Pepper leafroll virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004787035.1 |
| Isolate |
Peru: La Libertad, San Carlos Alto |
| Release date |
2019/6/28 |
| Submitter |
Martinez-Ayala,A., Sanchez-Campos,S., Aragon-Caballero,L., Navas-Castillo,J., Moriones,E. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
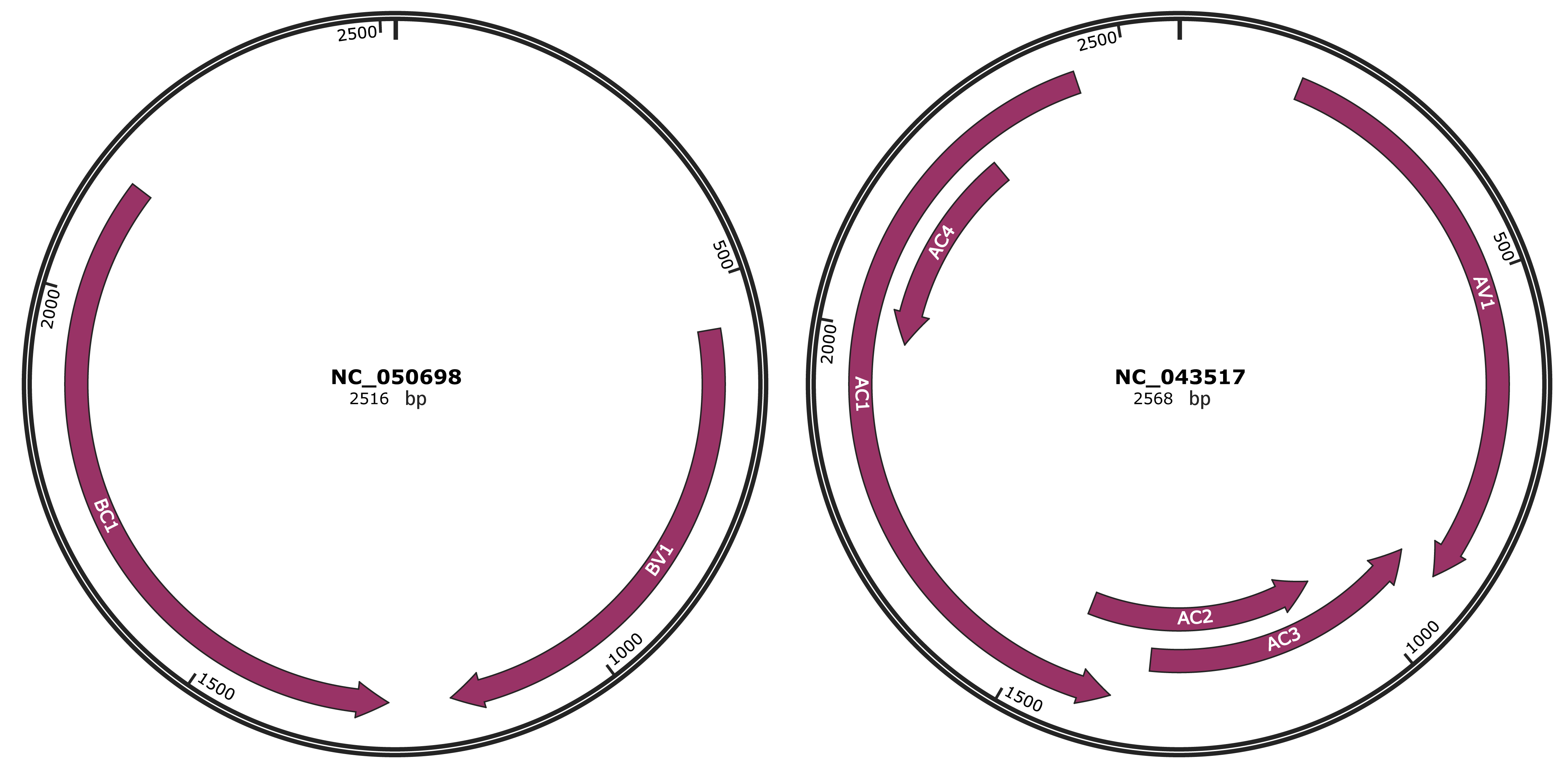
JBrowse
Genome
ACCGGATGGCCGCCGGGGACCGCTTTATCTTTGCACGTGGTGCAATCCCTGCCCTCCCTTGGCGTTAGTTTAAGGCCTAGAGATTTGCGAATTCAATTGAGCGCATTTTTGAGGTCCGCGAATTCAGTTAAGCGCATTATTTGAAATCCGCCCGTCTAGTCGTCCTCTACTTTAATTTGAATTAAAGCGTAGCTTTTCTATATAACCAATGAATTCGCGATTGTGGAATCTATATAGTCGTTATAAACCTTCGAATGTCGTGACGTTATATTTGTGTATGATTCCACTACGTACTACATATGACCTGGACCAATCACATTTCTTGTGTATAGTCAATTTAACAAGTGATTAATTCATTGAGCATTATATATGACCTATGGAATGAGTTATGAGTCATATGCATATTTGGAATCTCACTATGAATTCATGGAAATATGGACGTCGCGTTACTTGTACTGGTCGTCGAAATACTAATAGGTATTCCAAATATAAACGTACATATGGTGTGAAAAGGACCCAGTTGAACCAGGGTCCACTACTTCGAATAAGGGCCATGAAGATATGCCAGTGTCAGCCCAACGGATACATGAGAACCAATATGGGCCTGAGTTTGTTATGGCCCAAAATACAGCCATATCTAGTTACATCACATATCCTACACTTGGTAAGGGTGACTCTTGTCGATCACGGAGTTATATTAAGTTAAAACGTCTGCGTTTCAAAGGTACACTAAAGATTGAACGTATTAATCCGGATGTGAATATGCAAGATTTAAGCCCGAAGATTGAAGGTGTATTTTCTATGGTAATTGTTGTTGATCGTAAACCTCATCTTGGGGCATCTGGACGTCTGCATACGTTTGATGAACTATTTGGAGCAAGGATACATAGCCATGGGAATTTGGTTGTTACTGCTGCACAGAGAGACCGTTTTTATATACGGCATGTGTTTAAGCAAGTTATGTCCGTTGAAAATGATTCTACAATGGTCGATTTGGAAGGAGTGACATATTTATCGAACAGGCGTTATAATTGCTGGTCTACATTTAAAGACGTTGATCGTGATTCATGTAATGGGGTTTATGATAATATTAGCAAAAATGCTGTGTTAGTCTATTATTGCTGGATGACGGATATTCTATCTAAGGCATCGACATTTGTATCATTTGATCTTGATTATATTGGATGAAATAATAACCATTTAACATATGACATGAATTTTTACTATTTAAAAAGAATTTGATATAAAAAACAAGTGCATAAGGCTTTATTTCAAGGATTTGGTCTCAGTAGGAGTACAGTTATTTTTAATACATTCCTGGGCCGCAGTCTTAACCAATTCATTTAACTGGGCCATAGACATTGTTATGTTGGACTCTGCTCGTCGCGCACCTACAATTGATGCGGAGTCACCTGGGTCTAATAAGCTCGTACCTATTCTGTGTAGTTCTTTGTAAGGATGTAGTGCGCTCTCAATATCAGAGTCCGCATCTGTATGACCAGACCCGATAGTACTTCGTGTTGCCCATGTTTCACCTGGTGCTATTGTAATTGGGCTGTGTAGCCCATATCTTGAACTGGATGCGGACCTGATGAGTTTCCTTTCATATTTGCCGTACCCAACATGCGAGAAATCTATATCTTTCTCGGTAAACTGCTTAGACAATATTTTTACAGTTGGGGGTCTGAAAGGAATATCCACGGAATGTTTAGCCGTCGATAATTTCAGCTTGCCTTTGAATTTGGCAAAATGTGTCCTTTGATGAACATTCGTGTCGCTAACTCTATAATATAATTTCCATGGAATTGGGTCTTTAAGCGAAAAGAATGACGAAGAGAAATAGTGGAGGTCTATGTTACATCTTATGGGAAATGTCCATGACGCTTGCAATGACTCATTATCAGTCATTCTTTTATCATGAATCTCCACTATTACAGAACCAGATGCGTTAATCGGTACTTGTTGTCTGTATTCAATGACGCAATGGTCAATTTTCATACAGCTACGACTCAGTCTTGCAGTAAGTTGTGAAGCTGTTGAAGGAAACTGCAAAATAATCTCAGTTAAGTCGTGAGATAATTGATATTCATCACGTTGAGATTCGACATAATTAAACGCTGTTGGTGGGAAATCTAGCTGTGAACCCATACTGCTTGATGCTACTAATATGAAAATTCGGCCGCGCAGCTGAACTGGAACCTGAAATCAATATGAGGGAATAAAATAAGATTTGGTTATGTGAATATGGAACTCGTAACAATCAGCGGTTGTCTAAAGTTATATGCATATATGTTATTTTGCAGAACGTTAATCTTGTTTATATAGAGTGATATGAAATGTTATACTATTTTCTAATATGTTGAATAATTTCCGATAAGGGCATTTTAGGGAATATTGAATGAGTACCGATTGCTCGCCCTCAAACTTGGCGAAATGAATTGGGGAATGGTACTCAATTTATAGTAGAGTCATTTAATTTTTATGCGACACGTGGCGGCCATCCGTTATATAATATT
ACCGGATGGCCGCCTGACCCCCTTTTATAGTTGGCCCACAACGAACGTACGATCCAATGAGAATGCGTCTGGCACGTCTAATTAAATGACTTTGACCCTAAGTTGTGGGCCTATAAATTTGAAATATGTGACGTTGCACTCTTGCCTTTAATTCAAAATGCCAAAGCGGGATGCCCCATGGCGTACTATGGCGGGGACCTCCAAGGTGTCTCGTAATGCCAACTATTCCCCTCGTGGTGGTCCAAAGTTTGACAAGGCCTCTGCTTGGGTGAACAGGCCCATGTATAGGAAGCCCAGGATTTACCGGACTCTACGAGGGCCCGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTGCAGTCTTACGAGCAACGTCATGATATTTCCCATGTTGGTAAAGTTATGTGTATATCTGATGTCACGCGTGGTAACGGTATTACCCATCGTGTAGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTTTAGGTAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTGATGTTCTGGTTGGTGAGAGACCGTAGACCTTATTCCACGCCTATGGACTTTGGTCAAGTATTCAACATGTTTGATAATGAACCCAGTACTGCCACGGTGAAAAATGATTTGCGTGACCGTTATCAAGTTATGCACAAGTTTTATGCTAAGGTTACTGGTGGACAATATGCAAGTAACGAACAGGCGTTGGTCAAACGTTTCTGGAAGGTTAACAACTATGTGGTCTACAACCATCAGGAAGCGGGGAAATACGAGAATCATACGGAGAATGCGTTACTATTGTATATGGCATGTACTCATGCGTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATATTAAATTAATAAATTTTGAATTTTATTTCATGATTCTCAAGTACATAATTTACATATGCTCTGTCTGTTGCGTAACGAACAGCTCTGATTACATTGTTGAGTCCAATAACACCTACTCTATCTAAAAACGACAATACTAAATATTTAAATCTACTTAAATATATCTGCCCAGAAGCTGTCGTCAATGTCGTCCAAACTTGGAAATTGAGAAATGCCTTGTGGAGATCCAACGCTTTCCTCAGGTTGTGGTTGAAGCGTATCTGGACGTGGAATATTGTTGTCCTCGTGTAGAGAGGCTTCTCTACGTTGGTTATTTTGAAATAGAGGGGATTTTCTATCTCCCAGGTATATACGCCATTCTCTGCTTGAGGCACAGTGATGAGTTCCCCTGTGCGTAAATCCGTCGTTGCAGCAGTTGATGTGGACATAAATAGAACACCCACAATTAAGGTCGATGCGTCTACGTCTAGGTGCTCTACGTTTCGCTGCTGTGTGCTGTGCTTTGATACAAGGGGGCGTTGAGAGTGATGAATTTCGCATTATGGAGTGTCCACGATTTTAGCGATGCATTTTCCTGTCTGTCAAGGAAATATTTATAACTGGCCCCCTCTCCTGGATTGCACAGCACGATAGCGGGAATTCCTCCTTTAATTTGAACTGGCTTCCCGTATTTGCAGTTTGATTGCCAGTCCTTTTGAGCCCCAATTATCTCTTTCCAATGTTTCATCTTTAAATATTGCGGACTGACATCATCAATGACGTTGTACTCTGCATTATTTGAGTACACATTTGAATTAAAGTCGAGATGTCCGCTTAAATAATTATGTGGCCCTAGTGCACGCGCCCACATTGTCTTCCCTGTTCGACTATCACCTTCGATGATGATACTAATAGGTCTTTCCGGCCGCGCAGCGGCACCTCTCCCAAAATAATCATCAGCCCAATCTTGCATTTCTTTTGGGACATTATTGAACGAGGAGAGGTGGAATGGAGGTACCCAAGGTTCTGGAGCCTTTTGAAATAACTTATTAATATGCCCCCTAATTTTGTCTAAATGAAGAACATAATCTCTTGGCTGTTCTTCTCTTAATATATTAAGTGCCGTTGATGCACACTGTGCATTGAGAACCTTGGCGTACGTATCATTGGCAGATTGGCAACCTCCTCTAGCTGATCTTCCATCGACTTGGAAAATTCCAAAATCAATGAAGTCTCCGTCTTTCTCCATGTAGGTCTTGACATCTGACGAGCTCTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTTGTTGGGGAGACCAAGTCGAAGAATCTTGGATTTTGGCATCTGAATTTTCCTTCGAACTGGATAAGCACGTGTAGATGAGGTTGCCCATCCTCATGGAGTTCTCTTGTAACGCGAATGAACTTCTTATTTGTTGGTGTATTGAGTTGCTGTATCTGTGCAAGAGCTTCTTCTTTGGTTAATGGACAATGAGGGTATGTGAGGAAGAAGTTCTTCGCACTTACTTGAAAACGCTTTGGTAAGGGCATTTTAGGGAATATTGAATGAGTACCGATTGCTCGCCCTCAAACTTGGCGAAATGAATTGGGGAATGGTACTCAATTTATAGTAGAGTCATTTAATTTTTATGCGACACGTGGCGGCCATCCGTTATATAATATT
Gene Information
|
NCBI Accession
|
YP_009927293.1
|
|
Location
|
562-1188 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGCCAGTGTCAGCCCAACGGATACATGAGAACCAATATGGGCCTGAGTTTGTTATGGCCCAAAATACAGCCATATCTAGTTACATCACATATCCTACACTTGGTAAGGGTGACTCTTGTCGATCACGGAGTTATATTAAGTTAAAACGTCTGCGTTTCAAAGGTACACTAAAGATTGAACGTATTAATCCGGATGTGAATATGCAAGATTTAAGCCCGAAGATTGAAGGTGTATTTTCTATGGTAATTGTTGTTGATCGTAAACCTCATCTTGGGGCATCTGGACGTCTGCATACGTTTGATGAACTATTTGGAGCAAGGATACATAGCCATGGGAATTTGGTTGTTACTGCTGCACAGAGAGACCGTTTTTATATACGGCATGTGTTTAAGCAAGTTATGTCCGTTGAAAATGATTCTACAATGGTCGATTTGGAAGGAGTGACATATTTATCGAACAGGCGTTATAATTGCTGGTCTACATTTAAAGACGTTGATCGTGATTCATGTAATGGGGTTTATGATAATATTAGCAAAAATGCTGTGTTAGTCTATTATTGCTGGATGACGGATATTCTATCTAAGGCATCGACATTTGTATCATTTGATCTTGATTATATTGGATGA |
|
Protein Sequence
|
MPVSAQRIHENQYGPEFVMAQNTAISSYITYPTLGKGDSCRSRSYIKLKRLRFKGTLKIERINPDVNMQDLSPKIEGVFSMVIVVDRKPHLGASGRLHTFDELFGARIHSHGNLVVTAAQRDRFYIRHVFKQVMSVENDSTMVDLEGVTYLSNRRYNCWSTFKDVDRDSCNGVYDNISKNAVLVYYCWMTDILSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_009927294.1
|
|
Location
|
1267-2148 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGGTTCACAGCTAGATTTCCCACCAACAGCGTTTAATTATGTCGAATCTCAACGTGATGAATATCAATTATCTCACGACTTAACTGAGATTATTTTGCAGTTTCCTTCAACAGCTTCACAACTTACTGCAAGACTGAGTCGTAGCTGTATGAAAATTGACCATTGCGTCATTGAATACAGACAACAAGTACCGATTAACGCATCTGGTTCTGTAATAGTGGAGATTCATGATAAAAGAATGACTGATAATGAGTCATTGCAAGCGTCATGGACATTTCCCATAAGATGTAACATAGACCTCCACTATTTCTCTTCGTCATTCTTTTCGCTTAAAGACCCAATTCCATGGAAATTATATTATAGAGTTAGCGACACGAATGTTCATCAAAGGACACATTTTGCCAAATTCAAAGGCAAGCTGAAATTATCGACGGCTAAACATTCCGTGGATATTCCTTTCAGACCCCCAACTGTAAAAATATTGTCTAAGCAGTTTACCGAGAAAGATATAGATTTCTCGCATGTTGGGTACGGCAAATATGAAAGGAAACTCATCAGGTCCGCATCCAGTTCAAGATATGGGCTACACAGCCCAATTACAATAGCACCAGGTGAAACATGGGCAACACGAAGTACTATCGGGTCTGGTCATACAGATGCGGACTCTGATATTGAGAGCGCACTACATCCTTACAAAGAACTACACAGAATAGGTACGAGCTTATTAGACCCAGGTGACTCCGCATCAATTGTAGGTGCGCGACGAGCAGAGTCCAACATAACAATGTCTATGGCCCAGTTAAATGAATTGGTTAAGACTGCGGCCCAGGAATGTATTAAAAATAACTGTACTCCTACTGAGACCAAATCCTTGAAATAA |
|
Protein Sequence
|
MGSQLDFPPTAFNYVESQRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINASGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRPPTVKILSKQFTEKDIDFSHVGYGKYERKLIRSASSSRYGLHSPITIAPGETWATRSTIGSGHTDADSDIESALHPYKELHRIGTSLLDPGDSASIVGARRAESNITMSMAQLNELVKTAAQECIKNNCTPTETKSLK |
|
NCBI Accession
|
YP_009666355.1
|
|
Location
|
158-907 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCAAAGCGGGATGCCCCATGGCGTACTATGGCGGGGACCTCCAAGGTGTCTCGTAATGCCAACTATTCCCCTCGTGGTGGTCCAAAGTTTGACAAGGCCTCTGCTTGGGTGAACAGGCCCATGTATAGGAAGCCCAGGATTTACCGGACTCTACGAGGGCCCGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTGCAGTCTTACGAGCAACGTCATGATATTTCCCATGTTGGTAAAGTTATGTGTATATCTGATGTCACGCGTGGTAACGGTATTACCCATCGTGTAGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTTTAGGTAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTGATGTTCTGGTTGGTGAGAGACCGTAGACCTTATTCCACGCCTATGGACTTTGGTCAAGTATTCAACATGTTTGATAATGAACCCAGTACTGCCACGGTGAAAAATGATTTGCGTGACCGTTATCAAGTTATGCACAAGTTTTATGCTAAGGTTACTGGTGGACAATATGCAAGTAACGAACAGGCGTTGGTCAAACGTTTCTGGAAGGTTAACAACTATGTGGTCTACAACCATCAGGAAGCGGGGAAATACGAGAATCATACGGAGAATGCGTTACTATTGTATATGGCATGTACTCATGCGTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATATTAAATTAA |
|
Protein Sequence
|
MPKRDAPWRTMAGTSKVSRNANYSPRGGPKFDKASAWVNRPMYRKPRIYRTLRGPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYSTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
YP_009666356.1
|
|
Location
|
904-1326 |
|
Gene Name
|
AC3 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGTCCACATCAACTGCTGCAACGACGGATTTACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTATATACCTGGGAGATAGAAAATCCCCTCTATTTCAAAATAACCAACGTAGAGAAGCCTCTCTACACGAGGACAACAATATTCCACGTCCAGATACGCTTCAACCACAACCTGAGGAAAGCGTTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATATATTTAAGTAGATTTAAATATTTAGTATTGTCGTTTTTAGATAGAGTAGGTGTTATTGGACTCAACAATGTAATCAGAGCTGTTCGTTACGCAACAGACAGAGCATATGTAAATTATGTACTTGAGAATCATGAAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MSTSTAATTDLRTGELITVPQAENGVYTWEIENPLYFKITNVEKPLYTRTTIFHVQIRFNHNLRKALDLHKAFLNFQVWTTLTTASGQIYLSRFKYLVLSFLDRVGVIGLNNVIRAVRYATDRAYVNYVLENHEIKFKIY |
|
NCBI Accession
|
YP_009666357.1
|
|
Location
|
1049-1438 |
|
Gene Name
|
AC2 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGCGAAATTCATCACTCTCAACGCCCCCTTGTATCAAAGCACAGCACACAGCAGCGAAACGTAGAGCACCTAGACGTAGACGCATCGACCTTAATTGTGGGTGTTCTATTTATGTCCACATCAACTGCTGCAACGACGGATTTACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTATATACCTGGGAGATAGAAAATCCCCTCTATTTCAAAATAACCAACGTAGAGAAGCCTCTCTACACGAGGACAACAATATTCCACGTCCAGATACGCTTCAACCACAACCTGAGGAAAGCGTTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATATATTTAAGTAG |
|
Protein Sequence
|
MRNSSLSTPPCIKAQHTAAKRRAPRRRRIDLNCGCSIYVHINCCNDGFTHRGTHHCASSREWRIYLGDRKSPLFQNNQRREASLHEDNNIPRPDTLQPQPEESVGSPQGISQFPSLDDIDDSFWADIFK |
|
NCBI Accession
|
YP_009666358.1
|
|
Location
|
1374-2435 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCCTTACCAAAGCGTTTTCAAGTAAGTGCGAAGAACTTCTTCCTCACATACCCTCATTGTCCATTAACCAAAGAAGAAGCTCTTGCACAGATACAGCAACTCAATACACCAACAAATAAGAAGTTCATTCGCGTTACAAGAGAACTCCATGAGGATGGGCAACCTCATCTACACGTGCTTATCCAGTTCGAAGGAAAATTCAGATGCCAAAATCCAAGATTCTTCGACTTGGTCTCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAATGATACGTACGCCAAGGTTCTCAATGCACAGTGTGCATCAACGGCACTTAATATATTAAGAGAAGAACAGCCAAGAGATTATGTTCTTCATTTAGACAAAATTAGGGGGCATATTAATAAGTTATTTCAAAAGGCTCCAGAACCTTGGGTACCTCCATTCCACCTCTCCTCGTTCAATAATGTCCCAAAAGAAATGCAAGATTGGGCTGATGATTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATCATCGAAGGTGATAGTCGAACAGGGAAGACAATGTGGGCGCGTGCACTAGGGCCACATAATTATTTAAGCGGACATCTCGACTTTAATTCAAATGTGTACTCAAATAATGCAGAGTACAACGTCATTGATGATGTCAGTCCGCAATATTTAAAGATGAAACATTGGAAAGAGATAATTGGGGCTCAAAAGGACTGGCAATCAAACTGCAAATACGGGAAGCCAGTTCAAATTAAAGGAGGAATTCCCGCTATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGTTATAAATATTTCCTTGACAGACAGGAAAATGCATCGCTAAAATCGTGGACACTCCATAATGCGAAATTCATCACTCTCAACGCCCCCTTGTATCAAAGCACAGCACACAGCAGCGAAACGTAG |
|
Protein Sequence
|
MPLPKRFQVSAKNFFLTYPHCPLTKEEALAQIQQLNTPTNKKFIRVTRELHEDGQPHLHVLIQFEGKFRCQNPRFFDLVSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDFIDFGIFQVDGRSARGGCQSANDTYAKVLNAQCASTALNILREEQPRDYVLHLDKIRGHINKLFQKAPEPWVPPFHLSSFNNVPKEMQDWADDYFGRGAAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSNVYSNNAEYNVIDDVSPQYLKMKHWKEIIGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKYFLDRQENASLKSWTLHNAKFITLNAPLYQSTAHSSET |
|
NCBI Accession
|
YP_009666359.1
|
|
Location
|
1985-2284 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAGGATGGGCAACCTCATCTACACGTGCTTATCCAGTTCGAAGGAAAATTCAGATGCCAAAATCCAAGATTCTTCGACTTGGTCTCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAATGATACGTACGCCAAGGTTCTCAATGCACAGTGTGCATCAACGGCACTTAATATATTAA |
|
Protein Sequence
|
MRMGNLIYTCLSSSKENSDAKIQDSSTWSPQQGQHISIQTFRELRARQMSRPTWRKTETSLILEFSKSMEDQLEEVANLPMIRTPRFSMHSVHQRHLIY |