Pepper leaf curl Lahore virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000894415.1 |
| Isolate |
Pakistan:Punjab, Lahore |
| Release date |
2015/2/22 |
| Submitter |
Tahir,M., Haider,M.S., Briddon,R.W. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
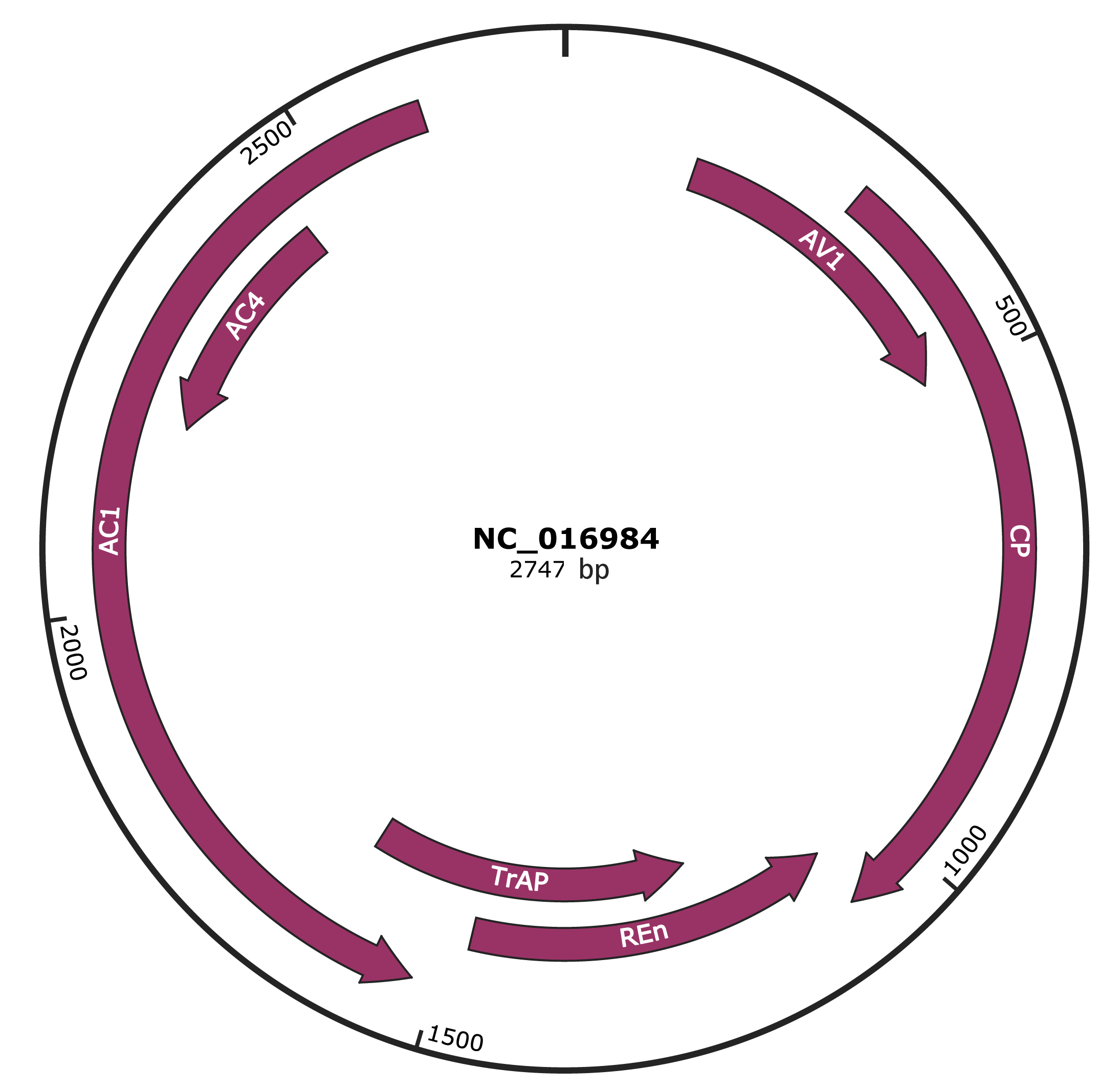
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTAAGTGGGCCCCACAACGCACGTGCTGACAAAGACATGTGGACCAATTAAAACCGCCCCTCATATCTTAATTGTTTCATGGTCCCCCCTATAAACTAGGGCTCCAAGTAGTGCACTCTTACCAATGTGGGATCCATTAGTAAACGAGTTTCCTGAAACCGTTCACGGTTTTAGGTGTATGTTAGCAGTTAAATATCTGCAGCTAGTAGAAAATACATATTCCCCAGACACTCTGGGCTACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGTCCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGTACGCCGCCGTCTCAACCTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGAGCATGGGCCAACAGGCCCATGAATCGGAAGCCCAGGATGTACAGGATGTACAGGAGCCCAGATGTTCCTAGGGGGTGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGTCTAGGCACGATGTAGTTCATATAGGGAAGGTTATGTGTATTAGTGATGTTACCCGTGGTACTGGTTTAACCCATAGAGTAGGTAGGCGTTTCTGTGTTAAGTCTGTGTATGTATTAGGGAAGATATGGATGGATGAGAATATCAAGACCAAGAATCACACGAATAGTGTGATGTTCTTTCTTGTCCGTGATCGTCGTCCTGTTGATAAACCACAAGATTTTGGAGAGGTGTTCAACATGTTTGACAACGAGCCTAGCACTGCAACCGTGAAGAATATGCATAGAGATCGTTATCAGGTCTTGAGGAAATGGCACGCAACGGTTACTGGTGGCCAGTACGCTTCGAAGGAACAGGCATTAGTTAAGAAGTTCGTTAGGGTTAACAATTATGTTGTGTATAACCAGCAGGAGGCTGGAAAATATGAAAATCACACAGAGAATGCTCTGATGTTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCGACGTTGAAGATACGGATCTATTTCTATGATTCAGTATCGAATTAATAAAGATTGAATTTTATTATATTTGAACTTTGTACATGAATTGTTTGTGCTAATACATGCCATAATACATGGTCGACAGCTCTAATTACATTGTTTATACTAATTACAGCTAAATTATTTAAAAACAGCAACACTTGGGTCCTAAATACCCTTAAGAAATGACCAGTCTGAGGCTGTAAGGTCGTCCAGATTCGGAAGGTTAGAAAACATTTGTGTATCCCCAACGCTTTCCTCAGGTTGTGATTGAACTGTATCTGCACGGTGATGATGTCTCGGTTCCTCAGGAATGGCCTGTTGTGGTGCTCGGTTATCTTGAAATATAGGGGATTTGTTATCTCCCAGATAAACACGCCATTCTCTGCCTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATAGCCGTGGCAGCGTAATGCGATGAAATATGAACAGCCGCAATCTAGGTCAACGCGACGACGCCTGGTCCCCTTCTTGGCTAGCCTGTGTTGCACTTTGATTGGAACCTGAGTAGAGTGGGCCTTCGAGGGTGATGAAGGTCGCATTCTTTAAAGCCCAATTTCTTAGTGCGCTATTTTTCTCTTCATCCAAGAACTCTTTATAGCTAGAATTGGGTCCTGGATTGCAGAGGAAGATAGCGGGAATTCCACCTTTAATTTGAACTGGCTTTCCGTATTTTGTGTTGGATTGCCAGTCCCTTTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGATAATGCGGATCAACGTCATTAATGACGTTATACCAGGCGTCGTTATTGTAGACCTTTGGGCTAAGGTCGAGATGTCCACACAAATAGTTGTGTGGTCCCAGGGACCTGGCCCACATTGTCTTCCCCGTTCTACTCTCACCCTCCAACACTATACTCATGGGTCTTAAAGGCCGCGCAGCGGCACTGACAACGTTCTGTGCAGCCCACTCCTCAAGTTCTGTCGGAACTTGATCAAAAGAAGAAGAACAACAAGGAGAAACATAAACCTCCGCTGGAGGTTGAAAAATCCTATCTAAATTAGATTTTAAATTATGATATTGAAAAATAAAATCTTTGAGGAGTTTCTCCCTTATTATTGCTAAAGCTGCTTCAGCCGAACCCGCATTTAAGGCCTCTGCTGCAGCATCATTAGCTGTCTGTTGACCTCCTCGACCATATCTTCCATCGATCTGAAACTGACCCCAGTCGATGTAATCACTGTCCTTCTCGATGTAGGACTTGACATCAGAGCTGGACTTAGCTCCCTGGAAGTTTGGGTGGAATTGGGAGGCGTTATTAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAACTTGGATTTACCTTTGAATTGGATGAGGGCGTGGATATGCAGAGACCCATCCTGGTGTTTCTCTTGTGCCACTCTGATAAATAGTTTATCAGATGGGCAATTTATCGACCGAAGAATGTCGAGCATTTGTTCTTTGGGTATTGGGCATTTGGGGTAAGTAAGGAAGATATTTTTTGCATTAACACAAAACGACTGCGTACGAGTCATATTGAATTGGGGACACTCAAAACTCTGAGGAATGGGGGACACTGGGGACGCTTTTATATGGTGTCCCCAAATTGCAAATTGGTAATTTGCACAACTTTAATTCAAATTCCCGAGAATCGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_005352656.1
|
|
Location
|
145-501 |
|
Gene Name
|
AV1 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCATTAGTAAACGAGTTTCCTGAAACCGTTCACGGTTTTAGGTGTATGTTAGCAGTTAAATATCTGCAGCTAGTAGAAAATACATATTCCCCAGACACTCTGGGCTACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGTCCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGTACGCCGCCGTCTCAACCTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGAGCATGGGCCAACAGGCCCATGAATCGGAAGCCCAGGATGTACAGGATGTACAGGAGCCCAGATGTTCCTAG |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLQLVENTYSPDTLGYDLIRDLISVIRARNYVEASSRYNHFHARFEGTPPSQPRQPICQPCCCPHCPRHKGKSMGQQAHESEAQDVQDVQEPRCS |
|
NCBI Accession
|
YP_005352657.1
|
|
Location
|
305-1075 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGTACGCCGCCGTCTCAACCTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGAGCATGGGCCAACAGGCCCATGAATCGGAAGCCCAGGATGTACAGGATGTACAGGAGCCCAGATGTTCCTAGGGGGTGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGTCTAGGCACGATGTAGTTCATATAGGGAAGGTTATGTGTATTAGTGATGTTACCCGTGGTACTGGTTTAACCCATAGAGTAGGTAGGCGTTTCTGTGTTAAGTCTGTGTATGTATTAGGGAAGATATGGATGGATGAGAATATCAAGACCAAGAATCACACGAATAGTGTGATGTTCTTTCTTGTCCGTGATCGTCGTCCTGTTGATAAACCACAAGATTTTGGAGAGGTGTTCAACATGTTTGACAACGAGCCTAGCACTGCAACCGTGAAGAATATGCATAGAGATCGTTATCAGGTCTTGAGGAAATGGCACGCAACGGTTACTGGTGGCCAGTACGCTTCGAAGGAACAGGCATTAGTTAAGAAGTTCGTTAGGGTTAACAATTATGTTGTGTATAACCAGCAGGAGGCTGGAAAATATGAAAATCACACAGAGAATGCTCTGATGTTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCGACGTTGAAGATACGGATCTATTTCTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNLDSPYASRAAAPIVRVTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGRRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_005352658.1
|
|
Location
|
1072-1476 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAACAAATCCCCTATATTTCAAGATAACCGAGCACCACAACAGGCCATTCCTGAGGAACCGAGACATCATCACCGTGCAGATACAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTATTTAGGACCCAAGTGTTGCTGTTTTTAAATAATTTAGCTGTAATTAGTATAAACAATGTAATTAGAGCTGTCGACCATGTATTATGGCATGTATTAGCACAAACAATTCATGTACAAAGTTCAAATATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAENGVFIWEITNPLYFKITEHHNRPFLRNRDIITVQIQFNHNLRKALGIHKCFLTFRIWTTLQPQTGHFLRVFRTQVLLFLNNLAVISINNVIRAVDHVLWHVLAQTIHVQSSNIIKFNLY |
|
NCBI Accession
|
YP_005352659.1
|
|
Location
|
1217-1621 |
|
Gene Name
|
TrAP |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTCATCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAACACAGGCTAGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGACCTAGATTGCGGCTGTTCATATTTCATCGCATTACGCTGCCACGGCTATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAACAAATCCCCTATATTTCAAGATAACCGAGCACCACAACAGGCCATTCCTGAGGAACCGAGACATCATCACCGTGCAGATACAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRPSSPSKAHSTQVPIKVQHRLAKKGTRRRRVDLDCGCSYFIALRCHGYGFTHRGTHHCSSGREWRVYLGDNKSPIFQDNRAPQQAIPEEPRHHHRADTVQSQPEESVGDTQMFSNLPNLDDLTASDWSFLKGI |
|
NCBI Accession
|
YP_005352660.1
|
|
Location
|
1524-2609 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGACTCGTACGCAGTCGTTTTGTGTTAATGCAAAAAATATCTTCCTTACTTACCCCAAATGCCCAATACCCAAAGAACAAATGCTCGACATTCTTCGGTCGATAAATTGCCCATCTGATAAACTATTTATCAGAGTGGCACAAGAGAAACACCAGGATGGGTCTCTGCATATCCACGCCCTCATCCAATTCAAAGGTAAATCCAAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATAACGCCTCCCAATTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCTGATGTCAAGTCCTACATCGAGAAGGACAGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGAAGATATGGTCGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCTTAAATGCGGGTTCGGCTGAAGCAGCTTTAGCAATAATAAGGGAGAAACTCCTCAAAGATTTTATTTTTCAATATCATAATTTAAAATCTAATTTAGATAGGATTTTTCAACCTCCAGCGGAGGTTTATGTTTCTCCTTGTTGTTCTTCTTCTTTTGATCAAGTTCCGACAGAACTTGAGGAGTGGGCTGCACAGAACGTTGTCAGTGCCGCTGCGCGGCCTTTAAGACCCATGAGTATAGTGTTGGAGGGTGAGAGTAGAACGGGGAAGACAATGTGGGCCAGGTCCCTGGGACCACACAACTATTTGTGTGGACATCTCGACCTTAGCCCAAAGGTCTACAATAACGACGCCTGGTATAACGTCATTAATGACGTTGATCCGCATTATCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAATTCCCGCTATCTTCCTCTGCAATCCAGGACCCAATTCTAGCTATAAAGAGTTCTTGGATGAAGAGAAAAATAGCGCACTAAGAAATTGGGCTTTAAAGAATGCGACCTTCATCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAACACAGGCTAGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGA |
|
Protein Sequence
|
MTRTQSFCVNAKNIFLTYPKCPIPKEQMLDILRSINCPSDKLFIRVAQEKHQDGSLHIHALIQFKGKSKFRNPRHFDVTHPNNASQFHPNFQGAKSSSDVKSYIEKDSDYIDWGQFQIDGRYGRGGQQTANDAAAEALNAGSAEAALAIIREKLLKDFIFQYHNLKSNLDRIFQPPAEVYVSPCCSSSFDQVPTELEEWAAQNVVSAAARPLRPMSIVLEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYNNDAWYNVINDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPAIFLCNPGPNSSYKEFLDEEKNSALRNWALKNATFITLEGPLYSGSNQSATQASQEGDQASSR |
|
NCBI Accession
|
YP_005352661.1
|
|
Location
|
2195-2452 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGTCTCTGCATATCCACGCCCTCATCCAATTCAAAGGTAAATCCAAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATAACGCCTCCCAATTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCTGATGTCAAGTCCTACATCGAGAAGGACAGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGAAGATATGGTCGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCTTAA |
|
Protein Sequence
|
MGLCISTPSSNSKVNPSSETPDISMSLTLITPPNSTQTSRELSPALMSSPTSRRTVITSTGVSFRSMEDMVEEVNRQLMMLQQRP |