Okra enation leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000887915.1 |
| Isolate |
India: Munthal, Haryana |
| Release date |
2015/2/22 |
| Submitter |
Venkataravanappa,V., Lakshminarayana Reddy,C.N., Jalali,S., Krishna Reddy,M., Lakshiminarayanareddy,C.N., Devaraju, Swaranalatha,P., Krishnareddy,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
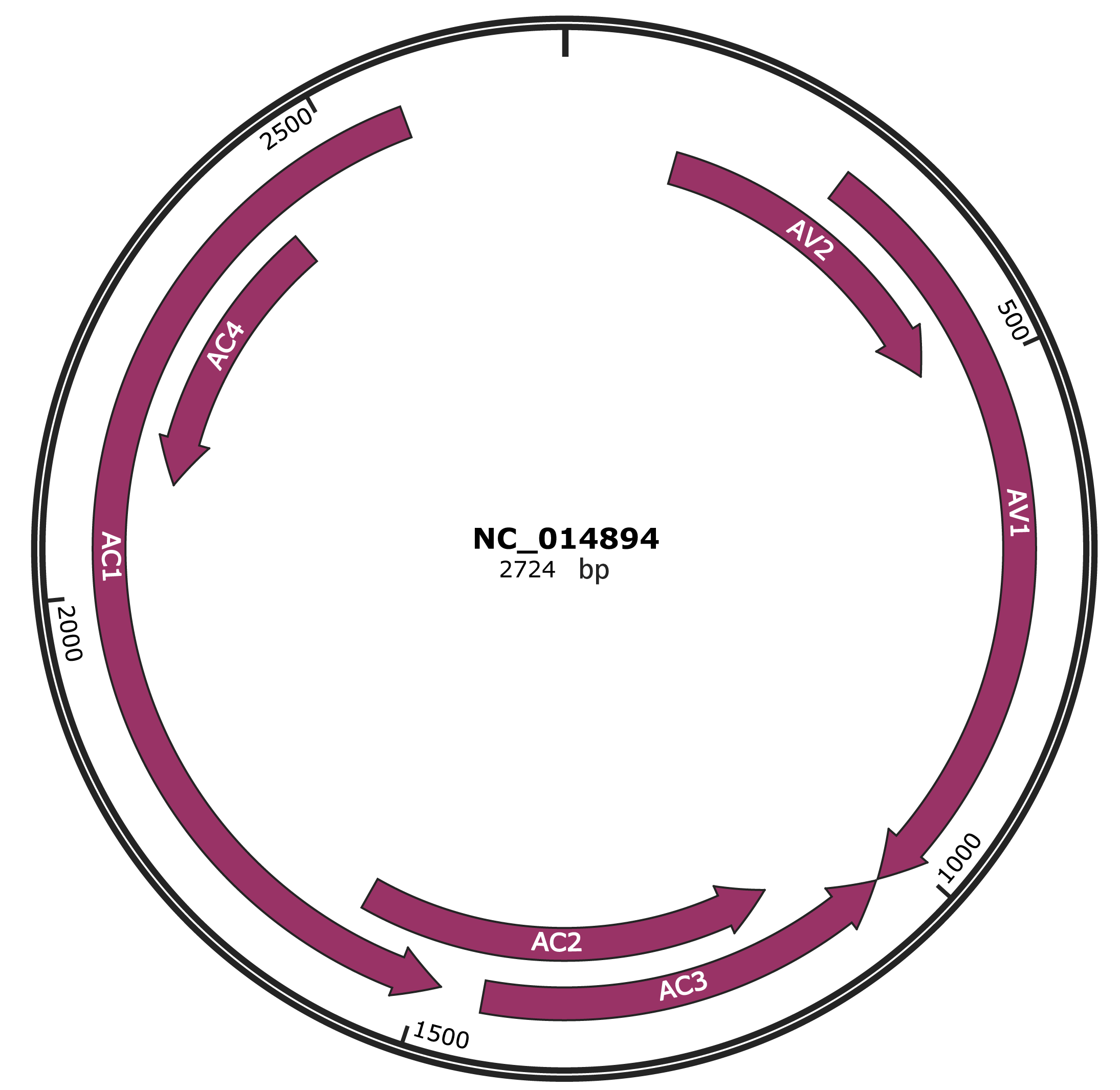
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTAGTGGTGGGTCCAGAACGCACGACGATGCAGACTCAAAGCTTAGATAACGCTCCTTTCGCTATAAGTACTTGCGCACTAAGTTTCAAATTGAAACATGTGGGATCCATTGTTAAACGAGTTCCCTGAGACGGTTCACGGGTTTCGTTGCATGCTTGCTATTAAATATCTTCAACAACTGTCTGAGGAATACTCTCCTGATACGGTTGGGTACGATCTAATTCGCGATCTAATTTCTATTTTACGTTGTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCGTATTCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAATCACGAATGTGGGCCAACAGACCCATGTACCGGAAGCCCAGAATGTACAGGATATACAGAAGCCCGGATGTTCCAAGAGGATGTGAAGGCCCATGTAAGGTGCAGTCTTTTGATGCGAAGAACGATATTGGTCACATGGGTAAGGTTATCTGTCTATCTGATGTTACTAGGGGTATTGGGCTGACCCATCGAGTAGGGAAACGTTTTTGCGTGAAGTCATTGATTTGCAGGGAGAACATCAAGACCAAGAACCATACGAATTCGGTGATGTTTTGGATCGTGAGAGACAGGCGTCCTACAGGCACCCCCTACGATTTCCAGCAAGTGTTCAATGTTTATGACAACGAGCCTTCTACGGCTACTGTAAAGAACGACCAGCGTGATCGATTCCAGGTTTTGAGGAGGTTTCAGGCGACAGTTACAGGAGGACAGTATGCTTGTAAGGAACAAGTTCCAATTAGGAAATTCTATCGTGTTAACAATTACGTGGTGTATAATCACCAGGAAGCTGGGAAGTATGAAAATCACACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTTTGAAAGTTAGGAGTTACTTCTACGATTCTGTAACGAATTAATATTAATAAAGATCGAATTTTATATCTGAATATTGATCCACATACATTGTTTGTTGAATTACATTGTACAATACGTGTTCTACAGCCTTAATTACTAAATTAATTGAGATTACACCTAGATTGTTGAGATACTTGAGGACTTGGGTTTTTAATACCCTTAAGAAAAGACCAGTCTGAGGGTGTAAGGTCGTCCAGATTCGGAAGGTCAGAAAACACTTGTGCACTCCCAGAGCTCTCCGAAGGTTGTAGTTGAATTGGATCCTGATTTTTATTATGTCCATGTTCGTCGTGAATGGACGGTCGTCGTGGCTGAGGATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATAAAGACGCCATTCCTTGTATGAGCTGCAGTGATGCGTTCCCCTGTGCGAGAATCCATGGTTGAAGCAGTTAATGGATAGATAATAAGAACACCCGCATTCAAGATCTACTCTCTTCCTCCTGTGCGCTCTCTTCGCTTCCCTGTGCTGTACTTTGATTGGTACCTGAGTACAATGGTCCTTCAAGGGTGACGAAGATCGCATTTTTCACTGCCCAGTTCTTTAGTGCTGAGTTCTTATCCTCGTCTAAGAACTCTTTATAACTGCTGTTGGGACCAGGATTGCAGAGGAAGATTGTTGGTATGCCGCCTTTAATTTGAACTGGCTTTCCGTACTTTGTGTTGGATTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTGAGGAAGTGGGGATCTACGTCATCAATGACGTTATACCAGGCCTCGTTACTGTAGATCTTTGGACTAAGGTCTAGATGCCCACACAAATAGTTATGTGGACCCAGTGATCTAGCCCACATCGTCTTCCCGGTACGACTATCTCCCTCAATCACTATACTTTGTGGTCTAAGTGGCCGCGCAGCGGCGTCGACAACGTTCTCGGCAGCCCATTCCTCAAGTTCTTCCGGAACTTGATCAAAAGAAGAAGAAGAAAAAGGAGAAACATAAACCTCCACAGGAGGTGTAAAAATCCTATCTAAATTAGCATTTAAATTATGGAATTGTAATACATAATCTTTTGGAGCTAACTCCTTAATGACTCTAAGAGCCTCTGACTTACTGCCTGCGTTAAGCGCTGCGGCGTAAGCGTCGTTGGCTGTCTGTTGTCCCCCTCTAGCAGATCGTCCGTCGATCTGAAACTCTCCCCACTCGAGAGTGTCCCCGTCCTTGTCGATGTAGGATTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGCTTGGGGAGACCAGGTCGAAGAATCGCTGATTCTGGCACTTGTATTTCCCCTCGATCTGGATGAGCACGTGCAGATGAGGTTCCCCATTTTCATGAAGTTCTCTGCAGATTTTAATATATTTTTTTGAAGTGGGGGTTTGGAAATTCTTGATTTGGGAAAGTGCTTCTTCTCTTGTGAGAGAGCACTTGGGATAAGTGAGGAAATAATTTTTGGAATTAATAAGGAACCGCTTAGGAGGCATGTTGACTAAGATAGAGGACCCGATTGACCGCTCTTGCAACTCTCCCCCTGTATATCGGGTCTCAATATATAGTGAGACCCAAATGGCAAAATTGTAATTGTGGGAATAAATTCAAAATCCTCACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_004123717.1
|
|
Location
|
121-486 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGATCCATTGTTAAACGAGTTCCCTGAGACGGTTCACGGGTTTCGTTGCATGCTTGCTATTAAATATCTTCAACAACTGTCTGAGGAATACTCTCCTGATACGGTTGGGTACGATCTAATTCGCGATCTAATTTCTATTTTACGTTGTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCGTATTCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAATCACGAATGTGGGCCAACAGACCCATGTACCGGAAGCCCAGAATGTACAGGATATACAGAAGCCCGGATGTTCCAAGAGGATGTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQQLSEEYSPDTVGYDLIRDLISILRCRNYVEASCRYRHFYPRVEGASSTELRQPVFNPCSCPHCPRHKITNVGQQTHVPEAQNVQDIQKPGCSKRM |
|
NCBI Accession
|
YP_004123718.1
|
|
Location
|
281-1033 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCGTATTCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAATCACGAATGTGGGCCAACAGACCCATGTACCGGAAGCCCAGAATGTACAGGATATACAGAAGCCCGGATGTTCCAAGAGGATGTGAAGGCCCATGTAAGGTGCAGTCTTTTGATGCGAAGAACGATATTGGTCACATGGGTAAGGTTATCTGTCTATCTGATGTTACTAGGGGTATTGGGCTGACCCATCGAGTAGGGAAACGTTTTTGCGTGAAGTCATTGATTTGCAGGGAGAACATCAAGACCAAGAACCATACGAATTCGGTGATGTTTTGGATCGTGAGAGACAGGCGTCCTACAGGCACCCCCTACGATTTCCAGCAAGTGTTCAATGTTTATGACAACGAGCCTTCTACGGCTACTGTAAAGAACGACCAGCGTGATCGATTCCAGGTTTTGAGGAGGTTTCAGGCGACAGTTACAGGAGGACAGTATGCTTGTAAGGAACAAGTTCCAATTAGGAAATTCTATCGTGTTAACAATTACGTGGTGTATAATCACCAGGAAGCTGGGAAGTATGAAAATCACACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTTTGAAAGTTAGGAGTTACTTCTACGATTCTGTAACGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYSTRAVAPTVRVTKSRMWANRPMYRKPRMYRIYRSPDVPRGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGIGLTHRVGKRFCVKSLICRENIKTKNHTNSVMFWIVRDRRPTGTPYDFQQVFNVYDNEPSTATVKNDQRDRFQVLRRFQATVTGGQYACKEQVPIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_004123719.1
|
|
Location
|
1036-1440 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACGCATCACTGCAGCTCATACAAGGAATGGCGTCTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACGACCGTCCATTCACGACGAACATGGACATAATAAAAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGAATCTGGACGACCTTACACCCTCAGACTGGTCTTTTCTTAAGGGTATTAAAAACCCAAGTCCTCAAGTATCTCAACAATCTAGGTGTAATCTCAATTAATTTAGTAATTAAGGCTGTAGAACACGTATTGTACAATGTAATTCAACAAACAATGTATGTGGATCAATATTCAGATATAAAATTCGATCTTTATTAA |
|
Protein Sequence
|
MDSRTGERITAAHTRNGVFIWEVPNPLYFKILSHDDRPFTTNMDIIKIRIQFNYNLRRALGVHKCFLTFRIWTTLHPQTGLFLRVLKTQVLKYLNNLGVISINLVIKAVEHVLYNVIQQTMYVDQYSDIKFDLY |
|
NCBI Accession
|
YP_004123720.1
|
|
Location
|
1133-1585 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGCGATCTTCGTCACCCTTGAAGGACCATTGTACTCAGGTACCAATCAAAGTACAGCACAGGGAAGCGAAGAGAGCGCACAGGAGGAAGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTATCCATTAACTGCTTCAACCATGGATTCTCGCACAGGGGAACGCATCACTGCAGCTCATACAAGGAATGGCGTCTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACGACCGTCCATTCACGACGAACATGGACATAATAAAAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGAATCTGGACGACCTTACACCCTCAGACTGGTCTTTTCTTAAGGGTATTAAAAACCCAAGTCCTCAAGTATCTCAACAATCTAGGTGTAATCTCAATTAA |
|
Protein Sequence
|
MRSSSPLKDHCTQVPIKVQHREAKRAHRRKRVDLECGCSYYLSINCFNHGFSHRGTHHCSSYKEWRLYLGGSKSPLFQDPQPRRPSIHDEHGHNKNQDPIQLQPSESSGSAQVFSDLPNLDDLTPSDWSFLKGIKNPSPQVSQQSRCNLN |
|
NCBI Accession
|
YP_004123721.1
|
|
Location
|
1482-2570 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replicase |
|
Coding Region
|
ATGCCTCCTAAGCGGTTCCTTATTAATTCCAAAAATTATTTCCTCACTTATCCCAAGTGCTCTCTCACAAGAGAAGAAGCACTTTCCCAAATCAAGAATTTCCAAACCCCCACTTCAAAAAAATATATTAAAATCTGCAGAGAACTTCATGAAAATGGGGAACCTCATCTGCACGTGCTCATCCAGATCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGACGGACGATCTGCTAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCGCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAGTTAGCTCCAAAAGATTATGTATTACAATTCCATAATTTAAATGCTAATTTAGATAGGATTTTTACACCTCCTGTGGAGGTTTATGTTTCTCCTTTTTCTTCTTCTTCTTTTGATCAAGTTCCGGAAGAACTTGAGGAATGGGCTGCCGAGAACGTTGTCGACGCCGCTGCGCGGCCACTTAGACCACAAAGTATAGTGATTGAGGGAGATAGTCGTACCGGGAAGACGATGTGGGCTAGATCACTGGGTCCACATAACTATTTGTGTGGGCATCTAGACCTTAGTCCAAAGATCTACAGTAACGAGGCCTGGTATAACGTCATTGATGACGTAGATCCCCACTTCCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAGTACGGAAAGCCAGTTCAAATTAAAGGCGGCATACCAACAATCTTCCTCTGCAATCCTGGTCCCAACAGCAGTTATAAAGAGTTCTTAGACGAGGATAAGAACTCAGCACTAAAGAACTGGGCAGTGAAAAATGCGATCTTCGTCACCCTTGAAGGACCATTGTACTCAGGTACCAATCAAAGTACAGCACAGGGAAGCGAAGAGAGCGCACAGGAGGAAGAGAGTAGATCTTGA |
|
Protein Sequence
|
MPPKRFLINSKNYFLTYPKCSLTREEALSQIKNFQTPTSKKYIKICRELHENGEPHLHVLIQIEGKYKCQNQRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDYVLQFHNLNANLDRIFTPPVEVYVSPFSSSSFDQVPEELEEWAAENVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNEAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNSALKNWAVKNAIFVTLEGPLYSGTNQSTAQGSEESAQEEESRS |
|
NCBI Accession
|
YP_004123722.1
|
|
Location
|
2114-2416 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCACGTGCTCATCCAGATCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGACGGACGATCTGCTAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCGCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAGTTAG |
|
Protein Sequence
|
MGNLICTCSSRSRGNTSARISDSSTWSPQAGQHISIRTYRELNPAPTSNPTSTRTGTLSSGESFRSTDDLLEGDNRQPTTLTPQRLTQAVSQRLLESLRS |