Mungbean yellow mosaic India virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000858565.1 |
| Release date |
2015/2/13 |
| Submitter |
Pant,V., Gupta,D., Choudhury,N.R., Malathi,V.G., Varma,A., Mukherjee,S.K. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
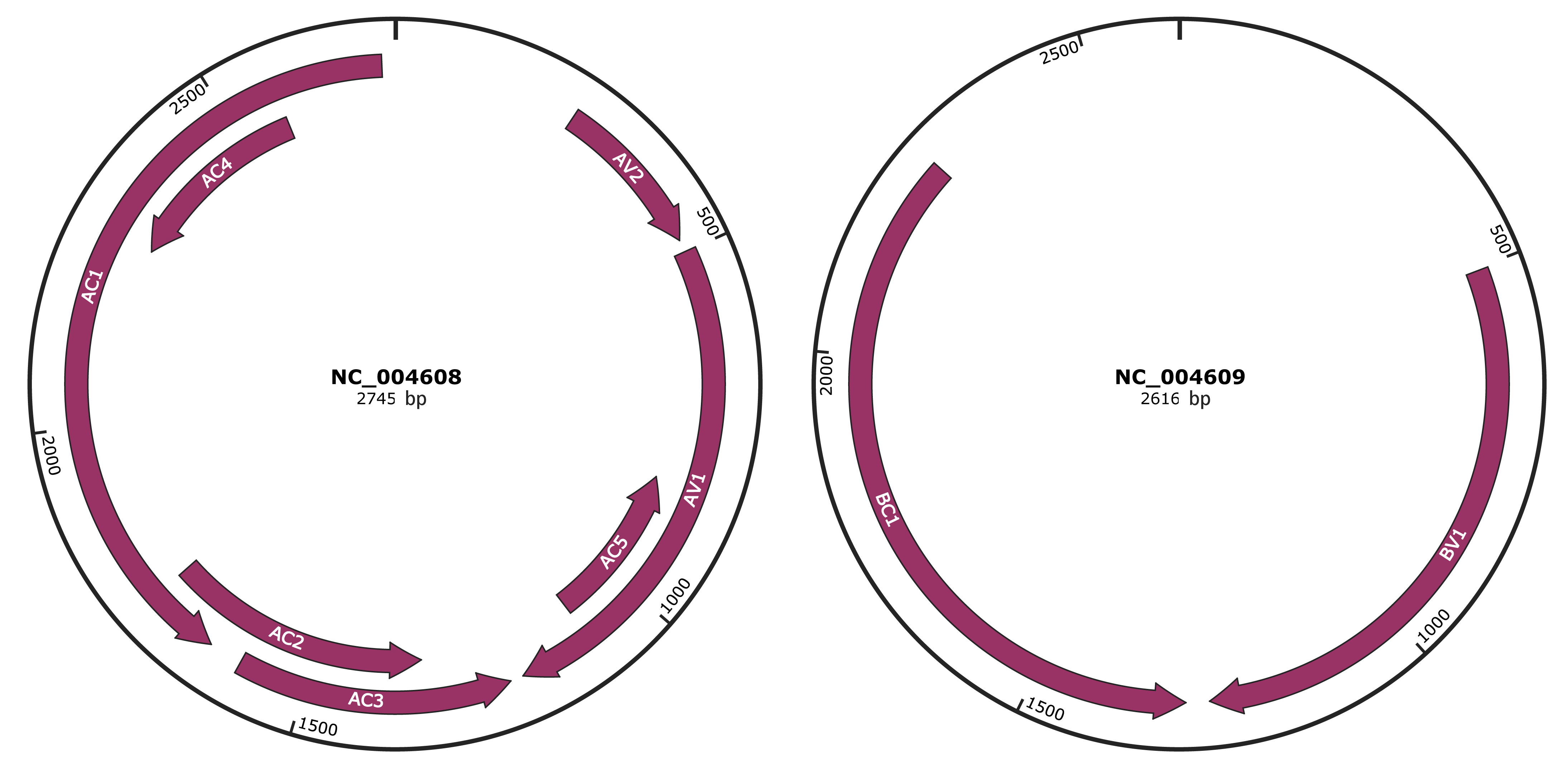
JBrowse
Genome
ATCGGTGTACACCGATTACTTCTCTATCCCCCTATCGGTGTATCGGTGTCTTATATATACTAGAGCTACTAAAAGCCCATAGGGGCACTCAGCTATAATATTACCTGAGTGCCCCGCGACCGGTGTATTGGGGTTACTTTAACTTTTCTGCTTTTGTGGTACCCTTATCTTTAGTCGTTCAATCAGAAGCGCTCCTCAGCGCTATGTTAATTCAAATTTGAATTATAAAGCAAGTGGACACTCTGAACCCACTAACAATGTGGGATCCATTGTTGAACGACTTTCCCAAATCAGTGCATGGATTCCGGTGCATGTTGGCAATAAAGTATTTGCAACAAGTTCAAGAGAATTACCCTTCTAATTCTCTAGGTTACTCGTACCTTACAGGGTTAATTCAGGTATTGCGCATCCGGAATCATGCCAAAGCGGACCTACGAATACTGCATTCTCTACCCCGATATCGAATGCACGGAGGAGATTGAACTTCGATACCCCGCTCATGCTGCCTGCCTCTGCGGGAGGTGTCCCTACCAACATGAAAAGGAGGCGTTGGACCAACCGCCCCATGTGGAGGAAACCTCGGTTTTACCGACTGTATAGGTCCCCTGATGTCCCTCGTGGTTGTGAGGGACCATGTAAAGTTCAATCATTTGAAGCAAAGGATATTGCCCCCACAGGCAAAGTGATTTGCATATCGGACGTNACTAAAAGTAATGGAATTACNCCTCGTTTAGGCAAACGTTTTTGTTGCATCAAGTCCGTGAACATTACTGGGAAGGTTTGGATGGACGAAAACATTAAGTCCAAAAATCACACGAATACTGTGATGTTCAAGTTATGTCGTGACAGACGACCATTTGGTACACCCATGGATTTTGGTCAAGTGTTCAACATGTATGACAACGAGCCCAGTACAGCCACTGTGAAGAACGATCTGCGTGATCGTTATCAAGTCTTGCGAAAGTTTAGTGCCACTGTTACTGGTGGCCAATATGCTTGTAAAGAACAAGCCATGGTGAATCGTTTCTTCAAGGTTAATAATTATGTTGTTTACAACCACCAGGAGGCAGCGAAGTATGAGAACCATACTGAGAACGCATTATTATTGTACATGGCATGTACTCATGCCTCAAATCCTGTGTATGCAACACTTAAAATTCGGATCTATTTTTATGATTCGATATTGAATTAATAAAGATTGTATTGAGCATTATGCGTAAAGCTTACATCCTCCACCAAGTGGAGTTTTATTGTACAGGAAATCCGATGCGAAATATAAAATATTTGCTAAGCTAATGACCCCTAAATTATTTAAAAACTTAAATAATTGGTTACGGAAGATCGATAAGATCATCCCAGAAGTCGCCTTCATATAATGGTAGAGCTTCAAGTCCAGGAAGCACTTGTGCATCCCCAGTGCTTTCTTCAACCTGTGATTGAACATATGCGCAGCTTGGTGACCATTCATTCTGGACTCTGCTAGAATTGGACTGTGGTGCATGATCTTGAAAGAGAGGGGATTTTGCACCTCCCAGATATAGACGCCACTCCTGAGTTGAGCTGCAGTGATGTTCTCCCCTGTGCGAAAATCCATAGTTACGGCAGTTGATATGGATGTAATAGCTACACCCACACTTCAGGTCAATTCGAGATCGTCGAATTGCTCTCTTCTTGGCGACCCTGTGTTGAACCTTGATTGACGGTGGAGAACAGTGGTTCTTTGAGGGTGTAGAATTCCGCATTCTTTGAAGCCCACTGTTTAAGCGCAGCATTGTTCTCTTCATCCAAGTACTCTTTATAGGAGGACTTGGGACCAGGGTTACACAGAAAGATGGTGGGGATACCACCTTTAATTTTAGTGGGCTTCCCGTACTTGACGTTAGACTGCCAGTCTCTTTGCGCGCCCATGAATTCTTTGAAATGTTTCAAATAATGTGGATCAACGTCATCGATGACGTTGTACCATGCCTCGTTAGAGTATGTTTTGTCGTTTAGATCCAAATGGCCGCAAAGATAATTATGAGGACCTATGGCACGTGCCCACATGGTTTTACCCGTGCGACTATCTCCTTCAATAACTATACTAATAGGTCTATCTGGCCGCGCGGCATCTCTCACATTTCTTTCAGCCCATGAAGAAATGTAGCTTGGAACCTTGTCGAATGACTCCAATGTAAAAGGCGACTCATATGCCTGTGTAGGCTCTGTGAATATCCGAGACAAATTACAATTTAAGTTATGAAATTGTAAAATGAAATCCTTAGGAGCCTTTTCCTTCAATATAAGGAGGGCCTCCAACTTTGATCCAGAGTTGAGTGCCTCGGCGTATGCGTCGTTGGCAGATTGTTTACCTCCTCTAGCTGATCTGCCATCGATTTGGAAGGTTCCATGATCAAGAATGTCTCCGTCTTTCTCCATGTATGTTTTAACATCTGAGCAGCTTTTAGCTCGCTGAATGTTCGGATGGTAATATGCCGATCTGCATCTGGAATGGAGGTCGAAGAACCTTTGGTTTTTCGTTTGTTGTTTCCCTTCGAACTGAAGCAGAACATGGAGATGAGGTTGTCCATCTTCATGGAGTTCTCGACAGATGCGGATGAACTTCTTGTTAACTGGTGTTGACAAGGCTAGAAGTTGTTCAAGAGCGTCCTCCTTTGTAAGAGGACATTTGGGATATGTCAAGAAATAGTTTTTTGCGTTTATAGCAAAACGACCTTCCCTTGGCATATTTGAAGTCGTTTTTGT
ATCGGTGTACACCGATTACTTCTCTATCCCCCTATCGGTGTATTGGTGTACTATATATAGTAAAGTTACTAGGGGCTCTCAGATATAATATTACCTGAGAGCCCCGCGATCGGTGTATCGGTTTAGAGCACGTGGGTGGTCCTCTAATACGTGGGCACTATGGAGTCTCGCTCGAAGCTTGTTTATTGAACGACTACTTAGAGTTACAGGTAACCGATGAGTGACCGTTCGTACATGGACAAATTTGTCTTTTCCTCAAAAAGACCGTTTTTGCATTCGGTGTTCAACTTTTAATGCCTAAGACCGGGAAACCCTTGGGGTATTTATGTCATTTCATTTGAAATGACTTTAATTTGAAATCGTTTTTCTTTAAAAAACGATATTCGTCCAATTTGTCCATACTAAGCTATACGCACAATGTCGTTCGTTTAATTTTATTTAAACATTTCAATATCTTCATCTACATATAAATCAAAACATGAACGTGAGTTTTCAACCATGAAATGTTTACTCGTAATTATCGCACCCCTTTTAAATTACGCCATGATAATTTTGGTTATAGATGGCAGCCTATGACACCGTCAAGAGGACGTTTACGTCTTCATAAGCCTAGTGCTTCACGTAAATTATCATATGACCGAGTTGAACGGGAAATGCGCACCAATTCTATCGTTGAGGTTCAACATGGAAGCCATATGTCCCTTGAGAAGAATACGGATGTATTTTCATTTGTGCAATACCCTGTTCGTGGAATAAACGGTGACGGACGTTGTAGGGATTACATCAAGTTACTTAAACTTGATGTCTCTGGTGTGATAAACATCAAGTCTTCGAATGGAGACCAAAGCATGGAACCAGGTGACAAGTTAAGTGGGCTATTTATTCTGACTGTCTTGCTTGATAAGAAACCCTATCTTCCAGAAGGTGTGAACAAGTTACCCTCCTTTGCGGAGTTATTTGGACCTTATTCTGCTGCATATGCGAATATACACCTCTTAGATTCCCAGAAGCCCCGCTTCAAGGTCCTTGGGACAATAAAGAAGTTCGTGAACTGCACATCAGGGACAATATATGGTCCTTTGAAATTAAATATGCCGTTGTCCCGGCGAAAGTGTCCTTTGTGGACTACGTTCAAGGACCCTGATCAGGGTAACTGTGGTGGAAATTATAAGAATTTTCCTGCTATTGTATTGAGCTATGCATTTATATCCATGCATAGCCTAGTTGTGGAACCATATTTTCAATTTGAATTGAAATACGTTGGATAAAATAAATAAAGATTTATTTATTTTCACTATGTTACAACACTTTGTTCACATTAGAACGTTGACTTATGAGACATTTGCTAATAGTCGTCTCTATAATGTCCTCTATTTCTCTCTTGCTCATTGCGTTAGACTGGGTCTGAGATATTGAATCTCCAGGATCCAATGATGCCTCTGGCAATTTGTGCAAATGTCTAAGTGGGTAATCTGCGTCTGAAGCGCTCGTGTTGTCTAGAATACTGGGCCTCTCGTTATTTGTGTAACGCATGGAGCTACTCCGTCCAATAGATGACCTTGTAGCCCAAGTCTCACCTGGCTGTAGCATAATGGGCCTATGGCCAGTATTTGGATATGGACCCTGATTGGGTCCTGGATTAAGCAAACGCCTAATGGGCTTGGGCTTCTCAACAGACCAAAAGTCCACACAGTCTGCAGTGTAGTCTTTAGACAATATGTTTATTGTCGGGGGTTTAAACCTTATGTCTGTTGAGTGCTTTGCGGAAGACAATTTCAGTTTGGCCCTTATCTGGGCAAATGTTGTTCCGTCGATCACGTTTGAGTCTTCGACCTTGTACACTATCTCCCATGGTGTTTCATCCTTTAGAGAGAAGAAGGATGATGAGAAATAATGGAGATCGACGTTACATGCAATTGGGAAGGTGAAAGCAGCTTGTGCTGCTTGTTCATAGCTTAGCCTTGTGTCACGAATTGTGACGATGACCGTTCCCTTGGCGTTGAACGGAACTTGGTTTCTGTACTCGATCACAGCATGGTCGACCTTCATGCATCTACCCATTATCTGGACAGTCTTCTGTTCCAGATAAGAAGGAAATTGTAATTTGATGGGCATCTCGTTGTTGGATAGTCTGTATTCGCAACTCTTTGTCTCCACATATTTGTTATTAATCAACTGCCCCCTGAAAATGACCACACACCCGGAAATTATTCTAATAATTTCAATTAGCGCGCAGCGGCAATGAGAAGAGTTTACAATTATAATCATAATTTAAACCAAACAAATATAAAAAACAGCTATTACCTGATTTTTGTAATACTCCCAGAAAATAAGAGCACTGGATGTGCACAGAGGAAGTAACAAATATTTTATTAAATATTTGTTGTTGTGATAATTGTGATTGATTCTATCAATCGATTTAAATAATTGAGTAACATGCGCAGGATTGGGTCCTGGATATTAAATAGGGGATTATTTAATATCCCTAAATGTACATATCTGGTGCCTCCATCGTTTCGGTGTCTAAGCGCATGTTTCTAGAGCGAGAAACTTGTTTCTAGACGAGAGATGCTTAGCAAAACGCAAAATGCTAGGCAAAAGAGCGTGTCGTTTCGA
Gene Information
|
NCBI Accession
|
NP_803145.1
|
|
Location
|
258-482 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTGTTGAACGACTTTCCCAAATCAGTGCATGGATTCCGGTGCATGTTGGCAATAAAGTATTTGCAACAAGTTCAAGAGAATTACCCTTCTAATTCTCTAGGTTACTCGTACCTTACAGGGTTAATTCAGGTATTGCGCATCCGGAATCATGCCAAAGCGGACCTACGAATACTGCATTCTCTACCCCGATATCGAATGCACGGAGGAGATTGA |
|
Protein Sequence
|
MWDPLLNDFPKSVHGFRCMLAIKYLQQVQENYPSNSLGYSYLTGLIQVLRIRNHAKADLRILHSLPRYRMHGGD |
|
NCBI Accession
|
NP_803146.1
|
|
Location
|
500-1192 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCTGCCTGCCTCTGCGGGAGGTGTCCCTACCAACATGAAAAGGAGGCGTTGGACCAACCGCCCCATGTGGAGGAAACCTCGGTTTTACCGACTGTATAGGTCCCCTGATGTCCCTCGTGGTTGTGAGGGACCATGTAAAGTTCAATCATTTGAAGCAAAGGATATTGCCCCCACAGGCAAAGTGATTTGCATATCGGACGTNACTAAAAGTAATGGAATTACNCCTCGTTTAGGCAAACGTTTTTGTTGCATCAAGTCCGTGAACATTACTGGGAAGGTTTGGATGGACGAAAACATTAAGTCCAAAAATCACACGAATACTGTGATGTTCAAGTTATGTCGTGACAGACGACCATTTGGTACACCCATGGATTTTGGTCAAGTGTTCAACATGTATGACAACGAGCCCAGTACAGCCACTGTGAAGAACGATCTGCGTGATCGTTATCAAGTCTTGCGAAAGTTTAGTGCCACTGTTACTGGTGGCCAATATGCTTGTAAAGAACAAGCCATGGTGAATCGTTTCTTCAAGGTTAATAATTATGTTGTTTACAACCACCAGGAGGCAGCGAAGTATGAGAACCATACTGAGAACGCATTATTATTGTACATGGCATGTACTCATGCCTCAAATCCTGTGTATGCAACACTTAAAATTCGGATCTATTTTTATGATTCGATATTGAATTAA |
|
Protein Sequence
|
MLPASAGGVPTNMKRRRWTNRPMWRKPRFYRLYRSPDVPRGCEGPCKVQSFEAKDIAPTGKVICISDVTKSNGITPRLGKRFCCIKSVNITGKVWMDENIKSKNHTNTVMFKLCRDRRPFGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVLRKFSATVTGGQYACKEQAMVNRFFKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
NP_803147.1
|
|
Location
|
836-1087 |
|
Gene Name
|
AC5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGGTTCTCATACTTCGCTGCCTCCTGGTGGTTGTAAACAACATAATTATTAACCTTGAAGAAACGATTCACCATGGCTTGTTCTTTACAAGCATATTGGCCACCAGTAACAGTGGCACTAAACTTTCGCAAGACTTGATAACGATCACGCAGATCGTTCTTCACAGTGGCTGTACTGGGCTCGTTGTCATACATGTTGAACACTTGACCAAAATCCATGGGTGTACCAAATGGTCGTCTGTCACGACATAA |
|
Protein Sequence
|
MVLILRCLLVVVNNIIINLEETIHHGLFFTSILATSNSGTKLSQDLITITQIVLHSGCTGLVVIHVEHLTKIHGCTKWSSVTT |
|
NCBI Accession
|
NP_803148.1
|
|
Location
|
1211-1594 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTTCGCACAGGGGAGAACATCACTGCAGCTCAACTCAGGAGTGGCGTCTATATCTGGGAGGTGCAAAATCCCCTCTCTTTCAAGATCATGCACCACAGTCCAATTCTAGCAGAGTCCAGAATGAATGGTCACCAAGCTGCGCATATGTTCAATCACAGGTTGAAGAAAGCACTGGGGATGCACAAGTGCTTCCTGGACTTGAAGCTCTACCATTATATGAAGGCGACTTCTGGGATGATCTTATCGATCTTCCGTAACCAATTATTTAAGTTTTTAAATAATTTAGGGGTCATTAGCTTAGCAAATATTTTATATTTCGCATCGGATTTCCTGTACAATAAAACTCCACTTGGTGGAGGATGTAAGCTTTACGCATAA |
|
Protein Sequence
|
MDFRTGENITAAQLRSGVYIWEVQNPLSFKIMHHSPILAESRMNGHQAAHMFNHRLKKALGMHKCFLDLKLYHYMKATSGMILSIFRNQLFKFLNNLGVISLANILYFASDFLYNKTPLGGGCKLYA |
|
NCBI Accession
|
NP_803149.1
|
|
Location
|
1332-1742 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGCGGAATTCTACACCCTCAAAGAACCACTGTTCTCCACCGTCAATCAAGGTTCAACACAGGGTCGCCAAGAAGAGAGCAATTCGACGATCTCGAATTGACCTGAAGTGTGGGTGTAGCTATTACATCCATATCAACTGCCGTAACTATGGATTTTCGCACAGGGGAGAACATCACTGCAGCTCAACTCAGGAGTGGCGTCTATATCTGGGAGGTGCAAAATCCCCTCTCTTTCAAGATCATGCACCACAGTCCAATTCTAGCAGAGTCCAGAATGAATGGTCACCAAGCTGCGCATATGTTCAATCACAGGTTGAAGAAAGCACTGGGGATGCACAAGTGCTTCCTGGACTTGAAGCTCTACCATTATATGAAGGCGACTTCTGGGATGATCTTATCGATCTTCCGTAA |
|
Protein Sequence
|
MRNSTPSKNHCSPPSIKVQHRVAKKRAIRRSRIDLKCGCSYYIHINCRNYGFSHRGEHHCSSTQEWRLYLGGAKSPLFQDHAPQSNSSRVQNEWSPSCAYVQSQVEESTGDAQVLPGLEALPLYEGDFWDDLIDLP |
|
NCBI Accession
|
NP_803150.1
|
|
Location
|
1642-2727 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCAAGGGAAGGTCGTTTTGCTATAAACGCAAAAAACTATTTCTTGACATATCCCAAATGTCCTCTTACAAAGGAGGACGCTCTTGAACAACTTCTAGCCTTGTCAACACCAGTTAACAAGAAGTTCATCCGCATCTGTCGAGAACTCCATGAAGATGGACAACCTCATCTCCATGTTCTGCTTCAGTTCGAAGGGAAACAACAAACGAAAAACCAAAGGTTCTTCGACCTCCATTCCAGATGCAGATCGGCATATTACCATCCGAACATTCAGCGAGCTAAAAGCTGCTCAGATGTTAAAACATACATGGAGAAAGACGGAGACATTCTTGATCATGGAACCTTCCAAATCGATGGCAGATCAGCTAGAGGAGGTAAACAATCTGCCAACGACGCATACGCCGAGGCACTCAACTCTGGATCAAAGTTGGAGGCCCTCCTTATATTGAAGGAAAAGGCTCCTAAGGATTTCATTTTACAATTTCATAACTTAAATTGTAATTTGTCTCGGATATTCACAGAGCCTACACAGGCATATGAGTCGCCTTTTACATTGGAGTCATTCGACAAGGTTCCAAGCTACATTTCTTCATGGGCTGAAAGAAATGTGAGAGATGCCGCGCGGCCAGATAGACCTATTAGTATAGTTATTGAAGGAGATAGTCGCACGGGTAAAACCATGTGGGCACGTGCCATAGGTCCTCATAATTATCTTTGCGGCCATTTGGATCTAAACGACAAAACATACTCTAACGAGGCATGGTACAACGTCATCGATGACGTTGATCCACATTATTTGAAACATTTCAAAGAATTCATGGGCGCGCAAAGAGACTGGCAGTCTAACGTCAAGTACGGGAAGCCCACTAAAATTAAAGGTGGTATCCCCACCATCTTTCTGTGTAACCCTGGTCCCAAGTCCTCCTATAAAGAGTACTTGGATGAAGAGAACAATGCTGCGCTTAAACAGTGGGCTTCAAAGAATGCGGAATTCTACACCCTCAAAGAACCACTGTTCTCCACCGTCAATCAAGGTTCAACACAGGGTCGCCAAGAAGAGAGCAATTCGACGATCTCGAATTGA |
|
Protein Sequence
|
MPREGRFAINAKNYFLTYPKCPLTKEDALEQLLALSTPVNKKFIRICRELHEDGQPHLHVLLQFEGKQQTKNQRFFDLHSRCRSAYYHPNIQRAKSCSDVKTYMEKDGDILDHGTFQIDGRSARGGKQSANDAYAEALNSGSKLEALLILKEKAPKDFILQFHNLNCNLSRIFTEPTQAYESPFTLESFDKVPSYISSWAERNVRDAARPDRPISIVIEGDSRTGKTMWARAIGPHNYLCGHLDLNDKTYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNVKYGKPTKIKGGIPTIFLCNPGPKSSYKEYLDEENNAALKQWASKNAEFYTLKEPLFSTVNQGSTQGRQEESNSTISN |
|
NCBI Accession
|
NP_803151.1
|
|
Location
|
2277-2576 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAGATGGACAACCTCATCTCCATGTTCTGCTTCAGTTCGAAGGGAAACAACAAACGAAAAACCAAAGGTTCTTCGACCTCCATTCCAGATGCAGATCGGCATATTACCATCCGAACATTCAGCGAGCTAAAAGCTGCTCAGATGTTAAAACATACATGGAGAAAGACGGAGACATTCTTGATCATGGAACCTTCCAAATCGATGGCAGATCAGCTAGAGGAGGTAAACAATCTGCCAACGACGCATACGCCGAGGCACTCAACTCTGGATCAAAGTTGGAGGCCCTCCTTATATTGA |
|
Protein Sequence
|
MKMDNLISMFCFSSKGNNKRKTKGSSTSIPDADRHITIRTFSELKAAQMLKHTWRKTETFLIMEPSKSMADQLEEVNNLPTTHTPRHSTLDQSWRPSLY |
|
NCBI Accession
|
NP_803152.1
|
|
Location
|
504-1268 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTTTACTCGTAATTATCGCACCCCTTTTAAATTACGCCATGATAATTTTGGTTATAGATGGCAGCCTATGACACCGTCAAGAGGACGTTTACGTCTTCATAAGCCTAGTGCTTCACGTAAATTATCATATGACCGAGTTGAACGGGAAATGCGCACCAATTCTATCGTTGAGGTTCAACATGGAAGCCATATGTCCCTTGAGAAGAATACGGATGTATTTTCATTTGTGCAATACCCTGTTCGTGGAATAAACGGTGACGGACGTTGTAGGGATTACATCAAGTTACTTAAACTTGATGTCTCTGGTGTGATAAACATCAAGTCTTCGAATGGAGACCAAAGCATGGAACCAGGTGACAAGTTAAGTGGGCTATTTATTCTGACTGTCTTGCTTGATAAGAAACCCTATCTTCCAGAAGGTGTGAACAAGTTACCCTCCTTTGCGGAGTTATTTGGACCTTATTCTGCTGCATATGCGAATATACACCTCTTAGATTCCCAGAAGCCCCGCTTCAAGGTCCTTGGGACAATAAAGAAGTTCGTGAACTGCACATCAGGGACAATATATGGTCCTTTGAAATTAAATATGCCGTTGTCCCGGCGAAAGTGTCCTTTGTGGACTACGTTCAAGGACCCTGATCAGGGTAACTGTGGTGGAAATTATAAGAATTTTCCTGCTATTGTATTGAGCTATGCATTTATATCCATGCATAGCCTAGTTGTGGAACCATATTTTCAATTTGAATTGAAATACGTTGGATAA |
|
Protein Sequence
|
MFTRNYRTPFKLRHDNFGYRWQPMTPSRGRLRLHKPSASRKLSYDRVEREMRTNSIVEVQHGSHMSLEKNTDVFSFVQYPVRGINGDGRCRDYIKLLKLDVSGVINIKSSNGDQSMEPGDKLSGLFILTVLLDKKPYLPEGVNKLPSFAELFGPYSAAYANIHLLDSQKPRFKVLGTIKKFVNCTSGTIYGPLKLNMPLSRRKCPLWTTFKDPDQGNCGGNYKNFPAIVLSYAFISMHSLVVEPYFQFELKYVG |
|
NCBI Accession
|
NP_803153.1
|
|
Location
|
1300-2268 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGATTATAATTGTAAACTCTTCTCATTGCCGCTGCGCGCTAATTGAAATTATTAGAATAATTTCCGGGTGTGTGGTCATTTTCAGGGGGCAGTTGATTAATAACAAATATGTGGAGACAAAGAGTTGCGAATACAGACTATCCAACAACGAGATGCCCATCAAATTACAATTTCCTTCTTATCTGGAACAGAAGACTGTCCAGATAATGGGTAGATGCATGAAGGTCGACCATGCTGTGATCGAGTACAGAAACCAAGTTCCGTTCAACGCCAAGGGAACGGTCATCGTCACAATTCGTGACACAAGGCTAAGCTATGAACAAGCAGCACAAGCTGCTTTCACCTTCCCAATTGCATGTAACGTCGATCTCCATTATTTCTCATCATCCTTCTTCTCTCTAAAGGATGAAACACCATGGGAGATAGTGTACAAGGTCGAAGACTCAAACGTGATCGACGGAACAACATTTGCCCAGATAAGGGCCAAACTGAAATTGTCTTCCGCAAAGCACTCAACAGACATAAGGTTTAAACCCCCGACAATAAACATATTGTCTAAAGACTACACTGCAGACTGTGTGGACTTTTGGTCTGTTGAGAAGCCCAAGCCCATTAGGCGTTTGCTTAATCCAGGACCCAATCAGGGTCCATATCCAAATACTGGCCATAGGCCCATTATGCTACAGCCAGGTGAGACTTGGGCTACAAGGTCATCTATTGGACGGAGTAGCTCCATGCGTTACACAAATAACGAGAGGCCCAGTATTCTAGACAACACGAGCGCTTCAGACGCAGATTACCCACTTAGACATTTGCACAAATTGCCAGAGGCATCATTGGATCCTGGAGATTCAATATCTCAGACCCAGTCTAACGCAATGAGCAAGAGAGAAATAGAGGACATTATAGAGACGACTATTAGCAAATGTCTCATAAGTCAACGTTCTAATGTGAACAAAGTGTTGTAA |
|
Protein Sequence
|
MIIIVNSSHCRCALIEIIRIISGCVVIFRGQLINNKYVETKSCEYRLSNNEMPIKLQFPSYLEQKTVQIMGRCMKVDHAVIEYRNQVPFNAKGTVIVTIRDTRLSYEQAAQAAFTFPIACNVDLHYFSSSFFSLKDETPWEIVYKVEDSNVIDGTTFAQIRAKLKLSSAKHSTDIRFKPPTINILSKDYTADCVDFWSVEKPKPIRRLLNPGPNQGPYPNTGHRPIMLQPGETWATRSSIGRSSSMRYTNNERPSILDNTSASDADYPLRHLHKLPEASLDPGDSISQTQSNAMSKREIEDIIETTISKCLISQRSNVNKVL |