Ocimum golden mosaic virus
Basic Information
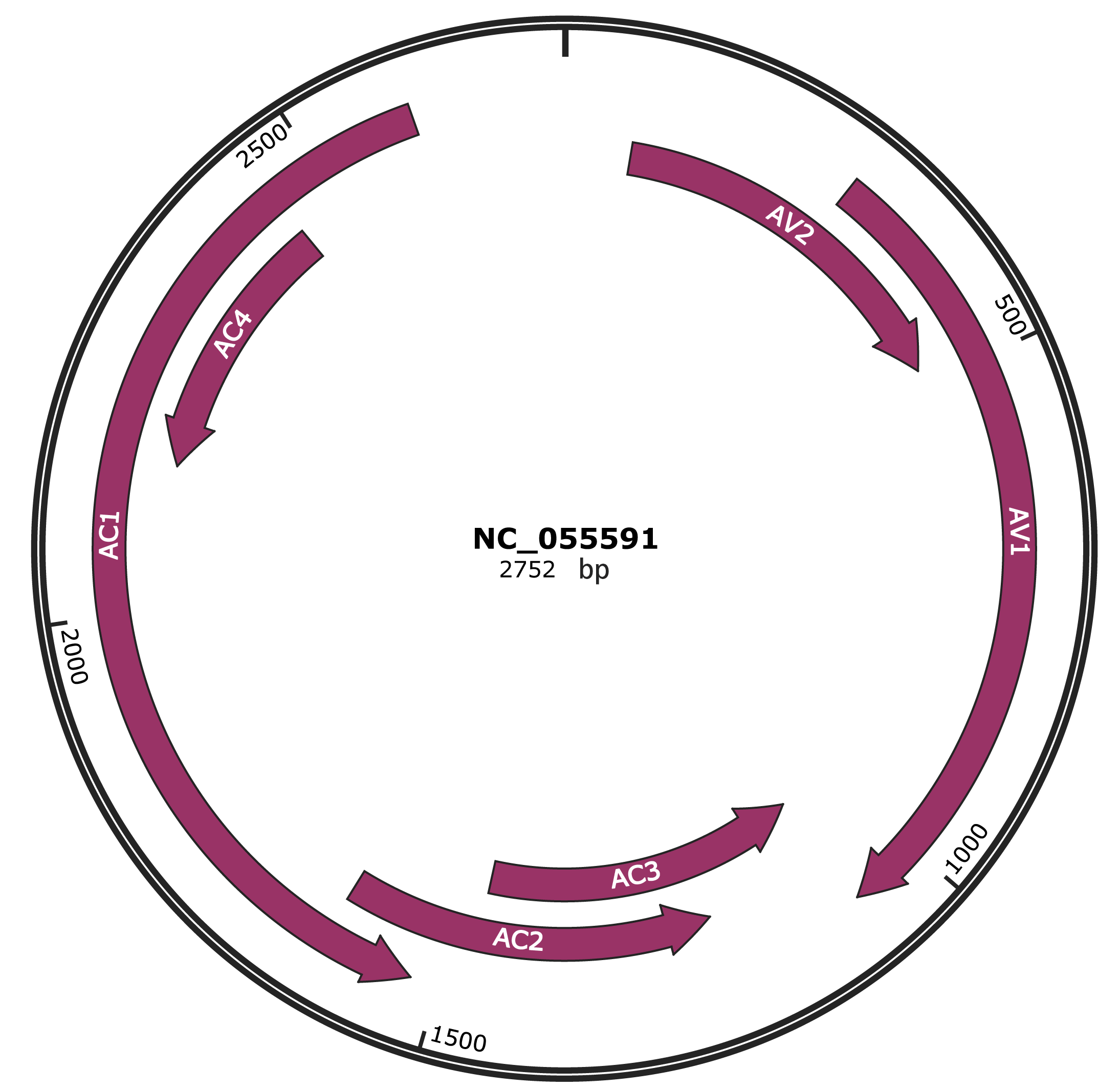
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCCCCTTTGCTGCGTGGGCCCCCCTCCTCTTTTATGTCGCCCAATCATATTGGTGCCTGAATGCCTATATACGTCATTTGTCTGTATATACGTGGCGCCCAAGTATTGGTGTATTGTAAGATGTGGGATCCTCTCTTGAATGATTTCCCTGAAACGGCTCATGCCTTCCGTTCTATGCTTGCCGTGAAATACTTGCAGTGTATAGAACAAACGTATGAACCTGGTACATTGGGTCACGATTTAATTCGAGATCTTATTTTGGTTATTCGAGCTAAAGATTATGTCGAAGCGACCAGGAGATATAATCATTTCCACGCCCGTATCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCCTATACCAACCGTGTTGCTGTCCCCACTGCCCGAGGCATAGGCAGACAGCGTCTATGGAAGTATCGGCCCATGTATCGAAAGCCCAGGATGTACAAAATGTACAAAAGTCGTGATGTTCCTATGGGCTGTGAAGGCCCATGTAAGGTTCAGTCTTATGAACAAAGGGATGATGTGAAGCATACTGGTACTGTCCGTTGTGTTAGTGATGTTACTCGTGGAACTGGTGACACTCATCGAGTTGGCAAGAGATTTTGTATTAAATCCATTTACATTTTGGGTAAGATATGGATGGATGAGAACATTAAGAAGCAGAATCACACTAATCAGGTTATTTTCTTTTTAGTCCGTGATAGAAGGCCCAATGGAGCAAGCCCAATGGATTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCTAGTACTGCGACTGTGAAGAACTATCTCCGTGATAGATACCAGGTTGTGAGGAGATTCTATGCAACCGTTGTTGGTGGACCTTCTGGCGTTAGAGAGCAGGCTTTGATCAAGAGATTTGTTCATGTTACTAATCATGTAGTTTATAATAATCAAGTAGAGGCTAAGTATGAGAATCATACTGAGAATGCCTTGTTGTTGTATATGGCGTGTACTCATGCCTCTAATCCAGTGTATGCTACTCTGAAAATACGCATCTATTTTTATGATGCAGTCACGAATTAATAAATATTGAATTTTATTTCATGGTTCTCCTTAACTTGGAGTGTGTTTACAATTACATTGTACAGTACATGATCCACTGCTCTGATGACATTGTTAATTGAAATAACGCCTAAGCTATCTAAATATTTAAGAACTTGAAACTTAAAGACTCTTAAGAAATGACCAATCCGAGGCTGTAAGGTCGTCCAGACCTGGAAATTCAGAAAACATTTGTGAATCCCCAACTCCTTCCTCATGTTGTGGTTGAACCTTATCTGGACTGATATGATGTCGTGGTTGTTGTTGAATGGTCTCTTGTCGTGGTGGGTTATTGTGAAATATAGGGGGTTGTTTATCTGCCAGATAAAAACGCCATTCCTTGCTTGAGGTGCAGTGATGAGTTCCCCTGTGCGTAAATCCATGGTTGATGCAGTCTATGTGTAGGTAGTATGAACAGCCGCAGTGTAGGTCGATACGTTTACGACGGATGGCCTTCTTCTTGGCTATTCTGTGTTGGACCTTGATGGGCACTTGAGTAGAGTGGCTCGTTGAGGGTGACGAAGGTTGCATTCTTGATAGCCCAGGCTTTGAGTGGTGTGTTTTTTTCCTCGTCGAGATATTCTTTATATGATGATGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATGCCCCCTTTAATTTGAATTGGTTTGCCGTACTTTGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTCAGATAATGCGGGTCTACGTCATCAATGACGTTGTACCAGGCATCGTTGCTGTAAACCTTCGGACTCAGATCTAAATGGCCACACAAATAATTGTGAGGTCCTAATGACCTCGCCCACATGGTCTTGCCGGTTCGACTATCACCCTCTACTACAATACTAATAGGCCTCCACGGCCGCGCAGCGGGTGTCTTGATATTTTCTGATACCCATTCCTCAAGTTCTTCTGGAACTTGATTAAAAGACGAACATAAAAATGGAGATACATAAGGAGTCGGGGGCTCCTGGAAAATTCTATCTAGATTGCTATTTAAATTATGAAATTGTAAAACAAAATCCTTTGGGGCTAATTCCTTTAATACGTTGAGAGCCTCCGATTTACTTCCTGAGTTAAGAGCTCTGGCGTAAGCGTCATTTGCTGATTGTTGCCCTCCCCTTGCGGATCTTCCATCGATCTGAAACTCGCCCCATTCGATGGTGTCTCCGTCCTTGTCCAGATATGACTTGACATCGGAACTGGACTTAGCGCCCTGTATGTTGGGGTGGAAACAGGTGCTACTGCTTGGGTGTATGTAATCGAACAGCCGATTATTCGTAATCGTAATCTTCCCCTCGAATTGGATGAGGGCGTGCAAATGAGGTTGCCCATCTTGGTGTAATTCTTTGCAGATCTTGATGAATTTTGGGTTTGATGCTAAGGATAACCCTTTTATGAATTGTAACAACAATTCTTTGGGCAATTGGCATTTGGGGTAAGTGAGAAATATGTTTTTCGCTTGAATTTTAAATCTAGGGTTCCTCATTTTGACCTGGTCAATTGGAGACACCCCGCTTCATGTCTCTTGTGTATTGGAGACAATATATAGTGTCTCTAAATGGCATAATTGTAAATATGAAATTATCAACTTTTACTTTAATTCAAATTCAAAAGCGGCCATCCGCATTAATATT
Gene Information
|
NCBI Accession
|
YP_010087818.1
|
|
Location
|
74-484 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGCCTATATACGTCATTTGTCTGTATATACGTGGCGCCCAAGTATTGGTGTATTGTAAGATGTGGGATCCTCTCTTGAATGATTTCCCTGAAACGGCTCATGCCTTCCGTTCTATGCTTGCCGTGAAATACTTGCAGTGTATAGAACAAACGTATGAACCTGGTACATTGGGTCACGATTTAATTCGAGATCTTATTTTGGTTATTCGAGCTAAAGATTATGTCGAAGCGACCAGGAGATATAATCATTTCCACGCCCGTATCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCCTATACCAACCGTGTTGCTGTCCCCACTGCCCGAGGCATAGGCAGACAGCGTCTATGGAAGTATCGGCCCATGTATCGAAAGCCCAGGATGTACAAAATGTACAAAAGTCGTGA |
|
Protein Sequence
|
MPIYVICLYIRGAQVLVYCKMWDPLLNDFPETAHAFRSMLAVKYLQCIEQTYEPGTLGHDLIRDLILVIRAKDYVEATRRYNHFHARIEGASKAELRQPLYQPCCCPHCPRHRQTASMEVSAHVSKAQDVQNVQKS |
|
NCBI Accession
|
YP_010087819.1
|
|
Location
|
294-1070 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATAATCATTTCCACGCCCGTATCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCCTATACCAACCGTGTTGCTGTCCCCACTGCCCGAGGCATAGGCAGACAGCGTCTATGGAAGTATCGGCCCATGTATCGAAAGCCCAGGATGTACAAAATGTACAAAAGTCGTGATGTTCCTATGGGCTGTGAAGGCCCATGTAAGGTTCAGTCTTATGAACAAAGGGATGATGTGAAGCATACTGGTACTGTCCGTTGTGTTAGTGATGTTACTCGTGGAACTGGTGACACTCATCGAGTTGGCAAGAGATTTTGTATTAAATCCATTTACATTTTGGGTAAGATATGGATGGATGAGAACATTAAGAAGCAGAATCACACTAATCAGGTTATTTTCTTTTTAGTCCGTGATAGAAGGCCCAATGGAGCAAGCCCAATGGATTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCTAGTACTGCGACTGTGAAGAACTATCTCCGTGATAGATACCAGGTTGTGAGGAGATTCTATGCAACCGTTGTTGGTGGACCTTCTGGCGTTAGAGAGCAGGCTTTGATCAAGAGATTTGTTCATGTTACTAATCATGTAGTTTATAATAATCAAGTAGAGGCTAAGTATGAGAATCATACTGAGAATGCCTTGTTGTTGTATATGGCGTGTACTCATGCCTCTAATCCAGTGTATGCTACTCTGAAAATACGCATCTATTTTTATGATGCAGTCACGAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVAVPTARGIGRQRLWKYRPMYRKPRMYKMYKSRDVPMGCEGPCKVQSYEQRDDVKHTGTVRCVSDVTRGTGDTHRVGKRFCIKSIYILGKIWMDENIKKQNHTNQVIFFLVRDRRPNGASPMDFGQVFNMFDNEPSTATVKNYLRDRYQVVRRFYATVVGGPSGVREQALIKRFVHVTNHVVYNNQVEAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_010087820.1
|
|
Location
|
1067-1471 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACTCATCACTGCACCTCAAGCAAGGAATGGCGTTTTTATCTGGCAGATAAACAACCCCCTATATTTCACAATAACCCACCACGACAAGAGACCATTCAACAACAACCACGACATCATATCAGTCCAGATAAGGTTCAACCACAACATGAGGAAGGAGTTGGGGATTCACAAATGTTTTCTGAATTTCCAGGTCTGGACGACCTTACAGCCTCGGATTGGTCATTTCTTAAGAGTCTTTAAGTTTCAAGTTCTTAAATATTTAGATAGCTTAGGCGTTATTTCAATTAACAATGTCATCAGAGCAGTGGATCATGTACTGTACAATGTAATTGTAAACACACTCCAAGTTAAGGAGAACCATGAAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDLRTGELITAPQARNGVFIWQINNPLYFTITHHDKRPFNNNHDIISVQIRFNHNMRKELGIHKCFLNFQVWTTLQPRIGHFLRVFKFQVLKYLDSLGVISINNVIRAVDHVLYNVIVNTLQVKENHEIKFNIY |
|
NCBI Accession
|
YP_010087821.1
|
|
Location
|
1212-1619 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCAACCTTCGTCACCCTCAACGAGCCACTCTACTCAAGTGCCCATCAAGGTCCAACACAGAATAGCCAAGAAGAAGGCCATCCGTCGTAAACGTATCGACCTACACTGCGGCTGTTCATACTACCTACACATAGACTGCATCAACCATGGATTTACGCACAGGGGAACTCATCACTGCACCTCAAGCAAGGAATGGCGTTTTTATCTGGCAGATAAACAACCCCCTATATTTCACAATAACCCACCACGACAAGAGACCATTCAACAACAACCACGACATCATATCAGTCCAGATAAGGTTCAACCACAACATGAGGAAGGAGTTGGGGATTCACAAATGTTTTCTGAATTTCCAGGTCTGGACGACCTTACAGCCTCGGATTGGTCATTTCTTAAGAGTCTTTAA |
|
Protein Sequence
|
MQPSSPSTSHSTQVPIKVQHRIAKKKAIRRKRIDLHCGCSYYLHIDCINHGFTHRGTHHCTSSKEWRFYLADKQPPIFHNNPPRQETIQQQPRHHISPDKVQPQHEEGVGDSQMFSEFPGLDDLTASDWSFLKSL |
|
NCBI Accession
|
YP_010087822.1
|
|
Location
|
1528-2604 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGAGGAACCCTAGATTTAAAATTCAAGCGAAAAACATATTTCTCACTTACCCCAAATGCCAATTGCCCAAAGAATTGTTGTTACAATTCATAAAAGGGTTATCCTTAGCATCAAACCCAAAATTCATCAAGATCTGCAAAGAATTACACCAAGATGGGCAACCTCATTTGCACGCCCTCATCCAATTCGAGGGGAAGATTACGATTACGAATAATCGGCTGTTCGATTACATACACCCAAGCAGTAGCACCTGTTTCCACCCCAACATACAGGGCGCTAAGTCCAGTTCCGATGTCAAGTCATATCTGGACAAGGACGGAGACACCATCGAATGGGGCGAGTTTCAGATCGATGGAAGATCCGCAAGGGGAGGGCAACAATCAGCAAATGACGCTTACGCCAGAGCTCTTAACTCAGGAAGTAAATCGGAGGCTCTCAACGTATTAAAGGAATTAGCCCCAAAGGATTTTGTTTTACAATTTCATAATTTAAATAGCAATCTAGATAGAATTTTCCAGGAGCCCCCGACTCCTTATGTATCTCCATTTTTATGTTCGTCTTTTAATCAAGTTCCAGAAGAACTTGAGGAATGGGTATCAGAAAATATCAAGACACCCGCTGCGCGGCCGTGGAGGCCTATTAGTATTGTAGTAGAGGGTGATAGTCGAACCGGCAAGACCATGTGGGCGAGGTCATTAGGACCTCACAATTATTTGTGTGGCCATTTAGATCTGAGTCCGAAGGTTTACAGCAACGATGCCTGGTACAACGTCATTGATGACGTAGACCCGCATTATCTGAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACAAAGTACGGCAAACCAATTCAAATTAAAGGGGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCATCATATAAAGAATATCTCGACGAGGAAAAAAACACACCACTCAAAGCCTGGGCTATCAAGAATGCAACCTTCGTCACCCTCAACGAGCCACTCTACTCAAGTGCCCATCAAGGTCCAACACAGAATAGCCAAGAAGAAGGCCATCCGTCGTAA |
|
Protein Sequence
|
MRNPRFKIQAKNIFLTYPKCQLPKELLLQFIKGLSLASNPKFIKICKELHQDGQPHLHALIQFEGKITITNNRLFDYIHPSSSTCFHPNIQGAKSSSDVKSYLDKDGDTIEWGEFQIDGRSARGGQQSANDAYARALNSGSKSEALNVLKELAPKDFVLQFHNLNSNLDRIFQEPPTPYVSPFLCSSFNQVPEELEEWVSENIKTPAARPWRPISIVVEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNTPLKAWAIKNATFVTLNEPLYSSAHQGPTQNSQEEGHPS |
|
NCBI Accession
|
YP_010087823.1
|
|
Location
|
2157-2450 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCATTTGCACGCCCTCATCCAATTCGAGGGGAAGATTACGATTACGAATAATCGGCTGTTCGATTACATACACCCAAGCAGTAGCACCTGTTTCCACCCCAACATACAGGGCGCTAAGTCCAGTTCCGATGTCAAGTCATATCTGGACAAGGACGGAGACACCATCGAATGGGGCGAGTTTCAGATCGATGGAAGATCCGCAAGGGGAGGGCAACAATCAGCAAATGACGCTTACGCCAGAGCTCTTAACTCAGGAAGTAAATCGGAGGCTCTCAACGTATTAA |
|
Protein Sequence
|
MGNLICTPSSNSRGRLRLRIIGCSITYTQAVAPVSTPTYRALSPVPMSSHIWTRTETPSNGASFRSMEDPQGEGNNQQMTLTPELLTQEVNRRLSTY |