Ocimum mosaic virus
Basic Information
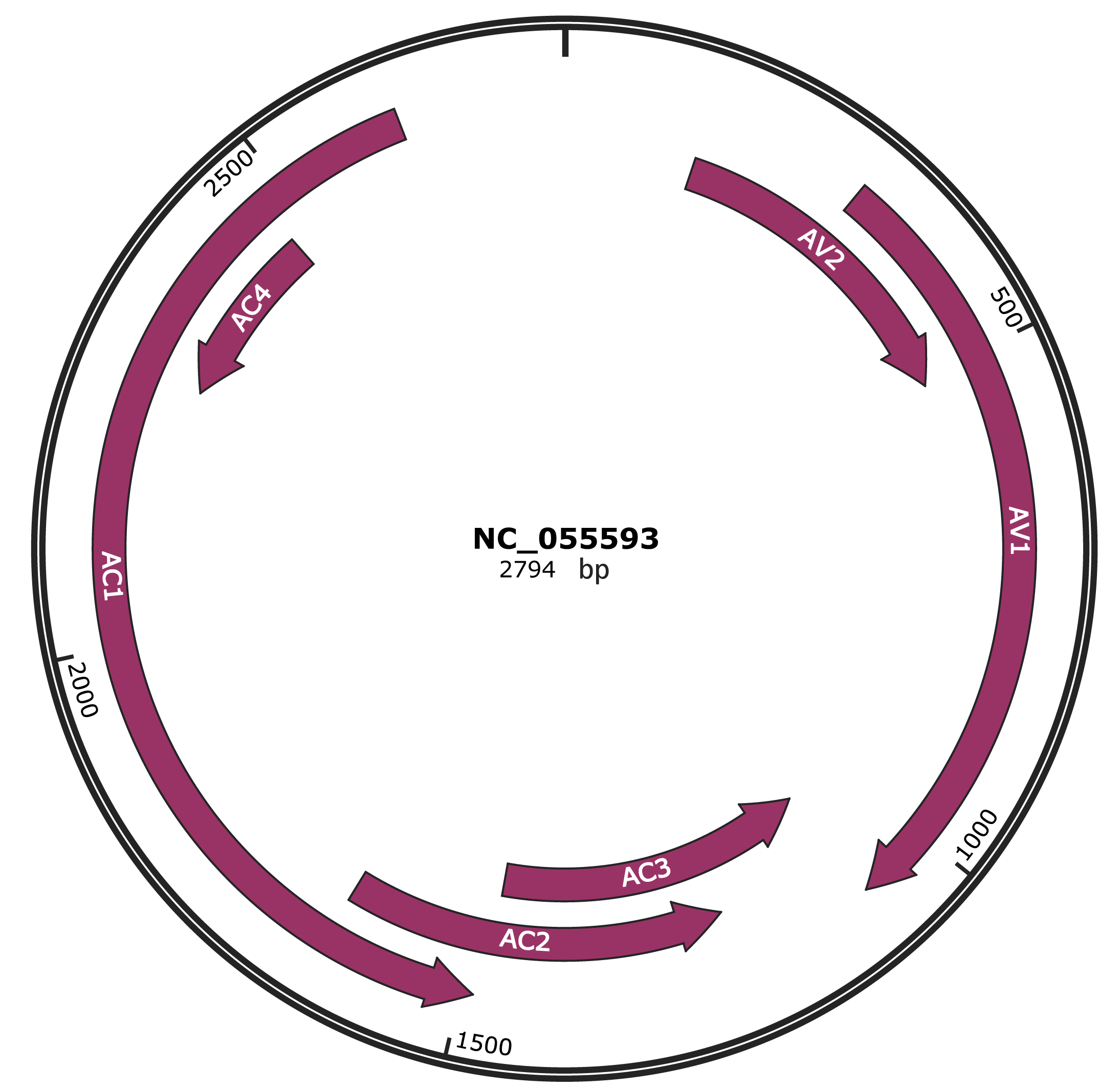
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCCCGCAACCACGCCCCGACTCGCGCGTGTCTTACACATCGTACACGTGGCATTTTATGAGGGTTTCTCACGATGTATTTTGGTACGACGGTATTTTATTAGTAAAGTTCGCCATTTTACGTATTTATGTACGATGTGGGACCCCTTGGAGAATGAATTCCCGGATACCGTTCATGGATTCCGGTGTATGCTCGCCGTCAAATATCTTCTTCTGGTGGAGTCTAAGTATGAGCCGGATACTCTAGGTCGTGATCTCATACGTGATCTTATACGTTGTTTGCGTGCATCGAGTTATAATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGCTTCCAAAGTTCGGCGTCGTCTGAATTTCGACAGCCCATACTCCGCCCGTGTACCTGTCAGCACTGTCCGTACTTCCAGAAGACGAATATGGGCCTCGCGTCCTATGTACAGAAAGCCCAAGATATACCGGATTTACAGAAGCCCGGATGTTCCAAAGGGCTGTGAAGGTCCGTGTAAAGTTCAATCTTATGAGGCCCGTCATGATGTAAAGCATACTGGTACTGTATTATGTTGCTCCGACGTTACACGTGGTAGTGGTTTGACTCACCGCGTTGGTAAGAGGTTTACTATCAAGTCTATTTACATATTGGGTAAGATCTGGATGGATGAGAATATCAAGAAGAAGAATCACACTAATATTGTCATGTTTTATCTTGTTCGGGATCGTCGGCCGTCTGATAAACCTTATGAATTTGGTTCTGTGTTTAACATGTTTGACAATGAGCCGGCTACTGCGACAGTGAAGATGGATCATCGGGATAGGTTTCAGGTTTTGCATAAGTTTTATGGTTGGGTTACCGGTGGTGAATACGCGTCTAAAGAGCAGGCGATGATTAGGAGGTTTTATAAGATATATCATCCTGTGGTGTACAACAATCAAGAGGGTGCTGAATACAAGAATCATCAGGAGAACGCTTTGTTATTGTATATGGCTTGTACTCATGCTTCTAATCCTGTGTACGCGACTCTTAAATGTCGCATATATTTTTATGACAGTGTGTCGAATTAATAAATTTTGAATTTTATATCATGATCTTCTTGCACTTCAATTGTGCCTTGCATTACATTGTACAATACATGATCAGCAGATCTAATACAAATATTTAAGCTAATAGCCCCTAATTGGTTTACATATTTCATGAACTGATATCTAAATACTCTTAAGAAATGCGATGTCTGAGGTTGTAAACGAGTGAAGATCTTGAAGGTCAGAAAACACTTCAGAATCCCCAACGCCTTCTTGAGGTTGTGGTTGAATCTGACTTGGACCACAATTATGTCGTGTCCCGTCTGGAATGGTCTGCTGTGGTGGTATAGAATTTTGAAATATAGGGGATTCGGCACGTCGGAGGTATAGACGCCACTCATTGACTGAGCTGCAGTGATATTCTCCCCTGTGCGAGAATCCATGGTTGTGGCAGTCAATGCTCAGAAAATAGCTGCAACCGCACCGGAGATCTATCCTCTTCCGCCTGATTGTTGTACGCTTGGTCTGCTTGGCTATCTTGTGTTGTACCTTGATTGGTACCTGCTGAATTGGAGTATAGGGGACTCTCGAGGGTGAAGAACTTGGCATTCTTTTCAGCCCAGGCCTTTAGCTGCTCATTCTTATCCTCATTCAGATATGATTTATAAGAAGAATTATGACCTGGATTGCATAAGAAGATAGTGGGAATGCCACCTTTAATTTGAATTGGTTTCCCGTACTTTGTGTTGCTTTGCCAATCACGTTGGGCCCCCATCAACTCTTTAAAATGCTTTAGGTAGTGGGGGTCAACATCATCAATAATGTTGTACCATGCTGAATTTGAAAATACCTTTGGGGATAGATCGAGGTGCCCACATAGATAATTATGGGGACCCAATCCCCGCGCCCAAATAGTTTTGCCGGTACGACTATCCCCCTCTATTACGATTGAGATTGGTCTCCACGGCCGCGCAGCGGAATCCTTAACATTTTCGTCAACCCAATTCCTTATTTCTTCAGGCACATTGTTGAATGTTGCATTAGCATATGGACTTACATATGGAACAGGTGGCAACTGGAAGATTTTCTCGAGATTTGCTTTCAGATTGTGGTATTGGAATATGTAATCCTTCGGCAGTTTTTCTCGAATTATTGCGAGTGCTGCTTCTGCCGAGTTAGCATTTAATGCATCAGCACATGCATCATTTGCATTTTGACAACCTCCTCTTGCACTTCTACCATCTACTTGGAATTCTCCCCATTTGAGTGTGTCTCCGTCCTTCTCAATGTATGATTTGACATCTGAGCTTGATTTAACTCCCTGAATGTTCGGATGGTAATGTGTTCCCCTGGTTGTGGCTTGAAGATCGAAGAATCGGTTATTCGTGCATGTGAATTTACCTTCGAATTGAATGAGAATGTGGAGATGAGGTTGCCCATCTTCGTGAAGCTCTCTGGCAATTTCTATGAATTTTTTATTCGTGTGTGTTTCAATTGCACGAATTTGAGTGAGGGCTTCTTCTTTAGAGAGGGAACATTTGGGATATGTGAGGAAGTAATTTTTGGCTTGAATTTTGAAGCGACGTGGAGGAGCCATTTATAGAGAGAGAATGTCTCCAATTGCTTTTCAGCTGAAGTCTCTATTGTATTGGAGACAATATATAGTGTCTCCAAATGGCATTATTGTAATTTGTAAAAGTAAGACGCTCCTTCATATCCCATCGTCCACGTGGGATCTTTTGCGGCCATCCGTTTAATATT
Gene Information
|
NCBI Accession
|
YP_010087830.1
|
|
Location
|
145-510 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGACCCCTTGGAGAATGAATTCCCGGATACCGTTCATGGATTCCGGTGTATGCTCGCCGTCAAATATCTTCTTCTGGTGGAGTCTAAGTATGAGCCGGATACTCTAGGTCGTGATCTCATACGTGATCTTATACGTTGTTTGCGTGCATCGAGTTATAATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGCTTCCAAAGTTCGGCGTCGTCTGAATTTCGACAGCCCATACTCCGCCCGTGTACCTGTCAGCACTGTCCGTACTTCCAGAAGACGAATATGGGCCTCGCGTCCTATGTACAGAAAGCCCAAGATATACCGGATTTACAGAAGCCCGGATGTTCCAAAGGGCTGTGA |
|
Protein Sequence
|
MWDPLENEFPDTVHGFRCMLAVKYLLLVESKYEPDTLGRDLIRDLIRCLRASSYNEASWRYSNFHTRFQSSASSEFRQPILRPCTCQHCPYFQKTNMGLASYVQKAQDIPDLQKPGCSKGL |
|
NCBI Accession
|
YP_010087831.1
|
|
Location
|
308-1075 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGCTTCCAAAGTTCGGCGTCGTCTGAATTTCGACAGCCCATACTCCGCCCGTGTACCTGTCAGCACTGTCCGTACTTCCAGAAGACGAATATGGGCCTCGCGTCCTATGTACAGAAAGCCCAAGATATACCGGATTTACAGAAGCCCGGATGTTCCAAAGGGCTGTGAAGGTCCGTGTAAAGTTCAATCTTATGAGGCCCGTCATGATGTAAAGCATACTGGTACTGTATTATGTTGCTCCGACGTTACACGTGGTAGTGGTTTGACTCACCGCGTTGGTAAGAGGTTTACTATCAAGTCTATTTACATATTGGGTAAGATCTGGATGGATGAGAATATCAAGAAGAAGAATCACACTAATATTGTCATGTTTTATCTTGTTCGGGATCGTCGGCCGTCTGATAAACCTTATGAATTTGGTTCTGTGTTTAACATGTTTGACAATGAGCCGGCTACTGCGACAGTGAAGATGGATCATCGGGATAGGTTTCAGGTTTTGCATAAGTTTTATGGTTGGGTTACCGGTGGTGAATACGCGTCTAAAGAGCAGGCGATGATTAGGAGGTTTTATAAGATATATCATCCTGTGGTGTACAACAATCAAGAGGGTGCTGAATACAAGAATCATCAGGAGAACGCTTTGTTATTGTATATGGCTTGTACTCATGCTTCTAATCCTGTGTACGCGACTCTTAAATGTCGCATATATTTTTATGACAGTGTGTCGAATTAA |
|
Protein Sequence
|
MKRPGDIVISTPASKVRRRLNFDSPYSARVPVSTVRTSRRRIWASRPMYRKPKIYRIYRSPDVPKGCEGPCKVQSYEARHDVKHTGTVLCCSDVTRGSGLTHRVGKRFTIKSIYILGKIWMDENIKKKNHTNIVMFYLVRDRRPSDKPYEFGSVFNMFDNEPATATVKMDHRDRFQVLHKFYGWVTGGEYASKEQAMIRRFYKIYHPVVYNNQEGAEYKNHQENALLLYMACTHASNPVYATLKCRIYFYDSVSN |
|
NCBI Accession
|
YP_010087832.1
|
|
Location
|
1072-1476 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAGAATATCACTGCAGCTCAGTCAATGAGTGGCGTCTATACCTCCGACGTGCCGAATCCCCTATATTTCAAAATTCTATACCACCACAGCAGACCATTCCAGACGGGACACGACATAATTGTGGTCCAAGTCAGATTCAACCACAACCTCAAGAAGGCGTTGGGGATTCTGAAGTGTTTTCTGACCTTCAAGATCTTCACTCGTTTACAACCTCAGACATCGCATTTCTTAAGAGTATTTAGATATCAGTTCATGAAATATGTAAACCAATTAGGGGCTATTAGCTTAAATATTTGTATTAGATCTGCTGATCATGTATTGTACAATGTAATGCAAGGCACAATTGAAGTGCAAGAAGATCATGATATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGENITAAQSMSGVYTSDVPNPLYFKILYHHSRPFQTGHDIIVVQVRFNHNLKKALGILKCFLTFKIFTRLQPQTSHFLRVFRYQFMKYVNQLGAISLNICIRSADHVLYNVMQGTIEVQEDHDIKFKIY |
|
NCBI Accession
|
YP_010087833.1
|
|
Location
|
1217-1642 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCCAAGTTCTTCACCCTCGAGAGTCCCCTATACTCCAATTCAGCAGGTACCAATCAAGGTACAACACAAGATAGCCAAGCAGACCAAGCGTACAACAATCAGGCGGAAGAGGATAGATCTCCGGTGCGGTTGCAGCTATTTTCTGAGCATTGACTGCCACAACCATGGATTCTCGCACAGGGGAGAATATCACTGCAGCTCAGTCAATGAGTGGCGTCTATACCTCCGACGTGCCGAATCCCCTATATTTCAAAATTCTATACCACCACAGCAGACCATTCCAGACGGGACACGACATAATTGTGGTCCAAGTCAGATTCAACCACAACCTCAAGAAGGCGTTGGGGATTCTGAAGTGTTTTCTGACCTTCAAGATCTTCACTCGTTTACAACCTCAGACATCGCATTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MPSSSPSRVPYTPIQQVPIKVQHKIAKQTKRTTIRRKRIDLRCGCSYFLSIDCHNHGFSHRGEYHCSSVNEWRLYLRRAESPIFQNSIPPQQTIPDGTRHNCGPSQIQPQPQEGVGDSEVFSDLQDLHSFTTSDIAFLKSI |
|
NCBI Accession
|
YP_010087834.1
|
|
Location
|
1488-2630 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTCCTCCACGTCGCTTCAAAATTCAAGCCAAAAATTACTTCCTCACATATCCCAAATGTTCCCTCTCTAAAGAAGAAGCCCTCACTCAAATTCGTGCAATTGAAACACACACGAATAAAAAATTCATAGAAATTGCCAGAGAGCTTCACGAAGATGGGCAACCTCATCTCCACATTCTCATTCAATTCGAAGGTAAATTCACATGCACGAATAACCGATTCTTCGATCTTCAAGCCACAACCAGGGGAACACATTACCATCCGAACATTCAGGGAGTTAAATCAAGCTCAGATGTCAAATCATACATTGAGAAGGACGGAGACACACTCAAATGGGGAGAATTCCAAGTAGATGGTAGAAGTGCAAGAGGAGGTTGTCAAAATGCAAATGATGCATGTGCTGATGCATTAAATGCTAACTCGGCAGAAGCAGCACTCGCAATAATTCGAGAAAAACTGCCGAAGGATTACATATTCCAATACCACAATCTGAAAGCAAATCTCGAGAAAATCTTCCAGTTGCCACCTGTTCCATATGTAAGTCCATATGCTAATGCAACATTCAACAATGTGCCTGAAGAAATAAGGAATTGGGTTGACGAAAATGTTAAGGATTCCGCTGCGCGGCCGTGGAGACCAATCTCAATCGTAATAGAGGGGGATAGTCGTACCGGCAAAACTATTTGGGCGCGGGGATTGGGTCCCCATAATTATCTATGTGGGCACCTCGATCTATCCCCAAAGGTATTTTCAAATTCAGCATGGTACAACATTATTGATGATGTTGACCCCCACTACCTAAAGCATTTTAAAGAGTTGATGGGGGCCCAACGTGATTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGTGGCATTCCCACTATCTTCTTATGCAATCCAGGTCATAATTCTTCTTATAAATCATATCTGAATGAGGATAAGAATGAGCAGCTAAAGGCCTGGGCTGAAAAGAATGCCAAGTTCTTCACCCTCGAGAGTCCCCTATACTCCAATTCAGCAGGTACCAATCAAGGTACAACACAAGATAGCCAAGCAGACCAAGCGTACAACAATCAGGCGGAAGAGGATAGATCTCCGGTGCGGTTGCAGCTATTTTCTGAGCATTGA |
|
Protein Sequence
|
MAPPRRFKIQAKNYFLTYPKCSLSKEEALTQIRAIETHTNKKFIEIARELHEDGQPHLHILIQFEGKFTCTNNRFFDLQATTRGTHYHPNIQGVKSSSDVKSYIEKDGDTLKWGEFQVDGRSARGGCQNANDACADALNANSAEAALAIIREKLPKDYIFQYHNLKANLEKIFQLPPVPYVSPYANATFNNVPEEIRNWVDENVKDSAARPWRPISIVIEGDSRTGKTIWARGLGPHNYLCGHLDLSPKVFSNSAWYNIIDDVDPHYLKHFKELMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGHNSSYKSYLNEDKNEQLKAWAEKNAKFFTLESPLYSNSAGTNQGTTQDSQADQAYNNQAEEDRSPVRLQLFSEH |
|
NCBI Accession
|
YP_010087835.1
|
|
Location
|
2276-2473 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCATCTCCACATTCTCATTCAATTCGAAGGTAAATTCACATGCACGAATAACCGATTCTTCGATCTTCAAGCCACAACCAGGGGAACACATTACCATCCGAACATTCAGGGAGTTAAATCAAGCTCAGATGTCAAATCATACATTGAGAAGGACGGAGACACACTCAAATGGGGAGAATTCCAAGTAG |
|
Protein Sequence
|
MGNLISTFSFNSKVNSHARITDSSIFKPQPGEHITIRTFRELNQAQMSNHTLRRTETHSNGENSK |