Rhynchosia golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_008802995.1 |
| Isolate |
Mexico |
| Release date |
2018/4/3 |
| Submitter |
Mauricio-Castillo,J.A., Mendez-Lozano,J., Perea-Araujo,L., Arguello-Astorga,G.R. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
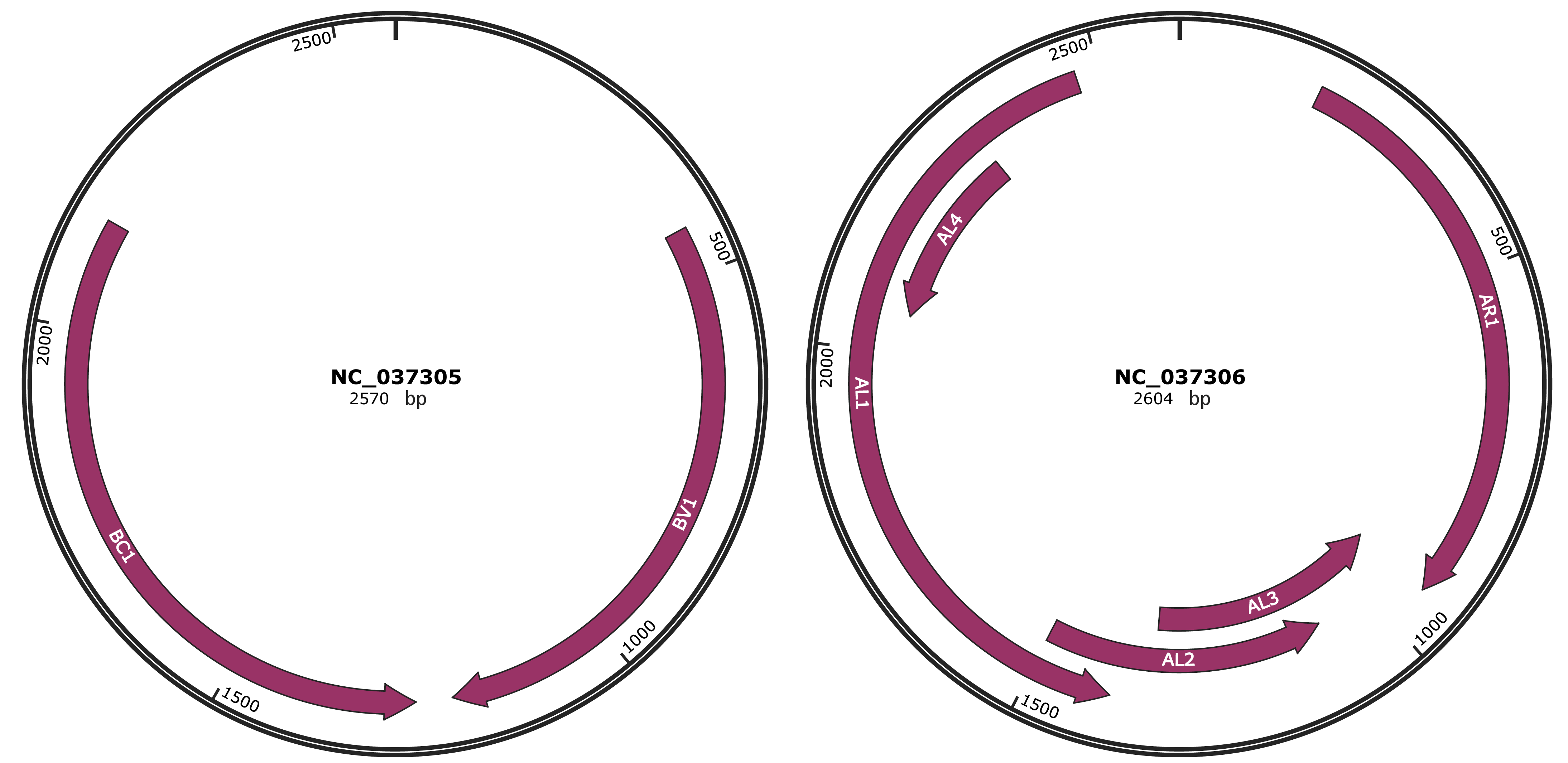
JBrowse
Genome
ACCGTTGGCCGACCGGTGCCAGACCCCCCCCTTTGGCGTACCCCACCACGTTTGGCGTACTGTCTTTGGTGCGCGGGCCCTTTTGACGTGGTGTGTTCTCTACCGTTGGATAAAGCTTATCGCGCGATAACAATTTGAATTATGAATTATTTGTACCGCTCCTGCTTTATATTTTATGTGGCAGTACGTGAACCATTTGATAAACGTTATCGCGCTATGTTATTTGAATTTTGAATTGGTTGCACGGATATCTATAATTGGGACCATGTGTGTAACGATAATGTTTGACTGGCAGATTTATCGATGTCTGCGACGTGGCCCAATTAAAATTCCTGTGGCGAGTCTAGTTATGTTATATTTGAATTGTCCTTTCTATATAATGGACCGTCTTTTGACATTATTTTCATATATTATATTCCATATATTAGGAGGAATATAATATGTATTCGTTTAAGTCTCGACGTGGGTTTTGTTATTCCCAAAGACGATCTTATCCACGTAATTCAGTGTTTAAACGTACAAGCGCTGTTAAACGTGTTGATGTTAAACGTCGAGCTAATCAGGTAAATAAGGTTAATGACGAGTGCAAAATGTCGTCGCAACGTCTACATGAGAACCAATACGGCCCTGAATTTGTTATGGCGCATAATTCAGCTATTTCTACTTTCATTAATTTTCCCCATTTGGGTAAGAATGAACCTAATCGTAGCAGATCATATATTAAGTTGAGACGTCTCCGTTTCAAGGGTACCGTGAAGATTGAGCGTGTTCCTGCTGATATGAATATGGACGGTGTACTTTCGAAGGTTGAAGGTGCTTTCTCCCTTGTTGTTGTGGTTGATCGTAAACCACATTTGAGTTCATCAGGATGTTTGCATACATTTGATGAATTATTTGGTGCAAGAATTCACAGCCATGGAAATTTAGCTATTACCCCCTCTTTGAAGGATCGTTTCTACATTCGTCATGTGTTTAAGCGCGTTTTGTCCGTGGAGAAGGATACTCTGATGGTAGACGTGGAAGGATCTACTTGGTTATCATCTCGGCGTTTTAATTGTTGGTCCACGTTTAAGGATTTGGATCATGATTCATGTAACGGTGTTTATGACAACATTAGTAAAAACGCCATATTAGTTTATTATTGCTGGATGTCAGATGTTGTGTCTAAGGCATCCACATTTGTATCTTTTGACCTTGATTATGTTGGTTGAATAAGAATAAAATGACGATAGACTTATAATTCGGAACGTAAATCATTTTATTTCAATGACTTCGGTGGTGCTGGATTACAATTACTATTAATACATTCTTGGACTGTTGTCCTAACCAGCTCGTTTAATTGGGCCATACTCATAGTTATGTTGGACTGGGCTCTCTGTATCCCTACTTGTGATGCGGAATCACCTGGGTCTAATACGCTGCCTCCTAATCGATTAAGGTCTCGATATGGGTGTATTGCGTTTTCCACTTCTGAGTCCGCATCTGTATGTGTTCGTCCAATTGTGCTTCTTGAAGCCCATGAGTCGCCTGGCTTTAATTCAATTGGGCCTGGTAGCCCAAATCTGGACATTGATGTGGACCTGATGATTTTTCTTTCCCACCGTCCATAGTCCACATGTTGAAAATCCACATCCTTATGTGAGAATTGTTTGGATAGGATTTTGACGGTGGGTGCTCGGAATGGGGTGTCTACAGAGTGTTTCGCCGTGGACAATTTGAGTTTGCCTTTGAATTTGGCAAAATGCGTCCTTTGATGCACATTTGTATCTGACACTCTGTAGTATAGTTTCCATGGAATTGGGTCCTTCAGGGAGAAGAATGGCGAGGAGAAGTAATGCAGATCTATGTTGCATCTAATGGGAAATGTCCATGACGCTTGTAACGATTCGTTGTCCGTCATTCGTTTGTCATGGATTTCCACTATGACCGAACCTGTTGCGTTAATCGGAACTTGTTGCCTATATTCTATGACGCAATGGTCGATTTTCATACAACTACGGTTGTGTCTTGCGGATAATTGCGACGCCGTTGAAGGAAATTGAAGGATTATCTCAGTTAGGTCATGAGATAATTGATACTCATCCCTATGGGACTCTATGTAATTGAACGCATTCGGAGGATTTGCTAACTGGGAATCCATATATGAATAATTGGCTGCGCAGCTGAACTATTTGAACAAGAAGTAGGCGTTAAGAACAATATGTGTTTGTGTTTGACAAAGAACAGAAATTATGAAGACCGATGTGTTTATTATGAGTTGTTGTATCTGGGTTGAACCCTGATATGAGCAGATAGATGATGATAATACTGGGTTTATGAAAGTGATGAGTGTTTGCAGAAGTGTGTCTAAGAATCGCAGTGCTTTGTTCAACCCAGTTTGTGTTAGTTAAATAGAACTGAGCGTGGGATGAGCGAGAGCGTTTTGAGTGGCATTCTTGTAATAAGAGGGGTGTACACCGATTGGGGCTCTCTCAAACTGGCTGATTGTATCGGTGTATTGGTATCCAATATATAGCTTCTTTCTTGGTATCACTTTTGACACGTGGAGGGAGGCCAACGTATATAATATT
ACCGTTGGCCGACCGGTGCCACGCGCCCCCCTCCGTACAACTTTATTTTGAATTAAAGATAATTCTTTTGTGTAGTCCAATGATATTGCGTCTGGCGAGTCTAGTTATCCGTTCCAACTTAGTGCGCAAGTTGTTGATTGTCCGCTATTTAAATTGAAATTGTGGAGCCAGGTTCTTTAATTCAAAATGCCTAAGCGGGATGCTCCGTGGCGTTTGATGGCGGGGACCTCAAAGGTGTCCCGTTCTGCCAATTATTCTCCTGGTGCGGGTACGGGCCCTAAATCAAATAGGGCCTCCGCTTGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATTTATCGGATGTACAGATCCCCCGATGTTCCGAAAGGGTGTGAAGGGCCTTGTAAGGTCCAATCGTTTGAATCACGACATGATGTTACCCATGTTGGTAAGGTCCTTTGTATATCCGATATTACACGTGGTAGTGGTATTACCCACCGCGTTGGTAAGCGTTTCTGCGTGAAGTCCGTGTATATCCTAGGCAAAGTATGGATGGACGAGAACATCAAGTTGAAGAACCACACCAACAGCGTCATGTTTTGGTTGGTGAGGGATAGGAGACCATATGGTACCCCTATGGATTTTGGCCAGGTGTTCAACATGTTTGACAATGAACCTAGTACCGCTACTGTTAAGAACGATTTGCGTGACCGTTTTCAAGTTATGCATAAGTTCTATGCCAAGGTTACGGGTGGACAGTATGCGAGCAACGAGCAAGCGCTGGTGAAGCGTTTTTGGAAGGTTAACAATTATGTGGTGTACAATCATCAAGAAGCGGCAAAGTACGAGAATCACACGGAGAACGCTTTGTTATTGTATATGGCGTGTACTCATGCCTCTAATCCTGTGTATGCAACTCTTAAAATTCGGGTCTATTTTTATGACTCGATAATGAATTAATAAATTTTGTATTTTATTTCATGATTCTCGAGTACATCGCTTACATAATGTTTATCTGTCGCGAATGCAACAGCTCTAATTACATTGTTAACTGAAATAACGCCTAAATTGTCTAAATACGACATTACAAGTAATTTGAATCTACTTAAATAAATCTGCCCAGAAGCTGTCGTCAATGTCGTCCAGACTTGGAAATTGAAGAAGGCTTTGTGGAGATCCAACGCTCTCCGTAGGTTGTGGTTGGCTCTGATTTGAATGTGGAAGACCTTGCTGTGCGTGTGTAATGGGACCTCCACTCTGATTATCTTGAAATATAGGGGATTTGGAACCTCCCAAATAAAAACGCCATTCGTTGCTTGAGGCGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTGGCGCAATTTATGTGGACGTATATTGAACAACCGCACTGGAGATCAATTCTTTTACGCCTCGTTTGTCTCTTGGCGTATCTGTGTTGAGCCTTGATCGACAGTGGTGAAGAACGGTTCCTCAATGGTGATGAAGATGGCGTTTTGTTGTGCCCAGTCATTGAGGCTTTTGTTTTTCTCTTTGCTGAGATACTCCTTATATGATGAATGGGGGCCAGGATTGCAGAGGAAGATAGCGGGAATTCCTCCTTTAATTTGAATTGGCTTTCCGTATTTGCAGTTCGATTGCCAATCCCTTTGGGCCCCCATGAACTCCTTAAAGTGTTTCAGATAATGCGGATTGACGTCATCGATTACGTTATACCATGCATTATTGGAGTAGATTTTTTGATTGAGATCTAGATGACCACATAGGTAATTGTGAGGGCCGAGACTTCGGGCCCATTGTGTTTTGCCCGTCCTTGATGGTCCCTCAATAACGATTGATATAGGTCTCAATGGCCGCGCAGCGGAATCGCAAACGTTTTGATTAACCCATTGCGTAATTATCGGAGGAACATTATTGAACGATGACTGTTGAAATGGAGGGACCCATGGTTCCGGTGGTTTCTGGAAAATCCTGTTTGCGTTTGTGATTAGGTTATGAAATTGAAGAAAGAAATGTTGGGGTTGTTCTTCCTTTATGATCTGCAGAGCCGCTTCTGCAGATGTTGCGTTTAATGCCTTTGCGTATGTGTCATTAGCAGATTGCTGACCTCCTCTAGCTGATCTGCCGTCGATTTGGAACTCTCCCCATTCAATTGTGTCTCCATCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTCGTGCACTGGAATTTTCCTTCGAACTGTATGAGCACGTGTAGATGAGGTTGCCCATCTTCATGTGTTTCTCTGCATATCTTGATGAACTTCTTGTTTACTGGAGTCGAAAGGCGCTGTATTTGCTCGAGCGCCTCTTCTTTAGATATGGAACATTGAGGATATGTGAGGAAGTATTTCTTGGCATTTAAGCGAAAGCGTTTTGGGAGTGGCATTCTTGTAATAAGAGGGGTGTACACCGATTGGGGCTCTCTCAAACTGGCTGATTGTATCGGTGTATTGGTATCCAATATATAGCTTCTTTCTTGGTATCACTTTTGACACGTGGGAGGCCAACGTATATAATATT
Gene Information
|
NCBI Accession
|
YP_009472130.1
|
|
Location
|
441-1211 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTATTCGTTTAAGTCTCGACGTGGGTTTTGTTATTCCCAAAGACGATCTTATCCACGTAATTCAGTGTTTAAACGTACAAGCGCTGTTAAACGTGTTGATGTTAAACGTCGAGCTAATCAGGTAAATAAGGTTAATGACGAGTGCAAAATGTCGTCGCAACGTCTACATGAGAACCAATACGGCCCTGAATTTGTTATGGCGCATAATTCAGCTATTTCTACTTTCATTAATTTTCCCCATTTGGGTAAGAATGAACCTAATCGTAGCAGATCATATATTAAGTTGAGACGTCTCCGTTTCAAGGGTACCGTGAAGATTGAGCGTGTTCCTGCTGATATGAATATGGACGGTGTACTTTCGAAGGTTGAAGGTGCTTTCTCCCTTGTTGTTGTGGTTGATCGTAAACCACATTTGAGTTCATCAGGATGTTTGCATACATTTGATGAATTATTTGGTGCAAGAATTCACAGCCATGGAAATTTAGCTATTACCCCCTCTTTGAAGGATCGTTTCTACATTCGTCATGTGTTTAAGCGCGTTTTGTCCGTGGAGAAGGATACTCTGATGGTAGACGTGGAAGGATCTACTTGGTTATCATCTCGGCGTTTTAATTGTTGGTCCACGTTTAAGGATTTGGATCATGATTCATGTAACGGTGTTTATGACAACATTAGTAAAAACGCCATATTAGTTTATTATTGCTGGATGTCAGATGTTGTGTCTAAGGCATCCACATTTGTATCTTTTGACCTTGATTATGTTGGTTGA |
|
Protein Sequence
|
MYSFKSRRGFCYSQRRSYPRNSVFKRTSAVKRVDVKRRANQVNKVNDECKMSSQRLHENQYGPEFVMAHNSAISTFINFPHLGKNEPNRSRSYIKLRRLRFKGTVKIERVPADMNMDGVLSKVEGAFSLVVVVDRKPHLSSSGCLHTFDELFGARIHSHGNLAITPSLKDRFYIRHVFKRVLSVEKDTLMVDVEGSTWLSSRRFNCWSTFKDLDHDSCNGVYDNISKNAILVYYCWMSDVVSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009472131.1
|
|
Location
|
1259-2140 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCCCAGTTAGCAAATCCTCCGAATGCGTTCAATTACATAGAGTCCCATAGGGATGAGTATCAATTATCTCATGACCTAACTGAGATAATCCTTCAATTTCCTTCAACGGCGTCGCAATTATCCGCAAGACACAACCGTAGTTGTATGAAAATCGACCATTGCGTCATAGAATATAGGCAACAAGTTCCGATTAACGCAACAGGTTCGGTCATAGTGGAAATCCATGACAAACGAATGACGGACAACGAATCGTTACAAGCGTCATGGACATTTCCCATTAGATGCAACATAGATCTGCATTACTTCTCCTCGCCATTCTTCTCCCTGAAGGACCCAATTCCATGGAAACTATACTACAGAGTGTCAGATACAAATGTGCATCAAAGGACGCATTTTGCCAAATTCAAAGGCAAACTCAAATTGTCCACGGCGAAACACTCTGTAGACACCCCATTCCGAGCACCCACCGTCAAAATCCTATCCAAACAATTCTCACATAAGGATGTGGATTTTCAACATGTGGACTATGGACGGTGGGAAAGAAAAATCATCAGGTCCACATCAATGTCCAGATTTGGGCTACCAGGCCCAATTGAATTAAAGCCAGGCGACTCATGGGCTTCAAGAAGCACAATTGGACGAACACATACAGATGCGGACTCAGAAGTGGAAAACGCAATACACCCATATCGAGACCTTAATCGATTAGGAGGCAGCGTATTAGACCCAGGTGATTCCGCATCACAAGTAGGGATACAGAGAGCCCAGTCCAACATAACTATGAGTATGGCCCAATTAAACGAGCTGGTTAGGACAACAGTCCAAGAATGTATTAATAGTAATTGTAATCCAGCACCACCGAAGTCATTGAAATAA |
|
Protein Sequence
|
MDSQLANPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLSARHNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSPFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDTPFRAPTVKILSKQFSHKDVDFQHVDYGRWERKIIRSTSMSRFGLPGPIELKPGDSWASRSTIGRTHTDADSEVENAIHPYRDLNRLGGSVLDPGDSASQVGIQRAQSNITMSMAQLNELVRTTVQECINSNCNPAPPKSLK |
|
NCBI Accession
|
YP_009472132.1
|
|
Location
|
187-942 |
|
Gene Name
|
AR1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCTCCGTGGCGTTTGATGGCGGGGACCTCAAAGGTGTCCCGTTCTGCCAATTATTCTCCTGGTGCGGGTACGGGCCCTAAATCAAATAGGGCCTCCGCTTGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATTTATCGGATGTACAGATCCCCCGATGTTCCGAAAGGGTGTGAAGGGCCTTGTAAGGTCCAATCGTTTGAATCACGACATGATGTTACCCATGTTGGTAAGGTCCTTTGTATATCCGATATTACACGTGGTAGTGGTATTACCCACCGCGTTGGTAAGCGTTTCTGCGTGAAGTCCGTGTATATCCTAGGCAAAGTATGGATGGACGAGAACATCAAGTTGAAGAACCACACCAACAGCGTCATGTTTTGGTTGGTGAGGGATAGGAGACCATATGGTACCCCTATGGATTTTGGCCAGGTGTTCAACATGTTTGACAATGAACCTAGTACCGCTACTGTTAAGAACGATTTGCGTGACCGTTTTCAAGTTATGCATAAGTTCTATGCCAAGGTTACGGGTGGACAGTATGCGAGCAACGAGCAAGCGCTGGTGAAGCGTTTTTGGAAGGTTAACAATTATGTGGTGTACAATCATCAAGAAGCGGCAAAGTACGAGAATCACACGGAGAACGCTTTGTTATTGTATATGGCGTGTACTCATGCCTCTAATCCTGTGTATGCAACTCTTAAAATTCGGGTCTATTTTTATGACTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRSANYSPGAGTGPKSNRASAWVNRPMYRKPRIYRMYRSPDVPKGCEGPCKVQSFESRHDVTHVGKVLCISDITRGSGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSIMN |
|
NCBI Accession
|
YP_009472133.1
|
|
Location
|
939-1337 |
|
Gene Name
|
AL3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCGCCTCAAGCAACGAATGGCGTTTTTATTTGGGAGGTTCCAAATCCCCTATATTTCAAGATAATCAGAGTGGAGGTCCCATTACACACGCACAGCAAGGTCTTCCACATTCAAATCAGAGCCAACCACAACCTACGGAGAGCGTTGGATCTCCACAAAGCCTTCTTCAATTTCCAAGTCTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAGTAGATTCAAATTACTTGTAATGTCGTATTTAGACAATTTAGGCGTTATTTCAGTTAACAATGTAATTAGAGCTGTTGCATTCGCGACAGATAAACATTATGTAAGCGATGTACTCGAGAATCATGAAATAAAATACAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAPQATNGVFIWEVPNPLYFKIIRVEVPLHTHSKVFHIQIRANHNLRRALDLHKAFFNFQVWTTLTTASGQIYLSRFKLLVMSYLDNLGVISVNNVIRAVAFATDKHYVSDVLENHEIKYKIY |
|
NCBI Accession
|
YP_009472134.1
|
|
Location
|
1084-1500 |
|
Gene Name
|
AL2 |
|
Protein Name
|
transactivation protein |
|
Coding Region
|
ATGACTGGGCACAACAAAACGCCATCTTCATCACCATTGAGGAACCGTTCTTCACCACTGTCGATCAAGGCTCAACACAGATACGCCAAGAGACAAACGAGGCGTAAAAGAATTGATCTCCAGTGCGGTTGTTCAATATACGTCCACATAAATTGCGCCAATCATGGATTCACGCACAGGGGAACCCATCACTGCGCCTCAAGCAACGAATGGCGTTTTTATTTGGGAGGTTCCAAATCCCCTATATTTCAAGATAATCAGAGTGGAGGTCCCATTACACACGCACAGCAAGGTCTTCCACATTCAAATCAGAGCCAACCACAACCTACGGAGAGCGTTGGATCTCCACAAAGCCTTCTTCAATTTCCAAGTCTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAGTAG |
|
Protein Sequence
|
MTGHNKTPSSSPLRNRSSPLSIKAQHRYAKRQTRRKRIDLQCGCSIYVHINCANHGFTHRGTHHCASSNEWRFYLGGSKSPIFQDNQSGGPITHAQQGLPHSNQSQPQPTESVGSPQSLLQFPSLDDIDDSFWADLFK |
|
NCBI Accession
|
YP_009472135.1
|
|
Location
|
1394-2470 |
|
Gene Name
|
AL1 |
|
Protein Name
|
replication initiation protein |
|
Coding Region
|
ATGCCACTCCCAAAACGCTTTCGCTTAAATGCCAAGAAATACTTCCTCACATATCCTCAATGTTCCATATCTAAAGAAGAGGCGCTCGAGCAAATACAGCGCCTTTCGACTCCAGTAAACAAGAAGTTCATCAAGATATGCAGAGAAACACATGAAGATGGGCAACCTCATCTACACGTGCTCATACAGTTCGAAGGAAAATTCCAGTGCACGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACACAATTGAATGGGGAGAGTTCCAAATCGACGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCTAATGACACATACGCAAAGGCATTAAACGCAACATCTGCAGAAGCGGCTCTGCAGATCATAAAGGAAGAACAACCCCAACATTTCTTTCTTCAATTTCATAACCTAATCACAAACGCAAACAGGATTTTCCAGAAACCACCGGAACCATGGGTCCCTCCATTTCAACAGTCATCGTTCAATAATGTTCCTCCGATAATTACGCAATGGGTTAATCAAAACGTTTGCGATTCCGCTGCGCGGCCATTGAGACCTATATCAATCGTTATTGAGGGACCATCAAGGACGGGCAAAACACAATGGGCCCGAAGTCTCGGCCCTCACAATTACCTATGTGGTCATCTAGATCTCAATCAAAAAATCTACTCCAATAATGCATGGTATAACGTAATCGATGACGTCAATCCGCATTATCTGAAACACTTTAAGGAGTTCATGGGGGCCCAAAGGGATTGGCAATCGAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGAGGAATTCCCGCTATCTTCCTCTGCAATCCTGGCCCCCATTCATCATATAAGGAGTATCTCAGCAAAGAGAAAAACAAAAGCCTCAATGACTGGGCACAACAAAACGCCATCTTCATCACCATTGAGGAACCGTTCTTCACCACTGTCGATCAAGGCTCAACACAGATACGCCAAGAGACAAACGAGGCGTAA |
|
Protein Sequence
|
MPLPKRFRLNAKKYFLTYPQCSISKEEALEQIQRLSTPVNKKFIKICRETHEDGQPHLHVLIQFEGKFQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQSANDTYAKALNATSAEAALQIIKEEQPQHFFLQFHNLITNANRIFQKPPEPWVPPFQQSSFNNVPPIITQWVNQNVCDSAARPLRPISIVIEGPSRTGKTQWARSLGPHNYLCGHLDLNQKIYSNNAWYNVIDDVNPHYLKHFKEFMGAQRDWQSNCKYGKPIQIKGGIPAIFLCNPGPHSSYKEYLSKEKNKSLNDWAQQNAIFITIEEPFFTTVDQGSTQIRQETNEA |
|
NCBI Accession
|
YP_009472136.1
|
|
Location
|
2056-2319 |
|
Gene Name
|
AL4 |
|
Protein Name
|
AL4 |
|
Coding Region
|
ATGAAGATGGGCAACCTCATCTACACGTGCTCATACAGTTCGAAGGAAAATTCCAGTGCACGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACACAATTGAATGGGGAGAGTTCCAAATCGACGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCTAATGACACATACGCAAAGGCATTAA |
|
Protein Sequence
|
MKMGNLIYTCSYSSKENSSARITDSSTWYPQPGQHISIRTYRELNPAPTSSPTSTRMETQLNGESSKSTADQLEEVSNLLMTHTQRH |