Passionfruit leaf distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001876915.1 |
| Isolate |
Colombia |
| Release date |
2016/11/13 |
| Submitter |
Vaca-Vaca,J.C., Carrasco-Lozano,E.C., Lopez-Lopez,K., Carrasco-Lozano,E. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
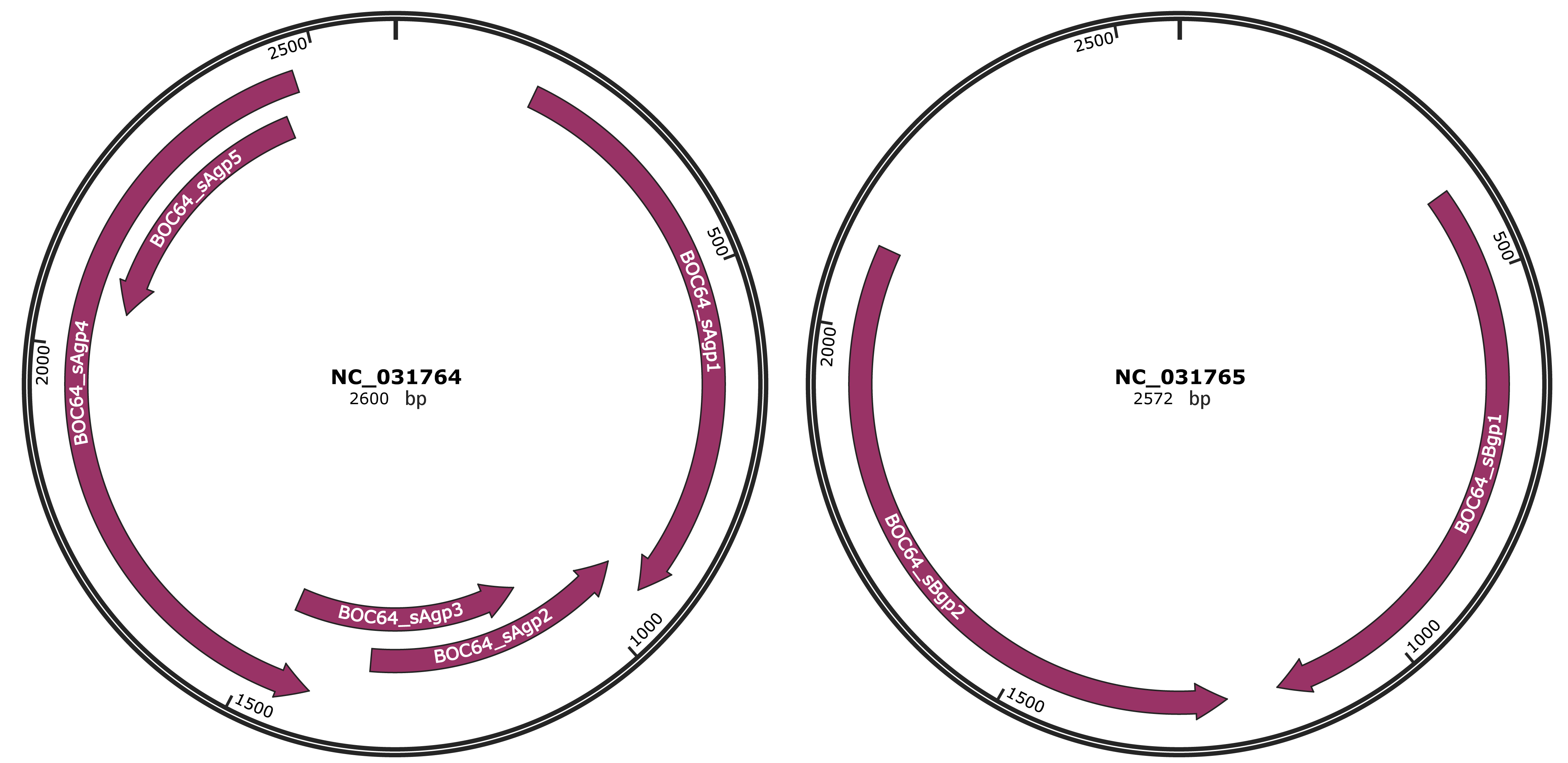
JBrowse
Genome
ACCGGATGGCCGCGCTTTGGTGTCCGCTCTCTCTTTCTCTTTAATTTGAATTAAAGCGCTCCGCTTTCGTCTCAGCCAATCATCTCGCGCCTGACGAGCCTAGATATGTGCAACAACTTGGGCCCTAAGTTGTTTTATGTCTGTTATAAATTAAAGAGCACTCGGCCCACTGCCTTTAACTCAAAATGCCTAAGCGGGATGCCCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGTCGCAATGCCAATTACTCTCCTCGTTCAGGCAGTGGCCCAAAGTTAAATAGGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTTAGGACTCCTGATGTCCCACGAGGATGTGAAGGCCCGTGTAAGGTACAGTCCTACGAACAGCGTCACGACATATCCCATGTTGGCAAGGTAATGTGTATCTCTGATGTCACACGTGGTAATGGTATCACCCACCGTGTCGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTAGGCAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCCGAGACCGTAGACCGTATGGAACTCCCATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACAGCTACGGTTAAGAACGATCTCCGCGATCGTTACCAGGTCATGCATAAGTTCTATGGGAAGGTGACAGGTGGACAATATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAACCACGTTGTCTACAACCATCAAGAGGCTGGCAAATATGAGAATCACACGGAGAACGCCTTGTTATTGTACATGGCATGTACCCATGCATCTAACCCCGTCTATGCAACTCTCAAGATTCGGATCTATTTTTACGATTCGATTTTGAATTAATAAAATTTATATTTTATTGAATGATTTTCCAGTACATGAGATACATAAACCCTGTCTGTTGCGAATCGAACAGCTCTAATGACATTGTTAATAGAAATTACGCCTAACTGATCTAAATACATGAGGACTAAATGTCTAAACCTATTTAAATAAGTCAACCCAGAAGCTGTCAGGGATACTGTCCAGACTTGGAAGTTCAGGTAAGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATTTGCACGTGATATACCCTGGTCATCGTATATCGCAGGTCCTCTACTTGAATTATCTTGAAATATAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGACGTGCAGTGATGAACTCCCCTGTGCGTGAATCCATGTCCCGTGCAGCCTATGTGGAAGTAAATGGAGCACCCGCACTGCAAGTCAATGCGTCGTCGTCTGATCGCACGCCTCTTAGCCTGTCTGTGTGCTATCTTGATAGAGGGGGGATTCGAGGGTGATGAAGATCGCATTCTTTAACGTCCAGTTTCTGAGCGATGCATTTTCCGCTTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGAATCCCCCCTTTAATAAGGACTGGCTTACCGTACTTGCAATTTGACTGCCACATCTTTTGAGCCCCTATCAATTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCTATTACGTTATACTCCACTTCGTCTGAGAAAACCCGGGAATTGAAGTCTAGGTGTCCACTGAGATAATTATGTGGGCCTAACGCACGTGCCCACATCGTCTTCCCCGTCCTAGAATCACCTTCGACGATGATACTAATAGGTCTTTCCGGCCGCGCAGCTGGACTCAAAGAAAAATAACTATCTGCCCACTCTTGCATCTCGTCGGGCACGTTAGTGAAGGAGGAGAGTGGAAACGGAGGAACCCACGGTTCAGGAGCCTTTTGGAATATTCTGGTTGCGTTAGCAACCAGGTTGTGATGCTGAAGGAAGAAATGTTGCGGTTGTTCTTCCTTTATTATTTGCAGGGCAGCCTCTGCTGATCCTGCATTCAACGCCTTGGCATATGTGTCGTTAGTAGACTGCTGACCTCCTCTAGCAGACCTGCCGTCGATCTGGAACTGTCCCCATTCAACTGTGTCTCCGTCCTTGTCGATGTAAGACTTGACGTCGGAGCTCGACTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTAGTTGGGGAGACCAGATCGAAGAATCTGTTATTCTGGCATTGGTATTTCCCTTCGAACTGGATGAGGACGTGGAGATGAGGCTCCCCATTTTCGTGTAATTCCCTGGAGACCTTGATGAACTTCTTATTAACTGGGGTTTTAATGTGTTGAATTTGGGAAAGTACTTCTGCTTTAGTAAGAGAGCATTGTGGATAAGTGAGGAAATAGTTCTTGGCATTCACTCTGAATTTCCTAGGCGGTGGCATTTCTGTAATAAGAAGTGGTACACCAATTGAGCTCTCTCAAAACTGTCTTATGCAATTGGTGTTTGGTGTCTTATTTATACTAGAACCCTCAATCTTGGTTTGGTACACGTGGCGGCCATCCATATAATATT
ACCGGATGGCCGCGCATTGGTGTTCGCTCTATCTGGTGGCCCGCGCTCTGTGATCCTGCCACCTGGCGCGCTCTATCGCTCCCCGTGCTCTTCTGGTGGGTCGTATTTACTTTGACTGCCCTTTAATTTGAATTAAAGGGCCTTTCTTTATGTCGCGCGAGTTCTTTTGAAATTTGAATAATTTCCTCGCGTTATTGCCATGGCCCACTGTACCTCACGACTGACGTGGCTCGTTTTAGACCATGCGGCTGAGTCTATTTATCTATTTTGAACCATCCTTATCTATATATTGAAGTCGAATGATATGTGTCATGTAAGCTGACTCAGCCTTCCACCACGGTTATATCGCTTTATAATTTGTGTATTAACTGTGTTTATATTTTGACAATGTATCCCTCGAGGAATAAACGTGGTTTGTCCTTCACCCCACGTCGATTTTATGCTCGAAACACTGTGTTCAACCGCCCGCATTCTGGAAAACGTCAAGCCTGGAAACGTCGAGGTGCCAATTCAAACAAGTCGGATGATGAGCCCAGAATGTCGTCCCAACGCATACATGAGAATCAGTATGGGCCAGAATTCGTTATGCCCCATAACCAAGCCATTTCTACGTTTATCAGCTACCCATGCGTTGGTAAGACCGAGCCCAACCGAAGTAGGTCCTATATTAAGTTGAAACGACTCCGTTTCAAGGGTACTGTGAAGATTGAACGTGTTCAACCAGATATGAACATGGATGGTTCTACCCCCAAAGTGGAAGGAGTGTTTACTCTCGTGGTGGTTATGGATCGCAAACCCCACCTGGGTGCATCTGGGTGTCTGCATACATTCGACGAGCTGTTCGGTGCAAGGATCCATAGCCATGGTAACCTGAGCATAACCCCCTCTCTGAAAGACCGTTTCTACATACGACACGTATTCAAACGTGTATTGTCCGTGGAGAAGGATACGATGATGGTCGACGTGGAAGGATCTACAACGCTCTCTAACAGGCGTTTTAATTGCTGGTCCACATTCAAGGATCTTGATCATGACTCATGCAACGGTGTTTATGATAACATTAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCAACATTTGTATCGTTTGACCTTGATTATATAGGTTGATTAATAATAAACTATGTATATATTTACCATCGAACAGTCAATCTTTGAACAATCGAAGCATATAATTTATTGTAGTGATTTGGGCTGAGTAGCCTTACAATTACTATTAATACATTCTTGTACAGTGGATCGAACAAGCTCGTTCAACTGGCCCACTGTCATAGTAATGTTGGATTCGGCTCGCTGGGCTCCTACAATCGAAGCAGACTCCCCTGGGTCTAACACGCTCGTTCCCAGCCTACTGAGATGTCTATATGGATGCATTGCGTTCTCCACCTCCGAGTCCGCATCCGAATTACTTAGCCCAACTGTACTCCTTGAAGCCCACGACTCTCCTGGCTTTATTTCAATTGGGCCCGGAAGCCCAATCCTGGACATGGATGCGGACCTTATTATCTTCCTTTCCCATCTCCCATAGTCCACGTGGGAGAAATCCACGTCTTTGTCGGTGAACTGTTTGGACAAGATCTTAACCGTCGGTGCCCGGAAGGGGATATCTACGGAGTGTTTAGCCGTGGATAGTTTCAATTTCCCTTTGAACTTGGCGAAGTGGGTCCTCTGATGAACATTCGTATCACAAACTCTGTAATAGAGTTTCCAAGGAATAGGATCTTTGAGGGAAAAGAAGGAAGATGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCACGACGCCTGCAAAGACTCGTTGTCGGTCATTCTCTTGTCATGAATCTCCACTATAACAGATCCCGTCGCGTTAATTGGAACCTGTTGTCGGTACTCTATGACGCAGTGGTCTATTTTCATGCAACTCCGACTGAGTCTGGCTGTTAACTGAGACGCCGTCGACGGGAATTGCATAATTATCTCAGTTAGGTCATGAGAAAGCTGGTACTCGTCCCGATGGGACTCTATGTAGTTAAAGGCACTTGGAGGATTTACTAACTGAGAATCCATATGAGAAAATATGGCCGCGCAGCGGAACTGACGGACGACGAACAACTGACCAACGACGAACAATTAGTCAAGAAGCTGGAAGATTTGCAGAAGAAGAACAGTGGTTGAAGATAAGACTATTTTCTGGAAAACTCAGAAAAGGATATGAAGAAGGTGAAGAACAAACGTTGAACTTCTACTGAATATGAGTTTGTGTTTTGAGAAAGAGGAGAAAGCGGATGAATAACTCAGGGATGTTTATGATTTAGATCTGGGTGGGGTGTATATATAACCCACGAGGTTGTGTTTTAGTTCAGAGCTTTCAGGAGAAGTTATTTTGTTATATGGAATGGCATTTCTGTAATAAGAAGTGGTACACCAATTGAGCTCTCTCAAAACTGTCTCATGCAATTGGTGTTTGGTGTCTTATTTATACTAGAACCCTCAATCTTGGTTTGGTACACGTGGCGGCCATCCCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009316180.1
|
|
Location
|
186-941 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGTCGCAATGCCAATTACTCTCCTCGTTCAGGCAGTGGCCCAAAGTTAAATAGGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTTAGGACTCCTGATGTCCCACGAGGATGTGAAGGCCCGTGTAAGGTACAGTCCTACGAACAGCGTCACGACATATCCCATGTTGGCAAGGTAATGTGTATCTCTGATGTCACACGTGGTAATGGTATCACCCACCGTGTCGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTAGGCAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCCGAGACCGTAGACCGTATGGAACTCCCATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACAGCTACGGTTAAGAACGATCTCCGCGATCGTTACCAGGTCATGCATAAGTTCTATGGGAAGGTGACAGGTGGACAATATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAACCACGTTGTCTACAACCATCAAGAGGCTGGCAAATATGAGAATCACACGGAGAACGCCTTGTTATTGTACATGGCATGTACCCATGCATCTAACCCCGTCTATGCAACTCTCAAGATTCGGATCTATTTTTACGATTCGATTTTGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRSGSGPKLNRASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
YP_009316181.1
|
|
Location
|
938-1336 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAATTCAAGTAGAGGACCTGCGATATACGATGACCAGGGTATATCACGTGCAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACAGTATCCCTGACAGCTTCTGGGTTGACTTATTTAAATAGGTTTAGACATTTAGTCCTCATGTATTTAGATCAGTTAGGCGTAATTTCTATTAACAATGTCATTAGAGCTGTTCGATTCGCAACAGACAGGGTTTATGTATCTCATGTACTGGAAAATCATTCAATAAAATATAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITARQAENGVYIWEIENPLYFKIIQVEDLRYTMTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTVSLTASGLTYLNRFRHLVLMYLDQLGVISINNVIRAVRFATDRVYVSHVLENHSIKYKFY |
|
NCBI Accession
|
YP_009316182.1
|
|
Location
|
1083-1472 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCGATCTTCATCACCCTCGAATCCCCCCTCTATCAAGATAGCACACAGACAGGCTAAGAGGCGTGCGATCAGACGACGACGCATTGACTTGCAGTGCGGGTGCTCCATTTACTTCCACATAGGCTGCACGGGACATGGATTCACGCACAGGGGAGTTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAATTCAAGTAGAGGACCTGCGATATACGATGACCAGGGTATATCACGTGCAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACAGTATCCCTGACAGCTTCTGGGTTGACTTATTTAAATAG |
|
Protein Sequence
|
MRSSSPSNPPSIKIAHRQAKRRAIRRRRIDLQCGCSIYFHIGCTGHGFTHRGVHHCTSGREWRVYLGDRKSPIFQDNSSRGPAIYDDQGISRANTVQPQPEESVASPQSLPELPSLDSIPDSFWVDLFK |
|
NCBI Accession
|
YP_009316183.1
|
|
Location
|
1414-2469 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCACCGCCTAGGAAATTCAGAGTGAATGCCAAGAACTATTTCCTCACTTATCCACAATGCTCTCTTACTAAAGCAGAAGTACTTTCCCAAATTCAACACATTAAAACCCCAGTTAATAAGAAGTTCATCAAGGTCTCCAGGGAATTACACGAAAATGGGGAGCCTCATCTCCACGTCCTCATCCAGTTCGAAGGGAAATACCAATGCCAGAATAACAGATTCTTCGATCTGGTCTCCCCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGAGACACAGTTGAATGGGGACAGTTCCAGATCGACGGCAGGTCTGCTAGAGGAGGTCAGCAGTCTACTAACGACACATATGCCAAGGCGTTGAATGCAGGATCAGCAGAGGCTGCCCTGCAAATAATAAAGGAAGAACAACCGCAACATTTCTTCCTTCAGCATCACAACCTGGTTGCTAACGCAACCAGAATATTCCAAAAGGCTCCTGAACCGTGGGTTCCTCCGTTTCCACTCTCCTCCTTCACTAACGTGCCCGACGAGATGCAAGAGTGGGCAGATAGTTATTTTTCTTTGAGTCCAGCTGCGCGGCCGGAAAGACCTATTAGTATCATCGTCGAAGGTGATTCTAGGACGGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAATTATCTCAGTGGACACCTAGACTTCAATTCCCGGGTTTTCTCAGACGAAGTGGAGTATAACGTAATAGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATAGGGGCTCAAAAGATGTGGCAGTCAAATTGCAAGTACGGTAAGCCAGTCCTTATTAAAGGGGGGATTCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGCGGAAAATGCATCGCTCAGAAACTGGACGTTAAAGAATGCGATCTTCATCACCCTCGAATCCCCCCTCTATCAAGATAGCACACAGACAGGCTAA |
|
Protein Sequence
|
MPPPRKFRVNAKNYFLTYPQCSLTKAEVLSQIQHIKTPVNKKFIKVSRELHENGEPHLHVLIQFEGKYQCQNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGQFQIDGRSARGGQQSTNDTYAKALNAGSAEAALQIIKEEQPQHFFLQHHNLVANATRIFQKAPEPWVPPFPLSSFTNVPDEMQEWADSYFSLSPAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSDEVEYNVIDDVAPHYLKLKHWKELIGAQKMWQSNCKYGKPVLIKGGIPSIVLCNPGEGASYKDFLNKAENASLRNWTLKNAIFITLESPLYQDSTQTG |
|
NCBI Accession
|
YP_009316184.1
|
|
Location
|
2055-2441 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGCCAAGAACTATTTCCTCACTTATCCACAATGCTCTCTTACTAAAGCAGAAGTACTTTCCCAAATTCAACACATTAAAACCCCAGTTAATAAGAAGTTCATCAAGGTCTCCAGGGAATTACACGAAAATGGGGAGCCTCATCTCCACGTCCTCATCCAGTTCGAAGGGAAATACCAATGCCAGAATAACAGATTCTTCGATCTGGTCTCCCCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGAGACACAGTTGAATGGGGACAGTTCCAGATCGACGGCAGGTCTGCTAGAGGAGGTCAGCAGTCTACTAACGACACATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MPRTISSLIHNALLLKQKYFPKFNTLKPQLIRSSSRSPGNYTKMGSLISTSSSSSKGNTNARITDSSIWSPQLGQHISIRTFRELSRAPTSSLTSTRTETQLNGDSSRSTAGLLEEVSSLLTTHMPRR |
|
NCBI Accession
|
YP_009316185.1
|
|
Location
|
388-1158 |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGTATCCCTCGAGGAATAAACGTGGTTTGTCCTTCACCCCACGTCGATTTTATGCTCGAAACACTGTGTTCAACCGCCCGCATTCTGGAAAACGTCAAGCCTGGAAACGTCGAGGTGCCAATTCAAACAAGTCGGATGATGAGCCCAGAATGTCGTCCCAACGCATACATGAGAATCAGTATGGGCCAGAATTCGTTATGCCCCATAACCAAGCCATTTCTACGTTTATCAGCTACCCATGCGTTGGTAAGACCGAGCCCAACCGAAGTAGGTCCTATATTAAGTTGAAACGACTCCGTTTCAAGGGTACTGTGAAGATTGAACGTGTTCAACCAGATATGAACATGGATGGTTCTACCCCCAAAGTGGAAGGAGTGTTTACTCTCGTGGTGGTTATGGATCGCAAACCCCACCTGGGTGCATCTGGGTGTCTGCATACATTCGACGAGCTGTTCGGTGCAAGGATCCATAGCCATGGTAACCTGAGCATAACCCCCTCTCTGAAAGACCGTTTCTACATACGACACGTATTCAAACGTGTATTGTCCGTGGAGAAGGATACGATGATGGTCGACGTGGAAGGATCTACAACGCTCTCTAACAGGCGTTTTAATTGCTGGTCCACATTCAAGGATCTTGATCATGACTCATGCAACGGTGTTTATGATAACATTAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCAACATTTGTATCGTTTGACCTTGATTATATAGGTTGA |
|
Protein Sequence
|
MYPSRNKRGLSFTPRRFYARNTVFNRPHSGKRQAWKRRGANSNKSDDEPRMSSQRIHENQYGPEFVMPHNQAISTFISYPCVGKTEPNRSRSYIKLKRLRFKGTVKIERVQPDMNMDGSTPKVEGVFTLVVVMDRKPHLGASGCLHTFDELFGARIHSHGNLSITPSLKDRFYIRHVFKRVLSVEKDTMMVDVEGSTTLSNRRFNCWSTFKDLDHDSCNGVYDNISKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_009316186.1
|
|
Location
|
1225-2106 |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGATTCTCAGTTAGTAAATCCTCCAAGTGCCTTTAACTACATAGAGTCCCATCGGGACGAGTACCAGCTTTCTCATGACCTAACTGAGATAATTATGCAATTCCCGTCGACGGCGTCTCAGTTAACAGCCAGACTCAGTCGGAGTTGCATGAAAATAGACCACTGCGTCATAGAGTACCGACAACAGGTTCCAATTAACGCGACGGGATCTGTTATAGTGGAGATTCATGACAAGAGAATGACCGACAACGAGTCTTTGCAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCATCTTCCTTCTTTTCCCTCAAAGATCCTATTCCTTGGAAACTCTATTACAGAGTTTGTGATACGAATGTTCATCAGAGGACCCACTTCGCCAAGTTCAAAGGGAAATTGAAACTATCCACGGCTAAACACTCCGTAGATATCCCCTTCCGGGCACCGACGGTTAAGATCTTGTCCAAACAGTTCACCGACAAAGACGTGGATTTCTCCCACGTGGACTATGGGAGATGGGAAAGGAAGATAATAAGGTCCGCATCCATGTCCAGGATTGGGCTTCCGGGCCCAATTGAAATAAAGCCAGGAGAGTCGTGGGCTTCAAGGAGTACAGTTGGGCTAAGTAATTCGGATGCGGACTCGGAGGTGGAGAACGCAATGCATCCATATAGACATCTCAGTAGGCTGGGAACGAGCGTGTTAGACCCAGGGGAGTCTGCTTCGATTGTAGGAGCCCAGCGAGCCGAATCCAACATTACTATGACAGTGGGCCAGTTGAACGAGCTTGTTCGATCCACTGTACAAGAATGTATTAATAGTAATTGTAAGGCTACTCAGCCCAAATCACTACAATAA |
|
Protein Sequence
|
MDSQLVNPPSAFNYIESHRDEYQLSHDLTEIIMQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKIIRSASMSRIGLPGPIEIKPGESWASRSTVGLSNSDADSEVENAMHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMTVGQLNELVRSTVQECINSNCKATQPKSLQ |