Rhynchosia golden mosaic Havana virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002867595.1 |
| Isolate |
Cuba: Havana |
| Release date |
2018/8/26 |
| Submitter |
Fiallo-Olive,E., Navas-Castillo,J., Moriones,E., Martinez-Zubiaur,Y. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
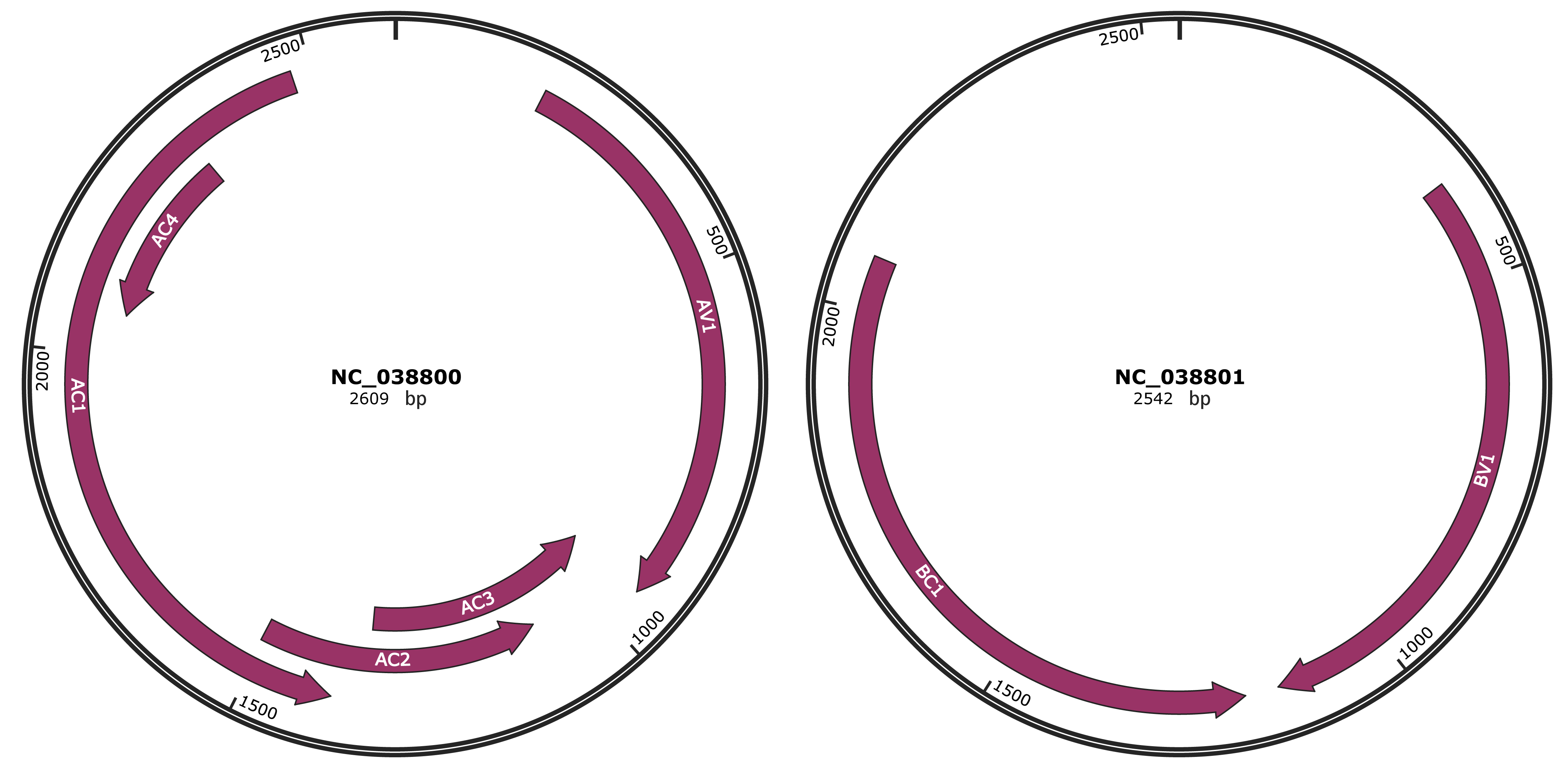
JBrowse
Genome
ACCGGATGGCCGACCAGCGTATTGGTGTATGCCGTACTGCACGTGTTGCTTTATTTTGAATTAAAGATTAAAGTGGTGCGTTGTCCAATCATATGCGCACTTGTGAGTCTAGTTATTTGTGTTCAAACTTAGTGGCCAAGTTTGCTTTCATTTAAATACGATCCAGCTTACGTGGATCGAACATGCTTTAATTCAAAATGCCTAAGCGCGATGGCTCTTGGCGTTCTATGGCGGGGACCTCCAAGGTGAGCCGCAATGCTAATTACTCTCCACGTTCTGGCCCAACGTCTAACAGGGCCAATGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGAATTTATAGGATGTACAGATCCCCTGATGTTCCTAAGGGTTGTGAAGGGCCCTGTAAAATTCAATCATTTGAACAGCGACATGATATTTCTCATACTGGTAAGGTTATGTGTATATCCGACGTCACACGTGGTAATGGTATTACCCATCGTGTTGGAAAACGATTTTGTGTGAAATCTGTGTACATATTAGGTAAGGTATGGATGGACGACAACATCAAGTTAAAGAACCATACCAACAGCGTCATGTTTTGGTTGGTTAGGGATAGAAGACCGTATGGAACTCCTATGGATTTTGGACAAGTTTTTAATATGTTCGACAATGAACCTAGTACAGCAACTGTTAAGAATGATTTGCGTGATCGTTTTCAAGTTATGCACAAGTTTTACTCCAAAGTTACAGGTGGACAATATGCAAGTAATGAACAGGCAATTGTTAAGCGGTTTTGGAAGGTGAATAACAATGTCGTCTATAATCACCAGGAAGCAGCAAAGTACGAGAACCATACTGAGAATGCGTTATTATTGTATATGGCATGTACTCATGCTTCGAATCCTGTGTATGCAACTCTTAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAATAAATCTTGAATTTTATTATATGATTTTCCAGTACATCGTTGACATAACTTTTGTTCGTCGCATAGGAAACAGCTCTAATTACATTATTAATTGAAATAACACCTAAATTGTCTAAGAACTGCATTACAAGAAACTTGAATCTACTTAAATAAATCTGCCCAGATGCTGTCGTCAAAGTCGTCCAAACTTGGAAATTGAAGTAAGCTTTGTGGAGAGCCAACGCTTTCCTCAGGTTGTGGTTGGCTCTGATTTGTAAGTGGAACACCGTCGTGTGTGTGAATATTGGTTTCTCTACTTCGATTATCTTGAAATACAGGGGATTTGGAACCTCCCAAATATAAACGCCACTCGTTGCTTGAACTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATTGTTCCTGCAGTTAATATGAATATAAATAGAACAGCCGCACTGCAGATCAATCCTTCTTCGTCTCACTTGTTTTTTCGCGTATCTGTGCCGCGGTTTGATTTGTGGTGGTGAAGAGAGGTTCTTCAATGGAGACGAAGATGGCGTTTTTCTTTGCCCAGTCATGGAGTGATGTGTTTTTTTCTTCGCCGAGGAACTCCTTATATGATGAATGGGGGCCTGGATTGCAAAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATTGGCTTTCCGTATTTGCAGTTTGATTGCCAATCCCTTTGTGCCCCCATGAACTCTTTAAAGTGCTTTAGATAATGCGGATCAACGTCATCGATAACGTTGTACCATGCATCATTGGAGTATATCTTCGGATTGAGATCGATATGACCACATAGATAATTGTGAGGGCCCATGCTTCGGGCCCATATTGTTTTGCCCGTCCTTGATGGTCCTTCAACAATAATTGATATAGGTCTCAATGGCCGCGCAGCGGCATCGGAAATATTAACGTTAACCCATTCCGACATTATCGCCGGGACATTATTGAATGTGGACAATTGAAATGGAGGAACCCATGGTTCCGGTGGTTTATGAAATATTTTCGTTATGTTGGACACCAGGTTATGGTATTGGAGGACAAAATGTTGTGGTTGATGCTCTTTGATAATCTGCAGAGCCTGTTCTGCAGATTCTGCATTTAACGCCTTTGCATATGAGTCGTTCGCAGTTTGTTGTCCTCCTCTAGCAGACCTGCCGTCGATTTGAAACTCTCCCCATTGAAGTGTATCTCCATCCTTGTCGATGTAGGACTTGACGTCTGAGCTTGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTGGTTGTGGATACCAGGTCGAAGAATCTGTTATTCGTGCACTGGTATTTGCCTTCGAACTGGATGAGCACGTGAAGATGAGGTTCCCCATTTTCATGAAGTTCTTTGCAAATCTTGATGAACTTCTTGTTTACGGGAGTCGGAATGGACAATAGCTGACCTAGGGCTTCTTCTTTTGAGATGGAGCATTTGGGGTATGTGAGGAAGAAGTTCTTGGCATTTAAGCGAAATCGCCTCTGTAATGGCATTTCTGTAATAAGAAGGGTGTACCCCGATTGAGGCTCTCAACACTGGCTCATTATATTGGTGTATTGGGGTGCAATATATAGTATACCTTCTATTCGTTATCTGCTTACACGTGGAGGCCATCCGTTATAATATT
ACCGGATGGCCGACCCGGGGTATTGGTGTATGCCTTTCCCCCGCGCGCTTCTCTTCTCTCCGTACGCCGCATTTGCTTTCCCATTTTGCCCTTACCATGTGGCGCATCACAGACCGTTGGATAAACTTAGCGCTTGTGACCGTTGGATTGCGCTATAACGTTTGAATTTTGAATTATTGATGGTCCCGAGGCTGACGTATGCCACGTGAACAAGTGGATTGTGTGGTCTACATACTGGTGTCTTTGATACGTGGACCAGTCAAAATTCATATTGTGCGTCTATTTAAATCCTCGAGGTCATGTACATTCTTTATATATTGGATCTTTTATTGGTTTTGATATCTATTGTTGACATTGTGAAGAGGATTTACAATGTATTTTTCTAGAAATCGACGTGGATCGTTTTATTCTCAACGACGAGGTTATGGTCGTAATTATTTGCCCAAACGTTCAGTTGGTGTGAAACGGAATGATTCCAAACGTCGATACGGTCAACTAGGTAAAGTGTGTGATGATTCTAAAATGTTTAATCAACGAATCCATGAAAATCAATTTGGGCCCGAATTTGTTATGGCCCATAATACAGCCATATCTACGTTCATTAATTATCCTCACTTGGGAAAGACTGAGCCCAATCGAAGCAGATCATATATTAAGTTAAAAAGACTACGTTATAAAGGAACAGTGAAGATAGAACGTGTTCATGCCGATGTGAATATGGACGTTTTAACCCCCAAAATTGAAGGTGTTTTCTCTTTGGTTATTGTGGTTGATCGTAAACCACATTTGACTGCAAGTGGTTGTCTGCTTACATTTGATGAATTATTTGGAGCACGAATTCATAGTCATGGAAACTTGGCTATTAGTCCCTGTTGGAAGGACCGTTTTTATATACGGAATGTGTTTAAGCGTGTGTTATCCGTGGAGAAGGACACCACGATGATCGATGTTGAAGGTTCAACCACTCTTTCAAATAGGCGTTTTAATTTATGGTCTACTTTTAAGGATATTGATCATGATTCATGTAACGGTGTTTATGCTAACATTAGTAAGAACGCCCTTCTAGTTTATTATTGTTGGATGTCAGATGCTATGTCTAAAGCATCCTCATTTGTGTCGTTTGACCTTGATTATGTTGGTTAAATATGTAGTAATGAACAACAATATGTATAAATAAAATACTCATTTATTGTAATGATTTCGGTTGCGTCGGATTACAATTGCTGTTTATACATTCGTGCACTGTTGTCCGAACTATCTCGTTTAATTGAGCTATGGACATTGTTATGTTGGACTGTGTTCTCTGGGATCCTACAATCGAAGCCGAGTCTCCTGGGTCTAATACGCTTGTTCCAAGCCTGTTTAGTTGTCTGTATGGGTGTATTGCGTTCTCTATATCTGAGTCCGCATCTGTATGGCTCAATCCAATTGTGCTTTTACTGGCCCAAGATTCGCCCGGTTTTAATTCAATTGGGCCTTGTAGTCCATATCTTGATAATGATGCGGACCTTATCGTCTTTCTTTCCCATTTTCCATAGTCCACGTGTGAGAAATCCACATCTCTGTTAGAAAACTGTTTGGAAAGGATTTTTACGGTTGGGGCTCTGAACGGTATATCCACTGAGTGCTTCGCCGTGGATAATTTTAGTTTTCCTTTGAATTTTGCGAAATGTGTCCTTTGGTGGACGTTTGTATCAGACACTCGATAATACAGTTTCCATGGTATGGGGTCTTTCAGTGAGAAGAAAGACGAAGAAAAATAGTGGAGATCTATGTTGCATCTGATTGGAAACGTCCAGGATGCTTGTAATGATTCGTTGTCCGTCATTCTTCTGTCATGAATCTCCACTATTACGGAACCTGTTGCGTTAATAGGTACCTGTTGTCTATATTCTATGACGCAGTGGTCTATTTTCATACAGCTACGACTGAGTCTTGCTGACAATTGAGACGCTGTAGAAGGAAATTGCAGGACAATTTCTGTTAGATCATGAGAAAGCTGATATTCATCTCTGTGAGACTCAATATAATTAAATGCATCGGGAGCACTTGGTAACTGAGAATCCATTTAATAATATATGGCCGCGCAGCGGAATTGTTTATGTAGATGAAGATATTGAAAGGGGTAATCTAATAAGAACCATATATGATTAAATAATGCGATATGTTGCCCCAAACTGTGTGCATATGTTTTTGAGCTGTTGACAAAGATGACAGTACTCAAGATGATCAAGGTTTTCAGAGACAAACATGATAAACAATTACACAGATGGGTATACTATGCAGTAACAGGCAGGGCAGTGAACAATTAAAATAAATAGTGTAATAGATTCAAGGAATGCGTCGACAGGTATGAGGAATCCATGATAGAGGTGTCATTATTATATAGGCGAAGCGAGAGTGGCATTCTTGTAATAAGAGGGGTGTACCCCGATTGAGGCTCTCAACACTGGCTCATTATATTGGTGTATTGGGGTGCAATATATAGTATACCTTCTATTCTATTGATTTTGTACACGTGGAGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508006.1
|
|
Location
|
198-947 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGGCTCTTGGCGTTCTATGGCGGGGACCTCCAAGGTGAGCCGCAATGCTAATTACTCTCCACGTTCTGGCCCAACGTCTAACAGGGCCAATGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGAATTTATAGGATGTACAGATCCCCTGATGTTCCTAAGGGTTGTGAAGGGCCCTGTAAAATTCAATCATTTGAACAGCGACATGATATTTCTCATACTGGTAAGGTTATGTGTATATCCGACGTCACACGTGGTAATGGTATTACCCATCGTGTTGGAAAACGATTTTGTGTGAAATCTGTGTACATATTAGGTAAGGTATGGATGGACGACAACATCAAGTTAAAGAACCATACCAACAGCGTCATGTTTTGGTTGGTTAGGGATAGAAGACCGTATGGAACTCCTATGGATTTTGGACAAGTTTTTAATATGTTCGACAATGAACCTAGTACAGCAACTGTTAAGAATGATTTGCGTGATCGTTTTCAAGTTATGCACAAGTTTTACTCCAAAGTTACAGGTGGACAATATGCAAGTAATGAACAGGCAATTGTTAAGCGGTTTTGGAAGGTGAATAACAATGTCGTCTATAATCACCAGGAAGCAGCAAAGTACGAGAACCATACTGAGAATGCGTTATTATTGTATATGGCATGTACTCATGCTTCGAATCCTGTGTATGCAACTCTTAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDGSWRSMAGTSKVSRNANYSPRSGPTSNRANAWVNRPMYRKPRIYRMYRSPDVPKGCEGPCKIQSFEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYSKVTGGQYASNEQAIVKRFWKVNNNVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009508007.1
|
|
Location
|
944-1342 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGTTCAAGCAACGAGTGGCGTTTATATTTGGGAGGTTCCAAATCCCCTGTATTTCAAGATAATCGAAGTAGAGAAACCAATATTCACACACACGACGGTGTTCCACTTACAAATCAGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCTTACTTCAATTTCCAAGTTTGGACGACTTTGACGACAGCATCTGGGCAGATTTATTTAAGTAGATTCAAGTTTCTTGTAATGCAGTTCTTAGACAATTTAGGTGTTATTTCAATTAATAATGTAATTAGAGCTGTTTCCTATGCGACGAACAAAAGTTATGTCAACGATGTACTGGAAAATCATATAATAAAATTCAAGATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAVQATSGVYIWEVPNPLYFKIIEVEKPIFTHTTVFHLQIRANHNLRKALALHKAYFNFQVWTTLTTASGQIYLSRFKFLVMQFLDNLGVISINNVIRAVSYATNKSYVNDVLENHIIKFKIY |
|
NCBI Accession
|
YP_009508008.1
|
|
Location
|
1089-1505 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGACTGGGCAAAGAAAAACGCCATCTTCGTCTCCATTGAAGAACCTCTCTTCACCACCACAAATCAAACCGCGGCACAGATACGCGAAAAAACAAGTGAGACGAAGAAGGATTGATCTGCAGTGCGGCTGTTCTATTTATATTCATATTAACTGCAGGAACAATGGATTCACGCACAGGGGAACCCATCACTGCAGTTCAAGCAACGAGTGGCGTTTATATTTGGGAGGTTCCAAATCCCCTGTATTTCAAGATAATCGAAGTAGAGAAACCAATATTCACACACACGACGGTGTTCCACTTACAAATCAGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCTTACTTCAATTTCCAAGTTTGGACGACTTTGACGACAGCATCTGGGCAGATTTATTTAAGTAG |
|
Protein Sequence
|
MTGQRKTPSSSPLKNLSSPPQIKPRHRYAKKQVRRRRIDLQCGCSIYIHINCRNNGFTHRGTHHCSSSNEWRLYLGGSKSPVFQDNRSRETNIHTHDGVPLTNQSQPQPEESVGSPQSLLQFPSLDDFDDSIWADLFK |
|
NCBI Accession
|
YP_009508009.1
|
|
Location
|
1390-2475 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATTACAGAGGCGATTTCGCTTAAATGCCAAGAACTTCTTCCTCACATACCCCAAATGCTCCATCTCAAAAGAAGAAGCCCTAGGTCAGCTATTGTCCATTCCGACTCCCGTAAACAAGAAGTTCATCAAGATTTGCAAAGAACTTCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGCAAATACCAGTGCACGAATAACAGATTCTTCGACCTGGTATCCACAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCAAGCTCAGACGTCAAGTCCTACATCGACAAGGATGGAGATACACTTCAATGGGGAGAGTTTCAAATCGACGGCAGGTCTGCTAGAGGAGGACAACAAACTGCGAACGACTCATATGCAAAGGCGTTAAATGCAGAATCTGCAGAACAGGCTCTGCAGATTATCAAAGAGCATCAACCACAACATTTTGTCCTCCAATACCATAACCTGGTGTCCAACATAACGAAAATATTTCATAAACCACCGGAACCATGGGTTCCTCCATTTCAATTGTCCACATTCAATAATGTCCCGGCGATAATGTCGGAATGGGTTAACGTTAATATTTCCGATGCCGCTGCGCGGCCATTGAGACCTATATCAATTATTGTTGAAGGACCATCAAGGACGGGCAAAACAATATGGGCCCGAAGCATGGGCCCTCACAATTATCTATGTGGTCATATCGATCTCAATCCGAAGATATACTCCAATGATGCATGGTACAACGTTATCGATGACGTTGATCCGCATTATCTAAAGCACTTTAAAGAGTTCATGGGGGCACAAAGGGATTGGCAATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTTTGCAATCCAGGCCCCCATTCATCATATAAGGAGTTCCTCGGCGAAGAAAAAAACACATCACTCCATGACTGGGCAAAGAAAAACGCCATCTTCGTCTCCATTGAAGAACCTCTCTTCACCACCACAAATCAAACCGCGGCACAGATACGCGAAAAAACAAGTGAGACGAAGAAGGATTGA |
|
Protein Sequence
|
MPLQRRFRLNAKNFFLTYPKCSISKEEALGQLLSIPTPVNKKFIKICKELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSTTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLQWGEFQIDGRSARGGQQTANDSYAKALNAESAEQALQIIKEHQPQHFVLQYHNLVSNITKIFHKPPEPWVPPFQLSTFNNVPAIMSEWVNVNISDAAARPLRPISIIVEGPSRTGKTIWARSMGPHNYLCGHIDLNPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEFLGEEKNTSLHDWAKKNAIFVSIEEPLFTTTNQTAAQIREKTSETKKD |
|
NCBI Accession
|
YP_009508010.1
|
|
Location
|
2061-2318 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGCAAATACCAGTGCACGAATAACAGATTCTTCGACCTGGTATCCACAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCAAGCTCAGACGTCAAGTCCTACATCGACAAGGATGGAGATACACTTCAATGGGGAGAGTTTCAAATCGACGGCAGGTCTGCTAGAGGAGGACAACAAACTGCGAACGACTCATATGCAAAGGCGTTAA |
|
Protein Sequence
|
MGNLIFTCSSSSKANTSARITDSSTWYPQPGQHISIQTYRELNQAQTSSPTSTRMEIHFNGESFKSTAGLLEEDNKLRTTHMQRR |
|
NCBI Accession
|
YP_009508011.1
|
|
Location
|
373-1143 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttling protein |
|
Coding Region
|
ATGTATTTTTCTAGAAATCGACGTGGATCGTTTTATTCTCAACGACGAGGTTATGGTCGTAATTATTTGCCCAAACGTTCAGTTGGTGTGAAACGGAATGATTCCAAACGTCGATACGGTCAACTAGGTAAAGTGTGTGATGATTCTAAAATGTTTAATCAACGAATCCATGAAAATCAATTTGGGCCCGAATTTGTTATGGCCCATAATACAGCCATATCTACGTTCATTAATTATCCTCACTTGGGAAAGACTGAGCCCAATCGAAGCAGATCATATATTAAGTTAAAAAGACTACGTTATAAAGGAACAGTGAAGATAGAACGTGTTCATGCCGATGTGAATATGGACGTTTTAACCCCCAAAATTGAAGGTGTTTTCTCTTTGGTTATTGTGGTTGATCGTAAACCACATTTGACTGCAAGTGGTTGTCTGCTTACATTTGATGAATTATTTGGAGCACGAATTCATAGTCATGGAAACTTGGCTATTAGTCCCTGTTGGAAGGACCGTTTTTATATACGGAATGTGTTTAAGCGTGTGTTATCCGTGGAGAAGGACACCACGATGATCGATGTTGAAGGTTCAACCACTCTTTCAAATAGGCGTTTTAATTTATGGTCTACTTTTAAGGATATTGATCATGATTCATGTAACGGTGTTTATGCTAACATTAGTAAGAACGCCCTTCTAGTTTATTATTGTTGGATGTCAGATGCTATGTCTAAAGCATCCTCATTTGTGTCGTTTGACCTTGATTATGTTGGTTAA |
|
Protein Sequence
|
MYFSRNRRGSFYSQRRGYGRNYLPKRSVGVKRNDSKRRYGQLGKVCDDSKMFNQRIHENQFGPEFVMAHNTAISTFINYPHLGKTEPNRSRSYIKLKRLRYKGTVKIERVHADVNMDVLTPKIEGVFSLVIVVDRKPHLTASGCLLTFDELFGARIHSHGNLAISPCWKDRFYIRNVFKRVLSVEKDTTMIDVEGSTTLSNRRFNLWSTFKDIDHDSCNGVYANISKNALLVYYCWMSDAMSKASSFVSFDLDYVG |
|
NCBI Accession
|
YP_009508012.1
|
|
Location
|
1187-2068 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTACCAAGTGCTCCCGATGCATTTAATTATATTGAGTCTCACAGAGATGAATATCAGCTTTCTCATGATCTAACAGAAATTGTCCTGCAATTTCCTTCTACAGCGTCTCAATTGTCAGCAAGACTCAGTCGTAGCTGTATGAAAATAGACCACTGCGTCATAGAATATAGACAACAGGTACCTATTAACGCAACAGGTTCCGTAATAGTGGAGATTCATGACAGAAGAATGACGGACAACGAATCATTACAAGCATCCTGGACGTTTCCAATCAGATGCAACATAGATCTCCACTATTTTTCTTCGTCTTTCTTCTCACTGAAAGACCCCATACCATGGAAACTGTATTATCGAGTGTCTGATACAAACGTCCACCAAAGGACACATTTCGCAAAATTCAAAGGAAAACTAAAATTATCCACGGCGAAGCACTCAGTGGATATACCGTTCAGAGCCCCAACCGTAAAAATCCTTTCCAAACAGTTTTCTAACAGAGATGTGGATTTCTCACACGTGGACTATGGAAAATGGGAAAGAAAGACGATAAGGTCCGCATCATTATCAAGATATGGACTACAAGGCCCAATTGAATTAAAACCGGGCGAATCTTGGGCCAGTAAAAGCACAATTGGATTGAGCCATACAGATGCGGACTCAGATATAGAGAACGCAATACACCCATACAGACAACTAAACAGGCTTGGAACAAGCGTATTAGACCCAGGAGACTCGGCTTCGATTGTAGGATCCCAGAGAACACAGTCCAACATAACAATGTCCATAGCTCAATTAAACGAGATAGTTCGGACAACAGTGCACGAATGTATAAACAGCAATTGTAATCCGACGCAACCGAAATCATTACAATAA |
|
Protein Sequence
|
MDSQLPSAPDAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLSARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDRRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSNRDVDFSHVDYGKWERKTIRSASLSRYGLQGPIELKPGESWASKSTIGLSHTDADSDIENAIHPYRQLNRLGTSVLDPGDSASIVGSQRTQSNITMSIAQLNEIVRTTVHECINSNCNPTQPKSLQ |