Bean bushy stunt virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_018589415.1 |
| Isolate |
Argentina |
| Release date |
2021/6/1 |
| Submitter |
Reyna,P., Bejerman,N., Laguna,G., Rodriguez Pardina,P. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
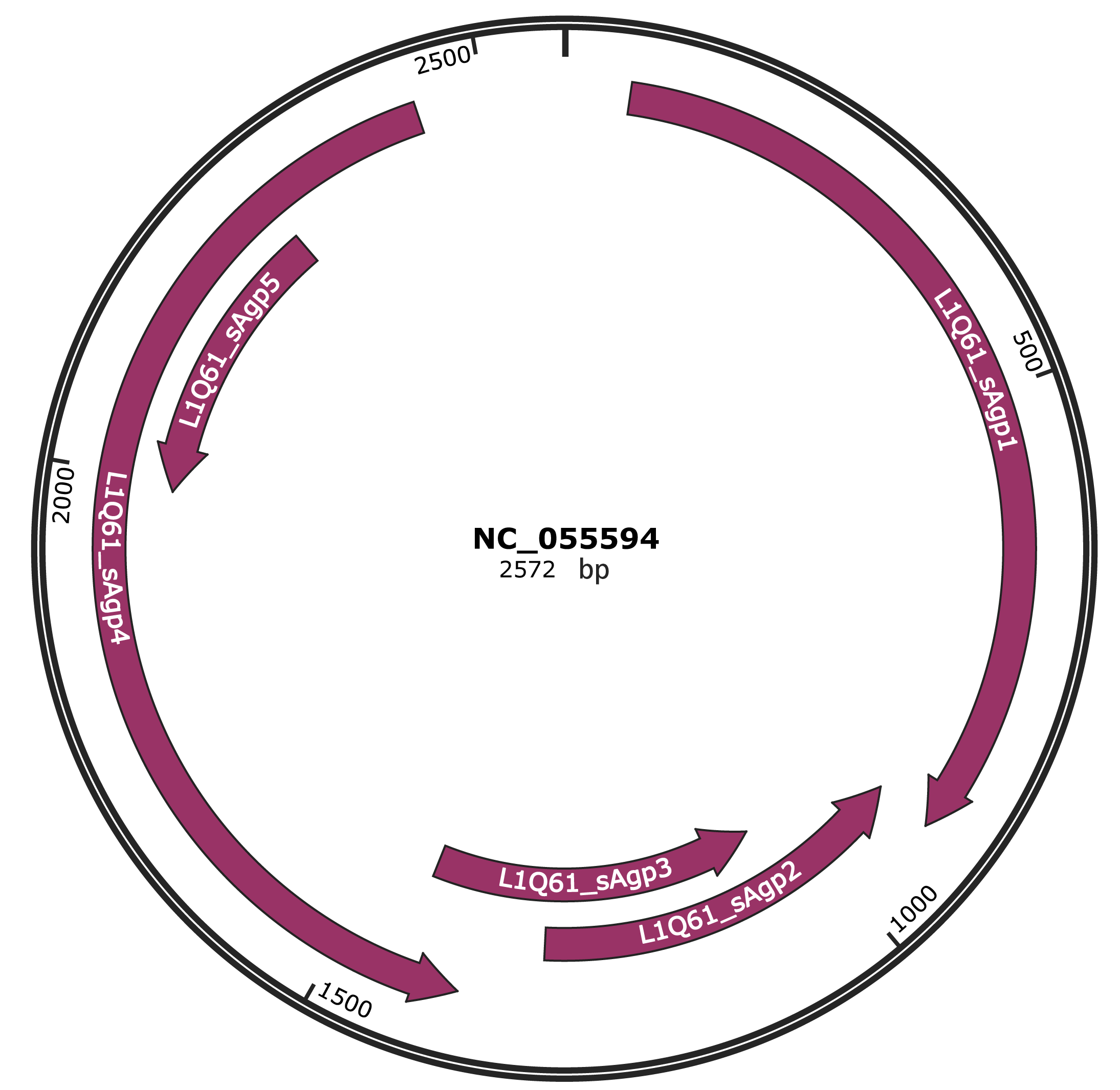
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTACTTATACTGGCCCACAACTAACTGTACTCACCAATGAGAATGCGTCTGACGAGTCTAGATATTTGTAACTTGGTCGCTAAGTTGTGGGCCTACGTCTTTAAATTGAATGACGTTGCCCAAATGCTTTACTTCAAAATGCCTAAGCGGGATGCCCCATGGCGTAACATGGCGGGGACCTCCAAGGTAACCCGTAATGCTAATTATTCGCCTCGTGGTGGGCTAAAGGTCGACAAGGCCTCTGCTTGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATCTATCGGACTCTCAGAGGCCCAGATGTTCCACGAGGCTGTGAAGGGCCTTGTAAGGTTCAATCCTACGAGCAACGTCATGACATCTCCCATGTTGGTAAGGTCATGTGTATTTCTGATGTTACTCGTGGTAACGGTATTACTCATCGTGTAGGAAAGCGTTTCTGTGTTAAGTCTGTGTACATATTAGGGAAGATCTGGATGGATGAGAACATCAAGTTGAAGAACCACACCAACAGTTGCATGTTTTGGTTGGTTCGAGACCGACGACCATATGGAACACCCATGGATTTCGGACAGGTATTCAATATGTTCGATAATGAGCCTAGCACTGCCACAGTCAAGAACGATCTACGTGATCGTTTCCAGGTTATGCACAAGTTCTACGCAAAGGTCACAGGTGGACAATATGCTAGTAACGAACAGGCGTTAGTCAAGCGTTTTTGGAAGGTCAACAATTATGTGGTTTATAACCACCAAGAAGCAGGGAAATACGAGAATCATACGGAAAACGCTTTATTATTGTATATGGCATGTACACATGCATCGAATCCTGTATACGCAACATTAAAAATTCGGATCTATTTCTATGATTCGATCACCAATTAATAAATTTTGAATTTTATTTCATGATTCTCAAGTACAACATTTACATAAGTTTTGTCTGTTGCAAAACTAACAGCTCTGATAACATTGTTAATACAAATAACACCTAAACGATCTAAATACAACATGACCAAATATTTAAATCTATTTAAATATGTCGTCCCAGAAACTGTCGTCAATGTCGTCCAGACTTGGAAATTGAGATAAGCCTTGTGGAGAGCCAACGCTTTCCTCAGGTTGTGGTTGAACCGGATCTGGACGTGGAAAATCCTCGTCCTGGTGTATACTGGGTCCTCTACGTGGTATATCCTGAAATAGAGGGGATTTTCTATCTCCCAGATATATACGCCACTCTCTGCTTGATGCGCAGTGATGCGTTCCCCGGTGCGTAAATCCATGGTCACTGCAGTTGATGTGAACGTAAATAGAGCAGCCACAAGGAAGGTCTATCCTTCTACGACGTGTTGCTCTTCTTTTAGCTGCTCTGTGCTGTGCTTTGATAGAGGGGGGCGTGGAGGAAGATAAATTTCGCATTATGAAGTGTCCACGATTTGAGAGATGCGTTTTCCTCTCTCTCAAGGAAATCTTTATAACTGGCCCCCTCTCCTGGATTGCACAGCACGATAGATGGGATCCCTCCTTTAATTTGAACTGGCTTTCCGTATTTGCAGTTTGATTGCCAGTCTCTTTGGGCCCCAATCAACTCTTTCCAATGCTTCAGCTTTAAATATTGCGGACTGACATCGTCAATGACGTTATACTCCACTGCATTGGAATAGACCTTTGAGTTAAAGTCGAGATGACCACTCAAATAATTATGTGGGCCTAGAGCACGTGCCCACATAGTCTTTCCGGTACGACTATCGCCCTCAATGATTATACTCACAGGTCTCGCCGGCCGCGCAGCGGCACCTCTCCCAAAATAATCGTCAGCCCAAGCTTTCATCTCATCTGGCACGTTAGTGAAGGAGGAGAGGTGAAACGGAGGAAGCCACGGTTCCGGAGCAACAGCAAACAACTTCTGGACATGTGTTCTTATTTTGTCCAGATGCAAAACATAATCTCTTGGCTGTTCTTCTCTTAATATATTGAGGGCCGTGGCTGCACAATCTGCGTTGAGAACCTTGGCATATGTATCGTTGGCAGATTGGCAACCTCCTCGAGCTGAACGTCCATCGACCTGGAAAACTCCATAATCAATGAAGTCTCCGTCTTTCTCCATATAGGTCTTGACATCTGAGGACGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTTGATGGGGAAACCAAGTCGAAGAATCTTTGATTCTGGCATCTGTATTTTCCTTCGAACTGGATGAGCACGTGTAAATGAGGTTCCCCATCTTCGTGTAATTCTCTTGTTACACGAATGAACTTCTTATTAGTCGGCGTTTTTAACGCTTGCAACTGAGAAAGAGCTTCCTCTTTCGTTAATGAACAATGAGGGTATGTGAGAAAGAAGTTCTTCGCGTTAACTGAGAAGCGCTTCGGTGGTGGCATATTTGTAATATGAGAATGATCCCCAATTGCCTCCCCTTGAAACTTGGTGAAATGAATTGGGGAATGGGGATCAATTTATAGTAGAGTCCATTATAATTTTATGGGACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087836.1
|
|
Location
|
60-911 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGAGAATGCGTCTGACGAGTCTAGATATTTGTAACTTGGTCGCTAAGTTGTGGGCCTACGTCTTTAAATTGAATGACGTTGCCCAAATGCTTTACTTCAAAATGCCTAAGCGGGATGCCCCATGGCGTAACATGGCGGGGACCTCCAAGGTAACCCGTAATGCTAATTATTCGCCTCGTGGTGGGCTAAAGGTCGACAAGGCCTCTGCTTGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATCTATCGGACTCTCAGAGGCCCAGATGTTCCACGAGGCTGTGAAGGGCCTTGTAAGGTTCAATCCTACGAGCAACGTCATGACATCTCCCATGTTGGTAAGGTCATGTGTATTTCTGATGTTACTCGTGGTAACGGTATTACTCATCGTGTAGGAAAGCGTTTCTGTGTTAAGTCTGTGTACATATTAGGGAAGATCTGGATGGATGAGAACATCAAGTTGAAGAACCACACCAACAGTTGCATGTTTTGGTTGGTTCGAGACCGACGACCATATGGAACACCCATGGATTTCGGACAGGTATTCAATATGTTCGATAATGAGCCTAGCACTGCCACAGTCAAGAACGATCTACGTGATCGTTTCCAGGTTATGCACAAGTTCTACGCAAAGGTCACAGGTGGACAATATGCTAGTAACGAACAGGCGTTAGTCAAGCGTTTTTGGAAGGTCAACAATTATGTGGTTTATAACCACCAAGAAGCAGGGAAATACGAGAATCATACGGAAAACGCTTTATTATTGTATATGGCATGTACACATGCATCGAATCCTGTATACGCAACATTAAAAATTCGGATCTATTTCTATGATTCGATCACCAATTAA |
|
Protein Sequence
|
MRMRLTSLDICNLVAKLWAYVFKLNDVAQMLYFKMPKRDAPWRNMAGTSKVTRNANYSPRGGLKVDKASAWVNRPMYRKPRIYRTLRGPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSCMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_010087837.1
|
|
Location
|
908-1306 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTTACGCACCGGGGAACGCATCACTGCGCATCAAGCAGAGAGTGGCGTATATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACCACGTAGAGGACCCAGTATACACCAGGACGAGGATTTTCCACGTCCAGATCCGGTTCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAGGCTTATCTCAATTTCCAAGTCTGGACGACATTGACGACAGTTTCTGGGACGACATATTTAAATAGATTTAAATATTTGGTCATGTTGTATTTAGATCGTTTAGGTGTTATTTGTATTAACAATGTTATCAGAGCTGTTAGTTTTGCAACAGACAAAACTTATGTAAATGTTGTACTTGAGAATCATGAAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDLRTGERITAHQAESGVYIWEIENPLYFRIYHVEDPVYTRTRIFHVQIRFNHNLRKALALHKAYLNFQVWTTLTTVSGTTYLNRFKYLVMLYLDRLGVICINNVIRAVSFATDKTYVNVVLENHEIKFKIY |
|
NCBI Accession
|
YP_010087838.1
|
|
Location
|
1053-1442 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGAAATTTATCTTCCTCCACGCCCCCCTCTATCAAAGCACAGCACAGAGCAGCTAAAAGAAGAGCAACACGTCGTAGAAGGATAGACCTTCCTTGTGGCTGCTCTATTTACGTTCACATCAACTGCAGTGACCATGGATTTACGCACCGGGGAACGCATCACTGCGCATCAAGCAGAGAGTGGCGTATATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACCACGTAGAGGACCCAGTATACACCAGGACGAGGATTTTCCACGTCCAGATCCGGTTCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAGGCTTATCTCAATTTCCAAGTCTGGACGACATTGACGACAGTTTCTGGGACGACATATTTAAATAG |
|
Protein Sequence
|
MRNLSSSTPPSIKAQHRAAKRRATRRRRIDLPCGCSIYVHINCSDHGFTHRGTHHCASSREWRIYLGDRKSPLFQDIPRRGPSIHQDEDFPRPDPVQPQPEESVGSPQGLSQFPSLDDIDDSFWDDIFK |
|
NCBI Accession
|
YP_010087839.1
|
|
Location
|
1384-2439 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACCACCGAAGCGCTTCTCAGTTAACGCGAAGAACTTCTTTCTCACATACCCTCATTGTTCATTAACGAAAGAGGAAGCTCTTTCTCAGTTGCAAGCGTTAAAAACGCCGACTAATAAGAAGTTCATTCGTGTAACAAGAGAATTACACGAAGATGGGGAACCTCATTTACACGTGCTCATCCAGTTCGAAGGAAAATACAGATGCCAGAATCAAAGATTCTTCGACTTGGTTTCCCCATCAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCGTCCTCAGATGTCAAGACCTATATGGAGAAAGACGGAGACTTCATTGATTATGGAGTTTTCCAGGTCGATGGACGTTCAGCTCGAGGAGGTTGCCAATCTGCCAACGATACATATGCCAAGGTTCTCAACGCAGATTGTGCAGCCACGGCCCTCAATATATTAAGAGAAGAACAGCCAAGAGATTATGTTTTGCATCTGGACAAAATAAGAACACATGTCCAGAAGTTGTTTGCTGTTGCTCCGGAACCGTGGCTTCCTCCGTTTCACCTCTCCTCCTTCACTAACGTGCCAGATGAGATGAAAGCTTGGGCTGACGATTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGCGAGACCTGTGAGTATAATCATTGAGGGCGATAGTCGTACCGGAAAGACTATGTGGGCACGTGCTCTAGGCCCACATAATTATTTGAGTGGTCATCTCGACTTTAACTCAAAGGTCTATTCCAATGCAGTGGAGTATAACGTCATTGACGATGTCAGTCCGCAATATTTAAAGCTGAAGCATTGGAAAGAGTTGATTGGGGCCCAAAGAGACTGGCAATCAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGGATCCCATCTATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGTTATAAAGATTTCCTTGAGAGAGAGGAAAACGCATCTCTCAAATCGTGGACACTTCATAATGCGAAATTTATCTTCCTCCACGCCCCCCTCTATCAAAGCACAGCACAGAGCAGCTAA |
|
Protein Sequence
|
MPPPKRFSVNAKNFFLTYPHCSLTKEEALSQLQALKTPTNKKFIRVTRELHEDGEPHLHVLIQFEGKYRCQNQRFFDLVSPSRSAHFHPNIQGAKSSSDVKTYMEKDGDFIDYGVFQVDGRSARGGCQSANDTYAKVLNADCAATALNILREEQPRDYVLHLDKIRTHVQKLFAVAPEPWLPPFHLSSFTNVPDEMKAWADDYFGRGAAARPARPVSIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSKVYSNAVEYNVIDDVSPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEREENASLKSWTLHNAKFIFLHAPLYQSTAQSS |
|
NCBI Accession
|
YP_010087840.1
|
|
Location
|
1989-2282 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCATTTACACGTGCTCATCCAGTTCGAAGGAAAATACAGATGCCAGAATCAAAGATTCTTCGACTTGGTTTCCCCATCAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCGTCCTCAGATGTCAAGACCTATATGGAGAAAGACGGAGACTTCATTGATTATGGAGTTTTCCAGGTCGATGGACGTTCAGCTCGAGGAGGTTGCCAATCTGCCAACGATACATATGCCAAGGTTCTCAACGCAGATTGTGCAGCCACGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGNLIYTCSSSSKENTDARIKDSSTWFPHQGQHISIRTFRELNRPQMSRPIWRKTETSLIMEFSRSMDVQLEEVANLPTIHMPRFSTQIVQPRPSIY |