Passionfruit severe leaf distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000883955.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Ferreira,S.S., Barros,D.R., de Almeida,M.R., Zerbini,F.M., Almeida,M.R. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
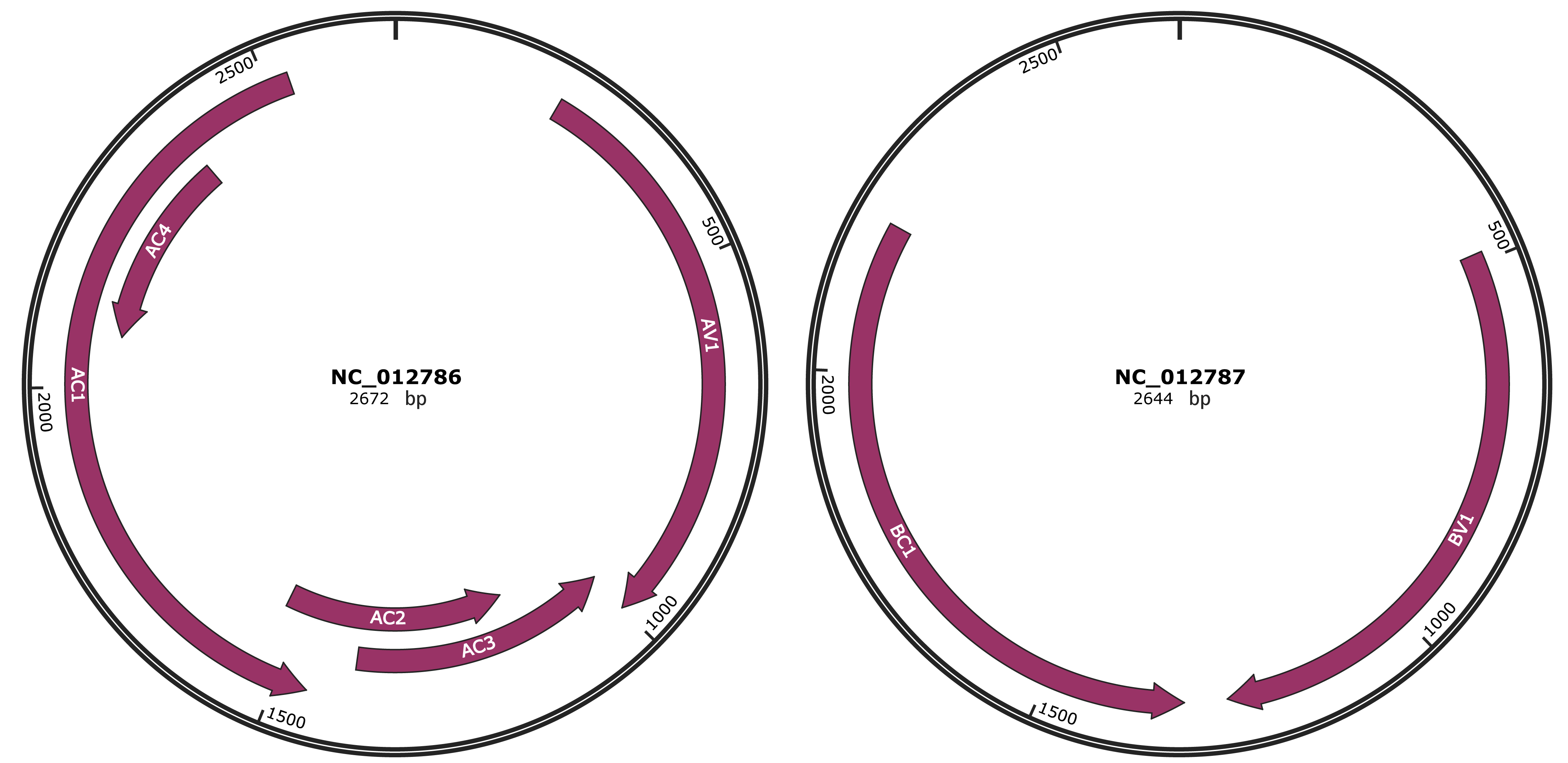
JBrowse
Genome
ACCGGATGGCCGCGCCCCTCCCGCTCCCGACCCGCTCCCGCAATCCGTGGCGCAATGTCGGCCACTATGATGAGTTGTCGCTTTCTTAGTGGTCCCAATGGATAATACGACAAATATGTTTGACCAATCATGACAGACATTCAAAGTTAAGATATTTTGAACAACTTGGCCGCTAAGTTGATATAAAGCGACAAGTATGATGGTGACTCGTCAGGTTAATTCAAAATGCCTAAGCGGGATGCTCCATGGCGTTTAATGGCGGGGACCTCAAAGGTTAGCCGCGGTGTCAGTTCGTCCCCACGTGGAGGCATGGCTTTTACTAGCCCAATTGTGCGGAAGTTCAACAGGTCCGCGGCTTGGGTCAATAGGCCCATGTACAAGAAGCCCAGGATATACAAGGTGCTCAGGACACCCGATGTGCCGTATGGTTGTGAAGGGCCTTGTAAGGTCCAGTCGTTTGAATCCCGCCATGATGTCTCCCATGTTGGTAAGGTGTTGTGTATTTCTGATGTGACACGGGGTAATGGGATTACCCACCGTGTAGGTAAGCGGTTCTGTGTTAAGTCTGTGTATATATTGGGGAAAGTTTGGATGGACGACAACATCAAGTTAAAGAACCACACCAATATAGTCATGTTCTGGTTGGTTAGAGACAGACGACCATATGGAACCCCGATGGACTTTGGCCAGGTGTTCAATATGTTCGATAATGAGCCTACGACGGCGACTGTTAAGAACGATCTTCGGGATCGTTTCCAGGTCATGCACAAGTTCAATGCCAAAGTGACAGGTGGACAATACGCCAGCAACGAGCAAGCCGCTGTCAAGCGCTTTTGGAAGGTCAATAATCATGTGGTGTACAATAACCAAGAAGCTGGCAAATACGAAAATCATACGGAGAACGCCCTCCTATTGTATATGGCGTGTACTCATGCATCGAATCCTGTATATGCGACTCTTAAAATTCGGATCTATTTTTATGATGCGATAACAAATTAATAAAGTTTATATTTTATTGAATGATTTTCGAGTACATGATTGACATAGAATCTGTCTGTTGCGAATCTGACAGCTCTAATTACAAAATTAATTGAAATGACACCTACTTGATCTAAGTACATATTTACTAAATATCGAAATCTATTTAAATAAGTCGTCCCAGAAGCTGTCAGATATCTGGTCCAGACCTGGAAGTTCAAGAAGCACCTGTGGAGATCCAGTGCTTTCCTCAGGTTGTGGTTGAACCTGATTTGTATGTGATACACTCTGGTGTTGGTGTACAGAAGGTCCTCCACGTGTGTGATCTTGAAATAAAGGGGATTTGGTATCTCCCAGATAAATGCGCCATTCTCTGCCTGAGGCGCAGTGATGATTTCCCCTGTGCGTGAATCCATGATCTCTGCAGTCGATGTGTACGTAAATGGTGCACCCGCACTCGCAATCAATTCGTCGTCGTCTAACCGCTCTCTTCTTGGCGATTCTGTGTTGTGGTTTGATAGAGGGGGGAGTTGAGGAAGACGAATTGCGCATTTCGAAGGGTCCAATTTCTAAGTGATGCGTTTTCCTCTTTGTCGAGGAAGTCTTTATAGCTGGACCCTTCCCCTGGATTACAGAGCACGATTGAAGGAACTCCACCTTTAATTTGAACTGGCTTTCCGTATTTACAGTTGGACTGCCAGTCCCTTTGGGCCCCAATGAGTTCCTTCCAGTGCTTCATTTTCAGATAATGTGGGCTAATGTCATCAATGACGTTATATTCCACGTCATTTGAATAAACCCTGGAATTGAAATCCAAGTGTCCACTAAGATAATTATGGACTCCTAATGAACGAGCCCACATTGTCTTCCCCGTTCGACTATCACCCTCGATGATAATACTAATAGCTCGTTCAGGCCGCGCAGCGGCATCAAGCCCAAAATATGAATCAGCCCACTCTTGCATCTCCTCTGGAACAAGAGTGAATGAGGAGAGGGGAAACGGAGGAACAAACGGTTCTGGAGCCTTTTGAAAAATGCGTTCTAAATTTGAACGGATATTATGATGTTGAAGGACAAAATCTTTGGGTTGTTCCTCTCTCAGTATATTGAGGGCCTCCATGACTGATCCTGAATTGAGGACCTTGGCATACGTGTCGTTGGCAGATTGCTGACCTCCTCTAGCAGATCTGCCGTCGATTTGGAAAATTCCATGATCAATGAAGTCTCCGTCTTTCTCCACATAGGTCTTGACGTCTGAAGAGCTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTAGTTGTGGAGACGAGGTCGAAGAATCTGTTATTTTGGCAATTGTATTTGCCTTCGAATTGGATGAGCACATGGAGGTGAGGTTGCCCATCTTCGTGTAGTTCTCTCGAGACACGAATGAATTTTTTATTGGTTGGTGTTTCAAGAGCAAGTAATTGGGAAAGTGCCTCTTCTTTGGAGAGAGAGCATTTAGGATAAGTAAGGAAAAAATTCCTACAGTTAACTCTAAAACGACGTGGTTCGGATGGCATTTTTGTAATAAGAAGCTTAGCACCGATTGGGGTCTCTCAAAACTTGCTCTGGCAATTGGGGTTTGGGGTCTTATTTATACTAGAACCCCCAATAGAACTCTCAATCCTCATCGCACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCTTTGGTGCCCCCCCCCCCACGTGGCGCGCTGGTGCCCGTTCGATGGTGCCCCTCTCCACGTGGCGCCCTGGTGCCCGCGCGTTCCCTTTACTCCTCCACCCAGTTTAGCGCTTATTTGGAGTCCGCGAAATGAGTTAACCGCATTTTTTGAGTTCCGGAAATCGTACATGTATACTGATAACTTTAATTCAAATTAAAGTTGAATTAACTTTGATTGACCAGTCATTTCGCTCTTGTCCCACTTTTCCTCTTCTCGCGCGATTTGTTGTAGACCGTTGGATAGTATTATCGTGCAATATCCTATTGCATTATTGGAGTTGAAGTGAGTGGCGCGAGAAAGATGAGGACCCATTGTACGACTTGTTCGACGTGTACCAGTTAAGTCGTTGCTGTGCAGGTAATTTAAGTCAGGAAATGTATATTTAATTCTGTGGGTATGGTGGTCGAATCAAGGTCTCTGGACATATTTAATATGTACTCTGCTAAGTTCAGACGTGTTCAGTCAAGTAATTACCGCCGTAATTACAGAAGGAATACAATATTTAAGCCTTCTGTTGGCGTAAAGCGGTACGATGGAAAACGTCGTTCTAGTCAGCATAACAAGGCACATGAAGAGAGTAAGATGTCAGCCCAGAGGATACACGAGAACCAGTTTGGGCCTGAATTTGTCATGGGCCATAACACAGCCATTTCAACGTTCATCACATTCCCTAGCCTCGGTAAGACCGAGCCTAACCGAACCAGGTCATACATCAAGCTAAAACGACTTCGTTTTAAGGGAACTATCAAGATTGAACGTGTACATACAGACGTCGTCATGGACGGTTCAAGTCCAAAGACCGAAGGAGTATTCTCTCTTGTGGTCGTCGTGGACCGTAAACCCCATCTCGGTTCAAGTGGATGCCTCCACACATTTGATGAGCTCTTTGGTGCCAGAATCCACAGTCATGGCAACCTAGCCATATCACCGTCTCTGAAGGACCGATTCTACATAAGACACGTGCTGAAACGTGTGTTGTCTGTGGAGAAGGATACATTAATGGTTGATCTTGAAGGGACGACGTCGCTCTCTAACAGGCGTTTCAACTGTTGGTCTTCGTTTAAAGACCTTGACCGTGATACATGTAACGGCGTTTACGCAAACATAAGCAAGAACGCCCTGTTAGTTTATTACTGTTGGATGTCTGACTCTCCGTCTAAGGCATCGACATTTGTATCATATGATCTGGATTATATTGGATAAATATAACTTAAGCATTAATATAAGCGCTCGAATGGGCATTGTATTGAATAATTGGGTTTAATTTAAAGATTTGGGCTGTGGAGGAGTACAATTTGTTTTGATACATTCCTGGACCGCAGTCCGAACTAACTCGTTTAATTGGGCCTCTGACATGGTTATATGCGATTCGACCCGCCTTGCAGCAACTATGGAGGCAGAGTCACCTGGGTCTAACATGCTGGTACCCAGTCTGTGTAGTCCTCGATACGGGTGTGCTGCGTTCTCCACGTCTGATTCCGTGCTGGATTGACCGATCCCTATGGCACTTCTGTTAGCCCAGGTCTCACCTGGATCGATTGATATTGGGCTGGGAAGCCCAAGTTTTACTGTTGATGTGGATCGGATCAATTTCCTTTCCCATTTGCCATAGCCCACATGGCAGAAATCGATATCCCTGTCCGTGAACTGTTTGGACAGGATCTTGACCGTTGGAGCTCGGAAAGGAATATCCACCGAATGTTTCGCCGTTGATATCTTGAGCTTCCCTTTGAACTTCGCGAAGTGGGTCCTCTGATGAACATTTGTGTCGCTGACCCTATAATAAAGCTTCCATGGGATCGGGTCTTTGAGGGAGAAGAACGACGAGGAGAAATAGTGAAGGTCTATGTTACACCTGATCGGGAAAGTCCATGACGCCTGTAAGGATTCGTTGTCAGTCATCCTCTTGTCGTGGATTTCGACGATGACGGAACCTGCGGCGTTTATGGGTACCTGTTGTCTGTATTCGATGACGCAATGGTCGATCTTCATACAGCTACGACTGAGTCTGGCGCTTATCTGAGCCGCCGCAGAAGGAAATTGCAGTACTATCTCAGTTAGGTCATGAGAAAGTTGATACTCATCACGCTGAGATTCTATATAATTAAATGCACTGGGCGGATTAACTAACTGAGACTCCATTGTTAAGTTTAATTTAAAAGAAAAGGGCCGCGCAGCGGAATGTTAAGAGAAGTGAACGAGAAAGGGTGATAGTCGAACGGGGAAGAAGACGTGAGTGAAATGAAAGATTAAATTGAAAGAGTAAAGTGAATAAGAGTTTAATTAGGGTTCCGGCGACTTGTACCGTCGACGGATGGAGAGGAGAGAGAAAGGAAAATGTCTGCTATTTTGATCCGGATATGTCCTGTTTAAATAGAGTTGGTGTCTATGAGTAATGATCGAATGGTCCTACAGTTAACTCTAAAACGACGTGGTTCGGATGGCATTGTTGTAATAAGAAGCTTAGCACCGATTGGGGTCTCTCAAAACTTGCTCTGGCAATTGGGGTTTGGGGTCTTATTTATACTAGAACCCCCAATAGAACTCTCAATCCTCATCGCACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_002941852.1
|
|
Location
|
226-999 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCTCCATGGCGTTTAATGGCGGGGACCTCAAAGGTTAGCCGCGGTGTCAGTTCGTCCCCACGTGGAGGCATGGCTTTTACTAGCCCAATTGTGCGGAAGTTCAACAGGTCCGCGGCTTGGGTCAATAGGCCCATGTACAAGAAGCCCAGGATATACAAGGTGCTCAGGACACCCGATGTGCCGTATGGTTGTGAAGGGCCTTGTAAGGTCCAGTCGTTTGAATCCCGCCATGATGTCTCCCATGTTGGTAAGGTGTTGTGTATTTCTGATGTGACACGGGGTAATGGGATTACCCACCGTGTAGGTAAGCGGTTCTGTGTTAAGTCTGTGTATATATTGGGGAAAGTTTGGATGGACGACAACATCAAGTTAAAGAACCACACCAATATAGTCATGTTCTGGTTGGTTAGAGACAGACGACCATATGGAACCCCGATGGACTTTGGCCAGGTGTTCAATATGTTCGATAATGAGCCTACGACGGCGACTGTTAAGAACGATCTTCGGGATCGTTTCCAGGTCATGCACAAGTTCAATGCCAAAGTGACAGGTGGACAATACGCCAGCAACGAGCAAGCCGCTGTCAAGCGCTTTTGGAAGGTCAATAATCATGTGGTGTACAATAACCAAGAAGCTGGCAAATACGAAAATCATACGGAGAACGCCCTCCTATTGTATATGGCGTGTACTCATGCATCGAATCCTGTATATGCGACTCTTAAAATTCGGATCTATTTTTATGATGCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRGVSSSPRGGMAFTSPIVRKFNRSAAWVNRPMYKKPRIYKVLRTPDVPYGCEGPCKVQSFESRHDVSHVGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNIVMFWLVRDRRPYGTPMDFGQVFNMFDNEPTTATVKNDLRDRFQVMHKFNAKVTGGQYASNEQAAVKRFWKVNNHVVYNNQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAITN |
|
NCBI Accession
|
YP_002941853.1
|
|
Location
|
996-1394 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAAATCATCACTGCGCCTCAGGCAGAGAATGGCGCATTTATCTGGGAGATACCAAATCCCCTTTATTTCAAGATCACACACGTGGAGGACCTTCTGTACACCAACACCAGAGTGTATCACATACAAATCAGGTTCAACCACAACCTGAGGAAAGCACTGGATCTCCACAGGTGCTTCTTGAACTTCCAGGTCTGGACCAGATATCTGACAGCTTCTGGGACGACTTATTTAAATAGATTTCGATATTTAGTAAATATGTACTTAGATCAAGTAGGTGTCATTTCAATTAATTTTGTAATTAGAGCTGTCAGATTCGCAACAGACAGATTCTATGTCAATCATGTACTCGAAAATCATTCAATAAAATATAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEIITAPQAENGAFIWEIPNPLYFKITHVEDLLYTNTRVYHIQIRFNHNLRKALDLHRCFLNFQVWTRYLTASGTTYLNRFRYLVNMYLDQVGVISINFVIRAVRFATDRFYVNHVLENHSIKYKLY |
|
NCBI Accession
|
YP_002941854.1
|
|
Location
|
1141-1530 |
|
Gene Name
|
AC2 |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCGCAATTCGTCTTCCTCAACTCCCCCCTCTATCAAACCACAACACAGAATCGCCAAGAAGAGAGCGGTTAGACGACGACGAATTGATTGCGAGTGCGGGTGCACCATTTACGTACACATCGACTGCAGAGATCATGGATTCACGCACAGGGGAAATCATCACTGCGCCTCAGGCAGAGAATGGCGCATTTATCTGGGAGATACCAAATCCCCTTTATTTCAAGATCACACACGTGGAGGACCTTCTGTACACCAACACCAGAGTGTATCACATACAAATCAGGTTCAACCACAACCTGAGGAAAGCACTGGATCTCCACAGGTGCTTCTTGAACTTCCAGGTCTGGACCAGATATCTGACAGCTTCTGGGACGACTTATTTAAATAG |
|
Protein Sequence
|
MRNSSSSTPPSIKPQHRIAKKRAVRRRRIDCECGCTIYVHIDCRDHGFTHRGNHHCASGREWRIYLGDTKSPLFQDHTRGGPSVHQHQSVSHTNQVQPQPEESTGSPQVLLELPGLDQISDSFWDDLFK |
|
NCBI Accession
|
YP_002941855.1
|
|
Location
|
1457-2530 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCCGAACCACGTCGTTTTAGAGTTAACTGTAGGAATTTTTTCCTTACTTATCCTAAATGCTCTCTCTCCAAAGAAGAGGCACTTTCCCAATTACTTGCTCTTGAAACACCAACCAATAAAAAATTCATTCGTGTCTCGAGAGAACTACACGAAGATGGGCAACCTCACCTCCATGTGCTCATCCAATTCGAAGGCAAATACAATTGCCAAAATAACAGATTCTTCGACCTCGTCTCCACAACTAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCTTCAGACGTCAAGACCTATGTGGAGAAAGACGGAGACTTCATTGATCATGGAATTTTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCCAACGACACGTATGCCAAGGTCCTCAATTCAGGATCAGTCATGGAGGCCCTCAATATACTGAGAGAGGAACAACCCAAAGATTTTGTCCTTCAACATCATAATATCCGTTCAAATTTAGAACGCATTTTTCAAAAGGCTCCAGAACCGTTTGTTCCTCCGTTTCCCCTCTCCTCATTCACTCTTGTTCCAGAGGAGATGCAAGAGTGGGCTGATTCATATTTTGGGCTTGATGCCGCTGCGCGGCCTGAACGAGCTATTAGTATTATCATCGAGGGTGATAGTCGAACGGGGAAGACAATGTGGGCTCGTTCATTAGGAGTCCATAATTATCTTAGTGGACACTTGGATTTCAATTCCAGGGTTTATTCAAATGACGTGGAATATAACGTCATTGATGACATTAGCCCACATTATCTGAAAATGAAGCACTGGAAGGAACTCATTGGGGCCCAAAGGGACTGGCAGTCCAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAGTTCCTTCAATCGTGCTCTGTAATCCAGGGGAAGGGTCCAGCTATAAAGACTTCCTCGACAAAGAGGAAAACGCATCACTTAGAAATTGGACCCTTCGAAATGCGCAATTCGTCTTCCTCAACTCCCCCCTCTATCAAACCACAACACAGAATCGCCAAGAAGAGAGCGGTTAG |
|
Protein Sequence
|
MPSEPRRFRVNCRNFFLTYPKCSLSKEEALSQLLALETPTNKKFIRVSRELHEDGQPHLHVLIQFEGKYNCQNNRFFDLVSTTRSTHFHPNIQGAKSSSDVKTYVEKDGDFIDHGIFQIDGRSARGGQQSANDTYAKVLNSGSVMEALNILREEQPKDFVLQHHNIRSNLERIFQKAPEPFVPPFPLSSFTLVPEEMQEWADSYFGLDAAARPERAISIIIEGDSRTGKTMWARSLGVHNYLSGHLDFNSRVYSNDVEYNVIDDISPHYLKMKHWKELIGAQRDWQSNCKYGKPVQIKGGVPSIVLCNPGEGSSYKDFLDKEENASLRNWTLRNAQFVFLNSPLYQTTTQNRQEESG |
|
NCBI Accession
|
YP_002941856.1
|
|
Location
|
2077-2370 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCACCTCCATGTGCTCATCCAATTCGAAGGCAAATACAATTGCCAAAATAACAGATTCTTCGACCTCGTCTCCACAACTAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCTTCAGACGTCAAGACCTATGTGGAGAAAGACGGAGACTTCATTGATCATGGAATTTTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCCAACGACACGTATGCCAAGGTCCTCAATTCAGGATCAGTCATGGAGGCCCTCAATATACTGA |
|
Protein Sequence
|
MGNLTSMCSSNSKANTIAKITDSSTSSPQLGQHISIRTFRELRALQTSRPMWRKTETSLIMEFSKSTADLLEEVSNLPTTRMPRSSIQDQSWRPSIY |
|
NCBI Accession
|
YP_002941857.1
|
|
Location
|
488-1258 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTACTCTGCTAAGTTCAGACGTGTTCAGTCAAGTAATTACCGCCGTAATTACAGAAGGAATACAATATTTAAGCCTTCTGTTGGCGTAAAGCGGTACGATGGAAAACGTCGTTCTAGTCAGCATAACAAGGCACATGAAGAGAGTAAGATGTCAGCCCAGAGGATACACGAGAACCAGTTTGGGCCTGAATTTGTCATGGGCCATAACACAGCCATTTCAACGTTCATCACATTCCCTAGCCTCGGTAAGACCGAGCCTAACCGAACCAGGTCATACATCAAGCTAAAACGACTTCGTTTTAAGGGAACTATCAAGATTGAACGTGTACATACAGACGTCGTCATGGACGGTTCAAGTCCAAAGACCGAAGGAGTATTCTCTCTTGTGGTCGTCGTGGACCGTAAACCCCATCTCGGTTCAAGTGGATGCCTCCACACATTTGATGAGCTCTTTGGTGCCAGAATCCACAGTCATGGCAACCTAGCCATATCACCGTCTCTGAAGGACCGATTCTACATAAGACACGTGCTGAAACGTGTGTTGTCTGTGGAGAAGGATACATTAATGGTTGATCTTGAAGGGACGACGTCGCTCTCTAACAGGCGTTTCAACTGTTGGTCTTCGTTTAAAGACCTTGACCGTGATACATGTAACGGCGTTTACGCAAACATAAGCAAGAACGCCCTGTTAGTTTATTACTGTTGGATGTCTGACTCTCCGTCTAAGGCATCGACATTTGTATCATATGATCTGGATTATATTGGATAA |
|
Protein Sequence
|
MYSAKFRRVQSSNYRRNYRRNTIFKPSVGVKRYDGKRRSSQHNKAHEESKMSAQRIHENQFGPEFVMGHNTAISTFITFPSLGKTEPNRTRSYIKLKRLRFKGTIKIERVHTDVVMDGSSPKTEGVFSLVVVVDRKPHLGSSGCLHTFDELFGARIHSHGNLAISPSLKDRFYIRHVLKRVLSVEKDTLMVDLEGTTSLSNRRFNCWSSFKDLDRDTCNGVYANISKNALLVYYCWMSDSPSKASTFVSYDLDYIG |
|
NCBI Accession
|
YP_002941858.1
|
|
Location
|
1316-2197 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGTCTCAGTTAGTTAATCCGCCCAGTGCATTTAATTATATAGAATCTCAGCGTGATGAGTATCAACTTTCTCATGACCTAACTGAGATAGTACTGCAATTTCCTTCTGCGGCGGCTCAGATAAGCGCCAGACTCAGTCGTAGCTGTATGAAGATCGACCATTGCGTCATCGAATACAGACAACAGGTACCCATAAACGCCGCAGGTTCCGTCATCGTCGAAATCCACGACAAGAGGATGACTGACAACGAATCCTTACAGGCGTCATGGACTTTCCCGATCAGGTGTAACATAGACCTTCACTATTTCTCCTCGTCGTTCTTCTCCCTCAAAGACCCGATCCCATGGAAGCTTTATTATAGGGTCAGCGACACAAATGTTCATCAGAGGACCCACTTCGCGAAGTTCAAAGGGAAGCTCAAGATATCAACGGCGAAACATTCGGTGGATATTCCTTTCCGAGCTCCAACGGTCAAGATCCTGTCCAAACAGTTCACGGACAGGGATATCGATTTCTGCCATGTGGGCTATGGCAAATGGGAAAGGAAATTGATCCGATCCACATCAACAGTAAAACTTGGGCTTCCCAGCCCAATATCAATCGATCCAGGTGAGACCTGGGCTAACAGAAGTGCCATAGGGATCGGTCAATCCAGCACGGAATCAGACGTGGAGAACGCAGCACACCCGTATCGAGGACTACACAGACTGGGTACCAGCATGTTAGACCCAGGTGACTCTGCCTCCATAGTTGCTGCAAGGCGGGTCGAATCGCATATAACCATGTCAGAGGCCCAATTAAACGAGTTAGTTCGGACTGCGGTCCAGGAATGTATCAAAACAAATTGTACTCCTCCACAGCCCAAATCTTTAAATTAA |
|
Protein Sequence
|
MESQLVNPPSAFNYIESQRDEYQLSHDLTEIVLQFPSAAAQISARLSRSCMKIDHCVIEYRQQVPINAAGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKISTAKHSVDIPFRAPTVKILSKQFTDRDIDFCHVGYGKWERKLIRSTSTVKLGLPSPISIDPGETWANRSAIGIGQSSTESDVENAAHPYRGLHRLGTSMLDPGDSASIVAARRVESHITMSEAQLNELVRTAVQECIKTNCTPPQPKSLN |