Rhynchosia rugose golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002867635.1 |
| Isolate |
Cuba: Camaguey |
| Release date |
2018/8/26 |
| Submitter |
Fiallo-Olive,E., Navas-Castillo,J., Moriones,E., Martinez-Zubiaur,Y. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
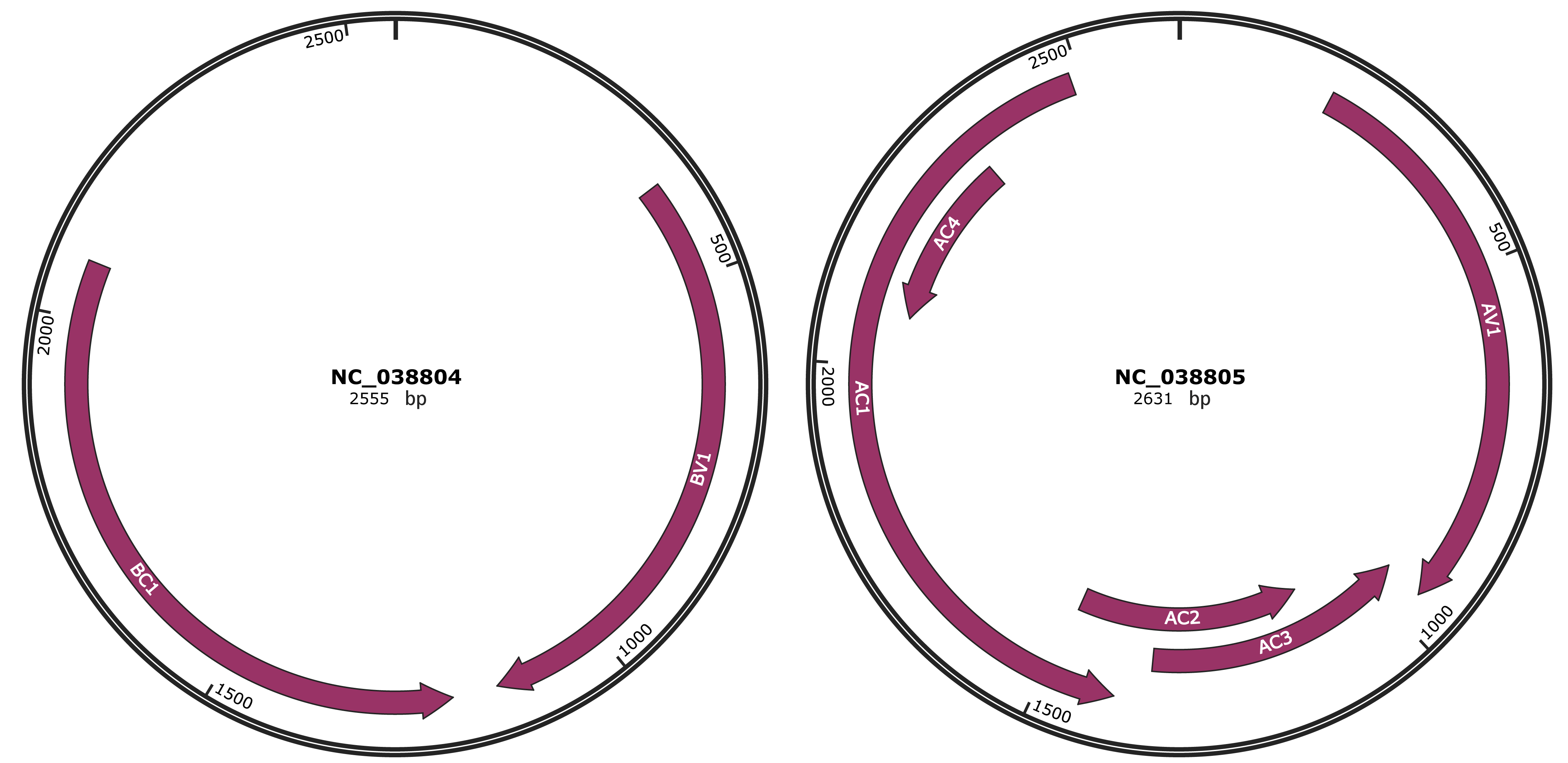
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTGGAGTCCTGGCGCTGGGGACCATCCCCCGCTCCCCTTTGGCGCACTCTCTCTCTTCCTTTGACGTGGCGCGTTGAACACCGTTGGATAACTCTTATCTCTGTGTGAAACCTTTAATTTGAAATTTGAAATAATTGGGCGCACATGTCTATTTTGAACGGTCTTCGTAACGATAAGGTTTCTGACACATTGTACGTTATGTGGAACGTGGCCCAATTATATTTCAGCTGTGGAGTTAAACTATCGCTTATTTTGAACGGCCCTTTCTATATAATGGACGATAGTTTAATATTTTAAATCGTCTTTTGACATTAAAACCAAAATAACCTATTATTTTGTACAGGTAGATTGAATTATGTATCCTACAAGGTTTAGACGTGGGTCATCTTATCCCCAAAGACGATTTGTTGCACGTAATCATGGTAATAAGCGTGCAACTTTTGTTAGACGGAGTGATGGGAAACGTCGTAATGGCCCATCAAGTAAAGCCCATGATGACCCCAAGATGACGTCGCAACGCATACATGAAAATCAATATGGGCCTGAATTTGTCATGACCCATAATTCAGCTATTTCAACTTTCATTAATTTCCCTGTACTTGGTAAGAGTGAACCTAACCGAAGCAGGTCGTACATTAAGTTGAAGCGTTTATCATTTAAGGGAACCGTTAAAATTGAACGTGTACATGCTGATGTCAACATGGACGGACTAAGTTCCAAGATAGAAGGTGTGTTTTCTCTTGTTATTGTTGTGGATCGCAAACCACATTTAAGCTCCTCTGGAGGTTTACACACATTTGATGAACTATTTGGAGCAAGAATCCACAGTCATGGGAACTTAGCTATTACACCCGCTTTGAAAGATCGTTATTACGTTCGCCATGTTTTGAAGCGTGTATTGTCCGTGGAGAAAGACAGTGTTATGGTCGATCTTGAAGGATCGGCAACCATTTCTAATAGGCGTTACAACTGTTGGGCCACATTTAAGGATCTTGAACATGACTCATGTAACGGTGTTTACGCGAATATAAGCAAGAACGCCATTTTAGTTTATTATTGTTGGATTTCCGATGCTATGTCTAAGGCATCAACTTTTGTATCATATGACCTTCATTATGTGGGTTAAACATGAATAAAATGGCGTTAAAGTTGATCATATGCATAATTAATCAAAATAAGCAATTTTATTGCAATGACTTTGGTTGTGAAGGATTACAATTATTGTTAATACACTCCTGCACCGTTGTCCTAACAAGCTCGTTTAATTGGGCCATGGACATCGTTATATTTGATTGGGCCCTCTGTAACCCGACCTGTGATGCTGAATCACCTGGGTCTAGCACGCTTGGTCCTAGACGATTAAGCTCTCTATATGGGTGTATTTCTGACTCCGTCTCCGTGTGAGTCCTTCCAATAGTGCTCCTTGAGGCCCATGACTCACCTGGTTTTAATTCAATTGGGCCTGGTAGCCCAAATCTGGACATTGATGTGGACCTCAAGGTTTTCCTTTCCCACGGTCCATAATCGACATGCGAGAAATCAACATCTTTGTGCGAAAACTGTTTGGAATGAATTTTGACCGTGGGAGCCCGGAAGGGTATATCTACAGAGTGTTTAGCGGTAGACAATTTCAATTTGCCTTTGAATTTGGCAAAATGGGTACGCTGATGAACATTTGTATCTGACACTCTGTAGTATAATTTCCATGGAATTGGGTCTTTTAACGAAAAGAATGACGATGAGAAATAATGGAGGTCTATGTTGCATCTTATGGGAAACGTCCATGATGCTTGTAAGGATTCGTTGTCCGTCATTCTTTTGTCATGAATTTCTACAATGACAGACCCAGTTGCGTTAATTGGTACTTGTTGCCTGTATTCGATGACGCAATGGTCTATCTTCATACAGCTACGATTGAGCCTTGCAGTTAATTGTGCAGCTGTGGAAGGAAATTGAAGAATAATCTCAGTTAGATCATGAGACAGCTGATATTCGTCTCTATGAGACTCTATGTAATTAAACGCATTTGGAGGATTTGCTAACTGAGATTCCATATACGAAAAAATGGCCGCGCAGCGGAACTGGGTTTAATAATATCTGGGTTGAACAATATCTGGGTTCAACAACAAAATAAGCCAGCGAAGTAGAACATGAATGTGTTTGACAAAGACCAGAAAAGGAGTTCAACTATTTCAATAACAAACTGGGTTTATATATACATATACAATATCTGGGTATGTTAACAAGAAGGATATGACGAAAGTGTTTCAGGAAAGATGAATAAGTTTGGTTATTTCCAGAACTTGTGTTTAATCACGTAAGTGTAACCGTGTTTATATAGAGAGCGAATTTGAAGTAAGTTAGAAACGCTCTGAAGGTTATGTTAGTGGCAGATGCGTAATAAGAAGGGTGTACCCCGATTGAGCTCTCTCAAATCTGTGCTATGAATTGGGGTCCTGGGGTCCCTTATATACTAGAAGTCTCTATAGAACTCTCAATCCTCATCGCACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCGCCCCCCCCCTGGTGCCGTACACTCTCGCGCGCTCCCTCGTCCTTTAATTTCGAATTAAAGGTGGTCCCTGGCGCCTGTGTCCAATCAGAATGCGCCTGACGAGCCTAGATATTTTGAACAACTTGGGCGCGAAGTTGTTGGGCCGTCTATAAATGAAAAGCCCATTGGCCCACTGTCTTTAACCCAAAATGCCTAAGCGCGATCTGCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAACTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGTTAACAAGGCCTCTGAATGGGCGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGCATACTCAGGACACCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGTAAAGTGCAGTCGTACGAACAGCGTCACGACATCTCACATGTCGGCAAGGTCATGTGCATCTCTGATGTTACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTCAAGTCTGTGTATATTTTAGGGAAGATCTGGATGGACGAGAACATCAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCGTATGGCACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCGAGCACTGCCACTGTGAAGAACGATCTCCGCGATCGTTACCAGGTTATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCGATAGTCAAGAGGTTCTGGAAGGTCAACACTCATGTGGTGTACAACCACCAAGAGGCTGGCAAGTACGAGAACCACACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCTGTGTATGCAACTTTGAAGATTCGGATCTATTTCTACGATTCGATCATGAATTAATAAAATTTGAATTTTATTGAATGATTTTCCAGTACATGATTTACATACGATCTGTCTGTCGCGAATCGAACAGCCCTGATTACATTGTTTAATGAAATCACTCCTAATTGATCTAAGTACAAGTTGACCAAATGCCTAAACCTAGCTAAATAGATTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATGTGTACGTGGTATACCCTCGTTTTGGTGTACAACAGGTCCTCTACTCTGTATATCTTGAAATACAGGGGATTTTCGATCTCCCAGATATACACGCCATTCTCCGCCTGACGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCCGTACAGCCTATGTGGAAGTAGATGGAGCACCCGCACTGCAGATCAATCCTGCGCCTCCTGATCGCCCTCTTCTTGGCCTGCCTGTGTGCTGTCTTGATAGAGGGCGGTTGTGAGGGTGATGAAGATCGCATTCTTGAGAGTCCAATTCTTTAGTCCTGCATTTTCCTCTTTGTCCAGGAACTCTTTATAACTGGCACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATTCCACCTTTAATTTGAACAGGCTTGCCGTATTTGCAATTTGACTGCCAGTCCTTTTGGGCCCCCAGCAATTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCGACGTCGTTCGAGTAGACCCGACCATTGAAGTCCAGGTGTCCACTGAGGTAGTTGTGTGGGCCTAACGCACGTGCCCACATCGTCTTCCCTGTCCTCGAGTCACCTTCTACTATCAAACTCAATGGTCTTTCTGGCCGCGCAGCGGAACCTCTCCCAAAATAATCATCCGCCCACTCCTGCATCTCGTCGGGAACGGCTGTGAAAGAGGAGAGTGGAAACGGAGGAACCCATGGTTCCGGAGCCTTTGCGAATATTCTCTCGAGATTGGAGCGGATGTTATGATTCTGCAAGACGAAGTCCTTTGGCTGTTCTTCCTTTAAAATGGACATGGCAGATTGAACAGAATCTGCATTTAACGCCTTGGCATATGAATCATTAGCAGACTGCTGGCCTCCTCGAGCAGATCTTCCGTCGATCTGGAATTCTCCCCATTCCAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTAATTCGTGCACTGGTATTTTCCCTCGAACTGTATGAGCACATGGAGATGAGGCTCCCCATTCTCATGAAGCTCTCTGCAAATCTTGATGAATTTCTTGTTAACTGGAGTTGCTAGGTTTTGTAATTGGGAAAGTGCCTCTTCTTTTGTCAGAGAGCACTGTGGATAGGTTATGAAATAGTTTTTGGCTGAGACTTTGAAACGCTTAACTGATGGCATTTTTGTAATAAGAAGGGTGTACCCCGATTGAGCTCTCTCAAATCTGTGCTATGAATTGGGGTAAAGGGGTACTATATATACTAGAAGTCTCTATAGAACTTTCAATCCTCATCGCACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508020.1
|
|
Location
|
375-1145 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttling protein |
|
Coding Region
|
ATGTATCCTACAAGGTTTAGACGTGGGTCATCTTATCCCCAAAGACGATTTGTTGCACGTAATCATGGTAATAAGCGTGCAACTTTTGTTAGACGGAGTGATGGGAAACGTCGTAATGGCCCATCAAGTAAAGCCCATGATGACCCCAAGATGACGTCGCAACGCATACATGAAAATCAATATGGGCCTGAATTTGTCATGACCCATAATTCAGCTATTTCAACTTTCATTAATTTCCCTGTACTTGGTAAGAGTGAACCTAACCGAAGCAGGTCGTACATTAAGTTGAAGCGTTTATCATTTAAGGGAACCGTTAAAATTGAACGTGTACATGCTGATGTCAACATGGACGGACTAAGTTCCAAGATAGAAGGTGTGTTTTCTCTTGTTATTGTTGTGGATCGCAAACCACATTTAAGCTCCTCTGGAGGTTTACACACATTTGATGAACTATTTGGAGCAAGAATCCACAGTCATGGGAACTTAGCTATTACACCCGCTTTGAAAGATCGTTATTACGTTCGCCATGTTTTGAAGCGTGTATTGTCCGTGGAGAAAGACAGTGTTATGGTCGATCTTGAAGGATCGGCAACCATTTCTAATAGGCGTTACAACTGTTGGGCCACATTTAAGGATCTTGAACATGACTCATGTAACGGTGTTTACGCGAATATAAGCAAGAACGCCATTTTAGTTTATTATTGTTGGATTTCCGATGCTATGTCTAAGGCATCAACTTTTGTATCATATGACCTTCATTATGTGGGTTAA |
|
Protein Sequence
|
MYPTRFRRGSSYPQRRFVARNHGNKRATFVRRSDGKRRNGPSSKAHDDPKMTSQRIHENQYGPEFVMTHNSAISTFINFPVLGKSEPNRSRSYIKLKRLSFKGTVKIERVHADVNMDGLSSKIEGVFSLVIVVDRKPHLSSSGGLHTFDELFGARIHSHGNLAITPALKDRYYVRHVLKRVLSVEKDSVMVDLEGSATISNRRYNCWATFKDLEHDSCNGVYANISKNAILVYYCWISDAMSKASTFVSYDLHYVG |
|
NCBI Accession
|
YP_009508021.1
|
|
Location
|
1204-2073 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTAGCAAATCCTCCAAATGCGTTTAATTACATAGAGTCTCATAGAGACGAATATCAGCTGTCTCATGATCTAACTGAGATTATTCTTCAATTTCCTTCCACAGCTGCACAATTAACTGCAAGGCTCAATCGTAGCTGTATGAAGATAGACCATTGCGTCATCGAATACAGGCAACAAGTACCAATTAACGCAACTGGGTCTGTCATTGTAGAAATTCATGACAAAAGAATGACGGACAACGAATCCTTACAAGCATCATGGACGTTTCCCATAAGATGCAACATAGACCTCCATTATTTCTCATCGTCATTCTTTTCGTTAAAAGACCCAATTCCATGGAAATTATACTACAGAGTGTCAGATACAAATGTTCATCAGCGTACCCATTTTGCCAAATTCAAAGGCAAATTGAAATTGTCTACCGCTAAACACTCTGTAGATATACCCTTCCGGGCTCCCACGGTCAAAATTCATTCCAAACAGTTTTCGCACAAAGATGTTGATTTCTCGCATGTCGATTATGGACCGTGGGAAAGGAAAACCTTGAGGTCCACATCAATGTCCAGATTTGGGCTACCAGGCCCAATTGAATTAAAACCAGGTGAGTCATGGGCCTCAAGGAGCACTATTGGAAGGACTCACACGGAGACGGAGTCAGAAATACACCCATATAGAGAGCTTAATCGTCTAGGACCAAGCGTGCTAGACCCAGGTGATTCAGCATCACAGGTCGGGTTACAGAGGGCCCAATCAAATATAACGATGTCCATGGCCCAATTAAACGAGCTTGTTAGGACAACGGTGCAGGAGTGTATTAACAATAATTGTAATCCTTCACAACCAAAGTCATTGCAATAA |
|
Protein Sequence
|
MESQLANPPNAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFSHKDVDFSHVDYGPWERKTLRSTSMSRFGLPGPIELKPGESWASRSTIGRTHTETESEIHPYRELNRLGPSVLDPGDSASQVGLQRAQSNITMSMAQLNELVRTTVQECINNNCNPSQPKSLQ |
|
NCBI Accession
|
YP_009508022.1
|
|
Location
|
205-960 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTGCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAACTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGTTAACAAGGCCTCTGAATGGGCGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGCATACTCAGGACACCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGTAAAGTGCAGTCGTACGAACAGCGTCACGACATCTCACATGTCGGCAAGGTCATGTGCATCTCTGATGTTACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTCAAGTCTGTGTATATTTTAGGGAAGATCTGGATGGACGAGAACATCAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCGTATGGCACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCGAGCACTGCCACTGTGAAGAACGATCTCCGCGATCGTTACCAGGTTATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCGATAGTCAAGAGGTTCTGGAAGGTCAACACTCATGTGGTGTACAACCACCAAGAGGCTGGCAAGTACGAGAACCACACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCTGTGTATGCAACTTTGAAGATTCGGATCTATTTCTACGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSMAGTSKVSRNANYSPRAGSGPRVNKASEWANRPMYRKPRIYRILRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNTHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009508023.1
|
|
Location
|
957-1355 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATATACAGAGTAGAGGACCTGTTGTACACCAAAACGAGGGTATACCACGTACACATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAATCTATTTAGCTAGGTTTAGGCATTTGGTCAACTTGTACTTAGATCAATTAGGAGTGATTTCATTAAACAATGTAATCAGGGCTGTTCGATTCGCGACAGACAGATCGTATGTAAATCATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVYIWEIENPLYFKIYRVEDLLYTKTRVYHVHIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSIYLARFRHLVNLYLDQLGVISLNNVIRAVRFATDRSYVNHVLENHSIKFKFY |
|
NCBI Accession
|
YP_009508024.1
|
|
Location
|
1102-1491 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACAACCGCCCTCTATCAAGACAGCACACAGGCAGGCCAAGAAGAGGGCGATCAGGAGGCGCAGGATTGATCTGCAGTGCGGGTGCTCCATCTACTTCCACATAGGCTGTACGGGACATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATATACAGAGTAGAGGACCTGTTGTACACCAAAACGAGGGTATACCACGTACACATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAATCTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKTAHRQAKKRAIRRRRIDLQCGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPVFQDIQSRGPVVHQNEGIPRTHTVQPQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
YP_009508025.1
|
|
Location
|
1403-2488 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCAGTTAAGCGTTTCAAAGTCTCAGCCAAAAACTATTTCATAACCTATCCACAGTGCTCTCTGACAAAAGAAGAGGCACTTTCCCAATTACAAAACCTAGCAACTCCAGTTAACAAGAAATTCATCAAGATTTGCAGAGAGCTTCATGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAGGGAAAATACCAGTGCACGAATTACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGAAGATCTGCTCGAGGAGGCCAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCATGTCCATTTTAAAGGAAGAACAGCCAAAGGACTTCGTCTTGCAGAATCATAACATCCGCTCCAATCTCGAGAGAATATTCGCAAAGGCTCCGGAACCATGGGTTCCTCCGTTTCCACTCTCCTCTTTCACAGCCGTTCCCGACGAGATGCAGGAGTGGGCGGATGATTATTTTGGGAGAGGTTCCGCTGCGCGGCCAGAAAGACCATTGAGTTTGATAGTAGAAGGTGACTCGAGGACAGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACACAACTACCTCAGTGGACACCTGGACTTCAATGGTCGGGTCTACTCGAACGACGTCGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAGGACTGGCAGTCAAATTGCAAATACGGCAAGCCTGTTCAAATTAAAGGTGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGTTATAAAGAGTTCCTGGACAAAGAGGAAAATGCAGGACTAAAGAATTGGACTCTCAAGAATGCGATCTTCATCACCCTCACAACCGCCCTCTATCAAGACAGCACACAGGCAGGCCAAGAAGAGGGCGATCAGGAGGCGCAGGATTGA |
|
Protein Sequence
|
MPSVKRFKVSAKNYFITYPQCSLTKEEALSQLQNLATPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNYRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDSYAKALNADSVQSAMSILKEEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFPLSSFTAVPDEMQEWADDYFGRGSAARPERPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVYSNDVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKEFLDKEENAGLKNWTLKNAIFITLTTALYQDSTQAGQEEGDQEAQD |
|
NCBI Accession
|
YP_009508026.1
|
|
Location
|
2074-2331 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAGGGAAAATACCAGTGCACGAATTACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGAAGATCTGCTCGAGGAGGCCAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MGSLISMCSYSSRENTSARITDSSIWSPQPGQHISIRTYRELNPAPTSSPTSTRTEIHWNGENSRSTEDLLEEASSLLMIHMPRR |