Potato yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000838665.1 |
| Release date |
2015/2/12 |
| Submitter |
Fontes,E.P., Eagle,P.A., Sipe,P.S., Luckow,V.A., Hanley-Bowdoin,L., Coutts,R.H., Coffin,R.S., Roberts,E.J., Hamilton,W.D., Gladfelter,H.J., Schaffer,R.L., Petty,I.T. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
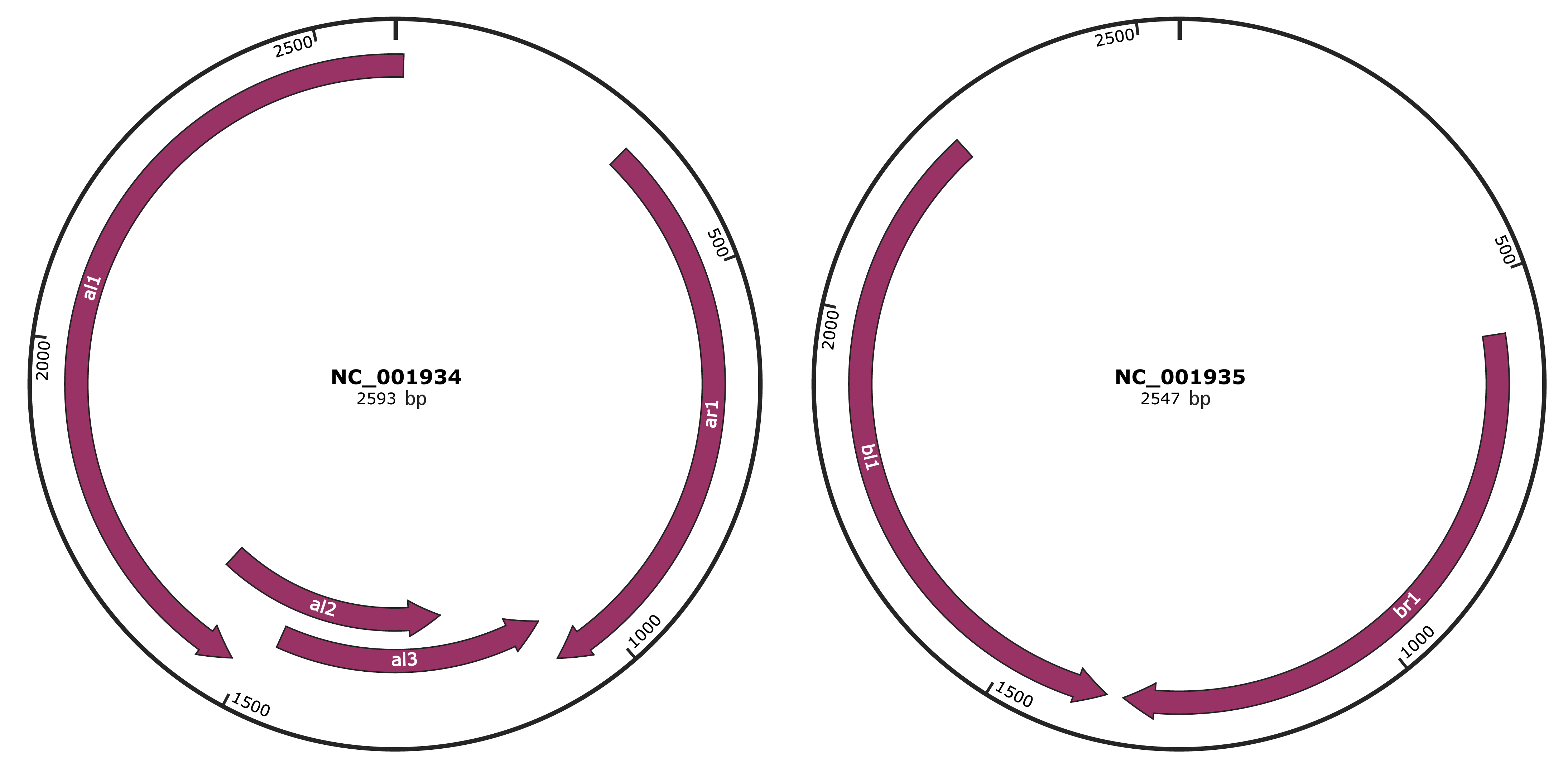
JBrowse
Genome
TTTCGTGGCATTTTTGTAAATATGAATGTTCTCCCAATATGTTCCCCCTATTGCTCTGGCTCTCAAAACTCTTATGAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCTAAAGGCAGATCAACACGTGCGGCCATCCGTTATAATATTACCGGATGGCCGCGTTTTTTTTTTAATGGGCCTTATTTGTAATGGGCTTTAATTTGGCCCAATCAACGTTAGTCTGACACACCTAGATAAGTGGAATTACTTTGTCGCTAAGTTGTGATTTTGTCTATAAATTAAAGCCTCTTGGCCCACTATCTTTAACTCAAAATGCCTAAGCGCGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTACTCTCCTCGTTCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAATAGGCCCATGTACCGGAAGCCCAGGATCTATCGGACGCTGAGGACGCCTGATGTTCCTAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCTTTCGAGCAGCGACACGATATCTTACACACTGGCAAGGTAATGTGCATATCTGACGTTACTCGCGGTAACGGTATTACTCACCGTGTCGGGAAGCGGTTCTGTGTTAAGTCCGTTTACATATTAGGTAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACCGCCACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCATGCTATTGTGAGGCGTTTCTGGAAGGTCAACAACCACGTTGTTTACAACCACCAGGAAGCTGGCAAATACGAGAATCATACTGAGAACGCCCTATTATTGTACATGGCATGTACTCATGCCTCAAATCCTGTATATGCAACACTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAATAAAATTTATATTTTATTGAATGATTTTCCAGTACATAATTTACATATGATCTATCTGTTGCAAAACGAACAGATCTAATTACATTGTTAATTGAAATGACACCTAACCGGTCTAAGTACAGAAGAACTAATTGTCTAAATCTAGCTAAATAATTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTATGCTTTGTGGAGATCCAATGCTCTCCTGAGGTTGTGGTTGAACCGGATTTGGACGCTGTATATCCTGGTCCTGGTGTATTGCATGTCCTCTACTTGGTTTATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATAAACACGCCATTCTCTGCCTGACGTGCAGTGATGAGCTCCCCTGTGCGTGAATCCATGTCCTGCGCAGTCTATGTGGAAGTATATGGAGCAACCGCAGTCTAAGTCAATGCGTCTCCTCCTGATTGCCCTCTTCTTTGCTTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGATGGTGATGAAGACCGCATTCTTTAGAGTCCAGTTTTTGAGAGACGCATTTTCGTCTTTGTCGAGGAAAGCTTTATAGCTGGAACCCTCACCAGGATTGCAGAGCACGATTGATGGGATACCGCCTTTAATTTGAACAGGCTTTCCGTACTTACAATTTGATTGCCAATCCCTTTGGGCCCCAAGCAGTTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCATTCGAATAGACCCTGGGATTGAAATCAAGATGACCGCTCAAGTAATTATGTGGGCCTAAGACTCGCGCCCACATCGTCTTGCCTCTTCGAGAATCACCTTCAATTATAATACTAATAGGTCTTTCTGGGCGCGCCGCACTACTCTTTCCGAAATAACCATCTGCCCACTCTTGCATCTCGTCGGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGCCCATGTCTCTGGAGCCTTCATGAAAATCCTATCGAGGTTACAGGATAGGTTATGATACTGAAAAAGAAACTTTTCCGGCAACTTCTCTTTAATGATTTTCATGGCTGCTTCCTTTGTTCCAGAGTTTAGTGCCTCGGCAGCTGCGTCGTTAACTGTCTGCTGGCCCCCTCGAGCACTTCTTCCGTCAATCTGGAACAAACCCCATTCGATGGTGTCTCCGTCTTTCTCGACATACGACTTGACATCGGAGCTCGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGGTTGGGGACACCAGATCGAACAGTCTGTTATTTGTGCAGTTGTATTTGCCTTCGAACTGGATAAGAACGTGGAGATGAGGTTCCCCATTCTCGTGAAGTTCTCTGCAAATCTTGATGAATTTCTTGTTGACTGGGATAGTTAGGTTTTGAAGTTGGGAAAGTGCTTCTTCTTTGCTAATAGAGCATTGAGGATACGTAAGGAAATAATTTTTGGCTTTAATAGAGAACGAACCC
TTTCGGGGCATTTTGATAAATATTAGTGTTCCCCCGATATGTTCCCCCAATTGCTCTGGCCCTCAAAACTCTTATGAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCTAAAGGCAGATCAACACGTGCGGCCATCCGTTATAATATTACCGGATGGCCGCGAGATTTTTTATACTGGGCTTTCTACTAAGGCCCAAGTATGATTGGACTCTAGGCCCATTTTTTAGCGGTCCCTCTTTTTCCTCGTCCTTTCTCTGCTGTTTCCTTTTACTTTAATTTAAATCACTCTTAAATTAAATATGTTGTGATCAATTTCAACAGCTGTCCCGCATAATATATGTACTGACGACGTGGGTAATTCTCGACCAAGTTACAGTGTTAAGTCGAAATTGATTTTAACGTCTCTCCATTTATGAGCTCATGGTCCTATTAAGCATTACATTACACGTGTACCATTTAAATTGATCGTGTGGAGTCAATTTAATTAATTGTATAACCTGATATGTCTATATATTCGCTGACTAGGAATGAGCTCATTATTACGTGGTACAAAGACATTACATGATAATGTATCCTAATAGGCACAGGCGTGCTTCTTTTTGTAGCCAGCCACGTACTTACCCACGTAATAGTTTGATTAGACAGCAGTCATTATTCAAGCGTAATGTTAGCAAACGACGACCATTTCAAACCGTGAAGATGGTTGATGACTCCATGATGAAGGCACAACGTATTCATGAGAATCAATACGGTCCAGATTTTTCACTGGCCCATAATACAGCCGTCTCTACATTTATAAGTTACCCTGATATTGCTAAGTCTCTGCCCAATAGAACCAGGTCATATATTAAGCTAAAACGACTTCGGTTCAAGGGTATTGTGAAGGTGGAACGTGTACATGTAGAGGTTAACATGGACTGTTCTGTGCCTAAGACCGAAGGAGTTTTCTCTTTGGTTATTGTAGTGGATCGTAAACCTCACCTTGGACCCTCTGGGGGACTGCCTACATTTGACGAGCTATTTGGCGCTAGGATCCACAGTCATGGTAACTTGGCAATAGTTCCATCTCTGAAGGATCGGTTCTACATACGCCATGTACTGAAGCGTGTGATATCAGTCGAGAAGGACACCATGATGGTGGACATAGAAGGTGTTGTAGCCCTTTCTAGCAGACGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGACATAGAGTCCCGAAAGGGTGTTTATGATAACATTAATAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATACAGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGATTATATTGGATGATTGTATTCACTAATACAAATTTTATTTAAAATTTTTTGGCTGAGAACTATTACAATTACTCTTTATACATTCTTGGACAGTTGTCCTTACAAGTTCATTTAACTGGGCTACGGACATGGTTATGTTCGATTGGGCCATGTTAGCACCAACTATAGATGCTGACTCTCCTGGATCTAGGACGCTGGCTCCTAGTCTTTGCAAATCTCGATACGTATGTAGCTCGTTCTCTATCTCTGACTCGCCCTCTGATTGACCCACTCCTATTGTACTCCTGGAAGCCCATGATTCACCAGGCCTTATTTCAATTGGGCCTCTGAGCCCAACTCTGGACATTGATGCGCATCTAATGGGCTTCCTCTCCCATCTCCCGTAGTCGACGTGCGAGAAATCCACGTCCTTATCTGTGAACTGTTTGGACAGGATCTTGACCGTTGGTGCTCTGAACGGAATGTCTACGGAATGTTTCGCCGTCGACAGTTTCAGCTTCCCTTTGAACTTGGCAAAGTGTGTCCGTTGATGAACGTTCGTGTCGGAAACTCTGTAATAGAGTTTCCATGGGATAGGATCTTTTAGGGAGAAAAAGGAAGCTGAGAAATAGTGGAGATCTATGTTGCATCTTAACGGGAACGTCCATGACGCCTGCAGAGATTCGTTGTCTGTCATCCTCTTATCATGAATCTCCACTATTACAGACCCGGTGGCGTTGATGGGTACCTGTTGCCTGTACTCAATTACGCAGTGGTCTATCTTCATACAGCTGCGACTGAGCCTCGCCGTTAACTGCGCCGCCGTCGACGGAAATTGCAGTATTATCTCAGTTAGGTCATGCGAAAGCTGATATTCATCCCGTTGAGACTCTATGTAATTGAAAGCATGAGGAGGATTAACTAACTGAGAATTCATTTATTGAAAATTAGGCCGCGCAGCGGCACCGCTTCCAGAATATGAACAGGAAAAGAGGATGATAGGGTTTCTCGAACAGGCAAGACGATGATCTTGAAGAGAAGACAGAGAAATATAATAGTGCTATGGAAGACTCTGAATATGTTAATGTTCAAGGATTAGGTAGTTTATATAAAGAAGTTGTTACTGCTGAGGTACCAATTAAGAAATTTGAAGTTGGGAAAGTGCATCTTCTTTGCTAAGATAGTATTGAGGATTCGTAAGGAAATAATTTTTGGCTTAAATAGAGAACGAGCCTT
Gene Information
|
NCBI Accession
|
NP_047237.1
|
|
Location
|
1519-2593,1-11 |
|
Gene Name
|
al1 |
|
Protein Name
|
AL1 protein |
|
Coding Region
|
ATGCCACGAAAGGGTTCGTTCTCTATTAAAGCCAAAAATTATTTCCTTACGTATCCTCAATGCTCTATTAGCAAAGAAGAAGCACTTTCCCAACTTCAAAACCTAACTATCCCAGTCAACAAGAAATTCATCAAGATTTGCAGAGAACTTCACGAGAATGGGGAACCTCATCTCCACGTTCTTATCCAGTTCGAAGGCAAATACAACTGCACAAATAACAGACTGTTCGATCTGGTGTCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCGAGCTCCGATGTCAAGTCGTATGTCGAGAAAGACGGAGACACCATCGAATGGGGTTTGTTCCAGATTGACGGAAGAAGTGCTCGAGGGGGCCAGCAGACAGTTAACGACGCAGCTGCCGAGGCACTAAACTCTGGAACAAAGGAAGCAGCCATGAAAATCATTAAAGAGAAGTTGCCGGAAAAGTTTCTTTTTCAGTATCATAACCTATCCTGTAACCTCGATAGGATTTTCATGAAGGCTCCAGAGACATGGGCTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCAGATGGTTATTTCGGAAAGAGTAGTGCGGCGCGCCCAGAAAGACCTATTAGTATTATAATTGAAGGTGATTCTCGAAGAGGCAAGACGATGTGGGCGCGAGTCTTAGGCCCACATAATTACTTGAGCGGTCATCTTGATTTCAATCCCAGGGTCTATTCGAATGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTGCTTGGGGCCCAAAGGGATTGGCAATCAAATTGTAAGTACGGAAAGCCTGTTCAAATTAAAGGCGGTATCCCATCAATCGTGCTCTGCAATCCTGGTGAGGGTTCCAGCTATAAAGCTTTCCTCGACAAAGACGAAAATGCGTCTCTCAAAAACTGGACTCTAAAGAATGCGGTCTTCATCACCATCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCAAAGAAGAGGGCAATCAGGAGGAGACGCATTGA |
|
Protein Sequence
|
MPRKGSFSIKAKNYFLTYPQCSISKEEALSQLQNLTIPVNKKFIKICRELHENGEPHLHVLIQFEGKYNCTNNRLFDLVSPTRSTHFHPNIQGAKSSSDVKSYVEKDGDTIEWGLFQIDGRSARGGQQTVNDAAAEALNSGTKEAAMKIIKEKLPEKFLFQYHNLSCNLDRIFMKAPETWAPPFPLSSFTNVPDEMQEWADGYFGKSSAARPERPISIIIEGDSRRGKTMWARVLGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKAFLDKDENASLKNWTLKNAVFITITAPLYQEGTQASKEEGNQEETH |
|
NCBI Accession
|
NP_047238.1
|
|
Location
|
321-1076 |
|
Gene Name
|
ar1 |
|
Protein Name
|
AR1 protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTACTCTCCTCGTTCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAATAGGCCCATGTACCGGAAGCCCAGGATCTATCGGACGCTGAGGACGCCTGATGTTCCTAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCTTTCGAGCAGCGACACGATATCTTACACACTGGCAAGGTAATGTGCATATCTGACGTTACTCGCGGTAACGGTATTACTCACCGTGTCGGGAAGCGGTTCTGTGTTAAGTCCGTTTACATATTAGGTAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACCGCCACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCATGCTATTGTGAGGCGTTTCTGGAAGGTCAACAACCACGTTGTTTACAACCACCAGGAAGCTGGCAAATACGAGAATCATACTGAGAACGCCCTATTATTGTACATGGCATGTACTCATGCCTCAAATCCTGTATATGCAACACTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRSGIGPRINKAAEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSFEQRHDILHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEHAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
NP_047239.1
|
|
Location
|
1073-1471 |
|
Gene Name
|
al3 |
|
Protein Name
|
AL3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATAAACCAAGTAGAGGACATGCAATACACCAGGACCAGGATATACAGCGTCCAAATCCGGTTCAACCACAACCTCAGGAGAGCATTGGATCTCCACAAAGCATACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAGATTTAGACAATTAGTTCTTCTGTACTTAGACCGGTTAGGTGTCATTTCAATTAACAATGTAATTAGATCTGTTCGTTTTGCAACAGATAGATCATATGTAAATTATGTACTGGAAAATCATTCAATAAAATATAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVFIWEIENPLYFKINQVEDMQYTRTRIYSVQIRFNHNLRRALDLHKAYLNFQVWTTSMTASGSNYLARFRQLVLLYLDRLGVISINNVIRSVRFATDRSYVNYVLENHSIKYKFY |
|
NCBI Accession
|
NP_047240.1
|
|
Location
|
1218-1607 |
|
Gene Name
|
al2 |
|
Protein Name
|
AL2 protein |
|
Coding Region
|
ATGCGGTCTTCATCACCATCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCAAAGAAGAGGGCAATCAGGAGGAGACGCATTGACTTAGACTGCGGTTGCTCCATATACTTCCACATAGACTGCGCAGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATAAACCAAGTAGAGGACATGCAATACACCAGGACCAGGATATACAGCGTCCAAATCCGGTTCAACCACAACCTCAGGAGAGCATTGGATCTCCACAAAGCATACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKKAHRQAKKRAIRRRRIDLDCGCSIYFHIDCAGHGFTHRGAHHCTSGREWRVYLGDRKSPLFQDKPSRGHAIHQDQDIQRPNPVQPQPQESIGSPQSIPELPSLDDIDDSFWVELFS |
|
NCBI Accession
|
NP_047241.1
|
|
Location
|
575-1345 |
|
Gene Name
|
br1 |
|
Protein Name
|
BR1 protein |
|
Coding Region
|
ATGTATCCTAATAGGCACAGGCGTGCTTCTTTTTGTAGCCAGCCACGTACTTACCCACGTAATAGTTTGATTAGACAGCAGTCATTATTCAAGCGTAATGTTAGCAAACGACGACCATTTCAAACCGTGAAGATGGTTGATGACTCCATGATGAAGGCACAACGTATTCATGAGAATCAATACGGTCCAGATTTTTCACTGGCCCATAATACAGCCGTCTCTACATTTATAAGTTACCCTGATATTGCTAAGTCTCTGCCCAATAGAACCAGGTCATATATTAAGCTAAAACGACTTCGGTTCAAGGGTATTGTGAAGGTGGAACGTGTACATGTAGAGGTTAACATGGACTGTTCTGTGCCTAAGACCGAAGGAGTTTTCTCTTTGGTTATTGTAGTGGATCGTAAACCTCACCTTGGACCCTCTGGGGGACTGCCTACATTTGACGAGCTATTTGGCGCTAGGATCCACAGTCATGGTAACTTGGCAATAGTTCCATCTCTGAAGGATCGGTTCTACATACGCCATGTACTGAAGCGTGTGATATCAGTCGAGAAGGACACCATGATGGTGGACATAGAAGGTGTTGTAGCCCTTTCTAGCAGACGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGACATAGAGTCCCGAAAGGGTGTTTATGATAACATTAATAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATACAGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGATTATATTGGATGA |
|
Protein Sequence
|
MYPNRHRRASFCSQPRTYPRNSLIRQQSLFKRNVSKRRPFQTVKMVDDSMMKAQRIHENQYGPDFSLAHNTAVSTFISYPDIAKSLPNRTRSYIKLKRLRFKGIVKVERVHVEVNMDCSVPKTEGVFSLVIVVDRKPHLGPSGGLPTFDELFGARIHSHGNLAIVPSLKDRFYIRHVLKRVISVEKDTMMVDIEGVVALSSRRFNCWAGFKDLDIESRKGVYDNINKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
|
NCBI Accession
|
NP_047242.1
|
|
Location
|
1367-2248 |
|
Gene Name
|
bl1 |
|
Protein Name
|
BL1 protein |
|
Coding Region
|
ATGAATTCTCAGTTAGTTAATCCTCCTCATGCTTTCAATTACATAGAGTCTCAACGGGATGAATATCAGCTTTCGCATGACCTAACTGAGATAATACTGCAATTTCCGTCGACGGCGGCGCAGTTAACGGCGAGGCTCAGTCGCAGCTGTATGAAGATAGACCACTGCGTAATTGAGTACAGGCAACAGGTACCCATCAACGCCACCGGGTCTGTAATAGTGGAGATTCATGATAAGAGGATGACAGACAACGAATCTCTGCAGGCGTCATGGACGTTCCCGTTAAGATGCAACATAGATCTCCACTATTTCTCAGCTTCCTTTTTCTCCCTAAAAGATCCTATCCCATGGAAACTCTATTACAGAGTTTCCGACACGAACGTTCATCAACGGACACACTTTGCCAAGTTCAAAGGGAAGCTGAAACTGTCGACGGCGAAACATTCCGTAGACATTCCGTTCAGAGCACCAACGGTCAAGATCCTGTCCAAACAGTTCACAGATAAGGACGTGGATTTCTCGCACGTCGACTACGGGAGATGGGAGAGGAAGCCCATTAGATGCGCATCAATGTCCAGAGTTGGGCTCAGAGGCCCAATTGAAATAAGGCCTGGTGAATCATGGGCTTCCAGGAGTACAATAGGAGTGGGTCAATCAGAGGGCGAGTCAGAGATAGAGAACGAGCTACATACGTATCGAGATTTGCAAAGACTAGGAGCCAGCGTCCTAGATCCAGGAGAGTCAGCATCTATAGTTGGTGCTAACATGGCCCAATCGAACATAACCATGTCCGTAGCCCAGTTAAATGAACTTGTAAGGACAACTGTCCAAGAATGTATAAAGAGTAATTGTAATAGTTCTCAGCCAAAAAATTTTAAATAA |
|
Protein Sequence
|
MNSQLVNPPHAFNYIESQRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPLRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGVGQSEGESEIENELHTYRDLQRLGASVLDPGESASIVGANMAQSNITMSVAQLNELVRTTVQECIKSNCNSSQPKNFK |