Okra mottle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000875625.1 |
| Isolate |
Brazil |
| Release date |
2015/2/13 |
| Submitter |
Aranha,S.A., Inoue-Nagata,A.K. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
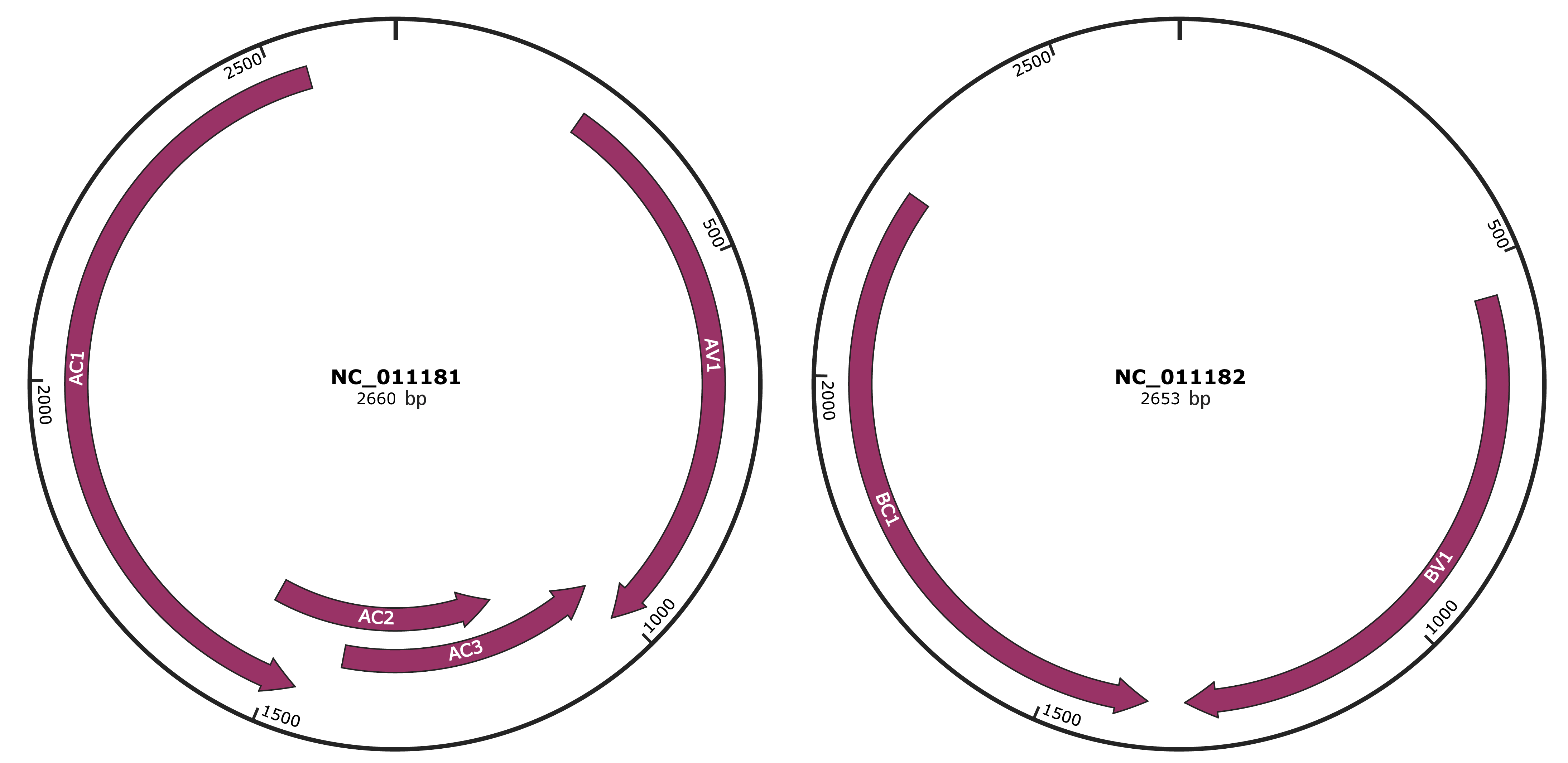
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCCCCCCTTTCTTGACGTGGCGCTCTGGTGGCCGCCCGATCCTCCTCTCCCTCTCCGCTCTCGTGGAGTACACCTTGCCCGCGCGCTGTTCTCCTTTAATTCAAATTAAAGGATTTAACTTTTGTCCGACCAATTATAGTGCGCCTGAGGAGCCTAGATATTTGCGAAAGACTTGGGCCCTAAGTTGTTGGACGACTATATAATTAAGTCATGTATGACGTCAGTAATTATTTCAAAATGCCCAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCACTACCAACTTTTCCCCTCGTGGAGGTGGAGGCCCAAAGTACAACAAGGCCTCGGAGTGGGTTCACAGGCCTATGTATAGGAAGCCCAGGATATACAGGATGATAAGGACTCCTGATGTTCCAAGAGGCTGTGAAGGGCCCTGCAAGGTTCAATCCTACGAGCAGCGTCACGACATCTCACATGTCGGGAAGGTCATGTGCATATCTGATGTCACACGTGGCAATGGTATAACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATATTCTGGTTGGTCAGAGACCGTAGACCGTATGGTACCCCTATGGAGTTTGGCCAGGTGTTTAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAGGCTGGGAAGTATGAGAATCACACGGAGAATGCTCTGTTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTCTACGATTCGATCACGAATTAATAAAGTTTGAATTTTATTGAATGATTTTCGAGTACATAACTGACATATGGCCTGTCTGTTGCGAAACGAACAGCTCTAATTACATTATTAATGGCAATTACACCTAATTGGTCTAAGTACATCATGACTAGCATCTTAAACCTAGCTAAATATGTCGTCCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTGAGGTAGGCCTTGTGGAGACCCAATGCTCTCCTGAGGTTGTGGTTGAACCTTATCTGTATGTGGTATATTCTGGTTCTCGTGTACGGTAGATCCTCTAGGTTGTATATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATATAGACGCCATTCTCTGTCTGAGGTGCAGTTATGAATTCCCCGGTGCGTGAATCCATGGCCGTTGCAGTTGAAGTGGACGTATATCGAGCAGCCGCACTCTAGGTCCACTCGTCTACGCCTGATGGCTCTCTTCTTGGCAATCCTGTGTCTCGGTTTGATAGAGGGGGGCGTCGAGGAAGATGAATTTAGCATTGTGGAGTGTCCACGATTTCAGAGCTGCATTTTCCTCCTTGTCTAGGAAGTCTTTATAGCTAGCCCCCTCTCCAGGATTGCACAGCACGATTGATGGGATGCCACCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCTTTTTGAGCACCAATCAATTCCTTCCAGTGCTTTAACTTTAGATATTGCGGTGTGACATCGTCAATGACGTTGTATTCCACTTCGTTCGAGTAAACCTTAGAATTGAAGTCCAGATGACCACTCAAGTAATTATGTGGGCCTAACGCACGAGCCCACATCGTCTTCCCTGTCCTTGAATCACCTTCGACTATCAAACTCATAGGTCTGAATGGCCGCGCAGCGGAACCTCTCCCAAAATATTCATCGGCCCACTCTTGCATCTCGTCGGGAACGTTAGTGAAGGAGGAGAGGTTAAACGGAGGAACCCACGGCTCCGGAGCCTTTGAGAAAATTCTATCTAAATTAGAATTTAAATTATGAAACTGAAAAAGATATTTCTCTGGCAATTTTTCCCGAATTAACTGAAGAGCCGTCTGTTTATCAGGAGCGTTTAACGCCTCAGCTGCAGCGTCATTAGCTGTCTGTTGGCCTCCCCTAGAACTCCTTCCGTCGACCTGGAAGTCACCCCATTCTACTGTATCTCCATCTTTGTCGATGTAAGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTTGTTGGGGAAACCAGGTCGAACAATCTGTTATTTGTGATTTGGACCTTTCCTTCCAATTGCAACAGGACGTGGAGGTGAGGTTCCCCATTTTCGTGAAGCTCTCTGCAAATCTTGATGAATTTCTTATTAGAGGGTAATTGAATAGCTTGCAATTGGGAAAGTGCCTCCTCTTTTGTAAGAGAGCACTGTGGATAAGTAAGGAAAATGTTTTTAGCTTGGAGTCTAAAACGACGTGGTTTGGATGGCATTTTTGTAAATAAGGGAGTGTACTCCGCTTGAGAGCTCGCTCATAAGTCTATATGAATTGGAGTATGGAGTACAATATATAGTAATAGGAGTTCCTAAGGCCATCCGTATAATATT
ACCGGATGGCCGCGCGATTTTTTCCCCCCCCCCTACGTGGCGCGCTGGTGCCCGTTGGATACCGCTCTCCCTGGTGGGCCTCCCCCTTGGTGCTACTCCCCCCCCTCTCCCGGCTCAATTCAATTGAGCGCTTTTTTGGAGTCCGCGAAATGAGTTAAACGCAATTTTTGATGTCCGCCTTCATTCAGCGCCTTTAATTTGAATTAAAGGCATATCATTATGTTGTCCACTCATTTCGGTCTGCTTGTCTCCTCGCGCGACGCTCGCTTTTGCCCAACCGGATGAGATGTGATCTTGGTCGTTGGATAATAATATAATTTATTCAGCCACTTTAATTTGAAACTTGAATTATTTGCGAGCGTCGTGGTACCATGTCCCATCGTACGAACTTGATGAGCTGGACCAGTGAAGTTGCACCTACAGAGTTAAATTGATCAAGGAATTTATGTTTAAATTCCCGGGTGATAGATGGTGATATCAGGTTAATTGAGCACGTCTATTGTTTGAGTAGCTACAGTTAACAGTTGTGTGTTAGTCAATTTTAAAACATGTTTCCCATTAGGTATAGACGTGGTTGGTCGTCTAATCAGCGACGAGGTTACACACGTAATCCCGTGTTTAAGCGTTATTATGTAGCTAAACGAAGTGATTTCAAGCGACGACCCAGTAATACTAACAAGGCCCAAGAAGATGGCAAGATGTCTACTCAACGTATACACGAGAACCAGTTTGGGCCTGAATTTGTAATGGGCCACAACTCAGCCATTTCAACGTTTATTACATTTCCTAGCCTCGGTAAGACCGAGCCTAACCGAACCAGGTCCTATGTCAAGCTAAAACGACTCCGTTTTAAGGGTACTGTGAAGATTGAACGTGTTTACAATGACGTCATCATGGATGGTTCAACCCCAAAGATTGAAGGAGTCTTTTCCCTCGTGGTCGTGGTAGATCGTAAACCCCACTTGGGATCATCTGGGTGTCTGCACACGTTTGACGAGTTATTCGGTGCCAGGATCCACAGTCATGGCAATCTGGCTATAACACCCTCCCTGAAAGACCGCTTTTACATTCGACACGTGTTCAAACGTGTGTTATCTGTGGAGAAAGACACTTTGATGGTTGATCTTGAAGGGACTACATACCTCTCTAACAGGCGTTTTAATTGTTGGTCAACGTTTAAGGATATTGACCGTGAATCATGTAACGGTGTTTATGCAAACATAAGCAAGAACGCCCTGTTAGTTTACTACTGTTGGATGTCGGACTCGTCGTCCAAGGCATCGACATTTGTATCATATGATCTCGATTACATCGGTTAAACATATAGACATATTTTCATTAATAACATTGTTATTGATTAATCACATATTAACTTAATGATTTGGGCTGTGGGGGAATACAATTTGTTTTAATACACTCCTGGACCGCACTCCTCACTAGGTCGTTTAATTGTGCCTCGGACATGGTTATATGCGATTCGGCCCTTCTCGCAGCAACTATGGAAGCCGAGTCACCTGGGTCCAACATGCTGGTGCCCAGTTTATGGAGCCCTCTATATGGGTGTGTTGCGTTCTCTACCTCTGACTCGGTGCTCGATTGACCGATCCCTATGGTACTGCGTGAAGCCCATGTCTCACCTGGATCAATGGTTATTGGGCTTGGGAGCCCATACTTGACTGTGGATGCGGATCGGATCAATTTCCTTTCCCATTTCCCATAGCCCACGTGGCTGAAATCTACGTCTCTATCTGTGAACTGTTTAGATAAGATCTTCACCGTCGGTGCTCGGAAAGGAATGTCGACGGAATGTTTCGCCGTTGACAGCTTTAGCTTCCCCTTGAATTTCGCGAAGTGCGTTCTCTGGTGAACATTCGTGTCGCTCACTCTGTAATACAATTTCCAGGGAATTGGGTCTTTCAGGGAGAAGAACGAGCATGAAAAGTAGTGGAGATCTATGTTGCACCTGATCGGGAATGTCCAGGACGCCTGTAACGATTCATTGTCCGTCATTCTCTTGTCGTGGATCTCCACGATGACGGAACCTGTGGCGTTTATGGGTACCTGTTGCCTGTATTCTATGACGCAGTGGTCTATCTTCATACAGCTGCGACTGAGCCTGGCGCTTATCTGAGCCGCCGCAGAAGGAAACTGCAGAACGATCTCAGTTAGGTCATGAGAAAGCTGATACTCATCACGCTGAGATTCTATATAATTAAAGGCATTGGGTGGATTAACTAACTGAGAACCCATTTTAACTATTAATCTAAGAAGAATAGGCCGCGCAGCGTAATCTGTAGGTGAAGTGAATAAGGCGAAAGCGGAAAAGAATATGGCGTCAGTCAAACTGAGAAGACAATTGTGTTAGGGTTTCAGTTGTTGAGAGGACGGATTAAGATGAGATATGAGGTGAAGGAATCTGTGTCTAACACCAATCTATAGGATTTATTTATAGATAGATGGGCTGGGTTCTGTCGGGTTATTTTTCCTATCGACTAAAACGACGAGGTTTTGATGTCATGACTATGCTTTGGATGGCATTTTTGTAAATAAGACTGTGTACTCCGCTTGAGAGCTCTTTCATAAGTCTATATGAATTGGAGTAAGGAGTACAATATATAGTAATAGGAGTTCCTAAGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_002154617.1
|
|
Location
|
259-1014 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCCAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCACTACCAACTTTTCCCCTCGTGGAGGTGGAGGCCCAAAGTACAACAAGGCCTCGGAGTGGGTTCACAGGCCTATGTATAGGAAGCCCAGGATATACAGGATGATAAGGACTCCTGATGTTCCAAGAGGCTGTGAAGGGCCCTGCAAGGTTCAATCCTACGAGCAGCGTCACGACATCTCACATGTCGGGAAGGTCATGTGCATATCTGATGTCACACGTGGCAATGGTATAACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATATTCTGGTTGGTCAGAGACCGTAGACCGTATGGTACCCCTATGGAGTTTGGCCAGGTGTTTAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAGGCTGGGAAGTATGAGAATCACACGGAGAATGCTCTGTTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTCTACGATTCGATCACGAATTAA |
|
Protein Sequence
|
MPKRDPSWRQMAGTSKVSRTTNFSPRGGGGPKYNKASEWVHRPMYRKPRIYRMIRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYGTPMEFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_002154618.1
|
|
Location
|
1011-1409 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAATTCATAACTGCACCTCAGACAGAGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACAACCTAGAGGATCTACCGTACACGAGAACCAGAATATACCACATACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCCTACCTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACATATTTAGCTAGGTTTAAGATGCTAGTCATGATGTACTTAGACCAATTAGGTGTAATTGCCATTAATAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGGCCATATGTCAGTTATGTACTCGAAAATCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITAPQTENGVYIWEVPNPLYFKIYNLEDLPYTRTRIYHIQIRFNHNLRRALGLHKAYLNFQVWTTSLTASGTTYLARFKMLVMMYLDQLGVIAINNVIRAVRFATDRPYVSYVLENHSIKFKLY |
|
NCBI Accession
|
YP_002154619.1
|
|
Location
|
1156-1545 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivation protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCGAGACACAGGATTGCCAAGAAGAGAGCCATCAGGCGTAGACGAGTGGACCTAGAGTGCGGCTGCTCGATATACGTCCACTTCAACTGCAACGGCCATGGATTCACGCACCGGGGAATTCATAACTGCACCTCAGACAGAGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACAACCTAGAGGATCTACCGTACACGAGAACCAGAATATACCACATACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCCTACCTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKPRHRIAKKRAIRRRRVDLECGCSIYVHFNCNGHGFTHRGIHNCTSDREWRLYLGGSKSPLFQDIQPRGSTVHENQNIPHTDKVQPQPQESIGSPQGLPQLPSLDDFSDSFWDDIFS |
|
NCBI Accession
|
YP_002154620.1
|
|
Location
|
1466-2545 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCCAAACCACGTCGTTTTAGACTCCAAGCTAAAAACATTTTCCTTACTTATCCACAGTGCTCTCTTACAAAAGAGGAGGCACTTTCCCAATTGCAAGCTATTCAATTACCCTCTAATAAGAAATTCATCAAGATTTGCAGAGAGCTTCACGAAAATGGGGAACCTCACCTCCACGTCCTGTTGCAATTGGAAGGAAAGGTCCAAATCACAAATAACAGATTGTTCGACCTGGTTTCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAAGATGGAGATACAGTAGAATGGGGTGACTTCCAGGTCGACGGAAGGAGTTCTAGGGGAGGCCAACAGACAGCTAATGACGCTGCAGCTGAGGCGTTAAACGCTCCTGATAAACAGACGGCTCTTCAGTTAATTCGGGAAAAATTGCCAGAGAAATATCTTTTTCAGTTTCATAATTTAAATTCTAATTTAGATAGAATTTTCTCAAAGGCTCCGGAGCCGTGGGTTCCTCCGTTTAACCTCTCCTCCTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCCGATGAATATTTTGGGAGAGGTTCCGCTGCGCGGCCATTCAGACCTATGAGTTTGATAGTCGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAATTACTTGAGTGGTCATCTGGACTTCAATTCTAAGGTTTACTCGAACGAAGTGGAATACAACGTCATTGACGATGTCACACCGCAATATCTAAAGTTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGCATCCCATCAATCGTGCTGTGCAATCCTGGAGAGGGGGCTAGCTATAAAGACTTCCTAGACAAGGAGGAAAATGCAGCTCTGAAATCGTGGACACTCCACAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCGAGACACAGGATTGCCAAGAAGAGAGCCATCAGGCGTAG |
|
Protein Sequence
|
MPSKPRRFRLQAKNIFLTYPQCSLTKEEALSQLQAIQLPSNKKFIKICRELHENGEPHLHVLLQLEGKVQITNNRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGDFQVDGRSSRGGQQTANDAAAEALNAPDKQTALQLIREKLPEKYLFQFHNLNSNLDRIFSKAPEPWVPPFNLSSFTNVPDEMQEWADEYFGRGSAARPFRPMSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVYSNEVEYNVIDDVTPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENAALKSWTLHNAKFIFLDAPLYQTETQDCQEESHQA |
|
NCBI Accession
|
YP_002154621.1
|
|
Location
|
549-1319 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTTTCCCATTAGGTATAGACGTGGTTGGTCGTCTAATCAGCGACGAGGTTACACACGTAATCCCGTGTTTAAGCGTTATTATGTAGCTAAACGAAGTGATTTCAAGCGACGACCCAGTAATACTAACAAGGCCCAAGAAGATGGCAAGATGTCTACTCAACGTATACACGAGAACCAGTTTGGGCCTGAATTTGTAATGGGCCACAACTCAGCCATTTCAACGTTTATTACATTTCCTAGCCTCGGTAAGACCGAGCCTAACCGAACCAGGTCCTATGTCAAGCTAAAACGACTCCGTTTTAAGGGTACTGTGAAGATTGAACGTGTTTACAATGACGTCATCATGGATGGTTCAACCCCAAAGATTGAAGGAGTCTTTTCCCTCGTGGTCGTGGTAGATCGTAAACCCCACTTGGGATCATCTGGGTGTCTGCACACGTTTGACGAGTTATTCGGTGCCAGGATCCACAGTCATGGCAATCTGGCTATAACACCCTCCCTGAAAGACCGCTTTTACATTCGACACGTGTTCAAACGTGTGTTATCTGTGGAGAAAGACACTTTGATGGTTGATCTTGAAGGGACTACATACCTCTCTAACAGGCGTTTTAATTGTTGGTCAACGTTTAAGGATATTGACCGTGAATCATGTAACGGTGTTTATGCAAACATAAGCAAGAACGCCCTGTTAGTTTACTACTGTTGGATGTCGGACTCGTCGTCCAAGGCATCGACATTTGTATCATATGATCTCGATTACATCGGTTAA |
|
Protein Sequence
|
MFPIRYRRGWSSNQRRGYTRNPVFKRYYVAKRSDFKRRPSNTNKAQEDGKMSTQRIHENQFGPEFVMGHNSAISTFITFPSLGKTEPNRTRSYVKLKRLRFKGTVKIERVYNDVIMDGSTPKIEGVFSLVVVVDRKPHLGSSGCLHTFDELFGARIHSHGNLAITPSLKDRFYIRHVFKRVLSVEKDTLMVDLEGTTYLSNRRFNCWSTFKDIDRESCNGVYANISKNALLVYYCWMSDSSSKASTFVSYDLDYIG |
|
NCBI Accession
|
YP_002154622.1
|
|
Location
|
1369-2250 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGGTTCTCAGTTAGTTAATCCACCCAATGCCTTTAATTATATAGAATCTCAGCGTGATGAGTATCAGCTTTCTCATGACCTAACTGAGATCGTTCTGCAGTTTCCTTCTGCGGCGGCTCAGATAAGCGCCAGGCTCAGTCGCAGCTGTATGAAGATAGACCACTGCGTCATAGAATACAGGCAACAGGTACCCATAAACGCCACAGGTTCCGTCATCGTGGAGATCCACGACAAGAGAATGACGGACAATGAATCGTTACAGGCGTCCTGGACATTCCCGATCAGGTGCAACATAGATCTCCACTACTTTTCATGCTCGTTCTTCTCCCTGAAAGACCCAATTCCCTGGAAATTGTATTACAGAGTGAGCGACACGAATGTTCACCAGAGAACGCACTTCGCGAAATTCAAGGGGAAGCTAAAGCTGTCAACGGCGAAACATTCCGTCGACATTCCTTTCCGAGCACCGACGGTGAAGATCTTATCTAAACAGTTCACAGATAGAGACGTAGATTTCAGCCACGTGGGCTATGGGAAATGGGAAAGGAAATTGATCCGATCCGCATCCACAGTCAAGTATGGGCTCCCAAGCCCAATAACCATTGATCCAGGTGAGACATGGGCTTCACGCAGTACCATAGGGATCGGTCAATCGAGCACCGAGTCAGAGGTAGAGAACGCAACACACCCATATAGAGGGCTCCATAAACTGGGCACCAGCATGTTGGACCCAGGTGACTCGGCTTCCATAGTTGCTGCGAGAAGGGCCGAATCGCATATAACCATGTCCGAGGCACAATTAAACGACCTAGTGAGGAGTGCGGTCCAGGAGTGTATTAAAACAAATTGTATTCCCCCACAGCCCAAATCATTAAGTTAA |
|
Protein Sequence
|
MGSQLVNPPNAFNYIESQRDEYQLSHDLTEIVLQFPSAAAQISARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSCSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDRDVDFSHVGYGKWERKLIRSASTVKYGLPSPITIDPGETWASRSTIGIGQSSTESEVENATHPYRGLHKLGTSMLDPGDSASIVAARRAESHITMSEAQLNDLVRSAVQECIKTNCIPPQPKSLS |