTTTGTAAATAAGGCTATGTACCCCAGATGAGAGCTCGCTCTATAAGTTATATGAATTGGGGTAATGGGGTACAATATATAGTAGAAGTTCCTAGGGGTCTTTAAGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCGATTTTTCCCCCCCCTACGTGGCGCTCTGGTGTCCGCGCGATTCTTCCCCCCCCTACGTGGCGCTCTGGTGTCCGCGCGAATGTCCCCTGCTCGCGCTCTGCTCCTCGCGCGATTTTCCTTTAATTCGAATTAAAGGAAAATAACCTTTATCTGACCAATCATATTGCGCCTGTCGAGTCTATTTAATTTGAAATACTTCGGCGCTAAGTTGTCTAGCCTGTATATATTTGGGCCTTGATTATTTGGGCTCGACAGGCTTTTATTCAATATGCCCAAGCGTGACCTTCCATGGCGCTCGACTTTGGGAACCTCAAAGGTCAGTCGTTCTTCTAACTTCTCCCCTCGTGGAGGTTACGGCCCAAAATACAATAAGGCCAATGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGGCTTATAGATCACCCGATGTTCCTAAAGGGTGTGAGGGGCCGTGCAAGGTCCAGTCCTACGAGCAGCGTCATGACATCTCACATGTCGGGAAGGTCATGTGCATATCTGATGTGACTCGTGGTAACGGTATTACCCACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAATCACACGAATAGTGTGATGTTTTGGTTGGTCAGAGACCGTAGACCGTATGGCACTCCGATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACCGTGAAGAACGATCTACGCGATCGTTACCAGGTTATGCACAAGTTTTATGCCAAGGTCACGGGTGGTCAGTATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCACCAGGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTCTACTACTGTATATGGCATGTACGCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATAACGAATTAATAAAATTTGAAGTTTATTGAATGATTTTCGAGTACATAACTGACATATGGCCTGTCTGTTGCGAATCGAACAGCTCTGATGACATTATTAAGACAAATTACACCTAATTGATCTAAATACATCATGACTAGTCTCTTAAACCTAGCTAAATATGTCGTCCCAGAAGCTCTCAGAGATGTCGTCCAGACTTGGAAGTTCAAGTAGGCTTTGTGGAGACCCAGTGCTCTCCTGAGGTTGTGGTTGAACCGGATCTGGACGTGGTATATTCTGGTCCTTGCGAACAGCGGTTCCTCTAGCCTGTATATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATATAGACGCCATTCTCCGCCTGACGTCGCGTGATGCTCTCCCCGGTGCGTGAATCCATGCCCTACGCAGTTTAAGTGGAGGAAGATTGAACAGCCGCAGTTCAAGTCAATTCGTTTACGGCGAATTGCTCTCTTCTTGGCGATCCTGTGTCGTGCTTTGATAGAGGGGGGCGTGGAGGAAGATGAATTTAGCATTGTGGATTGTCCAGCTTCGCAGATATGCGTTTTCCTCTTTGTCGAGGAAGTCTTTATAGCTGGCCCCCTCTCCTGGATTGCAAAGCACGATTGTTGGGATCCCTCCTTTAATTTGAACTGGCTTTCCGTACTTGCAATTTGACTGCCAGTCTTTTTGGGCTCCAATGAGCTCTTTCCAGTGCTTTAACTTTAGATAGTTGGGAGTGACGTCGTCAATGACGTTATATTCAGCCTCATTGGAGTACACCCTTGAATTGAGGTCCAGGTGACCACTGAGATAATTATGTGGGCCTAATGACCGAGCCCACATCGTCTTCCCTGTCCTAGAGTCACCTTCAACAATCAAACTGATAGGCCTCAATGGCCGCGCAGCGGCACCTCTCCCAAAATAATCATCTGCCCACTCTTGCATCTCGTCTGGCACGTTAGTGAATGAGGAGAGGGGAAACGGAGGGACCCATGGTTCCGGAGCCTTTGCAAAGATCCTATCTAAATTACTATTTAGATTGTGAAACTGGAATAGGAACTTTTCCGGCAACTTCTCTCGGACAATTTGCATGGCAGCTTCCTTTGAAGCTGCGTTTAGGGCTTCTGCGGCAGCGTCGTTAGCTGTCTGCTGACCTCCTCTAGCACTTCTTCCGTCGACCTGGAAACTTCCCCACTCGATTGTGTCCCCGTCCTTGCTAATGTAGGACTTGACGTCGGACGATGATTTAGCTCCCTGAATGTTCGGATGGAAATGTACTGACCGGGAAGGGGACACCAGATCGAAGAATCTCTGATTCGTGCATTGGAATTTCCCTTCGAACTGGATAAGCACGTGGAGATGTGGCTGCCCATCTTCGTGAAGTTCTCTGCAAATCTTGATGAACTTCTTTTTAACTGGTGTTGTTAAGCTCTCTAATTGGGAAAGTGTCTCCTCTTTGGTTAGGGAGCACTGGGGATATGTCAAGAAATAATTCTTGGCACTTATTTTAAAACGTTTTGGCGGTGGCATTTTTGTAAATAAGGCTATGTACCCCAGATGAGAGCTCGCTCTATAAGTTATATGAATTGGGGTAATGGGGACAATATATAGTAGAAGTTCCTAGGGACTTTAAGCGGCCATCCGTTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009547942.1
|
|
Location
|
567-1337 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCTGTTTAAGTACAGGCGTGGCAGTTTCTCTGGCCAACGACGTGGTTATTCTCGCAATCACGTGTTCAGACGTCCATCATCTACGAGACGTGTGGACGGGAAACGACGATATAATATATCTAGCAAGACCCCTGACGATGCCAAGATGTCGGCCCAGAGGATACATGAGAACCAGTTTGGGCCTGATTATGTATTGGCCCAGAATTCAGTATTGGCCACCTTCATCACCTTCCCCCAGCTTGGCAAGACCGAGCCTAACCGATCAAGGTCATATATTAAGTTGAAACGCCTCCGTTTCAAGGGTACGGTTAAGATTGAACGTGTGCAAGGTGATGTGAACATGGATGGGCCCGGCCCAAAGACGGAAGGCGTCTTCTCCTTAGTGGTCGTTGTGGATCGAAAACCTCATCTTAGCCCAACTGGATGTCTACATACCTTCGACGAGTTATTTGGTGCAAGGATCCACAGCCATGGTAACCTGGCGATAGTCCCTGCTTTGAAGGACCGTTTCTACGTACGTCATGTTCTCAAACGAGTGATATCGGTCGAGAAGGATACGTTAATGGTCGACCTTGAAGGAACGACGTCGTTCTCTAATAAGCGATTTAGTTGTTGGTCCTCTTTCAAGGACCTTGAGCGTGACTCATGTAATGGCGTTTATGGCAACATAAGCAAGAACGCCCTGTTAGTCTATTACTGTTGGATGTCGGATATTGTGTCCAAGGCATCGACATTTGTATCATATGACCTTGATTACGTTGGTTAA |
|
Protein Sequence
|
MYLFKYRRGSFSGQRRGYSRNHVFRRPSSTRRVDGKRRYNISSKTPDDAKMSAQRIHENQFGPDYVLAQNSVLATFITFPQLGKTEPNRSRSYIKLKRLRFKGTVKIERVQGDVNMDGPGPKTEGVFSLVVVVDRKPHLSPTGCLHTFDELFGARIHSHGNLAIVPALKDRFYVRHVLKRVISVEKDTLMVDLEGTTSFSNKRFSCWSSFKDLERDSCNGVYGNISKNALLVYYCWMSDIVSKASTFVSYDLDYVG |
|
NCBI Accession
|
YP_009547943.1
|
|
Location
|
1422-2303 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCAGCTAGTGAATCCTCCAAGTGCGTTCAACTATATCGAGTCTCGACGTGATGAATATCAACTGTCACATGACCTAACAGAGATCATTCTGCAATTTCCGTCAACGGCGGCTCAATTGAGTGCCAGAATCAGTCGTAGTTGTATGAAGATAGATCACTGCGTCATAGAATACAGGCAACAGGTGCCAATTAACGCCACCGGCACAGTGGTAGTGGAGATTCATGACAAAAGGATGACTGACAACGAGTCCTTGCAGGCGTCGTGGACTTTCCCGGTCAGATGTAACATCGATCTCCACTACTTCTCGTCGTCTTTCTTCTCCATGAAAGATCCCATTCCATGGAAGCTGTACTACAGGGTTTCCGACACGAACGTACACCAGAACACACACTTCGCCAAGTTCAAAGGTAAACTGAAATTGTCGACGGCGAAACATTCCGTCGACATCCCTTTCAAAGCTCCCACGGTCAAGATACTGTCGAAACAGTTCACGGAGAAAGACGTCGACTTCTGCCATGTGGGCTACGGGAGATGGGGAAGGAAGCTGATCAGGTCAGCATCCATATCGACAGTGGGTCGTCAAGGCCCAATAGAAATCCGGCCTGGTGAATCATGGGCTACCAGGAGTACAGTTGAACTGGGTCAATCAGATGCGGACTCTGAGCTCGCGAACGAGATCCATCCATACAGAGAGCTCCACAGACTAGGCACCAGCGCCCTAGACCCAGGTGACTCGGCCTCCATAGTTGGGGCTCAGAGGGCCCAGTCGAACATAACAATGTCAGTGGCCCAATTAAACGAGCTAGTCAGGGCCACTGTCAATGAGTGTATCAGTAGTAATTGTAGCACGGCCCAGCCCAAAACATTAAAATAA |
|
Protein Sequence
|
MDSQLVNPPSAFNYIESRRDEYQLSHDLTEIILQFPSTAAQLSARISRSCMKIDHCVIEYRQQVPINATGTVVVEIHDKRMTDNESLQASWTFPVRCNIDLHYFSSSFFSMKDPIPWKLYYRVSDTNVHQNTHFAKFKGKLKLSTAKHSVDIPFKAPTVKILSKQFTEKDVDFCHVGYGRWGRKLIRSASISTVGRQGPIEIRPGESWATRSTVELGQSDADSELANEIHPYRELHRLGTSALDPGDSASIVGAQRAQSNITMSVAQLNELVRATVNECISSNCSTAQPKTLK |
|
NCBI Accession
|
YP_009508423.1
|
|
Location
|
285-1040 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCCAAGCGTGACCTTCCATGGCGCTCGACTTTGGGAACCTCAAAGGTCAGTCGTTCTTCTAACTTCTCCCCTCGTGGAGGTTACGGCCCAAAATACAATAAGGCCAATGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGGCTTATAGATCACCCGATGTTCCTAAAGGGTGTGAGGGGCCGTGCAAGGTCCAGTCCTACGAGCAGCGTCATGACATCTCACATGTCGGGAAGGTCATGTGCATATCTGATGTGACTCGTGGTAACGGTATTACCCACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAATCACACGAATAGTGTGATGTTTTGGTTGGTCAGAGACCGTAGACCGTATGGCACTCCGATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACCGTGAAGAACGATCTACGCGATCGTTACCAGGTTATGCACAAGTTTTATGCCAAGGTCACGGGTGGTCAGTATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCACCAGGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTCTACTACTGTATATGGCATGTACGCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATAACGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSTLGTSKVSRSSNFSPRGGYGPKYNKANEWVNRPMYRKPRIYRAYRSPDVPKGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009508424.1
|
|
Location
|
1037-1435 |
|
Protein Name
|
REN |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAGCATCACGCGACGTCAGGCGGAGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACAGGCTAGAGGAACCGCTGTTCGCAAGGACCAGAATATACCACGTCCAGATCCGGTTCAACCACAACCTCAGGAGAGCACTGGGTCTCCACAAAGCCTACTTGAACTTCCAAGTCTGGACGACATCTCTGAGAGCTTCTGGGACGACATATTTAGCTAGGTTTAAGAGACTAGTCATGATGTATTTAGATCAATTAGGTGTAATTTGTCTTAATAATGTCATCAGAGCTGTTCGATTCGCAACAGACAGGCCATATGTCAGTTATGTACTCGAAAATCATTCAATAAACTTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGESITRRQAENGVYIWEVPNPLYFKIYRLEEPLFARTRIYHVQIRFNHNLRRALGLHKAYLNFQVWTTSLRASGTTYLARFKRLVMMYLDQLGVICLNNVIRAVRFATDRPYVSYVLENHSINFKFY |
|
NCBI Accession
|
YP_009508425.1
|
|
Location
|
1182-1571 |
|
Protein Name
|
TRAP |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCCACGCCCCCCTCTATCAAAGCACGACACAGGATCGCCAAGAAGAGAGCAATTCGCCGTAAACGAATTGACTTGAACTGCGGCTGTTCAATCTTCCTCCACTTAAACTGCGTAGGGCATGGATTCACGCACCGGGGAGAGCATCACGCGACGTCAGGCGGAGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACAGGCTAGAGGAACCGCTGTTCGCAAGGACCAGAATATACCACGTCCAGATCCGGTTCAACCACAACCTCAGGAGAGCACTGGGTCTCCACAAAGCCTACTTGAACTTCCAAGTCTGGACGACATCTCTGAGAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKARHRIAKKRAIRRKRIDLNCGCSIFLHLNCVGHGFTHRGEHHATSGGEWRLYLGGSKSPLFQDIQARGTAVRKDQNIPRPDPVQPQPQESTGSPQSLLELPSLDDISESFWDDIFS |
|
NCBI Accession
|
YP_009508426.1
|
|
Location
|
1492-2568 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACCGCCAAAACGTTTTAAAATAAGTGCCAAGAATTATTTCTTGACATATCCCCAGTGCTCCCTAACCAAAGAGGAGACACTTTCCCAATTAGAGAGCTTAACAACACCAGTTAAAAAGAAGTTCATCAAGATTTGCAGAGAACTTCACGAAGATGGGCAGCCACATCTCCACGTGCTTATCCAGTTCGAAGGGAAATTCCAATGCACGAATCAGAGATTCTTCGATCTGGTGTCCCCTTCCCGGTCAGTACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATTAGCAAGGACGGGGACACAATCGAGTGGGGAAGTTTCCAGGTCGACGGAAGAAGTGCTAGAGGAGGTCAGCAGACAGCTAACGACGCTGCCGCAGAAGCCCTAAACGCAGCTTCAAAGGAAGCTGCCATGCAAATTGTCCGAGAGAAGTTGCCGGAAAAGTTCCTATTCCAGTTTCACAATCTAAATAGTAATTTAGATAGGATCTTTGCAAAGGCTCCGGAACCATGGGTCCCTCCGTTTCCCCTCTCCTCATTCACTAACGTGCCAGACGAGATGCAAGAGTGGGCAGATGATTATTTTGGGAGAGGTGCCGCTGCGCGGCCATTGAGGCCTATCAGTTTGATTGTTGAAGGTGACTCTAGGACAGGGAAGACGATGTGGGCTCGGTCATTAGGCCCACATAATTATCTCAGTGGTCACCTGGACCTCAATTCAAGGGTGTACTCCAATGAGGCTGAATATAACGTCATTGACGACGTCACTCCCAACTATCTAAAGTTAAAGCACTGGAAAGAGCTCATTGGAGCCCAAAAAGACTGGCAGTCAAATTGCAAGTACGGAAAGCCAGTTCAAATTAAAGGAGGGATCCCAACAATCGTGCTTTGCAATCCAGGAGAGGGGGCCAGCTATAAAGACTTCCTCGACAAAGAGGAAAACGCATATCTGCGAAGCTGGACAATCCACAATGCTAAATTCATCTTCCTCCACGCCCCCCTCTATCAAAGCACGACACAGGATCGCCAAGAAGAGAGCAATTCGCCGTAA |
|
Protein Sequence
|
MPPPKRFKISAKNYFLTYPQCSLTKEETLSQLESLTTPVKKKFIKICRELHEDGQPHLHVLIQFEGKFQCTNQRFFDLVSPSRSVHFHPNIQGAKSSSDVKSYISKDGDTIEWGSFQVDGRSARGGQQTANDAAAEALNAASKEAAMQIVREKLPEKFLFQFHNLNSNLDRIFAKAPEPWVPPFPLSSFTNVPDEMQEWADDYFGRGAAARPLRPISLIVEGDSRTGKTMWARSLGPHNYLSGHLDLNSRVYSNEAEYNVIDDVTPNYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPTIVLCNPGEGASYKDFLDKEENAYLRSWTIHNAKFIFLHAPLYQSTTQDRQEESNSP |
|
NCBI Accession
|
YP_009508427.1
|
|
Location
|
2154-2411 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAGCCACATCTCCACGTGCTTATCCAGTTCGAAGGGAAATTCCAATGCACGAATCAGAGATTCTTCGATCTGGTGTCCCCTTCCCGGTCAGTACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATTAGCAAGGACGGGGACACAATCGAGTGGGGAAGTTTCCAGGTCGACGGAAGAAGTGCTAGAGGAGGTCAGCAGACAGCTAACGACGCTGCCGCAGAAGCCCTAA |
|
Protein Sequence
|
MGSHISTCLSSSKGNSNARIRDSSIWCPLPGQYISIRTFRELNHRPTSSPTLARTGTQSSGEVSRSTEEVLEEVSRQLTTLPQKP |