Rhynchosia golden mosaic Sinaloa virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002867615.1 |
| Isolate |
Mexico: Los Mochis, Sinaloa |
| Release date |
2018/8/26 |
| Submitter |
Mauricio-Castillo,J.A., Arguello-Astorga,G.R., Mendez-Lozano,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
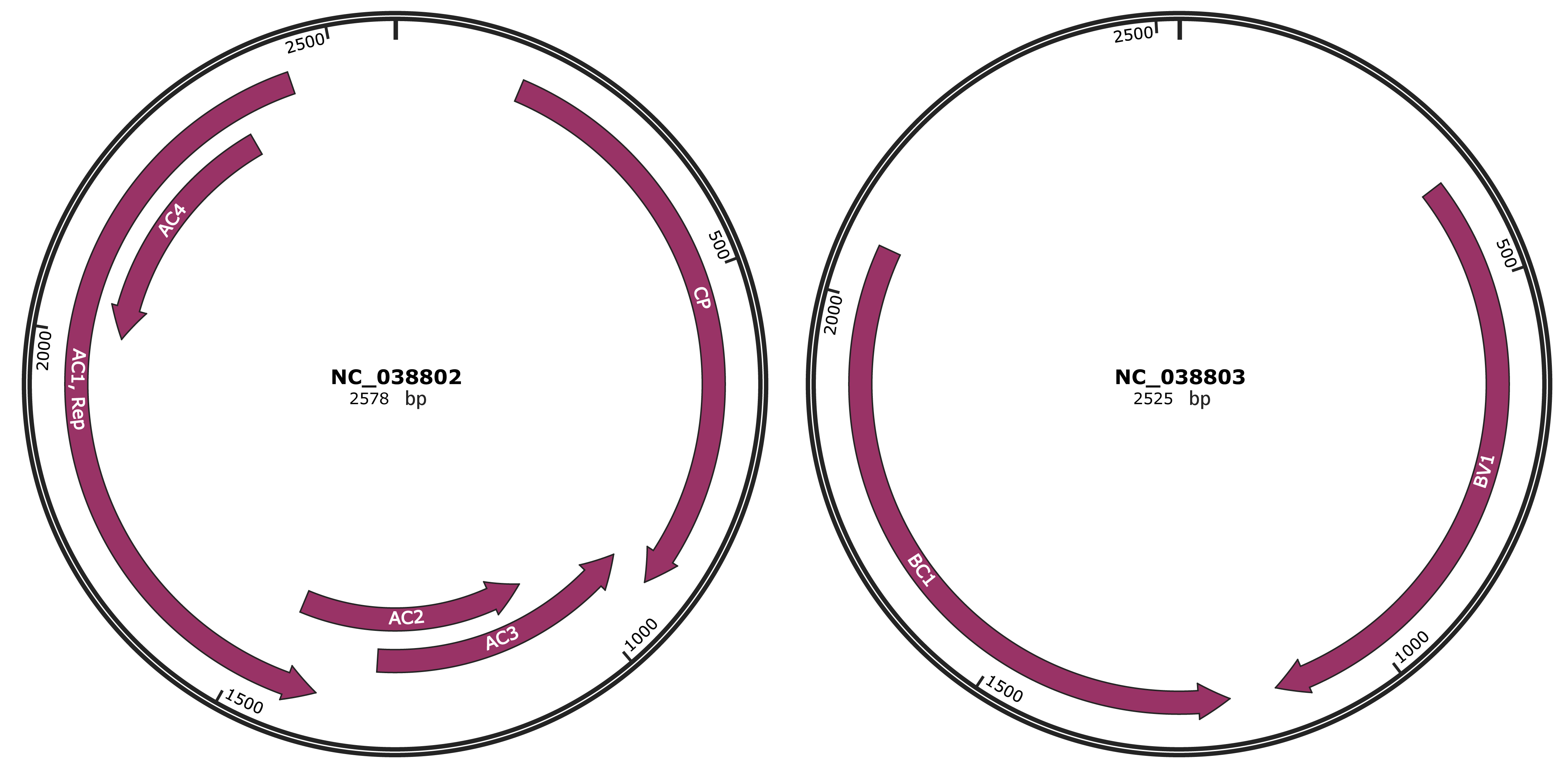
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTGGAGGATGCGTGGGACCCCGCAATAAATGAAATTTGAACTGACCAATCACATTGCGCCTGACTAGCCTAGATATTTGTGACTTGGCGACCAAGTTGTGGGCCTATAAAACGACGTGAAATTTCATTTATTGCTTTAATTCAAAATGGTTAAGCGGGATGCCCCATGGCGCCTATCTGCTGGGACCTCTAAGGTATCCCGCTCTACCAATTATACGCCTCGTGCAGGCATGGGCCCAAAATTTGATAAGGCCTCTGCCTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGGACGTTGAGAAGCCCCGATGTTCCAAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCTTTTGAATCAAGACATGATGTTACTCATGTTGGCAAGGTGATGTGCATTTCCGACGTGACACGTGGTAATGGTATTACCCATCGTGTTGGTAAGCGTTTCTGCGTTAAGTCCGTGTACATTTTGGGCAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACCAACAGCGTCATGTTTTGGTTGGTGCGAGACCGGAGACCCTATGGTACGCCTATGGATTTTGGCCAGGTATTCAACATGTTCGATAACGAACCCAGTACTGCCACTGTCAAGAACGATCTTCGTGATCGTTATCAAGTCATGCACAAGTTCTACGCTAAGGTGACTGGTGGACAGTATGCTAGCAACGAGCAGGCGTTGGTTAAACGCTTTTGGAAGGTCAACAACTACGTCGTGTACAACCATCAGGAAGCAGCTAAATACGAGAATCATACGGAGAACGCTTTGTTATTGTATATGGCGTGTACTCATGCGTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATATCAAATTAATAAATTTTGAATTTTATTTCATGATTCTCGAGTACATCAGTTACATAATGTTTGTTCGTCGCGAAACGAACAGCTCTAATTACATTGTTTATTCCTATAACGCCTAAGCTATCTAAATAAGACATAACAAGTAATTTAAATCTAGCTAAATATCTCTGCCCAGAAGCTCTCATCGAAGTCGTCCAGACTTGGAAGTTGAAGTAGGCTTTGTGGAGACCCAACGCTCTCCGTAGGTTGTGGTTGAACCGGACTTCGATGTGATATATCCTGGTTCTTGTGAATAACGGGTTCTCTACGTGGTGTATCTTGAAAAAGAGGGGATTTGGAACCTCCCAAATAAAAACGGAACTCTCTGCTTGACCCGCAGTGATGCTCTCCCCTGTGCGTGAATCCATTGTCTGCGCAGTTAATGTGTAGGAATATAGAACAGCCACAGTTCAAGTCTATGCGTCGTCGACGAACAGCTCTCCGTTTAGCAATCCTGTGCTGTGCTTTGATAGAGGGGGGCTTCAAGGGTGACGAATTGAGCATTTTTGACCGTCCAAGCTTTTAGTGATGCATTTTCCTCTTTGTTGAGGAAAGATATATAGCTGCTCCCCTCTCCTGGATTGCACAGCACGATTGACGGTATGCCACCTTTAATTTGAACTGGCTTTCCGTATTTGCAGTTTGATTGCCAGTCCTTTTGGGCCCCTATGAGTTCTTTCCAATGCTTTAGCTTTAAGTATTGCGGAGCTATGTCATCAATGACGTTATACTCCACATCATTTGAATAGACCTTGGAATTGAAGTCGAGGTGACCACTCAAGTAATTATGTGGGCCTAAAGCACGTGCCCACATCGTCTTTCCTGTTCTAGAACCACCTTCAATTATGATACTAATAGGTCGTTCTGGCCGCGCAGCGGAACTCCGACCAAAATAATCATTAACCCAAGCTTGAATGTCGTCCGGGACGTTAGTAAAGGAGGAGAGTTGAAACGGAGGAGCCCATGGTTCCGGAGCCTTTTGCAAGAGGCGCTCGATGTTAGACTTGATGTTATGATAACTAACGATAAATGTTTTTGGATCACCGGCTTTTATTATGGCGAGAGCCTCTTGCACACTTGCTGCATTAACTGCGTTATGGTAGACATCGTCCTTATTTGCTTTTGAACCCCCAGATACTTTGTATTGTCCGGATTCACAATAATCACCATCTTTGGCGATGTAATTCTGGACGGCATTGGTGTCTTTGGCCGCCTGAATGTTTGGGTGAAAATTGGTAGACCTTCTGGGGTGAGCGATGTCGAAAAATCTAGCATTCTTGATGTCGGACTCTCCTGATAGTTGGATGAGACAGTGTAAATGAGGGAACCCGTCTGAATGTTGCTCTCTTGCGACACGTATGTATGTGGGTTTGACGACTGACCATGGCAGCGACTGAAGCAACTGAAGAGCCTCATCTTTGGATATGTCGCACTGGGGATATGTTAAGAAAATGTTTCTGGCTTGTAAACGAAAGGAATTAGGGTTTCGTGGCATTTTTGTAAATAAGCCGAGGTACTCCAGCGGAGTCCTCCAGCAACTTGAGTGCTATATGCTGGAGGATTGGAGGACTATATATACTAAAAGGCTCTAGGGTACTCCAGGGGCAAAAGCGGCCATCCGTAATAATATT
ACCGGGATGGCCGCGATTTTTTGGAGGATAGCCCTCTTGGCGAACCCCCCCCTTTTGGCGTGCCCCACACACCCTTTGGCGTACCCCCCTTCCTTTGGCGTACCCTTTTGACGTGGTGCGCTGAATACCGTTGGATAAAGTTAATCGCGCAATTGGGTTTGAATTTTGAATTTGTTGCGCGGATATTTGTGTATGGACCATGTGCAAAACGATAAGGTATTCTGACACATTGTTTACGTGGGCCAATTAAAACTCCGCTGGCGAGTTAAGTTATTTGTATTTTGAATGTTGTTGTGTATATAATGGAGCGGAGTTTTATATTTAAAATCGTCTTTTGACATTAAAATATACATAGCCTATTATATAATATGTATTCGTCTAAGTTCCGACGTGGGGCATCATATTCACAGCGACGATTTTATCCACGTAATCAAGTATTTAAACGATCATCGGCGGTTAAACGTAACGATGGTAAACGTCGATCAAGTCATGTTAATAAGCTGCATGATGAGCCCAAGTTGAAGTCGCAATGCATACATGAGAACCAATATGGTTCCGAATTTGTTATGATTCATAATGCAGCTATTTCGACGTATATTAATTTTCCAGTTCTTGGTAAGAGTGAACCCAATCGTAGCAGGTCTTATATTAAGTTGAAACGGTTGTCTTTTAAAGGAACCGTTAGGATTGAGCGTGTTCACGCTGATGTGAACATGGACGGATTAAGCTCTAAGATTGAAGGAGTTTTCACTCTAGTGGTTGTAATTGACCGTAAACCACATTTGAGTTCCTCTGGATGTCTACATACATTTGACGAATTATTTGGAGCAAAAATCCACAGTCACGGTAATCTATGTATAAGTCCAGCGTTGAAAGATCGTTATTATGTGCGGCATGTTTTGAAGCGCGTTGTGTCTGTTGAGAAAGATAGTGTGATGTTAGACCTTGAAGGATGCAGCTCCTTATCTAATAAGCGCTTCAATTGTTGGTCTAGTTTTAAGGATTTAGAGCATGACTCATGTAACGGTGTTTATGCGAATATAAGCAAGAACGCCATATTAGTTTATTATTGTTGGATGTCGGATGTCATGTCCAAGGCATCTACATTTGTATCGTTTGATCTTGACTACGTTGGATAAACAATAATAAAATAATGAATTTGTTTCATATTATGACCTGGCAAGAAAAAACATGTTATTTATTGCAACGATTTTGGTGGTGCTGCATTACAATTACTATTAATACATTCTTGGACCGTAGTCCTAACAAGCTCGTTTAATTGGGCCATGGACATTGTGATGTTTGATTGGGCCCTCTGTAAACCCACTTGTGACGCAGAATCCCCTGGGTCTAACACGCTCCCTCCCAAACGATTAAGCTCTCTATACGGATGTAACTCGGAGTCCGTTTCCGTGTGAGGCCTACCTATTGTGCTTCGGGAAGCCCACGACTCGCCTGGTTTTAATTCTATTGGGCCTGTTAGCCCAAGACGTGACATGGATGTGGACCTTATTGTCTTCCGTTCCCATGGGCCGTAATCCACATGCGAGAAGTCCACATCCTTATGGGAGAACTGTTTAGAAAGGATTTTGACCGTGGGCGCCCGAAATGGTATATCTACAGAGTGCTTTGCCGTGGATAGTTTTAATTTGCCTTTGAACTTGGCAAAATGTGTCCTTTGATGGACATTTGTATCGGACACTCTGTAGTATAATTTCCATGGAATTGGATCCTTTAGCGAAAAGAATGACGATGAGAAATAATGGAGATCTATGTTACATCTTATGGGAAATGTCCAGGACGCTTGTAGCGATTCGTTGTCCGTCATTCTTTTGTCATGAATTTCCACAATTACCGAGCCAGTTGCGTTAATCGGAACTTGTTGTCTGTATTCAATGACGCAATGGTCAATTTTCATACAGCTCCGATTTAGTCTTGCTGTTAACTGCGACGCTGTTGAAGGGAATTGAAGCACTATCTCAGTTAGATCATGAGACAATTGATATTCATCTCTGTGCGACTCTATATAATTGAACGCATTCGGTGCATTGGCTAACTGAGATTCCATATATGAATAATTGGCCGCGCAGCGGAACTGTCTGCAGAAGAATATGAACGGTTATGAATATTGTTGTGTACAAGAACAATTGGAACAAGAAGATATGGCGATGAAGGTTATTGCGATTGTGTTGAGCAACAAATTAATAACCAATTGGACAAGAATTTATATCAACAGTGGATATTATGTGTAGAACAAGTGAGAACTGAAGAAGATGATAGGTTGGTTAACTGGGAAATGATGTTGTGATGAACTGGAACGAGAGCGTTTCTTATATAGGCAGTTCATGTGTTAGAATTATTTAGTTAAAGGATACAATGTTAGTGGCATATTTGTAAATAAGGCAGGGTACTCCAGCGGAGTCCTCCAGCAACTTGAGTGCTATATGCTGGAGGATTGGAGGACTATATATACTAAAAGGCTCTAGGGTACTCCAGGGGCAAAAGCGGCCATCCGTAATAATATT
Gene Information
|
NCBI Accession
|
YP_009508013.1
|
|
Location
|
165-920 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGGTTAAGCGGGATGCCCCATGGCGCCTATCTGCTGGGACCTCTAAGGTATCCCGCTCTACCAATTATACGCCTCGTGCAGGCATGGGCCCAAAATTTGATAAGGCCTCTGCCTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGGACGTTGAGAAGCCCCGATGTTCCAAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCTTTTGAATCAAGACATGATGTTACTCATGTTGGCAAGGTGATGTGCATTTCCGACGTGACACGTGGTAATGGTATTACCCATCGTGTTGGTAAGCGTTTCTGCGTTAAGTCCGTGTACATTTTGGGCAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACCAACAGCGTCATGTTTTGGTTGGTGCGAGACCGGAGACCCTATGGTACGCCTATGGATTTTGGCCAGGTATTCAACATGTTCGATAACGAACCCAGTACTGCCACTGTCAAGAACGATCTTCGTGATCGTTATCAAGTCATGCACAAGTTCTACGCTAAGGTGACTGGTGGACAGTATGCTAGCAACGAGCAGGCGTTGGTTAAACGCTTTTGGAAGGTCAACAACTACGTCGTGTACAACCATCAGGAAGCAGCTAAATACGAGAATCATACGGAGAACGCTTTGTTATTGTATATGGCGTGTACTCATGCGTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATATCAAATTAA |
|
Protein Sequence
|
MVKRDAPWRLSAGTSKVSRSTNYTPRAGMGPKFDKASAWVNRPMYRKPRIYRTLRSPDVPRGCEGPCKVQSFESRHDVTHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009508014.1
|
|
Location
|
917-1315 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGAGCATCACTGCGGGTCAAGCAGAGAGTTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTTTTTCAAGATACACCACGTAGAGAACCCGTTATTCACAAGAACCAGGATATATCACATCGAAGTCCGGTTCAACCACAACCTACGGAGAGCGTTGGGTCTCCACAAAGCCTACTTCAACTTCCAAGTCTGGACGACTTCGATGAGAGCTTCTGGGCAGAGATATTTAGCTAGATTTAAATTACTTGTTATGTCTTATTTAGATAGCTTAGGCGTTATAGGAATAAACAATGTAATTAGAGCTGTTCGTTTCGCGACGAACAAACATTATGTAACTGATGTACTCGAGAATCATGAAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGESITAGQAESSVFIWEVPNPLFFKIHHVENPLFTRTRIYHIEVRFNHNLRRALGLHKAYFNFQVWTTSMRASGQRYLARFKLLVMSYLDSLGVIGINNVIRAVRFATNKHYVTDVLENHEIKFKIY |
|
NCBI Accession
|
YP_009508015.1
|
|
Location
|
1062-1451 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCTCAATTCGTCACCCTTGAAGCCCCCCTCTATCAAAGCACAGCACAGGATTGCTAAACGGAGAGCTGTTCGTCGACGACGCATAGACTTGAACTGTGGCTGTTCTATATTCCTACACATTAACTGCGCAGACAATGGATTCACGCACAGGGGAGAGCATCACTGCGGGTCAAGCAGAGAGTTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTTTTTCAAGATACACCACGTAGAGAACCCGTTATTCACAAGAACCAGGATATATCACATCGAAGTCCGGTTCAACCACAACCTACGGAGAGCGTTGGGTCTCCACAAAGCCTACTTCAACTTCCAAGTCTGGACGACTTCGATGAGAGCTTCTGGGCAGAGATATTTAGCTAG |
|
Protein Sequence
|
MLNSSPLKPPSIKAQHRIAKRRAVRRRRIDLNCGCSIFLHINCADNGFTHRGEHHCGSSREFRFYLGGSKSPLFQDTPRREPVIHKNQDISHRSPVQPQPTESVGSPQSLLQLPSLDDFDESFWAEIFS |
|
NCBI Accession
|
YP_009508016.1
|
|
Location
|
1393-2442 |
|
Gene Name
|
AC1, Rep |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCACGAAACCCTAATTCCTTTCGTTTACAAGCCAGAAACATTTTCTTAACATATCCCCAGTGCGACATATCCAAAGATGAGGCTCTTCAGTTGCTTCAGTCGCTGCCATGGTCAGTCGTCAAACCCACATACATACGTGTCGCAAGAGAGCAACATTCAGACGGGTTCCCTCATTTACACTGTCTCATCCAACTATCAGGAGAGTCCGACATCAAGAATGCTAGATTTTTCGACATCGCTCACCCCAGAAGGTCTACCAATTTTCACCCAAACATTCAGGCGGCCAAAGACACCAATGCCGTCCAGAATTACATCGCCAAAGATGGTGATTATTGTGAATCCGGACAATACAAAGTATCTGGGGGTTCAAAAGCAAATAAGGACGATGTCTACCATAACGCAGTTAATGCAGCAAGTGTGCAAGAGGCTCTCGCCATAATAAAAGCCGGTGATCCAAAAACATTTATCGTTAGTTATCATAACATCAAGTCTAACATCGAGCGCCTCTTGCAAAAGGCTCCGGAACCATGGGCTCCTCCGTTTCAACTCTCCTCCTTTACTAACGTCCCGGACGACATTCAAGCTTGGGTTAATGATTATTTTGGTCGGAGTTCCGCTGCGCGGCCAGAACGACCTATTAGTATCATAATTGAAGGTGGTTCTAGAACAGGAAAGACGATGTGGGCACGTGCTTTAGGCCCACATAATTACTTGAGTGGTCACCTCGACTTCAATTCCAAGGTCTATTCAAATGATGTGGAGTATAACGTCATTGATGACATAGCTCCGCAATACTTAAAGCTAAAGCATTGGAAAGAACTCATAGGGGCCCAAAAGGACTGGCAATCAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGCATACCGTCAATCGTGCTGTGCAATCCAGGAGAGGGGAGCAGCTATATATCTTTCCTCAACAAAGAGGAAAATGCATCACTAAAAGCTTGGACGGTCAAAAATGCTCAATTCGTCACCCTTGAAGCCCCCCTCTATCAAAGCACAGCACAGGATTGCTAA |
|
Protein Sequence
|
MPRNPNSFRLQARNIFLTYPQCDISKDEALQLLQSLPWSVVKPTYIRVAREQHSDGFPHLHCLIQLSGESDIKNARFFDIAHPRRSTNFHPNIQAAKDTNAVQNYIAKDGDYCESGQYKVSGGSKANKDDVYHNAVNAASVQEALAIIKAGDPKTFIVSYHNIKSNIERLLQKAPEPWAPPFQLSSFTNVPDDIQAWVNDYFGRSSAARPERPISIIIEGGSRTGKTMWARALGPHNYLSGHLDFNSKVYSNDVEYNVIDDIAPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYISFLNKEENASLKAWTVKNAQFVTLEAPLYQSTAQDC |
|
NCBI Accession
|
YP_009508017.1
|
|
Location
|
2001-2363 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAGGCTCTTCAGTTGCTTCAGTCGCTGCCATGGTCAGTCGTCAAACCCACATACATACGTGTCGCAAGAGAGCAACATTCAGACGGGTTCCCTCATTTACACTGTCTCATCCAACTATCAGGAGAGTCCGACATCAAGAATGCTAGATTTTTCGACATCGCTCACCCCAGAAGGTCTACCAATTTTCACCCAAACATTCAGGCGGCCAAAGACACCAATGCCGTCCAGAATTACATCGCCAAAGATGGTGATTATTGTGAATCCGGACAATACAAAGTATCTGGGGGTTCAAAAGCAAATAAGGACGATGTCTACCATAACGCAGTTAATGCAGCAAGTGTGCAAGAGGCTCTCGCCATAA |
|
Protein Sequence
|
MRLFSCFSRCHGQSSNPHTYVSQESNIQTGSLIYTVSSNYQESPTSRMLDFSTSLTPEGLPIFTQTFRRPKTPMPSRITSPKMVIIVNPDNTKYLGVQKQIRTMSTITQLMQQVCKRLSP |
|
NCBI Accession
|
YP_009508018.1
|
|
Location
|
369-1139 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTCGTCTAAGTTCCGACGTGGGGCATCATATTCACAGCGACGATTTTATCCACGTAATCAAGTATTTAAACGATCATCGGCGGTTAAACGTAACGATGGTAAACGTCGATCAAGTCATGTTAATAAGCTGCATGATGAGCCCAAGTTGAAGTCGCAATGCATACATGAGAACCAATATGGTTCCGAATTTGTTATGATTCATAATGCAGCTATTTCGACGTATATTAATTTTCCAGTTCTTGGTAAGAGTGAACCCAATCGTAGCAGGTCTTATATTAAGTTGAAACGGTTGTCTTTTAAAGGAACCGTTAGGATTGAGCGTGTTCACGCTGATGTGAACATGGACGGATTAAGCTCTAAGATTGAAGGAGTTTTCACTCTAGTGGTTGTAATTGACCGTAAACCACATTTGAGTTCCTCTGGATGTCTACATACATTTGACGAATTATTTGGAGCAAAAATCCACAGTCACGGTAATCTATGTATAAGTCCAGCGTTGAAAGATCGTTATTATGTGCGGCATGTTTTGAAGCGCGTTGTGTCTGTTGAGAAAGATAGTGTGATGTTAGACCTTGAAGGATGCAGCTCCTTATCTAATAAGCGCTTCAATTGTTGGTCTAGTTTTAAGGATTTAGAGCATGACTCATGTAACGGTGTTTATGCGAATATAAGCAAGAACGCCATATTAGTTTATTATTGTTGGATGTCGGATGTCATGTCCAAGGCATCTACATTTGTATCGTTTGATCTTGACTACGTTGGATAA |
|
Protein Sequence
|
MYSSKFRRGASYSQRRFYPRNQVFKRSSAVKRNDGKRRSSHVNKLHDEPKLKSQCIHENQYGSEFVMIHNAAISTYINFPVLGKSEPNRSRSYIKLKRLSFKGTVRIERVHADVNMDGLSSKIEGVFTLVVVIDRKPHLSSSGCLHTFDELFGAKIHSHGNLCISPALKDRYYVRHVLKRVVSVEKDSVMLDLEGCSSLSNKRFNCWSSFKDLEHDSCNGVYANISKNAILVYYCWMSDVMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009508019.1
|
|
Location
|
1199-2068 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTAGCCAATGCACCGAATGCGTTCAATTATATAGAGTCGCACAGAGATGAATATCAATTGTCTCATGATCTAACTGAGATAGTGCTTCAATTCCCTTCAACAGCGTCGCAGTTAACAGCAAGACTAAATCGGAGCTGTATGAAAATTGACCATTGCGTCATTGAATACAGACAACAAGTTCCGATTAACGCAACTGGCTCGGTAATTGTGGAAATTCATGACAAAAGAATGACGGACAACGAATCGCTACAAGCGTCCTGGACATTTCCCATAAGATGTAACATAGATCTCCATTATTTCTCATCGTCATTCTTTTCGCTAAAGGATCCAATTCCATGGAAATTATACTACAGAGTGTCCGATACAAATGTCCATCAAAGGACACATTTTGCCAAGTTCAAAGGCAAATTAAAACTATCCACGGCAAAGCACTCTGTAGATATACCATTTCGGGCGCCCACGGTCAAAATCCTTTCTAAACAGTTCTCCCATAAGGATGTGGACTTCTCGCATGTGGATTACGGCCCATGGGAACGGAAGACAATAAGGTCCACATCCATGTCACGTCTTGGGCTAACAGGCCCAATAGAATTAAAACCAGGCGAGTCGTGGGCTTCCCGAAGCACAATAGGTAGGCCTCACACGGAAACGGACTCCGAGTTACATCCGTATAGAGAGCTTAATCGTTTGGGAGGGAGCGTGTTAGACCCAGGGGATTCTGCGTCACAAGTGGGTTTACAGAGGGCCCAATCAAACATCACAATGTCCATGGCCCAATTAAACGAGCTTGTTAGGACTACGGTCCAAGAATGTATTAATAGTAATTGTAATGCAGCACCACCAAAATCGTTGCAATAA |
|
Protein Sequence
|
MESQLANAPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSHKDVDFSHVDYGPWERKTIRSTSMSRLGLTGPIELKPGESWASRSTIGRPHTETDSELHPYRELNRLGGSVLDPGDSASQVGLQRAQSNITMSMAQLNELVRTTVQECINSNCNAAPPKSLQ |