Pepper yellow leaf curl Indonesia virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000867505.1 |
| Isolate |
Indonesia |
| Release date |
2015/2/13 |
| Submitter |
Sakata,J.J., Shibuya,Y., Sharma,P., Ikegami,M., Sakata,J. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
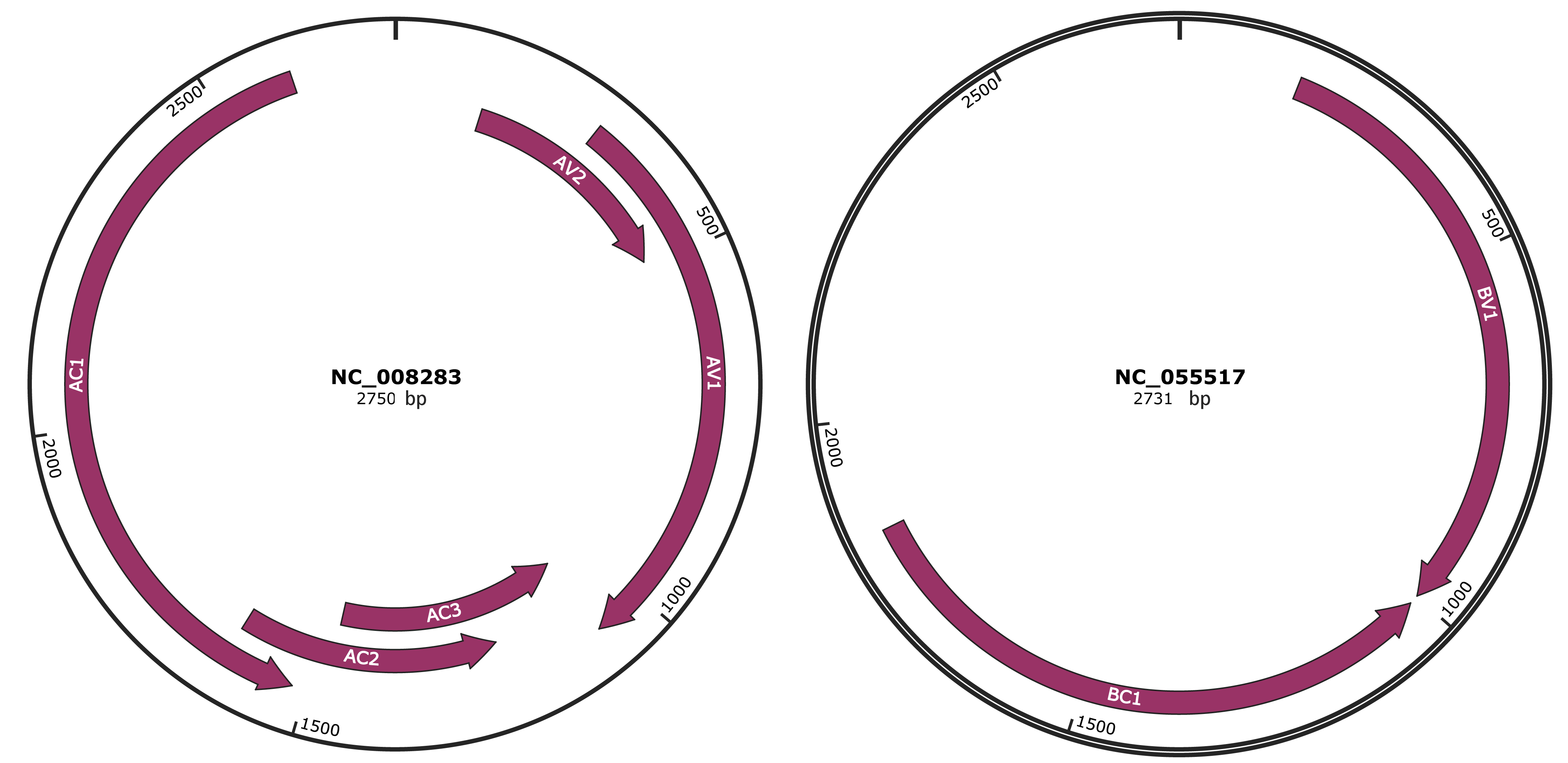
JBrowse
Genome
ACCGAGTGCCGCGAAAATTTTTTAAAGGTGGTCCCACGAGCCAACCTTCTGACTGACCAATGGCGTTGCTTCTGAAAAGCTTAATTAGTGGGTCGCCCACTATAAAGATAGGGACCACGCTCCACTACTCAAGGATGTGGGATCCGCTCGTTCATCCTTTTCCAGAAACCCTACACGGGTTTCGATGCATGTTGGCAATCAAATATCTGCAAAGCTTAGAGGCTACGTATTCTCCTGATACGGTCGGAGGTGAATTTGTGAAGGATTTAATCTGCCTGTTGCGTTGTAAAAACTATGCCGAAGCGTTCCATCGATACAGTGTCGTCGTTGCCAATGTCTATAACACGCCGGAGACTAAACTACGCGAGTCAGTACAGTCTCCCTGCTGCTGCCCCCACTGCCCCAGGCATGTCTTACAAACGAAGAGCATGGGTAAATCGGCCTATGAATCGGAAACCCAGATTCTACAGGGGTCGAAGGACCAGTGATGTTCCACGGGGTTGTGAAGGACCTTGTAAGGTCCAATCCTTTGAACAGAGACATGACGTAACACATACTGGGAAGGTCCTTTGCGTTTCCGATGTCACTAGAGGTAATGGTATTACGCATAGAGTAGGGAAAAGATTCTGTGTGAAATCTGTATATATTATTGGCAAAGTATGGATGGACGAGAACATCAAGTCGAAGAACCACACTAATAACGTCATGTTTTGGCTTGTTCGTGACCGGCGACCAGTTACAACTCCTTATGGCTTCGGCGAGTTGTTCAACATGTATGATAATGAACCCAGCACAGCAACTATCAAGAACGATCTTCGTGATCGTGTTCAGGTGTTACATCGTTTCTCAGCCACGGTGACAGGTGGTCAGTATGCAAGCAAAGAACAAGCAATCGTGAAGAGATTTTTTAGAGTTAACAATTATGTTGTTTACAATCATCAAGAAGCAGCAAAATATGAAAATCACACTGAAAATGCATTGTTGTTGTATATGGCATGTACTCATGCATCTAATCCTGTGTACGCTACATTGAAAATTCGTATATACTTCTACGACAATGTAACAAATTAATAAAGGTTAAATTTTATTATATGCAACTGCTTTGCGTACACTGTATGTTCAAGTACATCCCACAAAACATAATTCACAGCTCTAATTACATTGTTTATCGACACAATTCCTAAATTGGATAAATAGCTAATTACATTGTTCTTAAATACTCTTAAGAAATGCCAAGTCTGAGGACGTAAACGAGTCCAAATGTGGAAGATTAAAAAACACTTGTGAATCCCCAGCGCTTTCCTCAAGTTGTGGTTGAATTGGATTTGCACTTCCATGTAGTCCATGTCGGTGTTGAACGGTCTGGTGCTGTGCCTCAGCACCTTGAAATAGAGGGGATTTGGAACCTTCCAAATATAGACGCCATTCTGCGCCTGAGCTGCAGTGATGTACTCCCCTGTGCGAAAATCCATACCCATGACAGTTGATACTGAGATAATATGAGCAGCCGCAGTCTAAGTCAATACGTCTCCTGCGGATTATTTTCTTCTTCGCAATTTGGTGCAGTATCTTCTGTGGAACTTGAGTAGAGTGGCCCGTTGATGGTGACGAAGGTCGCATTTTTTAGTGCCCAAGATTTCAATGCATTATTTTTGTCCTCGTCAAGGTATTCTTTATATGACGAGGTAGGACCAGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAATTGGCTTGCCGTATTTTGTGTTGCTTTGCCAGTTCCTCTGGGCCCCCATAAACTCTTTAAAGTGCTTTAGATAGTGGGGGTCGACGTCATCAATGACGTTGTACCAGGCGTCATTGTTGTATACCTTGGGGCTCAAGTCTAGATGTCCACAGAGATAATTATGGAGGCCCAATGATCTAGCCCACATTGTTTTGCCTGTACGACTCTCACCTTCTAACACAATACTAATGGGCCTCCATGGCCGCGCAGCGGCATCCTTCACATTTTCACTAGCCCATTCTCGTAGTTCCTCTGGAACTTGGTCAAACGACGACGACGGATATGGTGAAACAAATGCATCTACAGGTTTAGCAAATATTTTATCGAAATTAACATTTAAATTGTGGTACTGTAGAACGTAGTCTTTTGGAGCAAGCTCTTTAATCAATTGAAGAGCATCGGACTTACTTCCACAATTTAGGGCCTGCGCATAAACATCGTTGACGGTGTGTTGACCACCTCGTGCAGATCTGCCATCTATCTGAAATTCTCCCCATTCGATTGAATCACCGTCTTTGTCCATGTACGCCTTGACATCGGAACTTGACTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGCCCTGGTTGAGGATAGCAGGTCGAAGAATCTGTTGTTGGTGCAGACGTATTTTCCTTCGAATTGTATGAGCACATGGAGATGAGGGCTCCCATCTTCGTGAAGTTCTCTACAGATCTTGACAAACAGCTTGTTGACAGGAGTGTTAAAAGATTTTAATTGTTCCAGTGCTTCTTCTTTTGTTAGAGAACAGTGTGGATATGTTAAGAAATAGTTTTTGCTCTGCAACTTAAAACGACGTGGTGGAGGCATTTGGAGTGTCGTTTTGTATTGGAGACAATCACTTCTATCCCTATGTATTGGAGACAGGAGACAATATATAGATAAGTTCTATAAGGGCTTCTAGGTAATTTTGTACACCCTTGAATGATTAAAGCGGCACTCGTATAATATT
ACCGAGGGCCGCGTTTTTTTTTTGTGGTCCCCCCACGTGCATTACTACGTGTCCTCATCGTAGTCACACACAAACGGACAGCTGTCACTCATCCAAGGGTTCACGTACATTCCTTTGACAGCTATAAGTATATTCAATCCATTATTCAGCATTTTGTTAGACAAAATGAGAATTCCCATTAGAACTCCCATGGGTTCAAACAGAGACCGGAGAGGGGGTTCTGGTTCCATATTCCGGTGGAACAACCCATATTCACGGTATTTTGGTCGTAGAGTTGGCACCCGTGTATACGGTATGCCTTTTGGTGGGTCGTCTGTACCTCGTAGACATGTCAGCAATTCTGTTCGTCGGAACTTGTTTTCCGACCACCAAGACAAAGGGCGTAAAAGAAGAAATTCTATAGAGGAGGTACATGACGGTACAGACTATCTTCTTTGTAACAACACTTCTAAGGTGTCTTATATTAGCTATCCTGCCATGTGCCGTTCTGATTTTAGTAGCAGGATAGATTCATTTGTTCGAGTGTTAGGGTTCAATGTCTCTGGGTCAGTAGTTGCCCGTCAGCAGGAGCGGGTTGACGGTTCGAAGACAAGCGGTATCCACGGCATATTCAGTACGGTGGTTGTCCGAGACAAGAAGCCTTGCGAGTTCTCCTCTGTGGATCCCCTCATTCCATTTGCGGAGATATTCGGACATGAGAAGGGAGCATGTTCTACTCTAAGAGTTAGAGATGCACATAGGAATAGGTTTGTGTTAGTCCAGCAGAAGAAGTGCGTTGTAAATACCGCTTTGCCGGTTCATGTATTTAGGTTTGTTTATTCTGTTAGGTTCAATAGATACCCTCTCTGGGTATCATTCAAGGACACAACTGATGTAGAACCTAGTGGTCTCTACAGCAACGTGTCAAAGAACGCACTTCTTGTTTATTATGTCTGGTTGTGTGATTCCAATGTAACTTCCGACATTCATGTAAAGTACGACCTTGACTATATTGGATAAATAAAATTATATTTTATTTGATCGGTTTTGCATTCGAAGTTACATTACTGCCTTCCATACACAACTCTACAGTTTTTTTGATAATGTTAATTACATCGTCGTTAATCTTGTTGTTATTCACAACAACGTCTGAGGCAGATGGTCCCGGGTCTAGTGTCTGGTCTTGCAGCCGGTGCAGTCCTCTGTATGGAAGATCGTCTTGATCTTCATTCCCAATTGCACTTGCAGAAGCCCATGTCTGCCCAGGAAGAATTGCAGGAGTTGTGTATCGACATGACTGCGACCTCATGTTGGTCAGTCCTTGGACAGGTTTCCTGGAAACCTGAGAATGGGGCACCGTCCAGAAATCAATGTTGGTCATGTTAAACGCCTTGGACAATATTTCAATCTTGGGGGATTTGAACTGGATTTCTGTGGACTGTTTAGCTGAAGACATCTTCAGCTTGCCTTGCATCCTACAGAAATGTACCCCGTTGACGACATTCGTGTCGTCAACCCTGTATAGAACCTTCCAAGGATTAGGGTCTTTCGGGGAAAAATACGAAGAGGAGTAGTAGTGTATATTGCAGTTGCACCCAATTGGAATTGTGAACTCCGCCTGTTTCGAGTCTCCTTCGTGCAGTCTTGTGTCGTGCATCTCTATTATGACGTGTCCAGTTGCATTTACAGGAACCTGATTCCTGTATTCAAGAATGACATGGTCAATTCTCAAACATTTGCCCATGAGTTTGGACAATTTTTGATCAAGAGTGGAAGGGAACAACAATGTCACCTCTGTTTTTTCATTGGACAGTTGAAACTCTGTCCTGTCCGACGTGGAATATGCAAGAGTGTTGTGGTTAGTTTCCATTTTTCACAGTGCATTCTTAGCTGGAATGCACTGCTTTTATAGTGGGTGTCAGAAAAGCTGTTGTACGTGGTGTCAGAAAAGTTGTTGTAGTGGGTGTCAGAAAAGCTGCCACAGTCTGAAACCGCCAAATTTGAAATTTGAAAACTTAATAACTAAGGATTGAAGCGTGGCTGCTATTCAGCCACGTCATGCATGTACTATGTGGATGACAGCTGTCATCCACTAACAGACAGAGTAGTGATTTAAAATGGGTAAAGCTGGAAACCCTAAATTGACCTTGACTGCAATTTCCAATTAAATTAAAGTGTGAATAGGAGTTAATTCTGAAAGCTGGATTGTTAACATACTCGTTAACACTAACAACACAACTGAACCAATTTATATGAACGGTAACATCGATTAACATACACGTTAATCGACAAAACAGGAAACAAGTCGAAGAACTTACAACTAAACAAAACTAATCAGAATCAATTAACAATAATTAGGCCGCGCAGCGGCAGTGTTCATCCATTTTATCCAACACTAAACAAGTGGGAAAAACAAGATGGGTTTGTTAACAAACCCATTAACAATAAATCAAATAATTAAGCAATTTAATTATTTGACAAAATAGCTATACCTAACAATGTTGCATTTTATAGCCTAACATTTAGACAAATCGTTTACTTATACTATTTATGAGATTTAATTTCAATTAAATCAGAGCAGGTGTGAGAGTTGTCTAGAGAGAGAAAGTGAATTCTAGAGAGAGAAGCAATTGGAGACAATCCTTCTATCCCCCTATATTGGAGACAGGAGACAATATATAGAAGTACTATATGGGCCTTACTACTTATTGGGCCTTACCCGGGTAAAGCGGCCCTCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_717090.1
|
|
Location
|
135-488 |
|
Gene Name
|
AV2 |
|
Protein Name
|
moving protein |
|
Coding Region
|
ATGTGGGATCCGCTCGTTCATCCTTTTCCAGAAACCCTACACGGGTTTCGATGCATGTTGGCAATCAAATATCTGCAAAGCTTAGAGGCTACGTATTCTCCTGATACGGTCGGAGGTGAATTTGTGAAGGATTTAATCTGCCTGTTGCGTTGTAAAAACTATGCCGAAGCGTTCCATCGATACAGTGTCGTCGTTGCCAATGTCTATAACACGCCGGAGACTAAACTACGCGAGTCAGTACAGTCTCCCTGCTGCTGCCCCCACTGCCCCAGGCATGTCTTACAAACGAAGAGCATGGGTAAATCGGCCTATGAATCGGAAACCCAGATTCTACAGGGGTCGAAGGACCAGTGA |
|
Protein Sequence
|
MWDPLVHPFPETLHGFRCMLAIKYLQSLEATYSPDTVGGEFVKDLICLLRCKNYAEAFHRYSVVVANVYNTPETKLRESVQSPCCCPHCPRHVLQTKSMGKSAYESETQILQGSKDQ |
|
NCBI Accession
|
YP_717091.1
|
|
Location
|
295-1071 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCGAAGCGTTCCATCGATACAGTGTCGTCGTTGCCAATGTCTATAACACGCCGGAGACTAAACTACGCGAGTCAGTACAGTCTCCCTGCTGCTGCCCCCACTGCCCCAGGCATGTCTTACAAACGAAGAGCATGGGTAAATCGGCCTATGAATCGGAAACCCAGATTCTACAGGGGTCGAAGGACCAGTGATGTTCCACGGGGTTGTGAAGGACCTTGTAAGGTCCAATCCTTTGAACAGAGACATGACGTAACACATACTGGGAAGGTCCTTTGCGTTTCCGATGTCACTAGAGGTAATGGTATTACGCATAGAGTAGGGAAAAGATTCTGTGTGAAATCTGTATATATTATTGGCAAAGTATGGATGGACGAGAACATCAAGTCGAAGAACCACACTAATAACGTCATGTTTTGGCTTGTTCGTGACCGGCGACCAGTTACAACTCCTTATGGCTTCGGCGAGTTGTTCAACATGTATGATAATGAACCCAGCACAGCAACTATCAAGAACGATCTTCGTGATCGTGTTCAGGTGTTACATCGTTTCTCAGCCACGGTGACAGGTGGTCAGTATGCAAGCAAAGAACAAGCAATCGTGAAGAGATTTTTTAGAGTTAACAATTATGTTGTTTACAATCATCAAGAAGCAGCAAAATATGAAAATCACACTGAAAATGCATTGTTGTTGTATATGGCATGTACTCATGCATCTAATCCTGTGTACGCTACATTGAAAATTCGTATATACTTCTACGACAATGTAACAAATTAA |
|
Protein Sequence
|
MPKRSIDTVSSLPMSITRRRLNYASQYSLPAAAPTAPGMSYKRRAWVNRPMNRKPRFYRGRRTSDVPRGCEGPCKVQSFEQRHDVTHTGKVLCVSDVTRGNGITHRVGKRFCVKSVYIIGKVWMDENIKSKNHTNNVMFWLVRDRRPVTTPYGFGELFNMYDNEPSTATIKNDLRDRVQVLHRFSATVTGGQYASKEQAIVKRFFRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDNVTN |
|
NCBI Accession
|
YP_717092.1
|
|
Location
|
1068-1472 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTTTCGCACAGGGGAGTACATCACTGCAGCTCAGGCGCAGAATGGCGTCTATATTTGGAAGGTTCCAAATCCCCTCTATTTCAAGGTGCTGAGGCACAGCACCAGACCGTTCAACACCGACATGGACTACATGGAAGTGCAAATCCAATTCAACCACAACTTGAGGAAAGCGCTGGGGATTCACAAGTGTTTTTTAATCTTCCACATTTGGACTCGTTTACGTCCTCAGACTTGGCATTTCTTAAGAGTATTTAAGAACAATGTAATTAGCTATTTATCCAATTTAGGAATTGTGTCGATAAACAATGTAATTAGAGCTGTGAATTATGTTTTGTGGGATGTACTTGAACATACAGTGTACGCAAAGCAGTTGCATATAATAAAATTTAACCTTTATTAA |
|
Protein Sequence
|
MDFRTGEYITAAQAQNGVYIWKVPNPLYFKVLRHSTRPFNTDMDYMEVQIQFNHNLRKALGIHKCFLIFHIWTRLRPQTWHFLRVFKNNVISYLSNLGIVSINNVIRAVNYVLWDVLEHTVYAKQLHIIKFNLY |
|
NCBI Accession
|
YP_717093.1
|
|
Location
|
1213-1620 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTCGTCACCATCAACGGGCCACTCTACTCAAGTTCCACAGAAGATACTGCACCAAATTGCGAAGAAGAAAATAATCCGCAGGAGACGTATTGACTTAGACTGCGGCTGCTCATATTATCTCAGTATCAACTGTCATGGGTATGGATTTTCGCACAGGGGAGTACATCACTGCAGCTCAGGCGCAGAATGGCGTCTATATTTGGAAGGTTCCAAATCCCCTCTATTTCAAGGTGCTGAGGCACAGCACCAGACCGTTCAACACCGACATGGACTACATGGAAGTGCAAATCCAATTCAACCACAACTTGAGGAAAGCGCTGGGGATTCACAAGTGTTTTTTAATCTTCCACATTTGGACTCGTTTACGTCCTCAGACTTGGCATTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MRPSSPSTGHSTQVPQKILHQIAKKKIIRRRRIDLDCGCSYYLSINCHGYGFSHRGVHHCSSGAEWRLYLEGSKSPLFQGAEAQHQTVQHRHGLHGSANPIQPQLEESAGDSQVFFNLPHLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_717094.1
|
|
Location
|
1520-2608 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTCCACCACGTCGTTTTAAGTTGCAGAGCAAAAACTATTTCTTAACATATCCACACTGTTCTCTAACAAAAGAAGAAGCACTGGAACAATTAAAATCTTTTAACACTCCTGTCAACAAGCTGTTTGTCAAGATCTGTAGAGAACTTCACGAAGATGGGAGCCCTCATCTCCATGTGCTCATACAATTCGAAGGAAAATACGTCTGCACCAACAACAGATTCTTCGACCTGCTATCCTCAACCAGGGCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCAAGTTCCGATGTCAAGGCGTACATGGACAAAGACGGTGATTCAATCGAATGGGGAGAATTTCAGATAGATGGCAGATCTGCACGAGGTGGTCAACACACCGTCAACGATGTTTATGCGCAGGCCCTAAATTGTGGAAGTAAGTCCGATGCTCTTCAATTGATTAAAGAGCTTGCTCCAAAAGACTACGTTCTACAGTACCACAATTTAAATGTTAATTTCGATAAAATATTTGCTAAACCTGTAGATGCATTTGTTTCACCATATCCGTCGTCGTCGTTTGACCAAGTTCCAGAGGAACTACGAGAATGGGCTAGTGAAAATGTGAAGGATGCCGCTGCGCGGCCATGGAGGCCCATTAGTATTGTGTTAGAAGGTGAGAGTCGTACAGGCAAAACAATGTGGGCTAGATCATTGGGCCTCCATAATTATCTCTGTGGACATCTAGACTTGAGCCCCAAGGTATACAACAATGACGCCTGGTACAACGTCATTGATGACGTCGACCCCCACTATCTAAAGCACTTTAAAGAGTTTATGGGGGCCCAGAGGAACTGGCAAAGCAACACAAAATACGGCAAGCCAATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCTGGTCCTACCTCGTCATATAAAGAATACCTTGACGAGGACAAAAATAATGCATTGAAATCTTGGGCACTAAAAAATGCGACCTTCGTCACCATCAACGGGCCACTCTACTCAAGTTCCACAGAAGATACTGCACCAAATTGCGAAGAAGAAAATAATCCGCAGGAGACGTATTGA |
|
Protein Sequence
|
MPPPRRFKLQSKNYFLTYPHCSLTKEEALEQLKSFNTPVNKLFVKICRELHEDGSPHLHVLIQFEGKYVCTNNRFFDLLSSTRAAHFHPNIQGAKSSSDVKAYMDKDGDSIEWGEFQIDGRSARGGQHTVNDVYAQALNCGSKSDALQLIKELAPKDYVLQYHNLNVNFDKIFAKPVDAFVSPYPSSSFDQVPEELREWASENVKDAAARPWRPISIVLEGESRTGKTMWARSLGLHNYLCGHLDLSPKVYNNDAWYNVIDDVDPHYLKHFKEFMGAQRNWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNNALKSWALKNATFVTINGPLYSSSTEDTAPNCEEENNPQETY |
|
NCBI Accession
|
YP_717095.1
|
|
Location
|
166-999 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGAGAATTCCCATTAGAACTCCCATGGGTTCAAACAGAGACCGGAGAGGGGGTTCTGGTTCCATATTCCGGTGGAACAACCCATATTCACGGTATTTTGGTCGTAGAGTTGGCACCCGTGTATACGGTATGCCTTTTGGTGGGTCGTCTGTACCTCGTAGACATGTCAGCAATTCTGTTCGTCGGAACTTGTTTTCCGACCACCAAGACAAAGGGCGTAAAAGAAGAAATTCTATAGAGGAGGTACATGACGGTACAGACTATCTTCTTTGTAACAACACTTCTAAGGTGTCTTATATTAGCTATCCTGCCATGTGCCGTTCTGATTTTAGTAGCAGGATAGATTCATTTGTTCGAGTGTTAGGGTTCAATGTCTCTGGGTCAGTAGTTGCCCGTCAGCAGGAGCGGGTTGACGGTTCGAAGACAAGCGGTATCCACGGCATATTCAGTACGGTGGTTGTCCGAGACAAGAAGCCTTGCGAGTTCTCCTCTGTGGATCCCCTCATTCCATTTGCGGAGATATTCGGACATGAGAAGGGAGCATGTTCTACTCTAAGAGTTAGAGATGCACATAGGAATAGGTTTGTGTTAGTCCAGCAGAAGAAGTGCGTTGTAAATACCGCTTTGCCGGTTCATGTATTTAGGTTTGTTTATTCTGTTAGGTTCAATAGATACCCTCTCTGGGTATCATTCAAGGACACAACTGATGTAGAACCTAGTGGTCTCTACAGCAACGTGTCAAAGAACGCACTTCTTGTTTATTATGTCTGGTTGTGTGATTCCAATGTAACTTCCGACATTCATGTAAAGTACGACCTTGACTATATTGGATAA |
|
Protein Sequence
|
MRIPIRTPMGSNRDRRGGSGSIFRWNNPYSRYFGRRVGTRVYGMPFGGSSVPRRHVSNSVRRNLFSDHQDKGRKRRNSIEEVHDGTDYLLCNNTSKVSYISYPAMCRSDFSSRIDSFVRVLGFNVSGSVVARQQERVDGSKTSGIHGIFSTVVVRDKKPCEFSSVDPLIPFAEIFGHEKGACSTLRVRDAHRNRFVLVQQKKCVVNTALPVHVFRFVYSVRFNRYPLWVSFKDTTDVEPSGLYSNVSKNALLVYYVWLCDSNVTSDIHVKYDLDYIG |
|
NCBI Accession
|
YP_717096.1
|
|
Location
|
1013-1849 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein in DNA-B |
|
Coding Region
|
ATGGAAACTAACCACAACACTCTTGCATATTCCACGTCGGACAGGACAGAGTTTCAACTGTCCAATGAAAAAACAGAGGTGACATTGTTGTTCCCTTCCACTCTTGATCAAAAATTGTCCAAACTCATGGGCAAATGTTTGAGAATTGACCATGTCATTCTTGAATACAGGAATCAGGTTCCTGTAAATGCAACTGGACACGTCATAATAGAGATGCACGACACAAGACTGCACGAAGGAGACTCGAAACAGGCGGAGTTCACAATTCCAATTGGGTGCAACTGCAATATACACTACTACTCCTCTTCGTATTTTTCCCCGAAAGACCCTAATCCTTGGAAGGTTCTATACAGGGTTGACGACACGAATGTCGTCAACGGGGTACATTTCTGTAGGATGCAAGGCAAGCTGAAGATGTCTTCAGCTAAACAGTCCACAGAAATCCAGTTCAAATCCCCCAAGATTGAAATATTGTCCAAGGCGTTTAACATGACCAACATTGATTTCTGGACGGTGCCCCATTCTCAGGTTTCCAGGAAACCTGTCCAAGGACTGACCAACATGAGGTCGCAGTCATGTCGATACACAACTCCTGCAATTCTTCCTGGGCAGACATGGGCTTCTGCAAGTGCAATTGGGAATGAAGATCAAGACGATCTTCCATACAGAGGACTGCACCGGCTGCAAGACCAGACACTAGACCCGGGACCATCTGCCTCAGACGTTGTTGTGAATAACAACAAGATTAACGACGATGTAATTAACATTATCAAAAAAACTGTAGAGTTGTGTATGGAAGGCAGTAATGTAACTTCGAATGCAAAACCGATCAAATAA |
|
Protein Sequence
|
METNHNTLAYSTSDRTEFQLSNEKTEVTLLFPSTLDQKLSKLMGKCLRIDHVILEYRNQVPVNATGHVIIEMHDTRLHEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWKVLYRVDDTNVVNGVHFCRMQGKLKMSSAKQSTEIQFKSPKIEILSKAFNMTNIDFWTVPHSQVSRKPVQGLTNMRSQSCRYTTPAILPGQTWASASAIGNEDQDDLPYRGLHRLQDQTLDPGPSASDVVVNNNKINDDVINIIKKTVELCMEGSNVTSNAKPIK |