Potato yellow mosaic Panama virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000839305.1 |
| Release date |
2015/2/12 |
| Submitter |
Engel,M., Fernandez,O., Jeske,H., Frischmuth,T. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
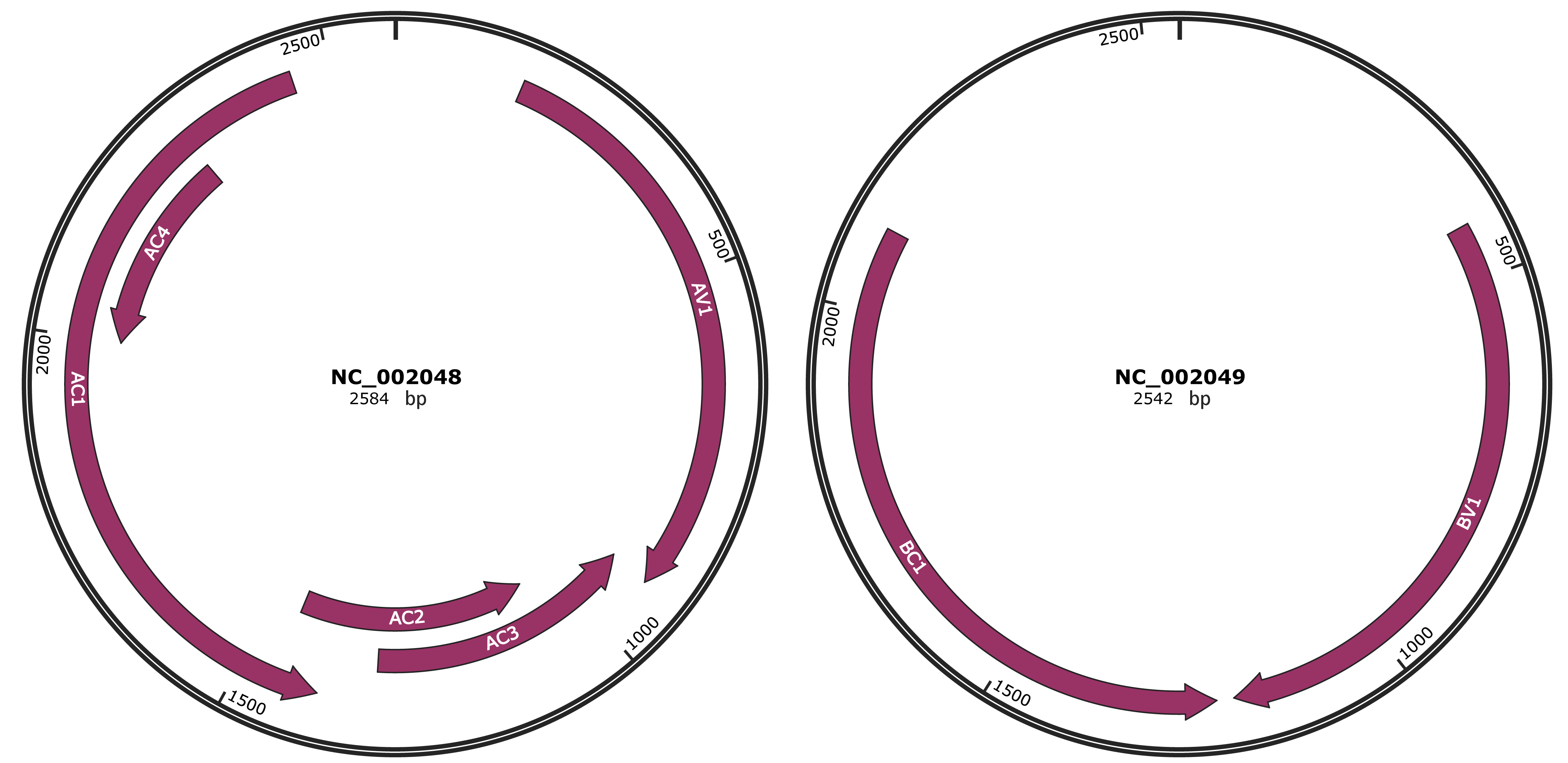
JBrowse
Genome
ACCGGATGGCCGCGCTTTTTTTCTTTTATGGGCTTTACTTGTATTGGGCTTTACTTTGGCCCAATCATAATCTGTCTGACAATCTTAGATAAGTGGAAATACTTTGGCGCTAAGTTGCTCTTTGTGTATAAATTAAAGCCTCTTGGCCCACTATCTTTAACTCAAAATGCCTAAGCGCGACGCTCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTATCGGAAGCCCAGGATCTATCGGACGTTGAGGACGCCTGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTCGAGCAGCGACATGACATCTTACACACTGGTAAGGTAATGTGTATATCTGACGTTACACGTGGTAACGGTATTACCCACCGTGTCGGTAAGCGGTTTTGTGTTAAGTCCGTTTACATATTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACTAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTACGGCAAGGTCACAGGTGGTCAGTATGCAAGCAACGAGCAGGCTATTGTGAGGCGGTTTTGGAAGGTCAACAATCACGTGGTCTACAACCACCAAGAAGCTGGCAAATATGAGAACCATACGGAGAACGCACTATTATTGTACATGGCATGTACTCATGCCTCAAACCCTGTATATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAATAAAATTTTAATTTTATTGAATGATTTTCCAGTACATGATTTACATATGATCGATCTGTTGCAAAACGAACAGCTCTAATTACATTGTTAATTGAAATAACACCTAACTGATCTAAGTACATAAGGACTAAATGTCTAAATCTAGCTAAATAATTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATCCAACGCTCTCCTGAGGTTGTGGTTGAATCTGATTTGGAGGTGGTACACCCTGGTTCTGGTGTATGATATGTGTTCTACTCGGTTTATCTTGAAATATAGGGGATTTTCTATCTCCCAGATAAACACGCCATTCTCTGCCTGACGTGCAGTGATGAGCTCCCCTGTGCGTGAATCCATGTCCTGCGCAGTCTATGTGGAAGTATATGGAGCAACCGCAGTCTAAATCAATGCGTCTCCTTCTGATGGCCCTCCTCTTAGCTTGCCTGTGTGCTTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGACAGCATTCTTTAGAGTCCAGTTTTTGAGAGACGCATTATCTTCTTTCTCGAGGAAAGCTTTATAGCTGGAACCCTCGCCAGGATTGCAGAGCACGATTGATGGGATCCCTCCTTTAATTTGAACAGGCTTTCCGTACTTGCAATTTGATTGCCAATCTTTTTGGGCCCCAATGAGTTCTTTCCAGTGCTTTAGCTTTAGATACTGCGGTGCGACGTCATCAATGACGTTATATTCCACTTCATTCGAATAGACCCTAGAATTGAAATCAAGATGACCGCTCAAGTAATTATGTGGGCCTAAGACCCGAGCCCACATCGTCTTCCCCGTTCGAGAGTCACCTTCAATGATAATACTAATAGGTCTTTCCCGGCGCGCAGCGGCACTCCTTCCAAAATAGTCATCAGCCCACCTTAGCATCTCGTCCGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGCCCATGGTTCCGGAGCATTTGCGAATATTCGTTCAAGATTCGAACGAATGTTATGATTTTGAAGGACAAAGTCCTTCGGTTGTTCTTCTCTCAATATATTGAGGGCCTCGGAGACCGTGCCTGAATTGAGGGCTTTGGCATATGAATCATTGGCAGTCTGGCAACCTCCTCTAGCTGATCGTCCATCGATCTGGAAAATTCCAAAATCAATGAAGTCTCCGTCTTTTTCCACATAGGTCTTGACGTCTGAAGACGATTTAGCTCTCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAAGTCGAAGAATCGTTGATTGGTGCACTGGTACTTTCCTTCGAACTGGATGAGAACGTGGAGATGAGGTTGCCCATCTTCGTGTAGTTCTCTTGAAACACGAATGAATTTCTTAGAAGTTGGGGTTTCTAGGTTTTGCAATTGGGAAAGGGCTTCTTCTTTTGTGAGCGAACACTGGGGATATGTGAGGAAATAATTCCTGGCATTTATACTAAAACGACCTGCCCGTGGCATTTTGGTAAATATGATAGTGTCCCCCGATTGAGCTCTCTCTAAAACTCTATATGAATCGGTGGAACGGTGGACAATATATAGTAGAAGTCTCATTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCTTTTTTTATACTGGGCTTTATATAGAGGCCCATTTGGAGTGGGTTTTTGGCCCATTTGGACTAACCACTCTCTTTCCTCGTATTTTCTCTGTGGTTTCTTTTAACTTTAATTTAAAATCACTTTTAAATTAAATATCTTTTTTTTTGTGTGGTCAATTTCGACAGCTGTTCTGCATAATATATATACTGACGACGTGGGTAATTTTCGACCAAGTTACAGTGTTTAAGTCGAAATTGTTTTTAACTGCTTTTGATTTAAGAGCTCATGGACCTATTGAGCTACATTGCACGTGTACCATTTAAATTGATCGTGTGGAGTCAAATTTTACATAATTGTATGAACTGACATGCATATATATTTGGCCGAAATAGGAAATGAGCTCATTATTACGTGGTATACAGACAATATTTGAAAATGTATCCTACGAAGTATAGGCGTGTGTCTTTGTCTAGCCAACCACGTAATTATTCACGTAATACTTCGATAAGACGTCAATCAGTTTTCAAGCGTAATGACAACAAGCATCGAACGTTTCCAACCGGTAAGACAACGGATGTTTCCATGATGAAGGCCCAACGGATTCATGAGAATCAATATGGTCCAGATTTTGCAATGGTTCATAATACAGCAGTGTCTACATTCATTAGCTACCCTGATGTGGCTAAGTCTATGCCTAACCGAAAGAGGTCATATATTAAGCTAAAACGACTTCGTTTCAAGGGTATAGTGAAAGTGGAACGTGTTCATGCAGAGGTGAACATGGACTGTTTAGCGCCTAAGACCGAAGGAGTTTTCTCTCTGGTTATTGTGATGGATCGAAAACCTCATCTTGGACCATCTGGGGGGCTGCCTACTTTCGATGAGCTGTTTGGCGCCAGGATCCACAGTCATGGTAACCTGGCAATAGTTCCTTCTTTTAAGGATCGTTTCTACATACGCCATGTATTGAAGCGGGTGATATCAGTGGACAAGGATACTATGATGGTGGACATCGAAGGCGTTACAACCCTTTCTAGCAGGCGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGATGTAGAGTCTCGAAAGGGTGTATATGATAATATTAATAAGAACGCCTTGTTAGTTTATTATTGTTGGATGTCGGATACTGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGACTATATTGGATGAGATATATATAATAATAAAAATTTTATTTTAAATTTTTGGGCTGAGAACTATTACACTGACTCTTTATACATTCTTGGACAGTTGTCCTTACAAGTTCATTTAACTGGGCTATAGACATGGTTATGTTGGACTGCGCCCTGTTTGCACCAACTATAGATGCGCTCTCTCCCGGATCTAGAACGCTGGCTCCTAGCCTTTGCAGATCTCGATACGGATGTAACTCGTTTTCTATCTCTGACTCCCCTTCTGAATGGACCCAACCTATAGTACTCCTGGAAGCCCATGATTCACCAGGCCTTAGATCAATTGGGCCTCTGAGCCCAACTCTCGACATTGATGCGCACCGTATGGGCTTCCTCTCCCATTTGCCATAGTCGACGTGAGAGAAATCTACATCTTTATCGGTGAATTGCTTGGACAGGATTTTCACCGTTGGCGCTCTGAACGGAATGTCCACGGAATGTTTAGCCGTCGACAGTTTCAGCTTCCCTTTGAACTTGGCAAAGTGTGTCCGCTGATGAACATTTGTATCTGAAACTCTGTAATAGAGTTTCCATGGGATGGGGTCTTTTAGGGAGAAAAAGGAAGCTGAAAAATAGTGGAGATCTATGTTGCATCTTATCGGGAATGTCCATGACGCCTGTAGTGATTCGTTGTCTGTCATCCTCTTGTCATGAATCTCCACTATTACAGAACCGGTGGCGTTGATGGGTACCTGTTGCCTGTACTCAATTACGCAGTGGTCTATTTTCATACAGCTGCGACTGAGCCTCGCCGTTAACTGCGCCGCCGTCGAAGGAAATTGGAGTATTATCTCAGTTAGATCATGAGAAAGCTGATACTCATCCCGCTGAGACTCTATGTAATTGAAAGCATGAGGAGGATTCACTAATTGAGAATTCATTTATGAAAAATAGGCGCGCAGCGGCACCGCTTAGAGAATACGAACAAGAAAGTACAGATATAGGGTTTCGTCAGAAAGTTAAAGACCTATTAGTATTATCATTGAAGGTGACTCTCGAACGGGCAAAACGATGATCTCGAAGGGAGAATAGAGAAACAGTAGATTATTATGGAAGAGTCTGCTATGATAAGATTCAAGGATTATGATGTTTATATAGAGAAGATGGTAATGATGAGGCAGCAATTAAGATATATCAGATAATAAATAGACGCATTAATAAAGAAGAAACCTTTCCGTGGCATTTTGGTAAATATGATAGTGTCCACCGATTGAGCTCTCTCTAAAACTCTATATGAATTGGTGGAACGGTGGACAATATATAGTAGAAGCCTCATTTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
NP_049352.1
|
|
Location
|
167-922 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGACGCTCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTATCGGAAGCCCAGGATCTATCGGACGTTGAGGACGCCTGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTCGAGCAGCGACATGACATCTTACACACTGGTAAGGTAATGTGTATATCTGACGTTACACGTGGTAACGGTATTACCCACCGTGTCGGTAAGCGGTTTTGTGTTAAGTCCGTTTACATATTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACTAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTACGGCAAGGTCACAGGTGGTCAGTATGCAAGCAACGAGCAGGCTATTGTGAGGCGGTTTTGGAAGGTCAACAATCACGTGGTCTACAACCACCAAGAAGCTGGCAAATATGAGAACCATACGGAGAACGCACTATTATTGTACATGGCATGTACTCATGCCTCAAACCCTGTATATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRAGIGPRINKAAEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSFEQRHDILHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
NP_049353.1
|
|
Location
|
919-1317 |
|
Gene Name
|
AC3 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAAACCGAGTAGAACACATATCATACACCAGAACCAGGGTGTACCACCTCCAAATCAGATTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAGATTTAGACATTTAGTCCTTATGTACTTAGATCAGTTAGGTGTTATTTCAATTAACAATGTAATTAGAGCTGTTCGTTTTGCAACAGATCGATCATATGTAAATCATGTACTGGAAAATCATTCAATAAAATTAAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVFIWEIENPLYFKINRVEHISYTRTRVYHLQIRFNHNLRRALDLHKAYLNFQVWTTSMTASGSNYLARFRHLVLMYLDQLGVISINNVIRAVRFATDRSYVNHVLENHSIKLKFY |
|
NCBI Accession
|
NP_049354.1
|
|
Location
|
1064-1453 |
|
Gene Name
|
AC2 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGCTGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAAGCACACAGGCAAGCTAAGAGGAGGGCCATCAGAAGGAGACGCATTGATTTAGACTGCGGTTGCTCCATATACTTCCACATAGACTGCGCAGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAAACCGAGTAGAACACATATCATACACCAGAACCAGGGTGTACCACCTCCAAATCAGATTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAG |
|
Protein Sequence
|
MLSSSPSQPPSIKKAHRQAKRRAIRRRRIDLDCGCSIYFHIDCAGHGFTHRGAHHCTSGREWRVYLGDRKSPIFQDKPSRTHIIHQNQGVPPPNQIQPQPQESVGSPQSLPELPSLDDIDDSFWVELFS |
|
NCBI Accession
|
NP_049355.1
|
|
Location
|
1395-2450 |
|
Gene Name
|
AC1 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGCCACGGGCAGGTCGTTTTAGTATAAATGCCAGGAATTATTTCCTCACATATCCCCAGTGTTCGCTCACAAAAGAAGAAGCCCTTTCCCAATTGCAAAACCTAGAAACCCCAACTTCTAAGAAATTCATTCGTGTTTCAAGAGAACTACACGAAGATGGGCAACCTCATCTCCACGTTCTCATCCAGTTCGAAGGAAAGTACCAGTGCACCAATCAACGATTCTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGAGAGCTAAATCGTCTTCAGACGTCAAGACCTATGTGGAAAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAGACTGCCAATGATTCATATGCCAAAGCCCTCAATTCAGGCACGGTCTCCGAGGCCCTCAATATATTGAGAGAAGAACAACCGAAGGACTTTGTCCTTCAAAATCATAACATTCGTTCGAATCTTGAACGAATATTCGCAAATGCTCCGGAACCATGGGCTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGCTAAGGTGGGCTGATGACTATTTTGGAAGGAGTGCCGCTGCGCGCCGGGAAAGACCTATTAGTATTATCATTGAAGGTGACTCTCGAACGGGGAAGACGATGTGGGCTCGGGTCTTAGGCCCACATAATTACTTGAGCGGTCATCTTGATTTCAATTCTAGGGTCTATTCGAATGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCAGTATCTAAAGCTAAAGCACTGGAAAGAACTCATTGGGGCCCAAAAAGATTGGCAATCAAATTGCAAGTACGGAAAGCCTGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTCTGCAATCCTGGCGAGGGTTCCAGCTATAAAGCTTTCCTCGAGAAAGAAGATAATGCGTCTCTCAAAAACTGGACTCTAAAGAATGCTGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAAGCACACAGGCAAGCTAA |
|
Protein Sequence
|
MPRAGRFSINARNYFLTYPQCSLTKEEALSQLQNLETPTSKKFIRVSRELHEDGQPHLHVLIQFEGKYQCTNQRFFDLVSPTRSAHFHPNIQRAKSSSDVKTYVEKDGDFIDFGIFQIDGRSARGGCQTANDSYAKALNSGTVSEALNILREEQPKDFVLQNHNIRSNLERIFANAPEPWAPPFPLSSFTNVPDEMLRWADDYFGRSAAARRERPISIIIEGDSRTGKTMWARVLGPHNYLSGHLDFNSRVYSNEVEYNVIDDVAPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKAFLEKEDNASLKNWTLKNAVFITLTAPLYQESTQAS |
|
NCBI Accession
|
NP_049356.1
|
|
Location
|
2000-2293 |
|
Gene Name
|
AC4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGGCAACCTCATCTCCACGTTCTCATCCAGTTCGAAGGAAAGTACCAGTGCACCAATCAACGATTCTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGAGAGCTAAATCGTCTTCAGACGTCAAGACCTATGTGGAAAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAGACTGCCAATGATTCATATGCCAAAGCCCTCAATTCAGGCACGGTCTCCGAGGCCCTCAATATATTGA |
|
Protein Sequence
|
MGNLISTFSSSSKESTSAPINDSSTWYPQPGQHISIRTYRELNRLQTSRPMWKKTETSLILEFSRSMDDQLEEVARLPMIHMPKPSIQARSPRPSIY |
|
NCBI Accession
|
NP_049357.1
|
|
Location
|
431-1201 |
|
Gene Name
|
BV1 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGTATCCTACGAAGTATAGGCGTGTGTCTTTGTCTAGCCAACCACGTAATTATTCACGTAATACTTCGATAAGACGTCAATCAGTTTTCAAGCGTAATGACAACAAGCATCGAACGTTTCCAACCGGTAAGACAACGGATGTTTCCATGATGAAGGCCCAACGGATTCATGAGAATCAATATGGTCCAGATTTTGCAATGGTTCATAATACAGCAGTGTCTACATTCATTAGCTACCCTGATGTGGCTAAGTCTATGCCTAACCGAAAGAGGTCATATATTAAGCTAAAACGACTTCGTTTCAAGGGTATAGTGAAAGTGGAACGTGTTCATGCAGAGGTGAACATGGACTGTTTAGCGCCTAAGACCGAAGGAGTTTTCTCTCTGGTTATTGTGATGGATCGAAAACCTCATCTTGGACCATCTGGGGGGCTGCCTACTTTCGATGAGCTGTTTGGCGCCAGGATCCACAGTCATGGTAACCTGGCAATAGTTCCTTCTTTTAAGGATCGTTTCTACATACGCCATGTATTGAAGCGGGTGATATCAGTGGACAAGGATACTATGATGGTGGACATCGAAGGCGTTACAACCCTTTCTAGCAGGCGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGATGTAGAGTCTCGAAAGGGTGTATATGATAATATTAATAAGAACGCCTTGTTAGTTTATTATTGTTGGATGTCGGATACTGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGACTATATTGGATGA |
|
Protein Sequence
|
MYPTKYRRVSLSSQPRNYSRNTSIRRQSVFKRNDNKHRTFPTGKTTDVSMMKAQRIHENQYGPDFAMVHNTAVSTFISYPDVAKSMPNRKRSYIKLKRLRFKGIVKVERVHAEVNMDCLAPKTEGVFSLVIVMDRKPHLGPSGGLPTFDELFGARIHSHGNLAIVPSFKDRFYIRHVLKRVISVDKDTMMVDIEGVTTLSSRRFNCWAGFKDLDVESRKGVYDNINKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
|
NCBI Accession
|
NP_049358.1
|
|
Location
|
1224-2105 |
|
Gene Name
|
BC1 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGAATTCTCAATTAGTGAATCCTCCTCATGCTTTCAATTACATAGAGTCTCAGCGGGATGAGTATCAGCTTTCTCATGATCTAACTGAGATAATACTCCAATTTCCTTCGACGGCGGCGCAGTTAACGGCGAGGCTCAGTCGCAGCTGTATGAAAATAGACCACTGCGTAATTGAGTACAGGCAACAGGTACCCATCAACGCCACCGGTTCTGTAATAGTGGAGATTCATGACAAGAGGATGACAGACAACGAATCACTACAGGCGTCATGGACATTCCCGATAAGATGCAACATAGATCTCCACTATTTTTCAGCTTCCTTTTTCTCCCTAAAAGACCCCATCCCATGGAAACTCTATTACAGAGTTTCAGATACAAATGTTCATCAGCGGACACACTTTGCCAAGTTCAAAGGGAAGCTGAAACTGTCGACGGCTAAACATTCCGTGGACATTCCGTTCAGAGCGCCAACGGTGAAAATCCTGTCCAAGCAATTCACCGATAAAGATGTAGATTTCTCTCACGTCGACTATGGCAAATGGGAGAGGAAGCCCATACGGTGCGCATCAATGTCGAGAGTTGGGCTCAGAGGCCCAATTGATCTAAGGCCTGGTGAATCATGGGCTTCCAGGAGTACTATAGGTTGGGTCCATTCAGAAGGGGAGTCAGAGATAGAAAACGAGTTACATCCGTATCGAGATCTGCAAAGGCTAGGAGCCAGCGTTCTAGATCCGGGAGAGAGCGCATCTATAGTTGGTGCAAACAGGGCGCAGTCCAACATAACCATGTCTATAGCCCAGTTAAATGAACTTGTAAGGACAACTGTCCAAGAATGTATAAAGAGTCAGTGTAATAGTTCTCAGCCCAAAAATTTAAAATAA |
|
Protein Sequence
|
MNSQLVNPPHAFNYIESQRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIDLRPGESWASRSTIGWVHSEGESEIENELHPYRDLQRLGASVLDPGESASIVGANRAQSNITMSIAQLNELVRTTVQECIKSQCNSSQPKNLK |