Polygala garcinii virus
Basic Information
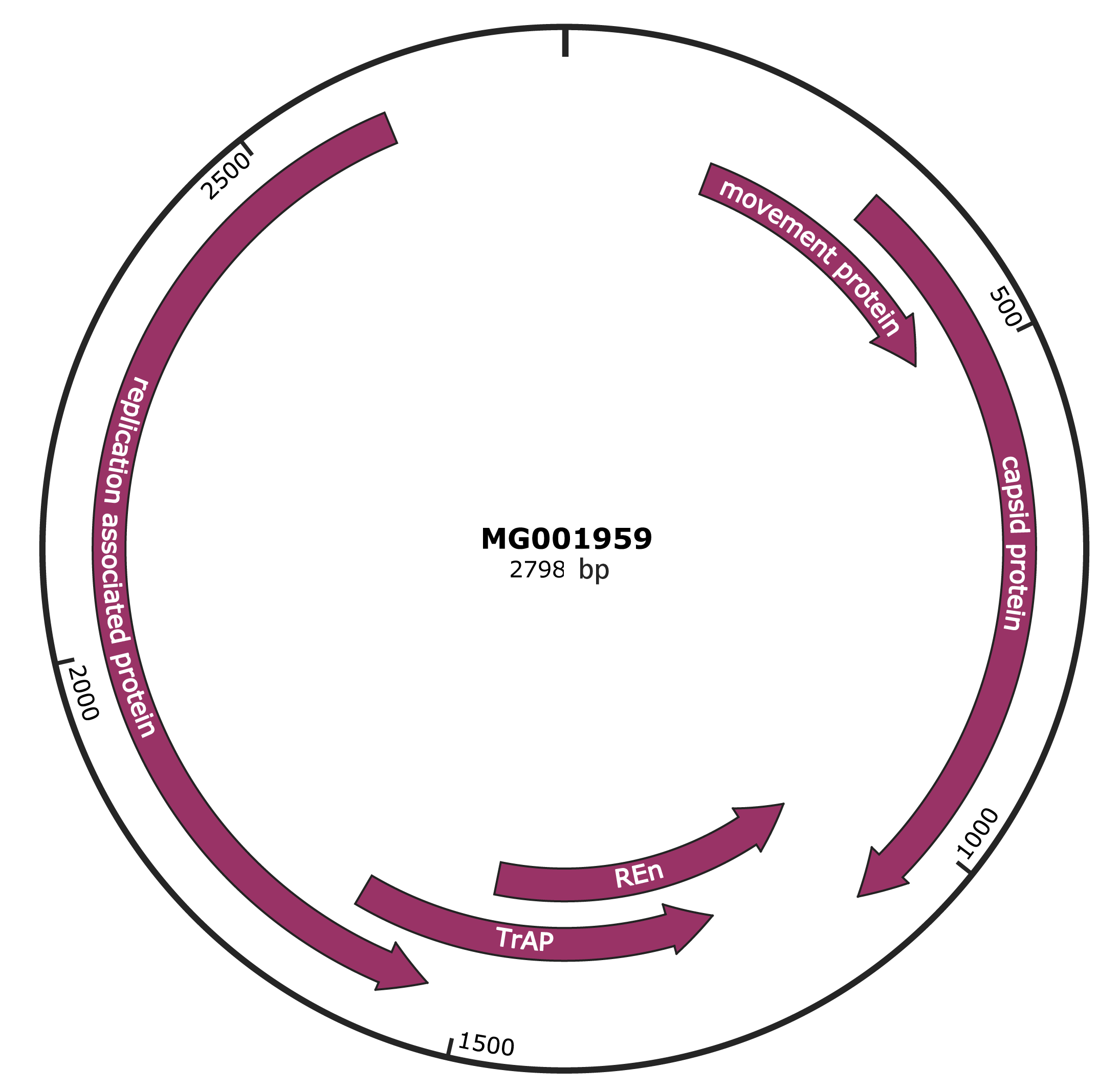
Genomic Organization
JBrowse
Genome
TAATATTACCGGATGGCCGCCGTTTGTCCTATGTTTGGCGGGTGATTTGACAGTTTGTCTCTTTTGCTTTGTTTGTCCAATGCGATGAATGCATTGGGGGTTATTTATAACCGTGTGGGCCCGTTATATACTTAGGTATGAAGTAGTTATTTTGAATTTGAAATGTGGGATCCATTATTGCACGATTTTCCGGAAAGCCTCCATGGCTTTCGGTGTATGCTTGCTGTAAAGTACCTTCTTTGTGTCTCGTCTCTGTACCCTGTACAGTCTGTGGGGTTCGAGTTGCTGAGGGATTGCATTAGTGCGGTGCGCACTCGTTCGTATGACGAAGGGTCGTGTAAGTATAGTGCCCTTTGTGCGAAGGTTAGGTCCACGTCTGAAGGGGAACTCACCCAGACGAGGACCCCGCTATGTTGTTGCCCGCACTGCCCCCGTCATATCGGCCGTGACCGAGTGGAAACGGAGACCAAGGAACCGGAACCCTAAGTCGTCTAAGAAGGATGTTGTTCCTTTCGGCTGCGAGGGTCCTTGTAAGGTTGAATCGTTTTCTGATAGGTATGAAGTGAAGCATACCGGTACTGTTTGTTGTTTGTCTCAGATTTCCCGTGGGAATGGTTTGAAGCAACGCATTGGGAAGAGGATTACTATTAAAAGTATTTACTTACTTGGTAAGGTGTGGTTGGACGGTAGTAACCGCATTTCCAATCATACTAATGTCTGTATATTTTTTGTCGTTAGGGATAGGCGTCCTTCTGTTACTCCTATCAATTTTGGTAGTTTATTTGATATGTTTGACGGTGAACCTGCTACGGCTTCTGTGAAGTCGGATCACCGTGATAGGTTTCAGGTGTTGTATCGTTTTCAGGTTTCTGTGTCTGGAGGGCAGTATTCTAGTCGTGATCAGACAGTTTTCCAGAAGTTTGTGAACCTCAATCATAGGGTTGTTTTTGATAATCAAGATGATGGTGTTTACGGGAATCATGATCAGAATGCGCTTCTTGTTTACATGGCTTGTTGCCATTCTACTAATTGGCTGTATTCTAGTATGAAAGCTAAAGTGTATTTCTATGATTCTGCAATGAATTAATAAAGTTTATATTTTATATCATGTTCTTCGTTTACAGATATGGTGTTCTCTAACACCTCGTACAGCACATGATCCACAGCTCTAATAACCGTGTTTAAACTGTAAACTCCTAATGAATCTAAAAACTTAAGAACTTGGTATCTAAAGACCCTCAAGAAACGCGATGTCTGAGGCTGTAGGCGGGTCCAGGTGCGAAAATTGAGGTAGCACTTGTGCATCCCCAACGCTCTCCTCAGGTTGTGGTTGAACCTGATTTGGAGGTGTATGATATCCGTGTCCGACAGGGCTGGTCTGATGTCGTGTTGGGTTATCTTGAAATAGAGGGCGTTTTGTACCGTCCAGGTAAAAACGCCATTCCTTGCGAGAGGTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTCGATGTGGACGTATATTGTGCAACCGCAGTCTAGATCAATTCGCTTCCTGCGAATGATTTTCTTCTTCTTCGCTGCCTTGTGCGCTATCTTGACGTCCTGTGTACAATGGTTGGGATAGGAAGACGAAGATTGCATTCTTCAGTGCCCAATTTTTGAGTGTGGAGTTCTTCTCCTCATCGAGGTACTCTTTATAGCTTGAAGTTGGGCCTGGATTGCACAGGAATATGGTCGGTATGCCACCCTTGACCATTGTGGGCTTGCCGTATTTGGTGTTTGATTTCCAGTTGGATTGGCAGCCCATGAATTCCTTGAAGTGCTTGAGATAATGTGGATCTACGTCATCAATGACGTTGTACCATGCGTCGTTGGAGAAGTCTCTCGGAGAGAGATCAATGTGACCGCAGATGTAATTATGCGGTCCTAATGACCTTGCCCAGAGAGTTTTACCCGTACGACTATCACCTTCAACCACTATGCTTATCGGTCTAATTGGCCGCGCAGCGGAATGAACAACGTTATCGCACGCCCATTCCTCCATCTCTTCTGGTACCCTATCAAACGATGAACAAGTAAATGGACATTGAAATTGTGGTATGGGTGGGGGAAATAACCTGTCTAAATTGGCTGTGATGTTGTGGTACTGTAATAGGAATGACTTGGGATCTTTTTCTTTTAGTACAGTGAGGGCCTGTGATTTGTCGCCTGTGTTGATTGCTTCGGCGTACGTGTCGGCTGCCGTGCTGCCGCCTCGTCTAGTAGATCTTCCATCGATCTGGAAAACTCCATGATCAATGACGTCCCCGTCTTTCTCCATGTAGGTTTTGACATCTGAGCTTGATTTAGCTGCCTGAATGTTTGGATGGTAATGTGTTGTCCGCACTGGAGAGGTGAGGTCGAAGAATCGGTTGTTGGTGCAGACGAATTTGCCTTCGAATTGGATGAGGACGTGGAGGTGTGGTTGCCCATCTTCGTGCAGTTCTCTGCATATGCGTATGAATTTTTTGTTTGTTGGTGTTGTGGGGTTTTGCAGTTGGGCGAGGGTTTCTTCCTTGGTTAGTGTACATTGTGGGTATGTTAGGAAGTAATTCCTTGCTGATATGCGGAATCGTCTGGTTGGTGGCATTTTCGCAATTTTGGGAGTGTCACCGATTCGTTTTGGGTGTCACCAATTGCCTTCTATCCATATGGTTTGGTGACTGGTGTACAATATATAGAAGTACTAGTTCTATAATAGTACCTATGCGGATGGGTGCCTTCGGATTTGGATCTGCCATGATACACGTGGCGGCCATCCGT
Gene Information
|
NCBI Accession
|
AUT11869.1
|
|
Location
|
163-486 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTGGGATCCATTATTGCACGATTTTCCGGAAAGCCTCCATGGCTTTCGGTGTATGCTTGCTGTAAAGTACCTTCTTTGTGTCTCGTCTCTGTACCCTGTACAGTCTGTGGGGTTCGAGTTGCTGAGGGATTGCATTAGTGCGGTGCGCACTCGTTCGTATGACGAAGGGTCGTGTAAGTATAGTGCCCTTTGTGCGAAGGTTAGGTCCACGTCTGAAGGGGAACTCACCCAGACGAGGACCCCGCTATGTTGTTGCCCGCACTGCCCCCGTCATATCGGCCGTGACCGAGTGGAAACGGAGACCAAGGAACCGGAACCCTAA |
|
Protein Sequence
|
MWDPLLHDFPESLHGFRCMLAVKYLLCVSSLYPVQSVGFELLRDCISAVRTRSYDEGSCKYSALCAKVRSTSEGELTQTRTPLCCCPHCPRHIGRDRVETETKEPEP |
|
NCBI Accession
|
AUT11870.1
|
|
Location
|
323-1087 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGACGAAGGGTCGTGTAAGTATAGTGCCCTTTGTGCGAAGGTTAGGTCCACGTCTGAAGGGGAACTCACCCAGACGAGGACCCCGCTATGTTGTTGCCCGCACTGCCCCCGTCATATCGGCCGTGACCGAGTGGAAACGGAGACCAAGGAACCGGAACCCTAAGTCGTCTAAGAAGGATGTTGTTCCTTTCGGCTGCGAGGGTCCTTGTAAGGTTGAATCGTTTTCTGATAGGTATGAAGTGAAGCATACCGGTACTGTTTGTTGTTTGTCTCAGATTTCCCGTGGGAATGGTTTGAAGCAACGCATTGGGAAGAGGATTACTATTAAAAGTATTTACTTACTTGGTAAGGTGTGGTTGGACGGTAGTAACCGCATTTCCAATCATACTAATGTCTGTATATTTTTTGTCGTTAGGGATAGGCGTCCTTCTGTTACTCCTATCAATTTTGGTAGTTTATTTGATATGTTTGACGGTGAACCTGCTACGGCTTCTGTGAAGTCGGATCACCGTGATAGGTTTCAGGTGTTGTATCGTTTTCAGGTTTCTGTGTCTGGAGGGCAGTATTCTAGTCGTGATCAGACAGTTTTCCAGAAGTTTGTGAACCTCAATCATAGGGTTGTTTTTGATAATCAAGATGATGGTGTTTACGGGAATCATGATCAGAATGCGCTTCTTGTTTACATGGCTTGTTGCCATTCTACTAATTGGCTGTATTCTAGTATGAAAGCTAAAGTGTATTTCTATGATTCTGCAATGAATTAA |
|
Protein Sequence
|
MTKGRVSIVPFVRRLGPRLKGNSPRRGPRYVVARTAPVISAVTEWKRRPRNRNPKSSKKDVVPFGCEGPCKVESFSDRYEVKHTGTVCCLSQISRGNGLKQRIGKRITIKSIYLLGKVWLDGSNRISNHTNVCIFFVVRDRRPSVTPINFGSLFDMFDGEPATASVKSDHRDRFQVLYRFQVSVSGGQYSSRDQTVFQKFVNLNHRVVFDNQDDGVYGNHDQNALLVYMACCHSTNWLYSSMKAKVYFYDSAMN |
|
NCBI Accession
|
AUT11872.1
|
|
Location
|
1084-1488 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCACCTCTCGCAAGGAATGGCGTTTTTACCTGGACGGTACAAAACGCCCTCTATTTCAAGATAACCCAACACGACATCAGACCAGCCCTGTCGGACACGGATATCATACACCTCCAAATCAGGTTCAACCACAACCTGAGGAGAGCGTTGGGGATGCACAAGTGCTACCTCAATTTTCGCACCTGGACCCGCCTACAGCCTCAGACATCGCGTTTCTTGAGGGTCTTTAGATACCAAGTTCTTAAGTTTTTAGATTCATTAGGAGTTTACAGTTTAAACACGGTTATTAGAGCTGTGGATCATGTGCTGTACGAGGTGTTAGAGAACACCATATCTGTAAACGAAGAACATGATATAAAATATAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAPLARNGVFTWTVQNALYFKITQHDIRPALSDTDIIHLQIRFNHNLRRALGMHKCYLNFRTWTRLQPQTSRFLRVFRYQVLKFLDSLGVYSLNTVIRAVDHVLYEVLENTISVNEEHDIKYKLY |
|
NCBI Accession
|
AUT11873.1
|
|
Location
|
1229-1636 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCAATCTTCGTCTTCCTATCCCAACCATTGTACACAGGACGTCAAGATAGCGCACAAGGCAGCGAAGAAGAAGAAAATCATTCGCAGGAAGCGAATTGATCTAGACTGCGGTTGCACAATATACGTCCACATCGACTGCCACAACCATGGATTCACGCACAGGGGAACCCATCACTGCACCTCTCGCAAGGAATGGCGTTTTTACCTGGACGGTACAAAACGCCCTCTATTTCAAGATAACCCAACACGACATCAGACCAGCCCTGTCGGACACGGATATCATACACCTCCAAATCAGGTTCAACCACAACCTGAGGAGAGCGTTGGGGATGCACAAGTGCTACCTCAATTTTCGCACCTGGACCCGCCTACAGCCTCAGACATCGCGTTTCTTGAGGGTCTTTAG |
|
Protein Sequence
|
MQSSSSYPNHCTQDVKIAHKAAKKKKIIRRKRIDLDCGCTIYVHIDCHNHGFTHRGTHHCTSRKEWRFYLDGTKRPLFQDNPTRHQTSPVGHGYHTPPNQVQPQPEESVGDAQVLPQFSHLDPPTASDIAFLEGL |
|
NCBI Accession
|
AUT11871.1
|
|
Location
|
1536-2624 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCAACCAGACGATTCCGCATATCAGCAAGGAATTACTTCCTAACATACCCACAATGTACACTAACCAAGGAAGAAACCCTCGCCCAACTGCAAAACCCCACAACACCAACAAACAAAAAATTCATACGCATATGCAGAGAACTGCACGAAGATGGGCAACCACACCTCCACGTCCTCATCCAATTCGAAGGCAAATTCGTCTGCACCAACAACCGATTCTTCGACCTCACCTCTCCAGTGCGGACAACACATTACCATCCAAACATTCAGGCAGCTAAATCAAGCTCAGATGTCAAAACCTACATGGAGAAAGACGGGGACGTCATTGATCATGGAGTTTTCCAGATCGATGGAAGATCTACTAGACGAGGCGGCAGCACGGCAGCCGACACGTACGCCGAAGCAATCAACACAGGCGACAAATCACAGGCCCTCACTGTACTAAAAGAAAAAGATCCCAAGTCATTCCTATTACAGTACCACAACATCACAGCCAATTTAGACAGGTTATTTCCCCCACCCATACCACAATTTCAATGTCCATTTACTTGTTCATCGTTTGATAGGGTACCAGAAGAGATGGAGGAATGGGCGTGCGATAACGTTGTTCATTCCGCTGCGCGGCCAATTAGACCGATAAGCATAGTGGTTGAAGGTGATAGTCGTACGGGTAAAACTCTCTGGGCAAGGTCATTAGGACCGCATAATTACATCTGCGGTCACATTGATCTCTCTCCGAGAGACTTCTCCAACGACGCATGGTACAACGTCATTGATGACGTAGATCCACATTATCTCAAGCACTTCAAGGAATTCATGGGCTGCCAATCCAACTGGAAATCAAACACCAAATACGGCAAGCCCACAATGGTCAAGGGTGGCATACCGACCATATTCCTGTGCAATCCAGGCCCAACTTCAAGCTATAAAGAGTACCTCGATGAGGAGAAGAACTCCACACTCAAAAATTGGGCACTGAAGAATGCAATCTTCGTCTTCCTATCCCAACCATTGTACACAGGACGTCAAGATAGCGCACAAGGCAGCGAAGAAGAAGAAAATCATTCGCAGGAAGCGAATTGA |
|
Protein Sequence
|
MPPTRRFRISARNYFLTYPQCTLTKEETLAQLQNPTTPTNKKFIRICRELHEDGQPHLHVLIQFEGKFVCTNNRFFDLTSPVRTTHYHPNIQAAKSSSDVKTYMEKDGDVIDHGVFQIDGRSTRRGGSTAADTYAEAINTGDKSQALTVLKEKDPKSFLLQYHNITANLDRLFPPPIPQFQCPFTCSSFDRVPEEMEEWACDNVVHSAARPIRPISIVVEGDSRTGKTLWARSLGPHNYICGHIDLSPRDFSNDAWYNVIDDVDPHYLKHFKEFMGCQSNWKSNTKYGKPTMVKGGIPTIFLCNPGPTSSYKEYLDEEKNSTLKNWALKNAIFVFLSQPLYTGRQDSAQGSEEEENHSQEAN |