Sida angular mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001777325.1 |
| Isolate |
Brazil |
| Release date |
2016/10/19 |
| Submitter |
Passos,L.S., Teixeira,J.W.M., Lima,K.J., Rodrigues,J.S., Soares,E.C.S., Xavier,C.A.D., Araujo,A.S.F., Zerbini,F.M., Beserra,J.E.A. Jr. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
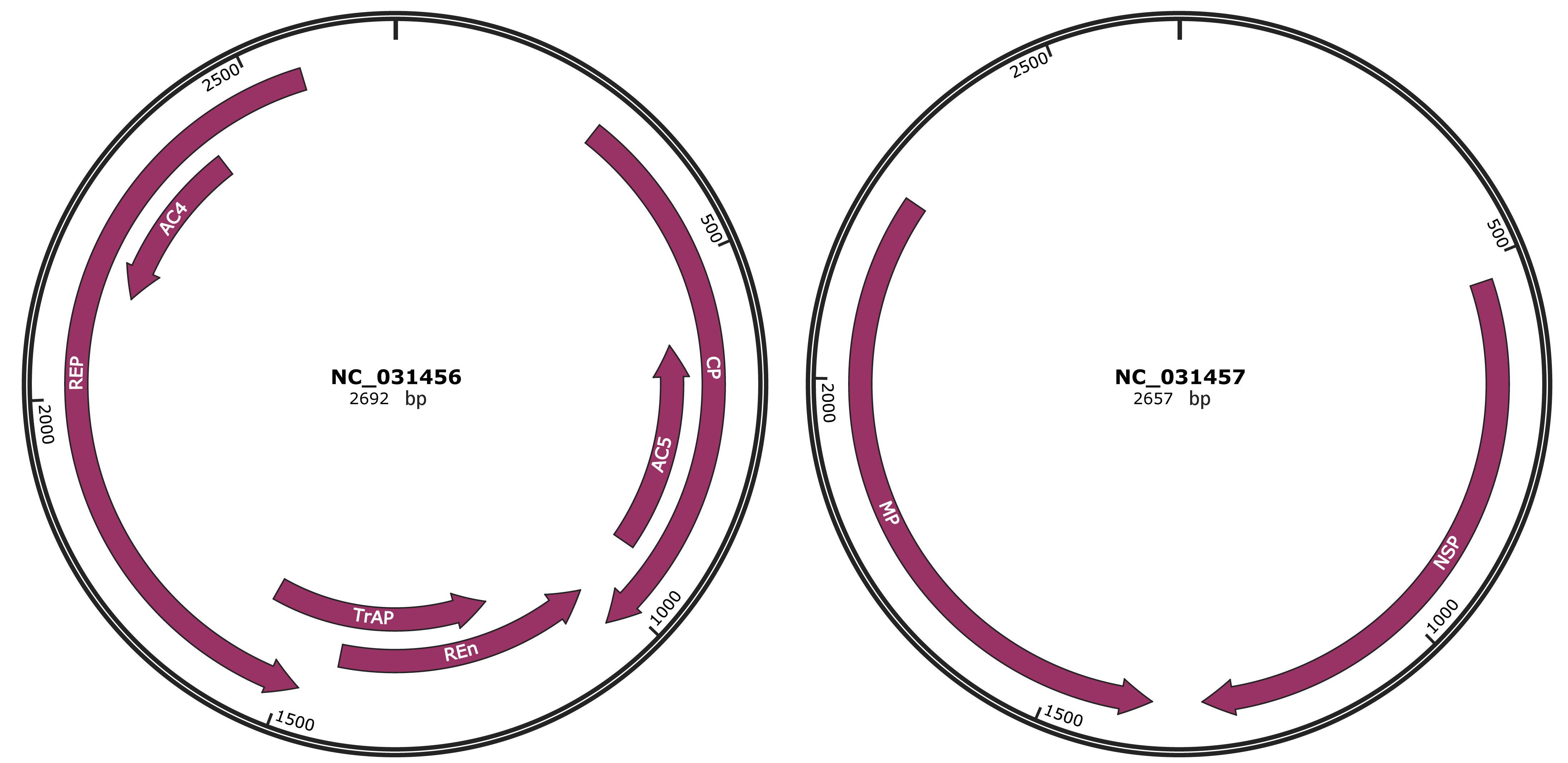
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCCCCCTACGTGGCGCGCTGGTGCCCGTCGGATCCTTCCCTCCCTGGTGGTCCCCTATTCATTGGTGCTCTCGTGTACTCTCATTCGGTGCTTCGGGCCAAGCCTGTTAAGTAAACTTTAATTCAAATTAAAGTTTAAGGCTTTTGTTTGGACCAATGGCGTTACGGCTGACGAGTCTAGATATCTGTGCTAAGACTTGGGCCCGAAGTTGCTGACGGCTATAAAATTAAATAAGCGATGACGTCAGTCATCAATTCAGAATGCCTAAGCGGGAAGCCCGTTGGCGCCTGTTGGCGGGAACCTCAAAGGTAAGCCGGTCAGCAAATTACAGCCCTCGTGGTGGGCTTAAATTCAACAAGGCCACAGAATGGGTCAACAGGCCTATGTACAGGAAGCCCAGAGTTTACCGGGCTTATAGATCAGCGGACGTACCCAAAGGGTGTGAGGGGCCTTGTAAGGTGCAGTCCTATGAGCAGAGACACGACATATCTCATGTCGGTAAGGTCATGTGCATCTCTGATGTTACACGTGGCAATGGCATCACTCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATATTAGGTAAGATATGGATGGACGAGAACATCAAGTTGAAGAACCACACGAATAGTGTCATGTTCTGGTTGGTCAGAGACCGCAGACCATATGGAACACCAATGGATTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCTAGTACTGCTACTGTTAAGAACGATCTCCGTGATCGTTATCAGGTTATGCACAAGTTCTATGGTAAGGTGACAGGTGGCCAATATGCCAGCAATGAACAGGCGATAGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTATAATCATCAGGAAGCTGGCAAGTACGAGAATCATACGGAGAACGCATTACTACTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATTTCAAATTAATAAAGTTTAAATTTTATTGAATGACGTTCGAGTACATGGCTTACATATTTTTTGTCCGTTGCGAAATCAACGGCTCTAATTACATTGTTAACAGAAATTACACCTAATCTATCTAAGTACAACATGACTAAGTCACTAAACCTAGTCAAATAAGTCGTTCCAGAAGCTGTCAGACAAGTCGTCCAGACTTGGAAATTGAGGAATGCCTTGTGGAGACCCAATGCTCTCCTGAGGTTGTGGTTGAACCTTATCTGTATGTTGTACACTCGTGTCGACGTGTACATCAGGTCCTCTACGTGGTACATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATAGACGCCATTCTCTGCCTGAAGTGCAGTGATGAACTCCCCGGTGCGTGTATCCATGGCCGGTGCAATTGAGGTGCTGATATATCGAGCACCCGCAGTCGAGATCAACTCGTCGTCGCCTGATCGCCCTCTTCTTCGCAATCCTGTGTCTCTGTTTGATAGAGGGGGGAGTCGAGGAAGATGAATTTAGCATTGTGTAATGTCCAGGCTCTTAAAGATGAGTTTTCCTCTTTGTCGAGGAAATCTTTATAGCTGGCCCCCTCTCCAGGATTGCAAAGCACGATTGAAGGAATTCCGCCTTTAATTTGAACAGGCTTTCCGTACTTACAGTTGGACTGCCAGTCTTTTTGAGCACCTATCAATTCCTTCCAGTGCTTTAACTTTAGATATTGCGGACTGACATCATCGATGATGACGTTATACTCCACTTCGTTGGAGTAAACACGAGAATTGAAGTCCAGGTGTCCACTGAGATAATTATGTAGGCCCAAAGCACGAGCCCACATTGTTTTACCTGTTCGAGAATCACCTTCTATGATAATACTGACAGGCCTACAAGGCCGCGCAGCGGCACTGGTCCCAAAATACTCATCGGCCCATTCTTGCATCTCCTCTGGGACGTTAGTGAAGGAGGAGAGTTGAAACGGAGGGACCCATGGTTCCGAAGCCTTTTTGAAAATCTTGTCCAGGTTACTCGACAGATTATGGTATTGGAACAGGAACTTTTCCGGCAACCTCTCTTTTATGATTTTCATGGCTAACTCTTTCGACGGAGCGTTCAATGCGTCGGCGGCTGCGTCGTTAGCTGTTTGGCAACCTCCTCTAGCACTGCGACCGTCGATCTGGAATTCTCCCCACTCGATGGTGTCCCCGTCTTTCTCGACATAGGACTTGACGTCGGAGCTCGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTAGGGGACACCAGATCGAACTGTCGGATATTTGTGATCTGCACTTTCCCTTCGAGTTGTAAGAGAATATGGAGGTGAGGTTGCCCATCGTCGTGAAGCTCTCTGGCGATTTTGATGAACTTTTTGTTCGATGGGAGAGGGATACTCTGTAATTGGGAAAGTGCTTCTTCTTTTGACAGAGAACACTGTGGATAAGTGAGGAAAATATTTTTGGACTGGAGCCTAAATCGTTTGGGCGGTGGCATTTTTGTAATAAGAGGGGTGTACTCCAATTGAGCTCCTCTTCAAAAACTCATATCAATTGGAGTAAAAGAGTACAATATATAGTAGAAGTTCCTAGGGGGCACGTGGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGCGATTTTTTGCCCCCCCCCCCTACGTGGCGCACTGGTGCCCGTCGGATCATTCCCTCCCTGGTGGTCCCCTCTCCCTTGGTACTCCTTTCCCTCTTGGTGCCCGCTCTCTTTTGACGAGGTCAAATTCGGTTGAGCGCTATTTTGGAGTCCGGGAATTTATCTGAGCGCATTTTTTGAGTTCCGCCAATGGTTATGTTCCAGGTGGCGTAAATAACTGTTTAGTGGTCAAGCATTTTAATGCTTTATATCTTGATTCATCTGAGACCATTGGCTAAAAATAAAAATGCAACGGCTGGATTTAATTTACGAATTTGAATAATTGTGGCGCAATTGAACTTTATGCCGTCCAATGATGTTGATGTTGTCTCTAGGGTCATCGTAGGAAACGTATGACGTGGGTCAATTGCGTCCATGTTGTAAAATCTATATATATTTTATTCATATTCAAGTTGTGGTCTATATATGGTGACGAAGTTAGAATTATTTACAGGTGTCTTAATTAACGCTTGAATATGTATTCTCAGAGGTTTAAACGAGGTTGGTCGTCCAGTCAGAAACGTTGTTATCGGCGTAACAATCTGATTAGGCAACCTTATAATGTTAAGCGTGTTGATAGCAAGCGACGACCAAGTGCTCATCAGAAGGCCCATGATGATAGTAAAATGGCAGCCCAGAAAATACACGAGAATCAGTTTGGGCCGGACTTTGTTATGGGCCAGAATGCTGCCATATCTACGTTCATTACGTTCCCTGGACTCGGTAAGACTGAACCTTGTCGAACGAGATCATATATTAAGTTAAAACGACTCCGTTTTAAAGGTACTGTCAAGATTGAGCGTGTTCATGCTGACGTCAACATGGATGGTTTAGCACCCAAGACTGAAGGAGTCTTCTCTTTGGTAATAGTTGTTGACCGTAAACCACATTTGGGTGCATCTGGCTCTCTGCACACTTTTGACGAACTATTCGGTGCACGGATCCATAGCCATGGTAATTTATCCATTATTCCTGCACTGAAAGACCGGTTCTACATAAGACACGTGCACAAACGTGTGTTGTCCGTGGAGAAGGACACGTTGATGGTCGATATTGAAGGGACGACATCGTTTTCTAACAAGCGTTTTAATTGTTGGTCATCGTTTAGAGATGTTGACCGTGAATCATGTAACGGCGTCTATGCAAACATAAGCAAGAACGCTTTGTTAGTTTATTATTGTTGGATGTCGGAAACCATGTCTAAGGCATCTACGTTTGTATCGTTCGATCTGGATTATATTGGTTAAATATAATTATTAAGAAACAATTATCATAAGATATGATTTGCTCGATTTGTCTTCTCCCTTTACAATTTAATTTAAAGGTTTGGGCTGAGAAGGAGTACAGTTACTGTTGATACACTCTTGGGCCGTGGCCCTTACAAGTTCATTTAATTGGGCCATTGACAGTGTTATGTTGGATTCCGCGCGCCTGGCAGCACATATTGATGCTGAGTCACCTGGGTCTAACATGCTGGTCCCAAGTCTATGAAGGCCTCTGTATGGATGTGCTGCGTTTTCTGATTCCGAATCCGCACTTGACTGACCTATGCCGATTGTGCTTCTGGCAGCCCATGTCTCACCTGGATCTATAGTTATTGGGCTGTGAAGCCCATATTTCGATGTGGATGCGGATCGGATCAGTTTCCTTTCCCATTTGCCATAGCCCACATGGCAGAAGTCGACGTCCCTGTCGGAGAACTGTTTGGATAAGATCTTGACCGTCGGTGCTCGGAAAGGAATATCGACCGAGTGTTTCGCAGTCGACAGCTTCAGCTTTCCCTTGAATTTCGCGAAGTGGGTCCTCTGATGGACATTTGTATCGCTGACCCTGTAGTACAATTTCCATGGAATTGGGTCTTTAAGGGAGAAGAATGACGACGAGAAGTAGTGCAGATCGATGTTGCATCTGATCGGGAATGTCCATGACGCCTGTAAAGACTCGTTGTCCGTCATCCTCTGGTCATGAATTTCAACGATCACCGATCCTGATGCGTTGATTGGGACTTGCTGTCTGTACTCGATGACGCAATGATCAATTTTCATACAGCTGCGACTGAGTCTGGCACTGAGTTGAGCTGCAGTTGAAGGGAACTGCAGTATGATCTCTGTAAGATCATGAGATAATTGATATTCATCACGCTGGGATTCTATGTAATTGAAAGCGTTAGGAGGATTGACTAACTGGGATTCCATTTGACTGTTTAAGTTATCTGATAGGGCCGCGCAGCGGGAATGATCAAGAAATTACTTGGTTAAGAGGAAGGATAAGCAAGCTTAGAGAAATCCAACAAGAGATCAAAGCCTATGAAGCAGTTAGGGAAGAAATTGATATTAAGAAACTAATTGAACTGGAAGAGAGTGATTAGGGATTTTAATCTTTATTAGGGTTTCAGAGGGCTGAGAGTTTTGTCGACGGATTGAGAGGAGATGTTAACCAGTCTATTTATAGACTCTAAGAGTAAAGTGATCTCAGTGGCATTTTTGTAATAAGAGGGGTGTACTCCGATTGAGCTCCTCTTCAAAAACTCATATCAATTGGAGTAAAAGAGTACAATATATAATAGAAGTTCCTATGGGGCACGTGGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009310082.1
|
|
Location
|
287-1036 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGAAGCCCGTTGGCGCCTGTTGGCGGGAACCTCAAAGGTAAGCCGGTCAGCAAATTACAGCCCTCGTGGTGGGCTTAAATTCAACAAGGCCACAGAATGGGTCAACAGGCCTATGTACAGGAAGCCCAGAGTTTACCGGGCTTATAGATCAGCGGACGTACCCAAAGGGTGTGAGGGGCCTTGTAAGGTGCAGTCCTATGAGCAGAGACACGACATATCTCATGTCGGTAAGGTCATGTGCATCTCTGATGTTACACGTGGCAATGGCATCACTCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATATTAGGTAAGATATGGATGGACGAGAACATCAAGTTGAAGAACCACACGAATAGTGTCATGTTCTGGTTGGTCAGAGACCGCAGACCATATGGAACACCAATGGATTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCTAGTACTGCTACTGTTAAGAACGATCTCCGTGATCGTTATCAGGTTATGCACAAGTTCTATGGTAAGGTGACAGGTGGCCAATATGCCAGCAATGAACAGGCGATAGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTATAATCATCAGGAAGCTGGCAAGTACGAGAATCATACGGAGAACGCATTACTACTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATTTCAAATTAA |
|
Protein Sequence
|
MPKREARWRLLAGTSKVSRSANYSPRGGLKFNKATEWVNRPMYRKPRVYRAYRSADVPKGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009310083.1
|
|
Location
|
614-931 |
|
Gene Name
|
AC5 |
|
Protein Name
|
AC5 |
|
Coding Region
|
ATGATTCTCGTACTTGCCAGCTTCCTGATGATTATAGACCACATGATTGTTGACCTTCCAGAACCTCTTGACTATCGCCTGTTCATTGCTGGCATATTGGCCACCTGTCACCTTACCATAGAACTTGTGCATAACCTGATAACGATCACGGAGATCGTTCTTAACAGTAGCAGTACTAGGCTCGTTGTCAAACATGTTGAACACCTGGCCAAAATCCATTGGTGTTCCATATGGTCTGCGGTCTCTGACCAACCAGAACATGACACTATTCGTGTGGTTCTTCAACTTGATGTTCTCGTCCATCCATATCTTACCTAA |
|
Protein Sequence
|
MILVLASFLMIIDHMIVDLPEPLDYRLFIAGILATCHLTIELVHNLITITEIVLNSSSTRLVVKHVEHLAKIHWCSIWSAVSDQPEHDTIRVVLQLDVLVHPYLT |
|
NCBI Accession
|
YP_009310084.1
|
|
Location
|
1033-1431 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATACACGCACCGGGGAGTTCATCACTGCACTTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGTACCACGTAGAGGACCTGATGTACACGTCGACACGAGTGTACAACATACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTCAATTTCCAAGTCTGGACGACTTGTCTGACAGCTTCTGGAACGACTTATTTGACTAGGTTTAGTGACTTAGTCATGTTGTACTTAGATAGATTAGGTGTAATTTCTGTTAACAATGTAATTAGAGCCGTTGATTTCGCAACGGACAAAAAATATGTAAGCCATGTACTCGAACGTCATTCAATAAAATTTAAACTTTATTAA |
|
Protein Sequence
|
MDTRTGEFITALQAENGVYIWEITNPLYFKMYHVEDLMYTSTRVYNIQIRFNHNLRRALGLHKAFLNFQVWTTCLTASGTTYLTRFSDLVMLYLDRLGVISVNNVIRAVDFATDKKYVSHVLERHSIKFKLY |
|
NCBI Accession
|
YP_009310085.1
|
|
Location
|
1178-1567 |
|
Gene Name
|
TrAP |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACAGAGACACAGGATTGCGAAGAAGAGGGCGATCAGGCGACGACGAGTTGATCTCGACTGCGGGTGCTCGATATATCAGCACCTCAATTGCACCGGCCATGGATACACGCACCGGGGAGTTCATCACTGCACTTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGTACCACGTAGAGGACCTGATGTACACGTCGACACGAGTGTACAACATACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTCAATTTCCAAGTCTGGACGACTTGTCTGACAGCTTCTGGAACGACTTATTTGACTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKQRHRIAKKRAIRRRRVDLDCGCSIYQHLNCTGHGYTHRGVHHCTSGREWRLYLGDNKSPVFQDVPRRGPDVHVDTSVQHTDKVQPQPQESIGSPQGIPQFPSLDDLSDSFWNDLFD |
|
NCBI Accession
|
YP_009310086.1
|
|
Location
|
1479-2567 |
|
Gene Name
|
REP |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCGCCCAAACGATTTAGGCTCCAGTCCAAAAATATTTTCCTCACTTATCCACAGTGTTCTCTGTCAAAAGAAGAAGCACTTTCCCAATTACAGAGTATCCCTCTCCCATCGAACAAAAAGTTCATCAAAATCGCCAGAGAGCTTCACGACGATGGGCAACCTCACCTCCATATTCTCTTACAACTCGAAGGGAAAGTGCAGATCACAAATATCCGACAGTTCGATCTGGTGTCCCCTACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATGTCGAGAAAGACGGGGACACCATCGAGTGGGGAGAATTCCAGATCGACGGTCGCAGTGCTAGAGGAGGTTGCCAAACAGCTAACGACGCAGCCGCCGACGCATTGAACGCTCCGTCGAAAGAGTTAGCCATGAAAATCATAAAAGAGAGGTTGCCGGAAAAGTTCCTGTTCCAATACCATAATCTGTCGAGTAACCTGGACAAGATTTTCAAAAAGGCTTCGGAACCATGGGTCCCTCCGTTTCAACTCTCCTCCTTCACTAACGTCCCAGAGGAGATGCAAGAATGGGCCGATGAGTATTTTGGGACCAGTGCCGCTGCGCGGCCTTGTAGGCCTGTCAGTATTATCATAGAAGGTGATTCTCGAACAGGTAAAACAATGTGGGCTCGTGCTTTGGGCCTACATAATTATCTCAGTGGACACCTGGACTTCAATTCTCGTGTTTACTCCAACGAAGTGGAGTATAACGTCATCATCGATGATGTCAGTCCGCAATATCTAAAGTTAAAGCACTGGAAGGAATTGATAGGTGCTCAAAAAGACTGGCAGTCCAACTGTAAGTACGGAAAGCCTGTTCAAATTAAAGGCGGAATTCCTTCAATCGTGCTTTGCAATCCTGGAGAGGGGGCCAGCTATAAAGATTTCCTCGACAAAGAGGAAAACTCATCTTTAAGAGCCTGGACATTACACAATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACAGAGACACAGGATTGCGAAGAAGAGGGCGATCAGGCGACGACGAGTTGA |
|
Protein Sequence
|
MPPPKRFRLQSKNIFLTYPQCSLSKEEALSQLQSIPLPSNKKFIKIARELHDDGQPHLHILLQLEGKVQITNIRQFDLVSPTRSAHFHPNIQGAKSSSDVKSYVEKDGDTIEWGEFQIDGRSARGGCQTANDAAADALNAPSKELAMKIIKERLPEKFLFQYHNLSSNLDKIFKKASEPWVPPFQLSSFTNVPEEMQEWADEYFGTSAAARPCRPVSIIIEGDSRTGKTMWARALGLHNYLSGHLDFNSRVYSNEVEYNVIIDDVSPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENSSLRAWTLHNAKFIFLDSPLYQTETQDCEEEGDQATTS |
|
NCBI Accession
|
YP_009310087.1
|
|
Location
|
2153-2410 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGCAACCTCACCTCCATATTCTCTTACAACTCGAAGGGAAAGTGCAGATCACAAATATCCGACAGTTCGATCTGGTGTCCCCTACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATGTCGAGAAAGACGGGGACACCATCGAGTGGGGAGAATTCCAGATCGACGGTCGCAGTGCTAGAGGAGGTTGCCAAACAGCTAACGACGCAGCCGCCGACGCATTGA |
|
Protein Sequence
|
MGNLTSIFSYNSKGKCRSQISDSSIWCPLPGQHISIQTFRELNRAPTSSPMSRKTGTPSSGENSRSTVAVLEEVAKQLTTQPPTH |
|
NCBI Accession
|
YP_009310088.1
|
|
Location
|
528-1298 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTCTCAGAGGTTTAAACGAGGTTGGTCGTCCAGTCAGAAACGTTGTTATCGGCGTAACAATCTGATTAGGCAACCTTATAATGTTAAGCGTGTTGATAGCAAGCGACGACCAAGTGCTCATCAGAAGGCCCATGATGATAGTAAAATGGCAGCCCAGAAAATACACGAGAATCAGTTTGGGCCGGACTTTGTTATGGGCCAGAATGCTGCCATATCTACGTTCATTACGTTCCCTGGACTCGGTAAGACTGAACCTTGTCGAACGAGATCATATATTAAGTTAAAACGACTCCGTTTTAAAGGTACTGTCAAGATTGAGCGTGTTCATGCTGACGTCAACATGGATGGTTTAGCACCCAAGACTGAAGGAGTCTTCTCTTTGGTAATAGTTGTTGACCGTAAACCACATTTGGGTGCATCTGGCTCTCTGCACACTTTTGACGAACTATTCGGTGCACGGATCCATAGCCATGGTAATTTATCCATTATTCCTGCACTGAAAGACCGGTTCTACATAAGACACGTGCACAAACGTGTGTTGTCCGTGGAGAAGGACACGTTGATGGTCGATATTGAAGGGACGACATCGTTTTCTAACAAGCGTTTTAATTGTTGGTCATCGTTTAGAGATGTTGACCGTGAATCATGTAACGGCGTCTATGCAAACATAAGCAAGAACGCTTTGTTAGTTTATTATTGTTGGATGTCGGAAACCATGTCTAAGGCATCTACGTTTGTATCGTTCGATCTGGATTATATTGGTTAA |
|
Protein Sequence
|
MYSQRFKRGWSSSQKRCYRRNNLIRQPYNVKRVDSKRRPSAHQKAHDDSKMAAQKIHENQFGPDFVMGQNAAISTFITFPGLGKTEPCRTRSYIKLKRLRFKGTVKIERVHADVNMDGLAPKTEGVFSLVIVVDRKPHLGASGSLHTFDELFGARIHSHGNLSIIPALKDRFYIRHVHKRVLSVEKDTLMVDIEGTTSFSNKRFNCWSSFRDVDRESCNGVYANISKNALLVYYCWMSETMSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_009310089.1
|
|
Location
|
1365-2246 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCCCAGTTAGTCAATCCTCCTAACGCTTTCAATTACATAGAATCCCAGCGTGATGAATATCAATTATCTCATGATCTTACAGAGATCATACTGCAGTTCCCTTCAACTGCAGCTCAACTCAGTGCCAGACTCAGTCGCAGCTGTATGAAAATTGATCATTGCGTCATCGAGTACAGACAGCAAGTCCCAATCAACGCATCAGGATCGGTGATCGTTGAAATTCATGACCAGAGGATGACGGACAACGAGTCTTTACAGGCGTCATGGACATTCCCGATCAGATGCAACATCGATCTGCACTACTTCTCGTCGTCATTCTTCTCCCTTAAAGACCCAATTCCATGGAAATTGTACTACAGGGTCAGCGATACAAATGTCCATCAGAGGACCCACTTCGCGAAATTCAAGGGAAAGCTGAAGCTGTCGACTGCGAAACACTCGGTCGATATTCCTTTCCGAGCACCGACGGTCAAGATCTTATCCAAACAGTTCTCCGACAGGGACGTCGACTTCTGCCATGTGGGCTATGGCAAATGGGAAAGGAAACTGATCCGATCCGCATCCACATCGAAATATGGGCTTCACAGCCCAATAACTATAGATCCAGGTGAGACATGGGCTGCCAGAAGCACAATCGGCATAGGTCAGTCAAGTGCGGATTCGGAATCAGAAAACGCAGCACATCCATACAGAGGCCTTCATAGACTTGGGACCAGCATGTTAGACCCAGGTGACTCAGCATCAATATGTGCTGCCAGGCGCGCGGAATCCAACATAACACTGTCAATGGCCCAATTAAATGAACTTGTAAGGGCCACGGCCCAAGAGTGTATCAACAGTAACTGTACTCCTTCTCAGCCCAAACCTTTAAATTAA |
|
Protein Sequence
|
MESQLVNPPNAFNYIESQRDEYQLSHDLTEIILQFPSTAAQLSARLSRSCMKIDHCVIEYRQQVPINASGSVIVEIHDQRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSDRDVDFCHVGYGKWERKLIRSASTSKYGLHSPITIDPGETWAARSTIGIGQSSADSESENAAHPYRGLHRLGTSMLDPGDSASICAARRAESNITLSMAQLNELVRATAQECINSNCTPSQPKPLN |