Ramie mosaic Yunnan virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001698395.1 |
| Isolate |
China |
| Release date |
2016/8/3 |
| Submitter |
Zhao,L.L., Zhong,J., Zhang,X.Y., Yin,Y.Y., Zhang,Z.K., Ding,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
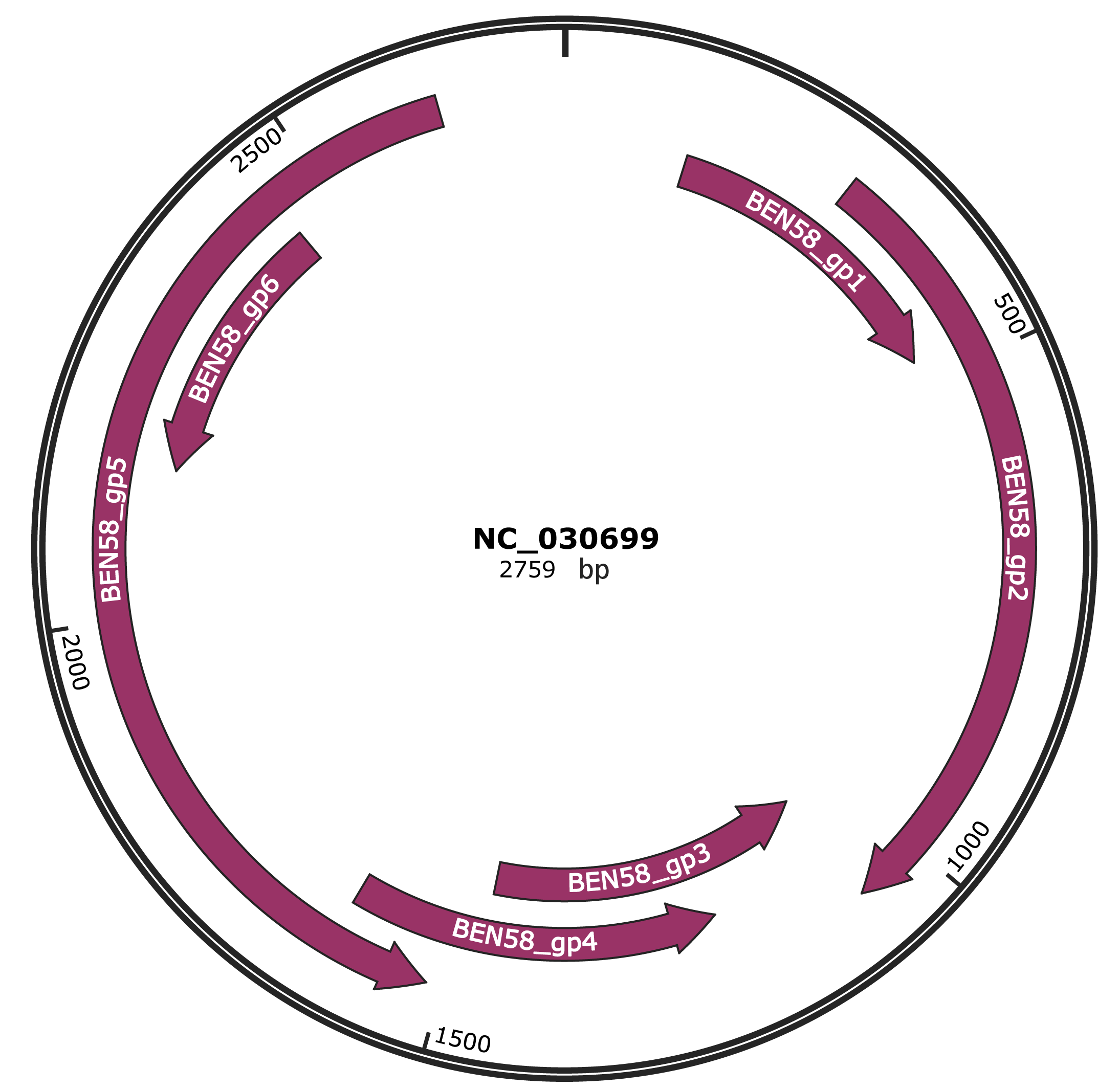
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTAAAGTGGGCCCCCCCACGTGGTGCTACGCTCCACTCAAAACGCTCCCTTAAAGCTTATTTAGTGCGTGTACCTCTATAAAGAACTTGCTAGGCAAGTTCCACATGCAAAGATGTGGGATCCGTTAGTCAATGAATTCCCCGAGACTGTTCACGGTCTACGGTGTATGTTGGCTATAAAATATCTACAGTTACTCGAGAATACGTACGCCCCGGATACGGTGGGATACGATCTTATACGTGACTTGATCCTTGTCATACGAGCTCGTAACTATGTCGAAGCGTCCCGCCGATATAGTCATTTCAACTCCCGCATCCAAGGTACGACGTCGGTTGAACTTCGACAGCCCAGTCTCCAGTCGTGCAACTGCCCCCACTGTCCTCGTCACAAACAGAAAGCGGTCATGGACTTACAGGCCCATGTACCGGAAGCCCAAGATATACAGAATGTATAGAAGTCCAGATATTCCTCGTGGGTGTGAAGGCCCATGTAAGGTCCAGTCATTTGAACAGCGTCATGATATAGCCCATACTGGTAAAGTTCTGTGCATTTCAGATGTTACCCGTGGTGGTGGGCTGACTCATCGCACGGGCAAGAGGTTTTGTGTGAAGTCCGTTTATGTTTTGGGGAAGGTCTGGATGGATGAGAATATTAAGGTTAAAAATCATACAAATACAGTTATGTTTTTTGTTGTTCGTGATAGAAGGCCTTATGGAACCCCTCAGGATTTTGGTCAGGTGTTTAACATGTATGATAATGAGCCTAGTACTGCAACTGTGAAGAACGATCTTAGGGATCGTTTTCAAGTGATCCGTCGTTTTAATTCAACTGTGACTGGCGGTCAATATGCGTCTAAGGAACAGGCTTTGGTTAAGAAGTACATGAAGGTCAATAATCATGTAGTTTATAATCATCAGGAAGCTGCGAAGTATGAGAACCATACGGAAAATGCTTTGTTATTGTATATGGCCTGTACACATGCCAGTAATCCTGTGTATGCAACCTTGAAAATCAGGATCTATTTTTATGATTCTGTTGCGAATTAATAAATATTATATTTTATTATATGAGTCAATTGAACATCAATTGTCCCTTCAAATACATCGTACATAACATTTGAAATTGCTCTAATTACATTATTCAAACTAATAATCCCCACGTTGTCTAAATATTTCATACATTGATATTTAAATACTCTTAAGAAACGCCCAGTCTGAGGTTGTAAACGAGTCCAGATTCGGCAGATCAGAAAACATTGGTGTATCCCCAATGCTTTCCTCAGGTTGTAATTGAACTGGACTTGGAGAGTGATGATGTCGAAGTTGTTCAGGAACGGTCTCACGTCGTGTTTCGTGATCTTGAAATACAGGGGATTCGGCACCTGCCAGATATACACGCCATTCTCGGCTTGAATTGCAGTGATGTACTCCCCTGTGCGTGAATCCATGTGATGCGCAGTTGATACTGATGTAGTATGTGCACCCGCAAGGTAAATCAACCCTCCGTCTGCGGATGGATTTCTTCTTGGCTATTCTGTGCTGAACCTTGATTGGCACCTGAGTACAGTGGCTCGGTAAGGGTGAAGAATTCTGCATTTTTCAGAGCCCACTCTTTTAAAGCTGAGTGCTTGTCCTCGTCCAAGTACTCTTTATATGATGATGTTGGCCCTGGATTGCATAGGAAGATAGTGGGAATACCTCCTTTAATTTGAATTGGTTTCCCGTATTTTGTGTTGCTCTGCCAGTCTCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGATAATGCGGGTCTACGTCATCAACCACGTTATACCACGCATCATTGCTGTATACCTTTGGACTCAAATCTAGGTGTCCACATAGGTAATTATGGGGCCCTAATGACCTGGCCCACATGGTCTTCCCTGTCCGACTCTCACCCTCTATGACAATACTCATGGGTCTCCAAGGCCGCGCAGCGGCAACCCTTACATTTTCAGAAACCCAACACTCTAGTTGTTCTGGAACTTGATTAAAAGAAGATGAAAGAAAAGGACATTTAAATACCTCTAATGGAGGTGCAAAAATTCTATCTAAATTGGCATTTAAATTATGAAACTGTAAAACATAATCCTTTGGAGCTAATTCCTTAATCACATTAAGAGCGTCTGACTTACTTCCGCTGTTAATCGCCTTGGCGTAAGCGTCATTTGCGGATTGTTGACCCCCTCGTGCAGATCGTCCGTCGATCTGAAACTCTCCCCATTCGAGGGTGTCTCCGTCCTTATCCAAATATGACTTAACGTCGGAACTTGACTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGCTTGGGGAGACCAGGTCGAAGAATCTGTTATTTGTGCATTGGTATTTGCCTTCGAATTGCACAAGCACATGGAGATGAGGACTCCCATCTGCATGCAATTCTCGACAGATCTTAATGAATAATTTATTCACTGGTGTAGCTAGGTTTTTTAATTGGGAAAGTGCTTCCTCTTTTGTGAGAGAGCATTTGGGATATGTTATGAAGTAATTTTTGGCATTTATTCTAAAACGACGTGGGACTGGCATTTTGAGAGTCGTTTTGATTCGGGGTTCAACCATCTATCGCATATAATCGGTGTAATGGGGGTCAATATATACTTGTACACCTAATGGCAATATCGTAAATATTAAAAGTTACTATAGAAATTCAAAATTCGAAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009269401.1
|
|
Location
|
134-475 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCGTTAGTCAATGAATTCCCCGAGACTGTTCACGGTCTACGGTGTATGTTGGCTATAAAATATCTACAGTTACTCGAGAATACGTACGCCCCGGATACGGTGGGATACGATCTTATACGTGACTTGATCCTTGTCATACGAGCTCGTAACTATGTCGAAGCGTCCCGCCGATATAGTCATTTCAACTCCCGCATCCAAGGTACGACGTCGGTTGAACTTCGACAGCCCAGTCTCCAGTCGTGCAACTGCCCCCACTGTCCTCGTCACAAACAGAAAGCGGTCATGGACTTACAGGCCCATGTACCGGAAGCCCAAGATATACAGAATGTATAG |
|
Protein Sequence
|
MWDPLVNEFPETVHGLRCMLAIKYLQLLENTYAPDTVGYDLIRDLILVIRARNYVEASRRYSHFNSRIQGTTSVELRQPSLQSCNCPHCPRHKQKAVMDLQAHVPEAQDIQNV |
|
NCBI Accession
|
YP_009269402.1
|
|
Location
|
294-1067 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGCCGATATAGTCATTTCAACTCCCGCATCCAAGGTACGACGTCGGTTGAACTTCGACAGCCCAGTCTCCAGTCGTGCAACTGCCCCCACTGTCCTCGTCACAAACAGAAAGCGGTCATGGACTTACAGGCCCATGTACCGGAAGCCCAAGATATACAGAATGTATAGAAGTCCAGATATTCCTCGTGGGTGTGAAGGCCCATGTAAGGTCCAGTCATTTGAACAGCGTCATGATATAGCCCATACTGGTAAAGTTCTGTGCATTTCAGATGTTACCCGTGGTGGTGGGCTGACTCATCGCACGGGCAAGAGGTTTTGTGTGAAGTCCGTTTATGTTTTGGGGAAGGTCTGGATGGATGAGAATATTAAGGTTAAAAATCATACAAATACAGTTATGTTTTTTGTTGTTCGTGATAGAAGGCCTTATGGAACCCCTCAGGATTTTGGTCAGGTGTTTAACATGTATGATAATGAGCCTAGTACTGCAACTGTGAAGAACGATCTTAGGGATCGTTTTCAAGTGATCCGTCGTTTTAATTCAACTGTGACTGGCGGTCAATATGCGTCTAAGGAACAGGCTTTGGTTAAGAAGTACATGAAGGTCAATAATCATGTAGTTTATAATCATCAGGAAGCTGCGAAGTATGAGAACCATACGGAAAATGCTTTGTTATTGTATATGGCCTGTACACATGCCAGTAATCCTGTGTATGCAACCTTGAAAATCAGGATCTATTTTTATGATTCTGTTGCGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPVSSRATAPTVLVTNRKRSWTYRPMYRKPKIYRMYRSPDIPRGCEGPCKVQSFEQRHDIAHTGKVLCISDVTRGGGLTHRTGKRFCVKSVYVLGKVWMDENIKVKNHTNTVMFFVVRDRRPYGTPQDFGQVFNMYDNEPSTATVKNDLRDRFQVIRRFNSTVTGGQYASKEQALVKKYMKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVAN |
|
NCBI Accession
|
YP_009269403.1
|
|
Location
|
1064-1468 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTACATCACTGCAATTCAAGCCGAGAATGGCGTGTATATCTGGCAGGTGCCGAATCCCCTGTATTTCAAGATCACGAAACACGACGTGAGACCGTTCCTGAACAACTTCGACATCATCACTCTCCAAGTCCAGTTCAATTACAACCTGAGGAAAGCATTGGGGATACACCAATGTTTTCTGATCTGCCGAATCTGGACTCGTTTACAACCTCAGACTGGGCGTTTCTTAAGAGTATTTAAATATCAATGTATGAAATATTTAGACAACGTGGGGATTATTAGTTTGAATAATGTAATTAGAGCAATTTCAAATGTTATGTACGATGTATTTGAAGGGACAATTGATGTTCAATTGACTCATATAATAAAATATAATATTTATTAA |
|
Protein Sequence
|
MDSRTGEYITAIQAENGVYIWQVPNPLYFKITKHDVRPFLNNFDIITLQVQFNYNLRKALGIHQCFLICRIWTRLQPQTGRFLRVFKYQCMKYLDNVGIISLNNVIRAISNVMYDVFEGTIDVQLTHIIKYNIY |
|
NCBI Accession
|
YP_009269404.1
|
|
Location
|
1209-1616 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCAGAATTCTTCACCCTTACCGAGCCACTGTACTCAGGTGCCAATCAAGGTTCAGCACAGAATAGCCAAGAAGAAATCCATCCGCAGACGGAGGGTTGATTTACCTTGCGGGTGCACATACTACATCAGTATCAACTGCGCATCACATGGATTCACGCACAGGGGAGTACATCACTGCAATTCAAGCCGAGAATGGCGTGTATATCTGGCAGGTGCCGAATCCCCTGTATTTCAAGATCACGAAACACGACGTGAGACCGTTCCTGAACAACTTCGACATCATCACTCTCCAAGTCCAGTTCAATTACAACCTGAGGAAAGCATTGGGGATACACCAATGTTTTCTGATCTGCCGAATCTGGACTCGTTTACAACCTCAGACTGGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSPLPSHCTQVPIKVQHRIAKKKSIRRRRVDLPCGCTYYISINCASHGFTHRGVHHCNSSREWRVYLAGAESPVFQDHETRRETVPEQLRHHHSPSPVQLQPEESIGDTPMFSDLPNLDSFTTSDWAFLKSI |
|
NCBI Accession
|
YP_009269405.1
|
|
Location
|
1516-2637 |
|
Protein Name
|
Rep protein |
|
Coding Region
|
ATGGTTGAACCCCGAATCAAAACGACTCTCAAAATGCCAGTCCCACGTCGTTTTAGAATAAATGCCAAAAATTACTTCATAACATATCCCAAATGCTCTCTCACAAAAGAGGAAGCACTTTCCCAATTAAAAAACCTAGCTACACCAGTGAATAAATTATTCATTAAGATCTGTCGAGAATTGCATGCAGATGGGAGTCCTCATCTCCATGTGCTTGTGCAATTCGAAGGCAAATACCAATGCACAAATAACAGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAGTCAAGTTCCGACGTTAAGTCATATTTGGATAAGGACGGAGACACCCTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCACGAGGGGGTCAACAATCCGCAAATGACGCTTACGCCAAGGCGATTAACAGCGGAAGTAAGTCAGACGCTCTTAATGTGATTAAGGAATTAGCTCCAAAGGATTATGTTTTACAGTTTCATAATTTAAATGCCAATTTAGATAGAATTTTTGCACCTCCATTAGAGGTATTTAAATGTCCTTTTCTTTCATCTTCTTTTAATCAAGTTCCAGAACAACTAGAGTGTTGGGTTTCTGAAAATGTAAGGGTTGCCGCTGCGCGGCCTTGGAGACCCATGAGTATTGTCATAGAGGGTGAGAGTCGGACAGGGAAGACCATGTGGGCCAGGTCATTAGGGCCCCATAATTACCTATGTGGACACCTAGATTTGAGTCCAAAGGTATACAGCAATGATGCGTGGTATAACGTGGTTGATGACGTAGACCCGCATTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGAGACTGGCAGAGCAACACAAAATACGGGAAACCAATTCAAATTAAAGGAGGTATTCCCACTATCTTCCTATGCAATCCAGGGCCAACATCATCATATAAAGAGTACTTGGACGAGGACAAGCACTCAGCTTTAAAAGAGTGGGCTCTGAAAAATGCAGAATTCTTCACCCTTACCGAGCCACTGTACTCAGGTGCCAATCAAGGTTCAGCACAGAATAGCCAAGAAGAAATCCATCCGCAGACGGAGGGTTGA |
|
Protein Sequence
|
MVEPRIKTTLKMPVPRRFRINAKNYFITYPKCSLTKEEALSQLKNLATPVNKLFIKICRELHADGSPHLHVLVQFEGKYQCTNNRFFDLVSPSRSTHFHPNIQGAKSSSDVKSYLDKDGDTLEWGEFQIDGRSARGGQQSANDAYAKAINSGSKSDALNVIKELAPKDYVLQFHNLNANLDRIFAPPLEVFKCPFLSSSFNQVPEQLECWVSENVRVAAARPWRPMSIVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVVDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKHSALKEWALKNAEFFTLTEPLYSGANQGSAQNSQEEIHPQTEG |
|
NCBI Accession
|
YP_009269406.1
|
|
Location
|
2157-2453 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGCAGATGGGAGTCCTCATCTCCATGTGCTTGTGCAATTCGAAGGCAAATACCAATGCACAAATAACAGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAGTCAAGTTCCGACGTTAAGTCATATTTGGATAAGGACGGAGACACCCTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCACGAGGGGGTCAACAATCCGCAAATGACGCTTACGCCAAGGCGATTAACAGCGGAAGTAAGTCAGACGCTCTTAATGTGA |
|
Protein Sequence
|
MQMGVLISMCLCNSKANTNAQITDSSTWSPQAGQHISIRTFRELSQVPTLSHIWIRTETPSNGESFRSTDDLHEGVNNPQMTLTPRRLTAEVSQTLLM |