Bean chlorosis virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000902035.1 |
| Isolate |
Venezuela |
| Release date |
2015/2/22 |
| Submitter |
Fiallo-Olive,E., Marquez-Martin,B., Hassan,I., Chirinos,D.T., Geraud-Pouey,F., Navas-Castillo,J., Moriones,E., Chirinos,D. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
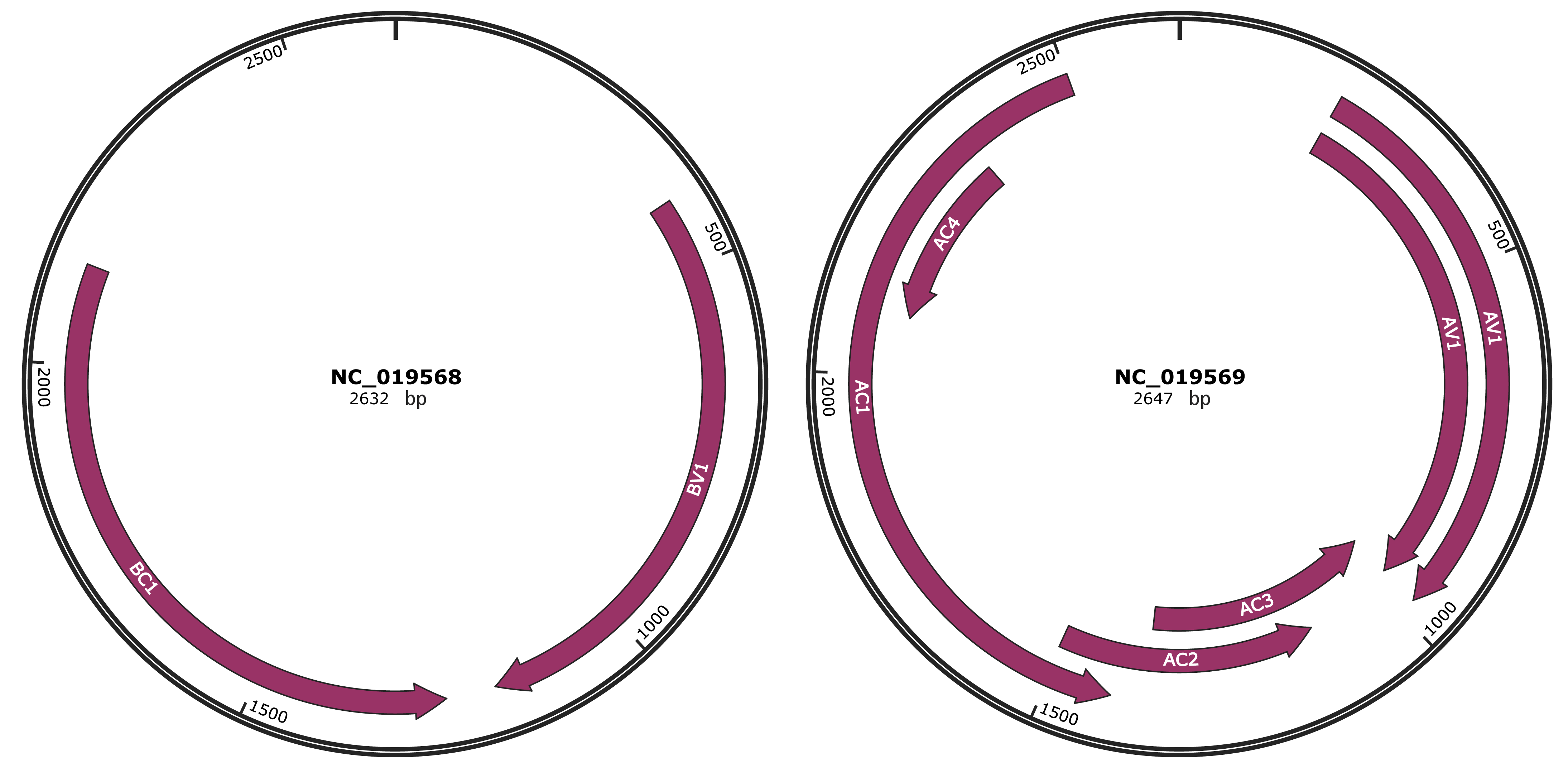
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCCCCCCCCCTACGTGGCGCTCTGGAGGCCGCGCGATCCCCTCGCGCCCCCTCACGCTCTCTCCCGCTTTGGAGGTGAAGACGCGCTCTCCCATTGGTGCTTTTGCTGCACGCGCGTCTTTTTGACCGCCCTTTAATTCAAATTAAAGGTTTAATCTTTTGTCGCGCGATTTGAATTATTGTCCCGCGACGTTTAAGTGTACCCCACTGTACTGCACGGTGGACGTGTCTAAATTCTGACCATGCTGCTGAGTCTATTTGCTATTTATGTTCAACTTGTTCAGTTATATATGTAGTGGAAATACATGTTAGTTCACATCTTATACAGCAATCCACCACGTCTATATAATNNNCNACTATTACTGTGTTTATCCATTATTATCTTTAGAAAATGCATTATTCTAGGAATAGACGTGGTTCTAACCCCGCTGGACGACGATATTATCCACGTAACACTGTGTTTACGCGTCTAACTCCATCGAAAAAGCATGGTGGGAAACGTGGAGGAGTCAATTCCAGCAAGTCCAGTGATGAGCCCAAGATGAAGGCCCAAGTCATACATGAGAATCAGTATGGGTCCAACTTTGTGTTGGCCCATAATTCAGCTATTTCTACCTACATCACTTATCCCAGCTTGGGGAAGACCGAACCTAGCAGGAGCAGATCCTATATTAAGTTGAAACGGTTACGTTTCAAAGGGACCGTGAAGATTGAACGTGTTCAACCGGACATGAATCTGGACGTTGCTATCCCCAAGGTGGAAGGAGTATTCACCGTCGTTGTGGTTGTGGATCGGAAACCCCATCTTGATCCATCTGGTGGACTGCATACTTTCGATGACCTCTTCGGTGCTAGGATACACAGCCACGGTAACCTCAGCATTATCCCGTCGCTGAAAGACCGCTACTGTATCCGACACGTGTGCAAACGTGTGTTGTCAGTGGAGAAGGACACGCTGATGGTAAATGTGGAAGGATCCATTCCCTTCTCTAACAGGCGTTATAATTGTTGGTCCACTTTTAAGGATCTGGATCGAGAATCATGTAATGGTGTTTATGGCAACATTAGCAAGAACGCCCTGTTAGTGTATTACTGCTGGATGTCGGATACTATGTCTAATGCATCCACATTTGTAACTTATGATCTGGATTATATTGGATGATTAATGAAGTAAACAATTTTATTTAGCCAAATGTGAACATTTTACTATGATGATCATAGTTACATTCTATTGCAATGATTTGGGCTGTGACGGTCTACAATTATTATTTATACATTCTTGGACCGTTGTCCTAACGAGCTCGTTCAACTGGCCCATAGACATCGTGATGTTTGACTCCGCTCTCTGGGCTCCCACCACTGAGGCAGACTCTCCTGGATCTAACACAGTGGTCCCAAGCCTGCTAAGGTGTCTGTAAGGGTGGAGTTCGTTCTCCACCTCCGAGTCCGCATCTGATTGACCCGTTCCTACAGTACTCCTGGAAGCCCACGATTCATCTGGTCTTAACTCAATTGGGCCTCTGAGCCCAAGTCTAGACATGGACGCGCATCTGATGGGCTTCCTTTCCCATCTTCCGTAGTCGACATGGGAGAAGTCCACATCTTTATCCGTGAACTGTTTGGACAGGATCTTTACTGTTGGTGACCGGAAAGGTATGTCGACGGAGTGTTTCGCCGTGGATAGTTTCAGCTTCCCCTTGAATTTCGCGAAGTGGGTCCTCTGATGAACATTCGTATCGCAAACTCTGTAATAGAGTTTCCATGGAATTGGGTCCTTGAGCGAGAAGAACGAAGCTGAAAAGTAGTGGAGATCTATGTTGCACCTGATCGGAAAAGTCCATGACGCCTGTAATGACTCGTTGTCCGTCATCCTTTTGTCGTGGATCTCCACAATTACGGATCCCGTCGCGTTGATCGGAACTTGCTGTCTGTACTCTATGACGCAGTGGTCGATCTTCATGCAACTACGACTCAGTCTAGCTGTCAACTGAGACGCCGTCGACGGAAATTGCAGAATTATCTCAGTTAGGTCATGAGAAAGCTGATATTCGTCCCGATGGGACTCGATGTAGTTAAAGGCACTTGGAGGATTAACTAACTGAGAATCCATTTCAAGAAAAATGGCCGCGCTAGCGGGACAGGTTGAAGAATCTGAACAAGGTGATAGTCGAACAGTTAACGAAGAAGGTAAACAGAGATATGTGACTGTGTCTGGGTTTAAGATCTATAAAATGCTTTGGGTGGTTATGAACTTGTTCGACTAATTATGGTTTAAGATGGAAATCTCGTTTAAGATCCCCAGTCTTTTTGAGAGAGAAAAGAGTGTTTATGAAGTAGCTGGGGATGATGAAGCTTGTGTTGTGAAGGTGTTTATATAGAACTCCAGAGGTTCTGGGTATTTAGGTTTTGTAATTGGGAAAGTGTTCTTATGTATTGAGAGAGCTTCGATGTTTAACTTGATGGCATTTTTGTAATAAAGGCTTGGACACCAAAGCGAGACACCAGTTGAGCTCTCTCAAACTATCTCATATGTATTGGTGTCTGGTGTCCTATATATACTAGAACCCTCAATAGATATTTGGTTCCTCCTAGCGGCCATCCGCACTAATATT
ACCGGATGGCCGCGCGATTTTCCCCCCCCCCTACGTGGCGCTTTGGTGGCCGCGCGATCCCCTCGCGCTTTCCCTTTAATTCAAATTAAAGGAACTAGCTTTTGTTTCGTCCAATGATAATGCGCCTGCCGCGCCTAGTTATTTCAAACAACTTGGGCCCTAAGTTGTTGTTGGTCTATAAATGAAAAGCTTACTGGGCCACACTCTTCAATTCGAAATGCCTAAGCGCGATCTCCCATGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGTAATGTCAATTACTCCCCTCGTGGAGGAGGTGGCCCAAAATCAAGTAGGGCCTCTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGGATGATCAGGACACCCGATGTGCCCAGAGGATGTGAAGGCCCGTGTAAGGTCCAGTCTTATGAACAGCGACACGACATCTCACATGTCGGCAAGGTCATGTGCATCTCCGATGTGACACGTGGTAATGGCATTACCCACCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATATTAGGTAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGGACGCCCATGGATTTTGGGCAAGTGTTCAACATGTTCGACAACGAGCCAAGCACTGCTACGGTTAAGAACGATCTTCGCGATCGTTACCAGGTCATGCATAAGTTCTATGGGAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAAGCCATTGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAGGCTGGCAAGTATGAGAATCACACGGAGAACGCACTTCTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACTTTGAAGATTCGAATCTATTTTTACGATTCGATCACGAATTAATAAAATTTGAATTTTATTGAATGATTTTCTAGTACATAATTTACATATGATTTGTCCGTTGCGAATCGTACAGCTCTAATTACATTGTTAAGCGATATTACGCCTAGCTGATCCAAGTACATCAAGACTAATTGTCTAAACCTAACTAAATAAGTCGTTCCAGAAGCTCTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGACCCAATGCTTTCCTGAGGTTGTGGTTGAACCGTATTTGTACGTGGTAGACTCTGGTTGTCGTATACAACGGGTCCTCTACTCGGTATATCTTGAAATAAAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGATGTGCACTGATGCTCTCCCCTGTGCGTGAATCCATACCCCGTGCAGCCTATGTGGAAGTATATTGTGCACCCGCACCCCAGATCAATCCTCCTCCGTCTGATGGCTCTCTTCTTGGCAATCCTGTGCTTCTGTTTGATAGAGGGGGGCGTCGAGGAAGATGAATTTAGCATTTTTCAATGTCCAGGAACGCAGTGATGCGTTTTCCTCTTTGTCTAGGAAGTCTTTATAGCTGGCCCCCTCTCCAGGATTGCATAGCACGATTGAAGGGACCCCACCTTCAATCACTCTTGGCTTTCCGTATTTACAGTTTGACTGCCACTTCTTTTGAGAGCCAATCAGTTCTTTCCAGTGTTTCAACTTTAGGTAATGCGGTGGTACGTCATCAATGACGTTATACTCCACTTCGTCTGAGTAGACCTTTGAGTTGAAATCCAGGTGTCCACTTAGGTAATTGTGTGGGCCTAAGGCACGAGCCCACATCGTCTTCCCTGTCCTTGAATCACCTTCAACGATGATACTAAGTGGTCTCTCAGGCCGCGCAGCGGAACCTCTCCCAAAATAATCATCCGCCCACTCTTGCATCTCGTCGGGAACGTTAGTGAATGAGGAGAGTTGAAACGGAGGGGCCCATGGCTCCGGAGCCTTTGCGAATATCCTTTCGAGGTTGGAGCGGATGTTATGATTCTGCAGGACAAAATCTTTTGGCTGTTCTTCCTTTAAAACAACCATGGCAGCGTCAACAGAACCTGCATTTAACGCCTTGGCATATGAATCATTAACAGACTGCTGGCCTCCTCTAGCAGATCTGCCGTCGATCTGGAAATCTCCCCATTCGATTGAGTCTCCGTCCTTGTCGATATAGGACTTGACGTCGGAGCTAGACTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCTTGCACTGGTATTTTCCTTCGAACTGGATGAGCACATGGAGATGAGGCTCCCCATTCTCATGAAGTTCTCGGCAGACTTTGATGAATTTCTTGTTAACTAGGGTTTCAAGGCTTTGTAATTGGGAAAGTGCCTCGTCTTTGGTTAGAGAGCACTGGGGATATGTAAGGAAATAGTTCTTGGCATTAATACGGAAACGTTTAATGGATGGCATTTTTGTAATAAAGGCTTGGACACCAAAGCGAGACACCAGTTGAGCTCTCTCAAACTATCTCATATGTATTGGTGTCTGGTGTCCCATTTATACTAGAACCCTCAATAGATATTTGGTTCCACCTGGCGGCCATCCGCACTAATATT
Gene Information
|
NCBI Accession
|
YP_007024778.1
|
|
Location
|
412-1182 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGCATTATTCTAGGAATAGACGTGGTTCTAACCCCGCTGGACGACGATATTATCCACGTAACACTGTGTTTACGCGTCTAACTCCATCGAAAAAGCATGGTGGGAAACGTGGAGGAGTCAATTCCAGCAAGTCCAGTGATGAGCCCAAGATGAAGGCCCAAGTCATACATGAGAATCAGTATGGGTCCAACTTTGTGTTGGCCCATAATTCAGCTATTTCTACCTACATCACTTATCCCAGCTTGGGGAAGACCGAACCTAGCAGGAGCAGATCCTATATTAAGTTGAAACGGTTACGTTTCAAAGGGACCGTGAAGATTGAACGTGTTCAACCGGACATGAATCTGGACGTTGCTATCCCCAAGGTGGAAGGAGTATTCACCGTCGTTGTGGTTGTGGATCGGAAACCCCATCTTGATCCATCTGGTGGACTGCATACTTTCGATGACCTCTTCGGTGCTAGGATACACAGCCACGGTAACCTCAGCATTATCCCGTCGCTGAAAGACCGCTACTGTATCCGACACGTGTGCAAACGTGTGTTGTCAGTGGAGAAGGACACGCTGATGGTAAATGTGGAAGGATCCATTCCCTTCTCTAACAGGCGTTATAATTGTTGGTCCACTTTTAAGGATCTGGATCGAGAATCATGTAATGGTGTTTATGGCAACATTAGCAAGAACGCCCTGTTAGTGTATTACTGCTGGATGTCGGATACTATGTCTAATGCATCCACATTTGTAACTTATGATCTGGATTATATTGGATGA |
|
Protein Sequence
|
MHYSRNRRGSNPAGRRYYPRNTVFTRLTPSKKHGGKRGGVNSSKSSDEPKMKAQVIHENQYGSNFVLAHNSAISTYITYPSLGKTEPSRSRSYIKLKRLRFKGTVKIERVQPDMNLDVAIPKVEGVFTVVVVVDRKPHLDPSGGLHTFDDLFGARIHSHGNLSIIPSLKDRYCIRHVCKRVLSVEKDTLMVNVEGSIPFSNRRYNCWSTFKDLDRESCNGVYGNISKNALLVYYCWMSDTMSNASTFVTYDLDYIG |
|
NCBI Accession
|
YP_007024779.1
|
|
Location
|
1249-2130 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGTTAATCCTCCAAGTGCCTTTAACTACATCGAGTCCCATCGGGACGAATATCAGCTTTCTCATGACCTAACTGAGATAATTCTGCAATTTCCGTCGACGGCGTCTCAGTTGACAGCTAGACTGAGTCGTAGTTGCATGAAGATCGACCACTGCGTCATAGAGTACAGACAGCAAGTTCCGATCAACGCGACGGGATCCGTAATTGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTCATTACAGGCGTCATGGACTTTTCCGATCAGGTGCAACATAGATCTCCACTACTTTTCAGCTTCGTTCTTCTCGCTCAAGGACCCAATTCCATGGAAACTCTATTACAGAGTTTGCGATACGAATGTTCATCAGAGGACCCACTTCGCGAAATTCAAGGGGAAGCTGAAACTATCCACGGCGAAACACTCCGTCGACATACCTTTCCGGTCACCAACAGTAAAGATCCTGTCCAAACAGTTCACGGATAAAGATGTGGACTTCTCCCATGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGCGCGTCCATGTCTAGACTTGGGCTCAGAGGCCCAATTGAGTTAAGACCAGATGAATCGTGGGCTTCCAGGAGTACTGTAGGAACGGGTCAATCAGATGCGGACTCGGAGGTGGAGAACGAACTCCACCCTTACAGACACCTTAGCAGGCTTGGGACCACTGTGTTAGATCCAGGAGAGTCTGCCTCAGTGGTGGGAGCCCAGAGAGCGGAGTCAAACATCACGATGTCTATGGGCCAGTTGAACGAGCTCGTTAGGACAACGGTCCAAGAATGTATAAATAATAATTGTAGACCGTCACAGCCCAAATCATTGCAATAG |
|
Protein Sequence
|
MDSQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRSPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRLGLRGPIELRPDESWASRSTVGTGQSDADSEVENELHPYRHLSRLGTTVLDPGESASVVGAQRAESNITMSMGQLNELVRTTVQECINNNCRPSQPKSLQ |
|
NCBI Accession
|
YP_007024780.1
|
|
Location
|
218-973 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTCCCATGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGTAATGTCAATTACTCCCCTCGTGGAGGAGGTGGCCCAAAATCAAGTAGGGCCTCTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGGATGATCAGGACACCCGATGTGCCCAGAGGATGTGAAGGCCCGTGTAAGGTCCAGTCTTATGAACAGCGACACGACATCTCACATGTCGGCAAGGTCATGTGCATCTCCGATGTGACACGTGGTAATGGCATTACCCACCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATATTAGGTAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGGACGCCCATGGATTTTGGGCAAGTGTTCAACATGTTCGACAACGAGCCAAGCACTGCTACGGTTAAGAACGATCTTCGCGATCGTTACCAGGTCATGCATAAGTTCTATGGGAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAAGCCATTGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAGGCTGGCAAGTATGAGAATCACACGGAGAACGCACTTCTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACTTTGAAGATTCGAATCTATTTTTACGATTCGATCACGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSMAGTSKVSRNVNYSPRGGGGPKSSRASEWVNRPMYRKPRIYRMIRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_007024781.1
|
|
Location
|
970-1368 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGAGCATCAGTGCACATCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTTTATTTCAAGATATACCGAGTAGAGGACCCGTTGTATACGACAACCAGAGTCTACCACGTACAAATACGGTTCAACCACAACCTCAGGAAAGCATTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGAGAGCTTCTGGAACGACTTATTTAGTTAGGTTTAGACAATTAGTCTTGATGTACTTGGATCAGCTAGGCGTAATATCGCTTAACAATGTAATTAGAGCTGTACGATTCGCAACGGACAAATCATATGTAAATTATGTACTAGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGESISAHQAENGVYIWEIENPLYFKIYRVEDPLYTTTRVYHVQIRFNHNLRKALGLHKAYLNFQVWTTSMRASGTTYLVRFRQLVLMYLDQLGVISLNNVIRAVRFATDKSYVNYVLENHSIKFKFY |
|
NCBI Accession
|
YP_007024782.1
|
|
Location
|
1115-1504 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACAGAAGCACAGGATTGCCAAGAAGAGAGCCATCAGACGGAGGAGGATTGATCTGGGGTGCGGGTGCACAATATACTTCCACATAGGCTGCACGGGGTATGGATTCACGCACAGGGGAGAGCATCAGTGCACATCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTTTATTTCAAGATATACCGAGTAGAGGACCCGTTGTATACGACAACCAGAGTCTACCACGTACAAATACGGTTCAACCACAACCTCAGGAAAGCATTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGAGAGCTTCTGGAACGACTTATTTAGTTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKQKHRIAKKRAIRRRRIDLGCGCTIYFHIGCTGYGFTHRGEHQCTSGREWRVYLGDRKSPLFQDIPSRGPVVYDNQSLPRTNTVQPQPQESIGSPQSLPELPSLDDIDESFWNDLFS |
|
NCBI Accession
|
YP_007024783.1
|
|
Location
|
1416-2501 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCCATTAAACGTTTCCGTATTAATGCCAAGAACTATTTCCTTACATATCCCCAGTGCTCTCTAACCAAAGACGAGGCACTTTCCCAATTACAAAGCCTTGAAACCCTAGTTAACAAGAAATTCATCAAAGTCTGCCGAGAACTTCATGAGAATGGGGAGCCTCATCTCCATGTGCTCATCCAGTTCGAAGGAAAATACCAGTGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAGTCTAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACTCAATCGAATGGGGAGATTTCCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAGTCTGTTAATGATTCATATGCCAAGGCGTTAAATGCAGGTTCTGTTGACGCTGCCATGGTTGTTTTAAAGGAAGAACAGCCAAAAGATTTTGTCCTGCAGAATCATAACATCCGCTCCAACCTCGAAAGGATATTCGCAAAGGCTCCGGAGCCATGGGCCCCTCCGTTTCAACTCTCCTCATTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCGGATGATTATTTTGGGAGAGGTTCCGCTGCGCGGCCTGAGAGACCACTTAGTATCATCGTTGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACACAATTACCTAAGTGGACACCTGGATTTCAACTCAAAGGTCTACTCAGACGAAGTGGAGTATAACGTCATTGATGACGTACCACCGCATTACCTAAAGTTGAAACACTGGAAAGAACTGATTGGCTCTCAAAAGAAGTGGCAGTCAAACTGTAAATACGGAAAGCCAAGAGTGATTGAAGGTGGGGTCCCTTCAATCGTGCTATGCAATCCTGGAGAGGGGGCCAGCTATAAAGACTTCCTAGACAAAGAGGAAAACGCATCACTGCGTTCCTGGACATTGAAAAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACAGAAGCACAGGATTGCCAAGAAGAGAGCCATCAGACGGAGGAGGATTGA |
|
Protein Sequence
|
MPSIKRFRINAKNYFLTYPQCSLTKDEALSQLQSLETLVNKKFIKVCRELHENGEPHLHVLIQFEGKYQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDSIEWGDFQIDGRSARGGQQSVNDSYAKALNAGSVDAAMVVLKEEQPKDFVLQNHNIRSNLERIFAKAPEPWAPPFQLSSFTNVPDEMQEWADDYFGRGSAARPERPLSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVYSDEVEYNVIDDVPPHYLKLKHWKELIGSQKKWQSNCKYGKPRVIEGGVPSIVLCNPGEGASYKDFLDKEENASLRSWTLKNAKFIFLDAPLYQTEAQDCQEESHQTEED |
|
NCBI Accession
|
YP_007024784.1
|
|
Location
|
2087-2344 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTCATCCAGTTCGAAGGAAAATACCAGTGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAGTCTAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACTCAATCGAATGGGGAGATTTCCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAGTCTGTTAATGATTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MGSLISMCSSSSKENTSARITDSSIWSPQPGQHISIQTYRELSLAPTSSPISTRTETQSNGEISRSTADLLEEASSLLMIHMPRR |