Okra leaf curl Oman virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001504015.1 |
| Isolate |
Oman:Barka |
| Release date |
2016/1/7 |
| Submitter |
Khan,A.J., Akhtar,S. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
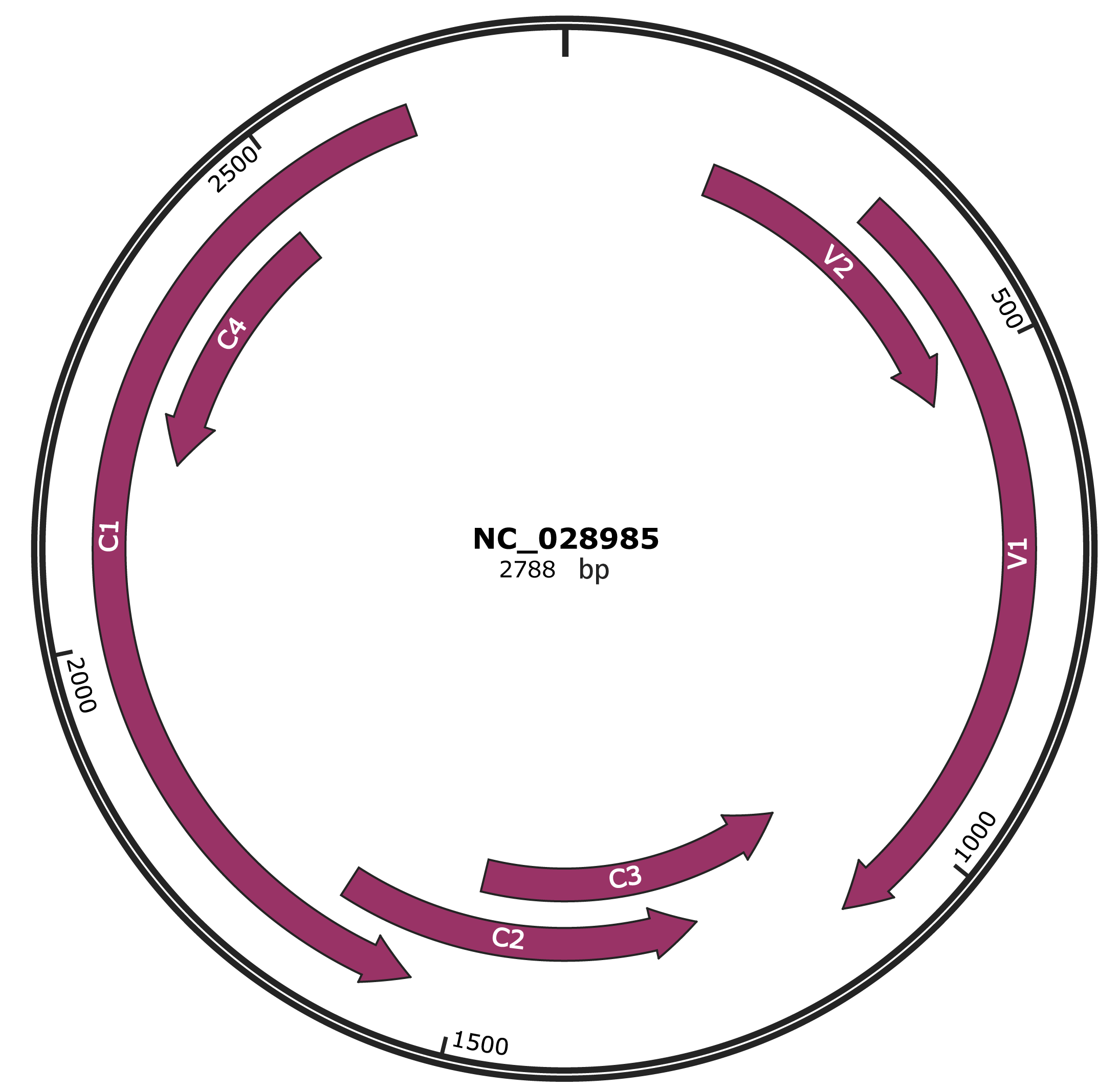
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTGTGGTCCCCGCCCCACGTGAACACGTCGCGCGAGTTCTGAAGATGTCGCGCGATGCTGTCCAATCAGAACGCGCGCTCTACGCATTATAATTTGAAATTTGAAATATAAACTTGCTCCCCTAAGTTTGTCCGGCATAACTATGTGGGATCCGTTATTGAACGACTTCCCTGAATCCGTTCACGGTTTCCGTTGTATGCTCGCCGTGAAATATTTGCAGGCTGTTCGAGAGTCGTACGATCCTTGCACTCTTGGGTACGATCTTCTTAGCGATCTTATCGGAGTTGTTCGCCGTACCAACTATGTCGAAGCGACCAGCAGATATCATCATTTCCACTCCCGCCTCGAAAGTGCGTCGCCGTCTGAACTTCGACAGCCCCGGGTTATCCTCTGCACGTGCCCCCACTGTCCTCGTCACAAACAAGCGTCGGGCCTGGAACAACAGGCCCCTATACAGAAAACCGAGGATTTATCGAATTTATCGCAGCCCAGATGTCCCAAAGGGATGTGAAGGTCCTTGTAAGGTCCAGTCTTATGAACAGCGTGATGATGTCAAGCATACGGGCATTGTTCGATGTGTGTCGGATGTTACTAAGGGTGTTGGTCTTACTCATCGTACTGGAAAGCGTTTCACTATCAAATCTATCTATATTCTTGGTAAGGTATGGATGGATGACAACATTAAGAAGCAGAATCACACCAACAATGTAATGTTTTTCCTTGTCCGTGATAGAAGACCCTATGGCAATAGTCCCATGGATTTTGGACAGGTTTTTCACATGTTTGACAACGAACCTAGCACTGCCACTGTAAAGAATGATTTGCGAGATCGTTTTCAGGTGATGCGTAAGTTTAGTGCTACTGTAACTGGTGGCCCTTCTGGGATGAAGGAACAAGTTCCTGTTCGTAGGTTTTTTAAGCTTAATAGTCAGACTGTGTATAACCATCAAGAAGCTGCGAAGTATGAGAATCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCAAACCCTGTGTATGCTACGTTAAAGATACGGATCTATTTCTACGATTCGGTATCTAATTAATATAATTTTATTTGAATATTGTGCGTGAATTCACTTGCCACGGTTGTTTGCAATACATCGTACAAAACATGATTGACTGCCCTAATTACATTGTTAATTGAAATTACGCCTATTCTATACAAATATTTCATAATCTGCTTCCTAAATACGTTTAAGAAAAGACCAGTCGGAGGGCGTGAGATCGTCCAGACCCTGAAGTTCATGAAACATTTGTGAATCCCCAATTCCTTCCTGAGGTTGTAGTTGAATCTTATCTGCATCTCTACCATTGTTTGATTCCCGTGCGTTAGAGGAATCTCCTTTATGGTTTTGAAATACAGGGGATTGTTGATTGTCCAGATAAGTACGCCATTCTCTGTCTGATGCGCAGTGATGAGTTCCCCTGTGCGTGAATCCATTGTCTCTGCACGTGAAGGCTACGTATACTGTGCAACCACAAGGGATGTCAATCCTGCGTCTCCTGATTGCTCTCTTCTTGGCCTCCCGATGCTGAACTTTGATTGGTACCTGAGTACAGCGGATTTGAGAGGGTGATGAAGGTCGCATTCTTTAATGCCCAGGATTTTAATGCTGAGTTCTTGTCCTCGTCTAAGAACTCTTTATAGCTTGCATTGGGCCCTGGATTGCAGAGGAAGATTGTTGGGATGCCCCCTTTAATTTGAACTGGTTTCCCGTATTTTGTGTTGGATTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTGAGGAAGTGCGGATCGACGTCATCAATGATGTTATACCAAGCGTCGTTACTGTACACCTTTGGACTTAGATCTAAATGCCCACATAGATAATTATGTGGGCCTAGTGACCTAGCCCATACGGTCTTTCCTGTTCTGCTTTCCCCTTCAATCACTATACTAATCGGTCTACTTGGCCGCGCAGCGGCATCGACGACGTTCTCGGCCGCCCACTCTTCAAGTTCTTCTGGAACTTGATCGAACGAAGAAGAAGAAAAAGGAGAAACATAAGGAGCTGGTGGCTCCTGAAAATACCTATCTAAATTACAATTTAAATTATGAAATTGGAGTAGAAAGTCTCTTGGGGCTTTCTCCTTCAGTATATTGAGGGCCTGAGCTTTGGACCCTGCGTTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCTGATCTTCCATCGACCTGGAAAACTCCATGATCAAGGATGTCTCCGTCTTTCTCCATGTAGGTTTTGACATCGCTTGAGCTTTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGGTGAGGTCGAAGAATCTATTGTTCTTGCACTGGAACTTCCCTTCGAATTGGATGAGAACATGCAAGTGAGGAGTCCCATCTTCGTGAAGCTCTCTGCAGATTCTAATGAATTTTTTGGAAGTGGGTGTTTGGAGATTTAATAATTGGGAAAGTGCTTCCTCTTTAGTAAGAGAGCACTTGGGATAAGTGAGAAAATAATTTTTGGCATTTATTCTAAACCGATTGGGGGCTGCCATGCTGACTTAGTCAATCGGTGTCTCTCAATTTGCTCTATGTATTGGTGTACTGGAGTCCTATATATATGGAGACTCTAATGGCATAATTGTAATAAAAGAACTTTAATTTGAATTTCAAATGAAAAGCCTAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009216259.1
|
|
Location
|
166-534 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCGTTATTGAACGACTTCCCTGAATCCGTTCACGGTTTCCGTTGTATGCTCGCCGTGAAATATTTGCAGGCTGTTCGAGAGTCGTACGATCCTTGCACTCTTGGGTACGATCTTCTTAGCGATCTTATCGGAGTTGTTCGCCGTACCAACTATGTCGAAGCGACCAGCAGATATCATCATTTCCACTCCCGCCTCGAAAGTGCGTCGCCGTCTGAACTTCGACAGCCCCGGGTTATCCTCTGCACGTGCCCCCACTGTCCTCGTCACAAACAAGCGTCGGGCCTGGAACAACAGGCCCCTATACAGAAAACCGAGGATTTATCGAATTTATCGCAGCCCAGATGTCCCAAAGGGATGTGA |
|
Protein Sequence
|
MWDPLLNDFPESVHGFRCMLAVKYLQAVRESYDPCTLGYDLLSDLIGVVRRTNYVEATSRYHHFHSRLESASPSELRQPRVILCTCPHCPRHKQASGLEQQAPIQKTEDLSNLSQPRCPKGM |
|
NCBI Accession
|
YP_009216260.1
|
|
Location
|
326-1102 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATCATCATTTCCACTCCCGCCTCGAAAGTGCGTCGCCGTCTGAACTTCGACAGCCCCGGGTTATCCTCTGCACGTGCCCCCACTGTCCTCGTCACAAACAAGCGTCGGGCCTGGAACAACAGGCCCCTATACAGAAAACCGAGGATTTATCGAATTTATCGCAGCCCAGATGTCCCAAAGGGATGTGAAGGTCCTTGTAAGGTCCAGTCTTATGAACAGCGTGATGATGTCAAGCATACGGGCATTGTTCGATGTGTGTCGGATGTTACTAAGGGTGTTGGTCTTACTCATCGTACTGGAAAGCGTTTCACTATCAAATCTATCTATATTCTTGGTAAGGTATGGATGGATGACAACATTAAGAAGCAGAATCACACCAACAATGTAATGTTTTTCCTTGTCCGTGATAGAAGACCCTATGGCAATAGTCCCATGGATTTTGGACAGGTTTTTCACATGTTTGACAACGAACCTAGCACTGCCACTGTAAAGAATGATTTGCGAGATCGTTTTCAGGTGATGCGTAAGTTTAGTGCTACTGTAACTGGTGGCCCTTCTGGGATGAAGGAACAAGTTCCTGTTCGTAGGTTTTTTAAGCTTAATAGTCAGACTGTGTATAACCATCAAGAAGCTGCGAAGTATGAGAATCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCAAACCCTGTGTATGCTACGTTAAAGATACGGATCTATTTCTACGATTCGGTATCTAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPGLSSARAPTVLVTNKRRAWNNRPLYRKPRIYRIYRSPDVPKGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTKGVGLTHRTGKRFTIKSIYILGKVWMDDNIKKQNHTNNVMFFLVRDRRPYGNSPMDFGQVFHMFDNEPSTATVKNDLRDRFQVMRKFSATVTGGPSGMKEQVPVRRFFKLNSQTVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009216261.1
|
|
Location
|
1099-1500 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCGCATCAGACAGAGAATGGCGTACTTATCTGGACAATCAACAATCCCCTGTATTTCAAAACCATAAAGGAGATTCCTCTAACGCACGGGAATCAAACAATGGTAGAGATGCAGATAAGATTCAACTACAACCTCAGGAAGGAATTGGGGATTCACAAATGTTTCATGAACTTCAGGGTCTGGACGATCTCACGCCCTCCGACTGGTCTTTTCTTAAACGTATTTAGGAAGCAGATTATGAAATATTTGTATAGAATAGGCGTAATTTCAATTAACAATGTAATTAGGGCAGTCAATCATGTTTTGTACGATGTATTGCAAACAACCGTGGCAAGTGAATTCACGCACAATATTCAAATAAAATTATATTAA |
|
Protein Sequence
|
MDSRTGELITAHQTENGVLIWTINNPLYFKTIKEIPLTHGNQTMVEMQIRFNYNLRKELGIHKCFMNFRVWTISRPPTGLFLNVFRKQIMKYLYRIGVISINNVIRAVNHVLYDVLQTTVASEFTHNIQIKLY |
|
NCBI Accession
|
YP_009216262.1
|
|
Location
|
1244-1648 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTCATCACCCTCTCAAATCCGCTGTACTCAGGTACCAATCAAAGTTCAGCATCGGGAGGCCAAGAAGAGAGCAATCAGGAGACGCAGGATTGACATCCCTTGTGGTTGCACAGTATACGTAGCCTTCACGTGCAGAGACAATGGATTCACGCACAGGGGAACTCATCACTGCGCATCAGACAGAGAATGGCGTACTTATCTGGACAATCAACAATCCCCTGTATTTCAAAACCATAAAGGAGATTCCTCTAACGCACGGGAATCAAACAATGGTAGAGATGCAGATAAGATTCAACTACAACCTCAGGAAGGAATTGGGGATTCACAAATGTTTCATGAACTTCAGGGTCTGGACGATCTCACGCCCTCCGACTGGTCTTTTCTTAAACGTATTTAG |
|
Protein Sequence
|
MRPSSPSQIRCTQVPIKVQHREAKKRAIRRRRIDIPCGCTVYVAFTCRDNGFTHRGTHHCASDREWRTYLDNQQSPVFQNHKGDSSNARESNNGRDADKIQLQPQEGIGDSQMFHELQGLDDLTPSDWSFLKRI |
|
NCBI Accession
|
YP_009216263.1
|
|
Location
|
1548-2636 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication initiation protein |
|
Coding Region
|
ATGGCAGCCCCCAATCGGTTTAGAATAAATGCCAAAAATTATTTTCTCACTTATCCCAAGTGCTCTCTTACTAAAGAGGAAGCACTTTCCCAATTATTAAATCTCCAAACACCCACTTCCAAAAAATTCATTAGAATCTGCAGAGAGCTTCACGAAGATGGGACTCCTCACTTGCATGTTCTCATCCAATTCGAAGGGAAGTTCCAGTGCAAGAACAATAGATTCTTCGACCTCACCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAAGCGATGTCAAAACCTACATGGAGAAAGACGGAGACATCCTTGATCATGGAGTTTTCCAGGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACGCAGGGTCCAAAGCTCAGGCCCTCAATATACTGAAGGAGAAAGCCCCAAGAGACTTTCTACTCCAATTTCATAATTTAAATTGTAATTTAGATAGGTATTTTCAGGAGCCACCAGCTCCTTATGTTTCTCCTTTTTCTTCTTCTTCGTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCGGCCGAGAACGTCGTCGATGCCGCTGCGCGGCCAAGTAGACCGATTAGTATAGTGATTGAAGGGGAAAGCAGAACAGGAAAGACCGTATGGGCTAGGTCACTAGGCCCACATAATTATCTATGTGGGCATTTAGATCTAAGTCCAAAGGTGTACAGTAACGACGCTTGGTATAACATCATTGATGACGTCGATCCGCACTTCCTCAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAATACGGGAAACCAGTTCAAATTAAAGGGGGCATCCCAACAATCTTCCTCTGCAATCCAGGGCCCAATGCAAGCTATAAAGAGTTCTTAGACGAGGACAAGAACTCAGCATTAAAATCCTGGGCATTAAAGAATGCGACCTTCATCACCCTCTCAAATCCGCTGTACTCAGGTACCAATCAAAGTTCAGCATCGGGAGGCCAAGAAGAGAGCAATCAGGAGACGCAGGATTGA |
|
Protein Sequence
|
MAAPNRFRINAKNYFLTYPKCSLTKEEALSQLLNLQTPTSKKFIRICRELHEDGTPHLHVLIQFEGKFQCKNNRFFDLTSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDILDHGVFQVDGRSARGGCQSANDAYAEAINAGSKAQALNILKEKAPRDFLLQFHNLNCNLDRYFQEPPAPYVSPFSSSSFDQVPEELEEWAAENVVDAAARPSRPISIVIEGESRTGKTVWARSLGPHNYLCGHLDLSPKVYSNDAWYNIIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNASYKEFLDEDKNSALKSWALKNATFITLSNPLYSGTNQSSASGGQEESNQETQD |
|
NCBI Accession
|
YP_009216264.1
|
|
Location
|
2186-2479 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGACTCCTCACTTGCATGTTCTCATCCAATTCGAAGGGAAGTTCCAGTGCAAGAACAATAGATTCTTCGACCTCACCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAAGCGATGTCAAAACCTACATGGAGAAAGACGGAGACATCCTTGATCATGGAGTTTTCCAGGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACGCAGGGTCCAAAGCTCAGGCCCTCAATATACTGA |
|
Protein Sequence
|
MGLLTCMFSSNSKGSSSARTIDSSTSPPQPGQHISIRTFRELKAQAMSKPTWRKTETSLIMEFSRSMEDQLEEVANLPTTHMPRQSTQGPKLRPSIY |