Sauropus leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002823285.1 |
| Isolate |
Thailand: Kamphaengsaen |
| Release date |
2018/8/25 |
| Submitter |
Shih,S.L., Tsai,W.S., Lee,L.M., Kenyon,L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
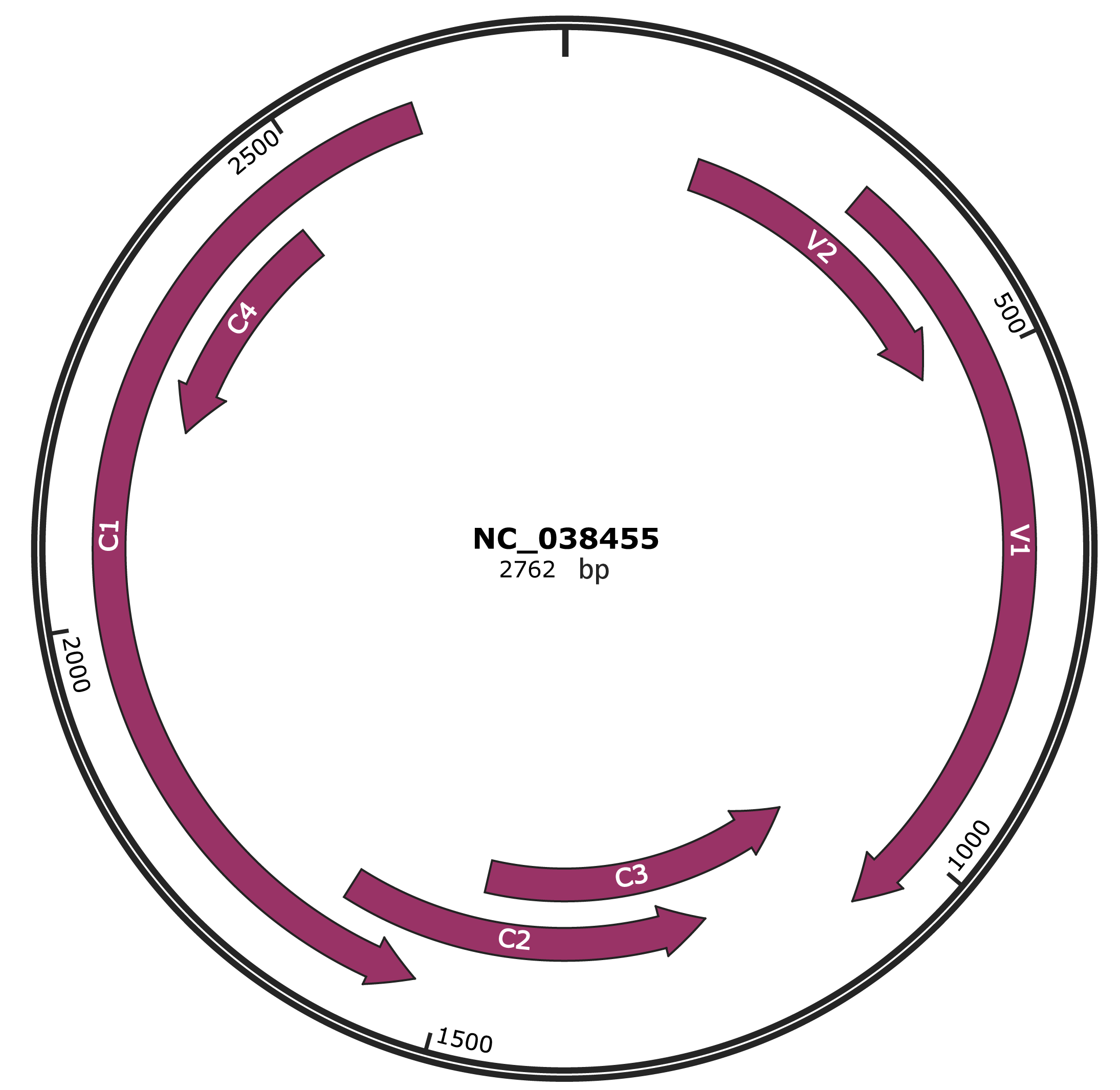
JBrowse
Genome
ACCGGATGGCCGCGCAAATTTTTGTCCCCTTTCGCTTTAGTGGTTCCCACGCACTATCTTTGGTCGGCCAATGAGAATGCGCGCTCAAAGCTTAGATATCCGTGTGGTCCCGTCATAAATAACTTCCCCTCGAAGGTAAATTCAAAATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGCTTTAGGTGTATGTTAGCAGTCAAATACCTGCAGTTAGTAGAGAAGACGTATTCGCCTGACACATTAGGGCACGATCTTATACGAGATTTAATATCAGTAATTCGTGCTCGCAATTATGTCGAAGCGACCCGCCGATATAGTCATTTCAACTCCCGCCTCGAAGGTACGACGTCGTCTGAACTTCGACACCCCCGTGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAAAAGGATATGGACCAACAGGCCCATGTATCGCAAGCCCAGATTCTACAGAGTGTACAAAAGCCCTGATGTGCCCCGTGGTTGTGAGGGTCCCTGTAAGGTCCAGTCGTTCGAGAAGAAGCATGATGTGGGTCATACTGGTACATTATTATGTGTGTCGGATGTTACTCGTGGAAATGGGCTTACCCATCGTGTTGGTAAGAGGTTTTGTATTAAGTCTATTTACATTCTGGGTAAGTTATGGATGGATGAGAACATCAAGACGAAGAATCACACGAACACAGTCATGTTCTGGTTAGTTAGGGATAGGCGTCCTATGACAACGCCCTATGGGTTCGGCGAGGCATTCAACATGTACGACAATGAGCCCAGTACAGCCACTATCAAGAACGATCTTCGTGATCGTCTGCAGGTGCTGCATAGGTTTCAAGCCACGCTCACGGGAGGTCAGTACGCGTGCAAGGAACAGGTCATGGTGAAGAGGTTCTGGAAGATCAACAATCACGTCGTGTACAACCATCAGGAGAAGGCTGCTTACGAGAATCACAATGAGAACGCATTAATATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACACTGAAGATCCGCATCTACTTCTATGATTCAGTGCAGAATTAATAAAGATTATATTTTATTATATGTGTCAATTGAGCATCAATTGTGCCCTCCAGTACATCGTACAGTACATGATCAATAGCCCTAATTACATTGTTAATGCTAATAACTCCTAATGTATCTAAATACTTCATACATTGAATATTAAATACTCTTAAGAAACGCCCAGTCTGAGGACGTAAACGAGTCCAGATCTGGCAGATCAGGAAACATTGGTGCATCCCCAGTGCTTTCCTCAGGTTGTAGTTGAACTGGACCTGGATTGTTATTACGTCGTGGTCCGTCAGGAATGGCCTCTCCAGGTGCTTGGTAATCTTGAAATAGAGGGGATTTCTGACCGTCCAGGTATAGACGCCACTCTCTGCCTGAGTTGCAGTGATGTACTCCCCGGTGCGAAAATCCATGGTTTGCACAGGTAATTGGGAAGAAGTACGAGCACCCGCAAGGTAGATCAACTCTCCTCCTGCGGATCGTCTTCTTCTTGGCTATTCTGTGCTGGACTTTGATGGGTACCTGAGTACAGTTGCTCTGAGAGGAAGATGAATTTTGCATTCTTCAGTGCCCACGATTTTAGAGCTGAATTTTTATCCTCATCCAGATATTCCTTATATGATGATGTTGGACCAGGATTGCATAGGAAGATTGTCGGAATGCCCCCTTTAATTTGAATTGGCTTCCCGTACTTGGTATTGCTTTGCCAATCCCTCTGGGCCCCCATGAATTCTTTAAAGTGTTTCAGATAGTGGGGGTCAACATCATCGATGACGTTATACCATGCGTCATTAGAGTAGATCTTGGGGCTCAAGTCTAGATGCCCACAAAGGTAATTATGTGGGCCTAGTGATCTGGCCCACATTGTTTTCCCAGTTCTACTCTCTCCCTCTATCACTATACTCACCGGTCTCCAAGGCCGCGCAGCGGCATCCCTGACATTCTCCTCCGCCCAACATTCAAGTTCTTCCGGAACTTGATCGAATGAAGAAGCTAAAAAAGGAGAAACAAAAACCTCTACGGGAGGTGAAAAAATTCTATCTAAATTAGCATTTAAATTATGAAATTGAAAAATATAATCTTTTGGGAGTTTTTCCCTTATTATATTTAATGCTGCTTCTTTAGAACCTGCATTTAAGGCTTCTGCGCATGCGTCGTTAGCATTCTGGCAGCCCCCTCTAGCACTTCTAGCGTCGATCTGGAATTCTCCCCAGTCGAGGGTGTCTCCGTCCTTGTCCAGATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGCCCTGGTTGGGGACACCAGGTCGAAGAATCTGTTATTCGAGCAGTTGTATTTCCCTTCGAATTGGATGAGCACGTGGAGATGAGGGCTCCCATCTTCGTGTAACTCTCTGCAGATTTTGATATATTTTTTATTTGTTGGGGTTTTTAGGTTTTGGATTTGGGAAAGTGCTTCTTCCTTTGTGAGTGAGCACTGAGGATATGTAAGAAAATAATTTTTTGCTTTAATAGAAAAACGTCCGGCTCTAGGCATTTTGGAATTGGGGGGCACTCTAAGTCTCTGCAATCGGGGGAAATGGGGGGCAATTTATATGTGCCCCCCAAATGGCATTCTCGTAATTCCTAAAAGAAAGTCAAATTCAAATTCAAATTCTAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506455.1
|
|
Location
|
147-497 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGCTTTAGGTGTATGTTAGCAGTCAAATACCTGCAGTTAGTAGAGAAGACGTATTCGCCTGACACATTAGGGCACGATCTTATACGAGATTTAATATCAGTAATTCGTGCTCGCAATTATGTCGAAGCGACCCGCCGATATAGTCATTTCAACTCCCGCCTCGAAGGTACGACGTCGTCTGAACTTCGACACCCCCGTGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAAAAGGATATGGACCAACAGGCCCATGTATCGCAAGCCCAGATTCTACAGAGTGTACAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLQLVEKTYSPDTLGHDLIRDLISVIRARNYVEATRRYSHFNSRLEGTTSSELRHPRDEPCCCPHCPRHQQKKDMDQQAHVSQAQILQSVQKP |
|
NCBI Accession
|
YP_009506456.1
|
|
Location
|
307-1080 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGCCGATATAGTCATTTCAACTCCCGCCTCGAAGGTACGACGTCGTCTGAACTTCGACACCCCCGTGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAAAAGGATATGGACCAACAGGCCCATGTATCGCAAGCCCAGATTCTACAGAGTGTACAAAAGCCCTGATGTGCCCCGTGGTTGTGAGGGTCCCTGTAAGGTCCAGTCGTTCGAGAAGAAGCATGATGTGGGTCATACTGGTACATTATTATGTGTGTCGGATGTTACTCGTGGAAATGGGCTTACCCATCGTGTTGGTAAGAGGTTTTGTATTAAGTCTATTTACATTCTGGGTAAGTTATGGATGGATGAGAACATCAAGACGAAGAATCACACGAACACAGTCATGTTCTGGTTAGTTAGGGATAGGCGTCCTATGACAACGCCCTATGGGTTCGGCGAGGCATTCAACATGTACGACAATGAGCCCAGTACAGCCACTATCAAGAACGATCTTCGTGATCGTCTGCAGGTGCTGCATAGGTTTCAAGCCACGCTCACGGGAGGTCAGTACGCGTGCAAGGAACAGGTCATGGTGAAGAGGTTCTGGAAGATCAACAATCACGTCGTGTACAACCATCAGGAGAAGGCTGCTTACGAGAATCACAATGAGAACGCATTAATATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACACTGAAGATCCGCATCTACTTCTATGATTCAGTGCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDTPVMSRAAAPTVLVTNKKRIWTNRPMYRKPRFYRVYKSPDVPRGCEGPCKVQSFEKKHDVGHTGTLLCVSDVTRGNGLTHRVGKRFCIKSIYILGKLWMDENIKTKNHTNTVMFWLVRDRRPMTTPYGFGEAFNMYDNEPSTATIKNDLRDRLQVLHRFQATLTGGQYACKEQVMVKRFWKINNHVVYNHQEKAAYENHNENALILYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_009506457.1
|
|
Location
|
1077-1481 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTTTCGCACCGGGGAGTACATCACTGCAACTCAGGCAGAGAGTGGCGTCTATACCTGGACGGTCAGAAATCCCCTCTATTTCAAGATTACCAAGCACCTGGAGAGGCCATTCCTGACGGACCACGACGTAATAACAATCCAGGTCCAGTTCAACTACAACCTGAGGAAAGCACTGGGGATGCACCAATGTTTCCTGATCTGCCAGATCTGGACTCGTTTACGTCCTCAGACTGGGCGTTTCTTAAGAGTATTTAATATTCAATGTATGAAGTATTTAGATACATTAGGAGTTATTAGCATTAACAATGTAATTAGGGCTATTGATCATGTACTGTACGATGTACTGGAGGGCACAATTGATGCTCAATTGACACATATAATAAAATATAATCTTTATTAA |
|
Protein Sequence
|
MDFRTGEYITATQAESGVYTWTVRNPLYFKITKHLERPFLTDHDVITIQVQFNYNLRKALGMHQCFLICQIWTRLRPQTGRFLRVFNIQCMKYLDTLGVISINNVIRAIDHVLYDVLEGTIDAQLTHIIKYNLY |
|
NCBI Accession
|
YP_009506458.1
|
|
Location
|
1222-1629 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activation protein |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCTCAGAGCAACTGTACTCAGGTACCCATCAAAGTCCAGCACAGAATAGCCAAGAAGAAGACGATCCGCAGGAGGAGAGTTGATCTACCTTGCGGGTGCTCGTACTTCTTCCCAATTACCTGTGCAAACCATGGATTTTCGCACCGGGGAGTACATCACTGCAACTCAGGCAGAGAGTGGCGTCTATACCTGGACGGTCAGAAATCCCCTCTATTTCAAGATTACCAAGCACCTGGAGAGGCCATTCCTGACGGACCACGACGTAATAACAATCCAGGTCCAGTTCAACTACAACCTGAGGAAAGCACTGGGGATGCACCAATGTTTCCTGATCTGCCAGATCTGGACTCGTTTACGTCCTCAGACTGGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSSSQSNCTQVPIKVQHRIAKKKTIRRRRVDLPCGCSYFFPITCANHGFSHRGVHHCNSGREWRLYLDGQKSPLFQDYQAPGEAIPDGPRRNNNPGPVQLQPEESTGDAPMFPDLPDLDSFTSSDWAFLKSI |
|
NCBI Accession
|
YP_009506459.1
|
|
Location
|
1529-2617 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTAGAGCCGGACGTTTTTCTATTAAAGCAAAAAATTATTTTCTTACATATCCTCAGTGCTCACTCACAAAGGAAGAAGCACTTTCCCAAATCCAAAACCTAAAAACCCCAACAAATAAAAAATATATCAAAATCTGCAGAGAGTTACACGAAGATGGGAGCCCTCATCTCCACGTGCTCATCCAATTCGAAGGGAAATACAACTGCTCGAATAACAGATTCTTCGACCTGGTGTCCCCAACCAGGGCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATCTGGACAAGGACGGAGACACCCTCGACTGGGGAGAATTCCAGATCGACGCTAGAAGTGCTAGAGGGGGCTGCCAGAATGCTAACGACGCATGCGCAGAAGCCTTAAATGCAGGTTCTAAAGAAGCAGCATTAAATATAATAAGGGAAAAACTCCCAAAAGATTATATTTTTCAATTTCATAATTTAAATGCTAATTTAGATAGAATTTTTTCACCTCCCGTAGAGGTTTTTGTTTCTCCTTTTTTAGCTTCTTCATTCGATCAAGTTCCGGAAGAACTTGAATGTTGGGCGGAGGAGAATGTCAGGGATGCCGCTGCGCGGCCTTGGAGACCGGTGAGTATAGTGATAGAGGGAGAGAGTAGAACTGGGAAAACAATGTGGGCCAGATCACTAGGCCCACATAATTACCTTTGTGGGCATCTAGACTTGAGCCCCAAGATCTACTCTAATGACGCATGGTATAACGTCATCGATGATGTTGACCCCCACTATCTGAAACACTTTAAAGAATTCATGGGGGCCCAGAGGGATTGGCAAAGCAATACCAAGTACGGGAAGCCAATTCAAATTAAAGGGGGCATTCCGACAATCTTCCTATGCAATCCTGGTCCAACATCATCATATAAGGAATATCTGGATGAGGATAAAAATTCAGCTCTAAAATCGTGGGCACTGAAGAATGCAAAATTCATCTTCCTCTCAGAGCAACTGTACTCAGGTACCCATCAAAGTCCAGCACAGAATAGCCAAGAAGAAGACGATCCGCAGGAGGAGAGTTGA |
|
Protein Sequence
|
MPRAGRFSIKAKNYFLTYPQCSLTKEEALSQIQNLKTPTNKKYIKICRELHEDGSPHLHVLIQFEGKYNCSNNRFFDLVSPTRAAHFHPNIQGAKSSSDVKSYLDKDGDTLDWGEFQIDARSARGGCQNANDACAEALNAGSKEAALNIIREKLPKDYIFQFHNLNANLDRIFSPPVEVFVSPFLASSFDQVPEELECWAEENVRDAAARPWRPVSIVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNSALKSWALKNAKFIFLSEQLYSGTHQSPAQNSQEEDDPQEES |
|
NCBI Accession
|
YP_009506460.1
|
|
Location
|
2203-2460 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGCTCATCCAATTCGAAGGGAAATACAACTGCTCGAATAACAGATTCTTCGACCTGGTGTCCCCAACCAGGGCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATCTGGACAAGGACGGAGACACCCTCGACTGGGGAGAATTCCAGATCGACGCTAGAAGTGCTAGAGGGGGCTGCCAGAATGCTAACGACGCATGCGCAGAAGCCTTAA |
|
Protein Sequence
|
MGALISTCSSNSKGNTTARITDSSTWCPQPGQHISIQTFRELNPAPTSSPIWTRTETPSTGENSRSTLEVLEGAARMLTTHAQKP |