Allamanda leaf mottle distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000919815.2 |
| Isolate |
India: Kalyani, West Bengal |
| Release date |
2018/12/27 |
| Submitter |
Shilpi,S., Tarafdar,J., Mandal,B., Jailani,A.A.K., Roy,A. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
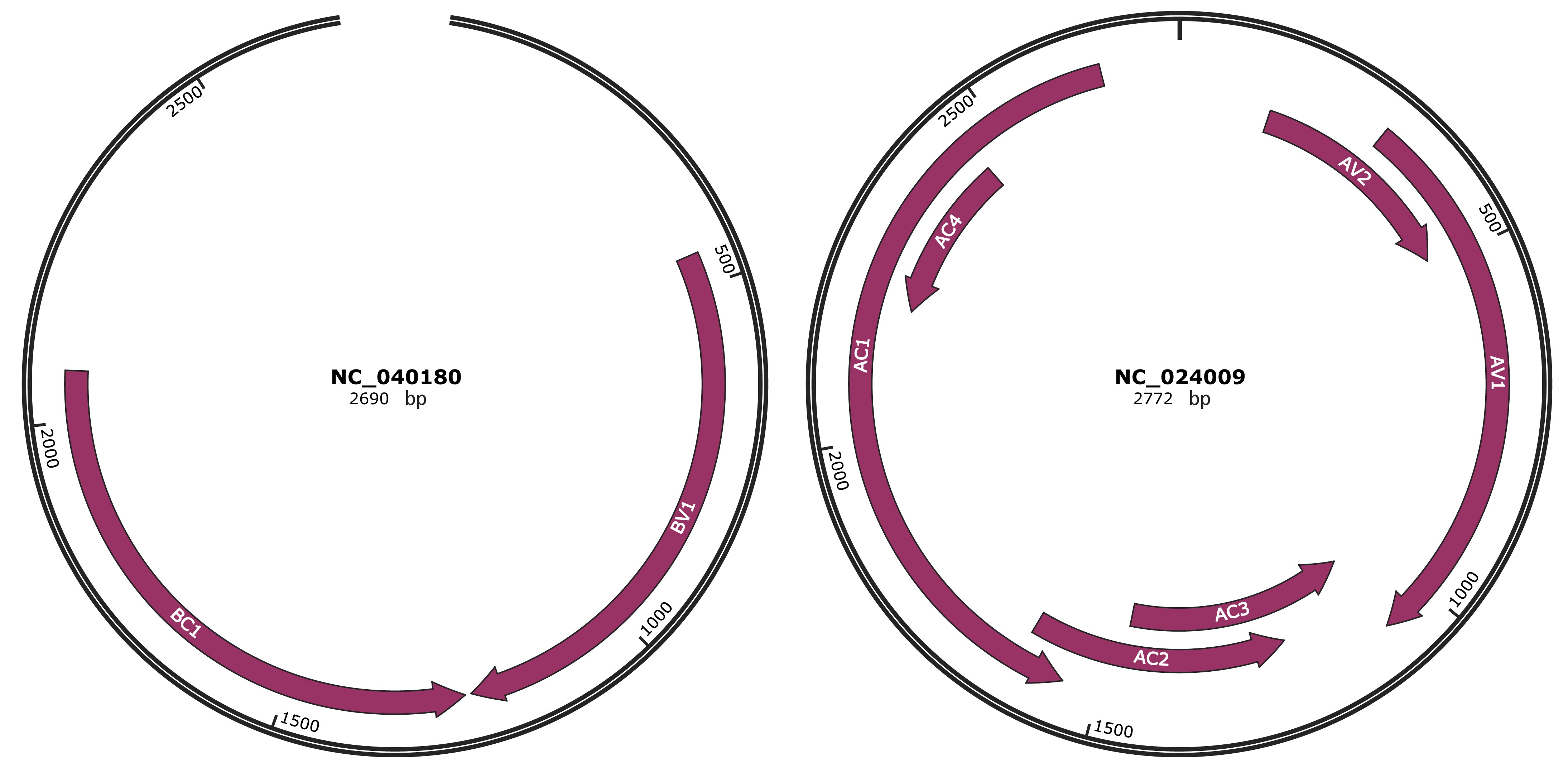
JBrowse
Genome
ACCGGATGGCCGCGCCCCGCTTTGTGGTGGACCCCCCCACGTGGAGATGTCCCCCACTCAGAAAGCTCCGTCAAAGTTTGTGGTGGACCCCACCACGTGGAGATGTCCCCCACTCAGAACGCTCCGTCAAAGCTTGTGGTGGCCCCCCCCCACCTGGAGATGTCCGCCTCGCATAAGGCGCCCTTGGAGCTTCAATAAATCAGTGGTCCCACTATGTTGGTTATAACGTGTGTAACGTTTGAGGCCGGATGCTAGTGCTGCCACGTGTGCGTTATGTCTACTTCTTTTGGAAGTTATAAGTCAGGGCCCTACATGTGGATATCTAACCGCATATTGTGTGAATTGTATAAACGTGGCAAAATCATGCCGGTTAGTGGGAACCATTGAATAAGGTTATTGTGTATATATATATGGGTATGTGGTATGTGGAATCCCTACACAAGTTGTTGGCAGAATGAGAATTGTTGGTTATACTCCCCGTTCCACGCCATTTGCTCGTGACCGGAGATCATATAATTCCGGTAAGCGTAGATCCTATCGTGGTTACCGTCGTCGTGTACCTGTTCGTCCACTAGCTCGTCGTGCCTTGTTCTGTGATGATAATGCACGGGCATTCACGTATAAGACCCTATCGGAGGATCAGTTTGGACCGGACTTTACTATACGTAACAATAATTATAAGTCATCGTACATATCTATGCCTGTTAAAACAGGTGCCCAGAGTAATAACCGTGTAGGTGATTATATCAAGCTTGTAAATATATCCTTTACAGGTACAGTGTGTATTAAAAATAGTCAGATGGAGTCTGAAGGAAGCCCAATGCTTGGCCTACATGGGCTCTTTACGTGTGTGTTGGTTCGCGATAAGACCCCTCGTGTATATTCAGCCAATGAGCCTCTGATACCGTTCCCACAGTTGTTTGGGTCCATAAACGCTAGCTGTGCGGATTTGTCCATACAGGACCCATATAAGAATCGTTTTGCTGTAATTCGCCAAGTGTCCTATCCCGTTAATACGGAGAAGGGTTACCATATGTGCCGTTTCAGAGGCAATCGCCGTTTTAATGGGAAATACCCTATCTGGGTCAGTTTTAAAGATGATGGTGGTAGTGGAGACTCGTCTGGGTTATATACTAATACATATAAAAATGCCATACTTGTATATTATGTATGGCTGAGCGACATGTCGTCCCAAGTGGACATGTATTGTAAATATGTAATGCGATATATTGGTTAATAAAAATGTTATACATTTTTTGATACATGGCTTTGCATACCTGTATTTAAACACATATCTACTGTCTGCCTAATAATATTGTTCAAGTCCTCTCTTGTTATGTGGTCCGATCCAACTTGTGATACGGATTTTCCTGGGTCCAATGCGTCTGGGTTGAGGCGGTGTAGGTGTCTGTAAGGCCTGTCTTCGGACGGCCCAACTTCACTCTTTACGGCCCATGATTCGTTTGGGCCTATAGAACATGGAGTGTACCTCATGGATCTCGATCCTATTAGACTTGGGCCCTGTACCAGTTTTCTTTGCTGGGCTATTCTTCCCACTGACCAGAAATCTATGTCCCTTTCTGTGAAGGCCTTGCTCAGAATCTCTATTTTGGGAGACCGGAACTGTATGTCAGTTGACTGCTTTGCAGTCGATAGCTTTAGTTTCCCTTGAATACGGCAGAAGTGGACTCCGTTGACTACGTTTGTGTCTACGACCCTGTAGAACACTCTCCATGGGTTTATGTCCTTCATGGAGAAGAACGAGGAAGAATAGTAGTGTAGGTTGCAGTTGCATTGAACGGGAATAGTGAACTCCGCCTGCTTGGAGTCCCCATCGTTCAACCGTTGGTCGTGAATCTCAATGATCACATGCCCTGTGGCGTTAATCGGTACTTGGTTTCGATATTCAAGAACGATGTGGTCAATTTTGCAGCAATGACCCTTGAGGAGTGATATTTTGTTATCCAAAATGGATTGGGAGCTCAACTTGACATCAGTGGAGTCATTGGTTAACTCATATTCGACCCTCTCGGAACGAAGATATGCTGAATTACTACTATTAGTTTCCATTGGCCCCGCAGGGGATATGCTTAGAAATTAACCCCAGTGTATAAGGAATAAATTAGTGTGCGTAGAGCAAGCCCCAGAGCTGAATAAATAATTGAAGGCATATATATTATATTATTGATGAAAGGTTACAACAGCATCCACGTGTCAGTGGATTACAAGATATATAAAAAGCGATATAAAATATCTAAATGGATTCATAGTGACGTCATCTTCAATAAACGGAATTGGAAACCCTAATGCATCTTGGATGCAGTTGGTCAAGTCGTCTAGTAGGACGTCATATGTTTCTGGCGTCATATGATGATAATCCTGAACTGGTCCTTATCCTTGAACTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGTTTTTCTTGTGCCACTCAGATAAATAATTTATCTGAGGGACAGTGTAAGGATTTGATGAGTTCGAGCATTTGCTCTTTTGGGATTGGGCATTTTGGATATGTAAGGAATATGTTGTTGGCTTTAACTTGGAAGGAATTAACACGTTGCATATTGAATTGGGTGCTCTCGAAACTCTGTGGGAATTGGGGGCTTTGGGTGCCCATTTATATGGAGCACCCAAATGGCAAAGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGCTTTTTTGTCCCCTTGTGGGCCCCACCAAGTGGACCATGTACACGTGGTCCAATGAAAACCACTCCTGCAAGCTTAGCTGTGGGTGGGCCCCATATATAATTGCTTGCTGAGTAAGTTTGTTGTAAACATGTGGGACCCACTAGTAAACGAGTTTCCAGAAACTGTTCATGGGTTTAGGTGCATGTTGGCAGTGAAATATCTGCATCTAGTTGCAGATACGTATTCTCCAGATACGGTGGGATACGACCTAATACGTGATTTAATTTGTATTTTACGTTCCAGGAATTATGTCGAAGCGCAAACCAGATATAATCATTTCCACCCCAGGCTCGAAGGTTCGACGGAGGCTGAACTTCGACAGTCCAGGATCGAGCCGTGCCTATGTCCCTACTGTCCGCGTCACCAAATCAAGTCTATGGGCCAACAGGCCCATGAACAGAAAGCCCAGACTGTACAGGATGTACAGAAGCCCTGATGTGCCTAGGGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGTCCAGGCATGATGTCGTCCATATTGGTAAGGTAATGTGTATTAGTGATGTTACTCGTGGAACTGGGCTGACCCATAGGGTTGGCAAGAGGTTCTGTGTGAAGTCTGTCTATGTCTTGGGTAAGATATGGATGGATGAGAACATCAAGACCAAGAATCACACGAACAGTGTGATGTTCTTCCTTGTACGTGATAGGCGTCCTGTTGATAAACCCCAAGACTTTGGGGATGTGTTCAATATGTTCGACAATGAGCCCAGTACGGCGACCGTGAAGAATGTATACAGGGATCGATACCAGGTTCTGAGGAAGTGGCATGTCACTGTGACAGGGGGTCTATATGCATCGAAGGAACAGGCATTGGTTAAGAAGTTCGTTAGGGTTAACAACCATGTGGTGTACAACCAACAGGAGGCAGGGAAATATGAAAACCATAGTGAGAATGCATTGATGTTGTATATGGCTTGTACTCATGCGAGTAACCCTGTATATACCACACTGAAGATACGGATCTATTTTTATGATTCAGTATCGAATTAATAAATTTTAAATTTTATATCATGATCCTCAATTACATCAATTGTGTCATGGAGTACATCATATAATACATGTTTAAATGCCCTAATACAATTATTTATACTAATCACTCCTAATCTATCTAAAAACTTTAAAACGTGAGTCCTAAATACTCGTAAGAAATGCCCAGTCTGAGGTTGTAAACGAGTGCAGATCGTCAAGCCCAAGAAACACTTCATTATCCCCAGTTCCTTCCTGAGGTTGTGATTGAACTGGATTCTGATGTGGATGATGTCGTGGTTCATGTTGAATGGCCTCTGGTCGTGGTTGAGGATCTTGAAATAGAGGGGATTTGTTACCTCCCAGATATACACGCCATTCATTGCCTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTGATGTGTACGTAGTATGAGCACCCACAGTTTAGATCAACCCTCTTACGCCGGATGGCTCTACGCTTAGCAGCTCTGTGTTGGACCTTGATTGGCACCTGAGTACAGTGGCTCTGTGAGGGTGATGAATTCTGCATTCTTTATAGCCCAAGACCTTAGTGCTGAGTTCTTTTCCTCGTCTAAGAACTCTTTATAGCTGGAGTTGGGCCCAGGATTGCATAGGAAGATAGTGGGAATGCCCCCTTTAATTTGAACTGGCTTCCCGTACTTGGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGGTAGTGGGGGTCTACGTCATCAATGACGTTGTACCAGGAGGCATTTGAATAGATTTTAGGGCTCAGATCTAAATGGCCACATAAGTAATTATGTGGTCCCAAAGACCTGGCCCACATAGTCTGGCCCGTACGACTATCACCCTCGATGACGATACTTTTAGGTCTCAATGGCCGCGCAGCGGGACCCATCACATTTGCAGAGGCCCATTCCTCTATGGGCTCTGGAACTTGATCAAAGGAAGAAGAAAGAAAAGGGGAAACATAAACCTCCATTGGAGGTGCAAAAATCCTATCTAAATTATTTTTTAAATTATGATATTGAAAAATAAAATCTTTAGGGAGTTTCTCCCTAATTATTGCCAGAGCAGCATCAGCGGACCCTGAATTCAGAGCTTCTGCAGCAGCATCATTAACTCTCTGTTGACCTCCTCTAGCAGATCTTCCATCGACCTGAAACTCACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCGGATGAGGACTTAGCTCCCTGGAAATTTGGGTGGAAATGGGAGGAGTTATGAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAACTGGGCCTTACCCTTGAACTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGTTTTTCTTGTGCCACTCGGATAAATAATTTATCTGAGGGACAGTGTATGGATTTGATGAGTTCGAGCATTTGCTCTTTTGGAATTGGGCATTTTGGATATGTAAGGAATATGTTTTTGGCTTTAACTTGGAAGGAATTAACACGCGGCATATTGAATTGGGTGCTCTCGAAACTCTGTGGGAATTGGGGGCTTTGGGTGCCCATTTATATGGAGCACCCAAATGGCAAATTGGTAATTTTAGAACTTTAATTTGAAATTAGAAATTCAAAATTCAAATTTCAAATCCCCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547922.1
|
|
Location
|
455-1237 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGAGAATTGTTGGTTATACTCCCCGTTCCACGCCATTTGCTCGTGACCGGAGATCATATAATTCCGGTAAGCGTAGATCCTATCGTGGTTACCGTCGTCGTGTACCTGTTCGTCCACTAGCTCGTCGTGCCTTGTTCTGTGATGATAATGCACGGGCATTCACGTATAAGACCCTATCGGAGGATCAGTTTGGACCGGACTTTACTATACGTAACAATAATTATAAGTCATCGTACATATCTATGCCTGTTAAAACAGGTGCCCAGAGTAATAACCGTGTAGGTGATTATATCAAGCTTGTAAATATATCCTTTACAGGTACAGTGTGTATTAAAAATAGTCAGATGGAGTCTGAAGGAAGCCCAATGCTTGGCCTACATGGGCTCTTTACGTGTGTGTTGGTTCGCGATAAGACCCCTCGTGTATATTCAGCCAATGAGCCTCTGATACCGTTCCCACAGTTGTTTGGGTCCATAAACGCTAGCTGTGCGGATTTGTCCATACAGGACCCATATAAGAATCGTTTTGCTGTAATTCGCCAAGTGTCCTATCCCGTTAATACGGAGAAGGGTTACCATATGTGCCGTTTCAGAGGCAATCGCCGTTTTAATGGGAAATACCCTATCTGGGTCAGTTTTAAAGATGATGGTGGTAGTGGAGACTCGTCTGGGTTATATACTAATACATATAAAAATGCCATACTTGTATATTATGTATGGCTGAGCGACATGTCGTCCCAAGTGGACATGTATTGTAAATATGTAATGCGATATATTGGTTAA |
|
Protein Sequence
|
MRIVGYTPRSTPFARDRRSYNSGKRRSYRGYRRRVPVRPLARRALFCDDNARAFTYKTLSEDQFGPDFTIRNNNYKSSYISMPVKTGAQSNNRVGDYIKLVNISFTGTVCIKNSQMESEGSPMLGLHGLFTCVLVRDKTPRVYSANEPLIPFPQLFGSINASCADLSIQDPYKNRFAVIRQVSYPVNTEKGYHMCRFRGNRRFNGKYPIWVSFKDDGGSGDSSGLYTNTYKNAILVYYVWLSDMSSQVDMYCKYVMRYIG |
|
NCBI Accession
|
YP_009547923.1
|
|
Location
|
1246-2070 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAAACTAATAGTAGTAATTCAGCATATCTTCGTTCCGAGAGGGTCGAATATGAGTTAACCAATGACTCCACTGATGTCAAGTTGAGCTCCCAATCCATTTTGGATAACAAAATATCACTCCTCAAGGGTCATTGCTGCAAAATTGACCACATCGTTCTTGAATATCGAAACCAAGTACCGATTAACGCCACAGGGCATGTGATCATTGAGATTCACGACCAACGGTTGAACGATGGGGACTCCAAGCAGGCGGAGTTCACTATTCCCGTTCAATGCAACTGCAACCTACACTACTATTCTTCCTCGTTCTTCTCCATGAAGGACATAAACCCATGGAGAGTGTTCTACAGGGTCGTAGACACAAACGTAGTCAACGGAGTCCACTTCTGCCGTATTCAAGGGAAACTAAAGCTATCGACTGCAAAGCAGTCAACTGACATACAGTTCCGGTCTCCCAAAATAGAGATTCTGAGCAAGGCCTTCACAGAAAGGGACATAGATTTCTGGTCAGTGGGAAGAATAGCCCAGCAAAGAAAACTGGTACAGGGCCCAAGTCTAATAGGATCGAGATCCATGAGGTACACTCCATGTTCTATAGGCCCAAACGAATCATGGGCCGTAAAGAGTGAAGTTGGGCCGTCCGAAGACAGGCCTTACAGACACCTACACCGCCTCAACCCAGACGCATTGGACCCAGGAAAATCCGTATCACAAGTTGGATCGGACCACATAACAAGAGAGGACTTGAACAATATTATTAGGCAGACAGTAGATATGTGTTTAAATACAGGTATGCAAAGCCATGTATCAAAAAATGTATAA |
|
Protein Sequence
|
METNSSNSAYLRSERVEYELTNDSTDVKLSSQSILDNKISLLKGHCCKIDHIVLEYRNQVPINATGHVIIEIHDQRLNDGDSKQAEFTIPVQCNCNLHYYSSSFFSMKDINPWRVFYRVVDTNVVNGVHFCRIQGKLKLSTAKQSTDIQFRSPKIEILSKAFTERDIDFWSVGRIAQQRKLVQGPSLIGSRSMRYTPCSIGPNESWAVKSEVGPSEDRPYRHLHRLNPDALDPGKSVSQVGSDHITREDLNNIIRQTVDMCLNTGMQSHVSKNV |
|
NCBI Accession
|
YP_009026392.1
|
|
Location
|
143-490 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGACCCACTAGTAAACGAGTTTCCAGAAACTGTTCATGGGTTTAGGTGCATGTTGGCAGTGAAATATCTGCATCTAGTTGCAGATACGTATTCTCCAGATACGGTGGGATACGACCTAATACGTGATTTAATTTGTATTTTACGTTCCAGGAATTATGTCGAAGCGCAAACCAGATATAATCATTTCCACCCCAGGCTCGAAGGTTCGACGGAGGCTGAACTTCGACAGTCCAGGATCGAGCCGTGCCTATGTCCCTACTGTCCGCGTCACCAAATCAAGTCTATGGGCCAACAGGCCCATGAACAGAAAGCCCAGACTGTACAGGATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLHLVADTYSPDTVGYDLIRDLICILRSRNYVEAQTRYNHFHPRLEGSTEAELRQSRIEPCLCPYCPRHQIKSMGQQAHEQKAQTVQDVQKP |
|
NCBI Accession
|
YP_009026393.1
|
|
Location
|
303-1073 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGCAAACCAGATATAATCATTTCCACCCCAGGCTCGAAGGTTCGACGGAGGCTGAACTTCGACAGTCCAGGATCGAGCCGTGCCTATGTCCCTACTGTCCGCGTCACCAAATCAAGTCTATGGGCCAACAGGCCCATGAACAGAAAGCCCAGACTGTACAGGATGTACAGAAGCCCTGATGTGCCTAGGGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGTCCAGGCATGATGTCGTCCATATTGGTAAGGTAATGTGTATTAGTGATGTTACTCGTGGAACTGGGCTGACCCATAGGGTTGGCAAGAGGTTCTGTGTGAAGTCTGTCTATGTCTTGGGTAAGATATGGATGGATGAGAACATCAAGACCAAGAATCACACGAACAGTGTGATGTTCTTCCTTGTACGTGATAGGCGTCCTGTTGATAAACCCCAAGACTTTGGGGATGTGTTCAATATGTTCGACAATGAGCCCAGTACGGCGACCGTGAAGAATGTATACAGGGATCGATACCAGGTTCTGAGGAAGTGGCATGTCACTGTGACAGGGGGTCTATATGCATCGAAGGAACAGGCATTGGTTAAGAAGTTCGTTAGGGTTAACAACCATGTGGTGTACAACCAACAGGAGGCAGGGAAATATGAAAACCATAGTGAGAATGCATTGATGTTGTATATGGCTTGTACTCATGCGAGTAACCCTGTATATACCACACTGAAGATACGGATCTATTTTTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRKPDIIISTPGSKVRRRLNFDSPGSSRAYVPTVRVTKSSLWANRPMNRKPRLYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGDVFNMFDNEPSTATVKNVYRDRYQVLRKWHVTVTGGLYASKEQALVKKFVRVNNHVVYNQQEAGKYENHSENALMLYMACTHASNPVYTTLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009026394.1
|
|
Location
|
1070-1474 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAATGAATGGCGTGTATATCTGGGAGGTAACAAATCCCCTCTATTTCAAGATCCTCAACCACGACCAGAGGCCATTCAACATGAACCACGACATCATCCACATCAGAATCCAGTTCAATCACAACCTCAGGAAGGAACTGGGGATAATGAAGTGTTTCTTGGGCTTGACGATCTGCACTCGTTTACAACCTCAGACTGGGCATTTCTTACGAGTATTTAGGACTCACGTTTTAAAGTTTTTAGATAGATTAGGAGTGATTAGTATAAATAATTGTATTAGGGCATTTAAACATGTATTATATGATGTACTCCATGACACAATTGATGTAATTGAGGATCATGATATAAAATTTAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAMNGVYIWEVTNPLYFKILNHDQRPFNMNHDIIHIRIQFNHNLRKELGIMKCFLGLTICTRLQPQTGHFLRVFRTHVLKFLDRLGVISINNCIRAFKHVLYDVLHDTIDVIEDHDIKFKIY |
|
NCBI Accession
|
YP_009026395.1
|
|
Location
|
1215-1622 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAGAATTCATCACCCTCACAGAGCCACTGTACTCAGGTGCCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGATCTAAACTGTGGGTGCTCATACTACGTACACATCAACTGCCACAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAATGAATGGCGTGTATATCTGGGAGGTAACAAATCCCCTCTATTTCAAGATCCTCAACCACGACCAGAGGCCATTCAACATGAACCACGACATCATCCACATCAGAATCCAGTTCAATCACAACCTCAGGAAGGAACTGGGGATAATGAAGTGTTTCTTGGGCTTGACGATCTGCACTCGTTTACAACCTCAGACTGGGCATTTCTTACGAGTATTTAG |
|
Protein Sequence
|
MQNSSPSQSHCTQVPIKVQHRAAKRRAIRRKRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGNEWRVYLGGNKSPLFQDPQPRPEAIQHEPRHHPHQNPVQSQPQEGTGDNEVFLGLDDLHSFTTSDWAFLTSI |
|
NCBI Accession
|
YP_009026396.1
|
|
Location
|
1552-2664 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGGCACCCAAAGCCCCCAATTCCCACAGAGTTTCGAGAGCACCCAATTCAATATGCCGCGTGTTAATTCCTTCCAAGTTAAAGCCAAAAACATATTCCTTACATATCCAAAATGCCCAATTCCAAAAGAGCAAATGCTCGAACTCATCAAATCCATACACTGTCCCTCAGATAAATTATTTATCCGAGTGGCACAAGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAGGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTCATAACTCCTCCCATTTCCACCCAAATTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGAGTTTCAGGTCGATGGAAGATCTGCTAGAGGAGGTCAACAGAGAGTTAATGATGCTGCTGCAGAAGCTCTGAATTCAGGGTCCGCTGATGCTGCTCTGGCAATAATTAGGGAGAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAAAATAATTTAGATAGGATTTTTGCACCTCCAATGGAGGTTTATGTTTCCCCTTTTCTTTCTTCTTCCTTTGATCAAGTTCCAGAGCCCATAGAGGAATGGGCCTCTGCAAATGTGATGGGTCCCGCTGCGCGGCCATTGAGACCTAAAAGTATCGTCATCGAGGGTGATAGTCGTACGGGCCAGACTATGTGGGCCAGGTCTTTGGGACCACATAATTACTTATGTGGCCATTTAGATCTGAGCCCTAAAATCTATTCAAATGCCTCCTGGTACAACGTCATTGATGACGTAGACCCCCACTACCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAGTACGGGAAGCCAGTTCAAATTAAAGGGGGCATTCCCACTATCTTCCTATGCAATCCTGGGCCCAACTCCAGCTATAAAGAGTTCTTAGACGAGGAAAAGAACTCAGCACTAAGGTCTTGGGCTATAAAGAATGCAGAATTCATCACCCTCACAGAGCCACTGTACTCAGGTGCCAATCAAGGTCCAACACAGAGCTGCTAA |
|
Protein Sequence
|
MGTQSPQFPQSFESTQFNMPRVNSFQVKAKNIFLTYPKCPIPKEQMLELIKSIHCPSDKLFIRVAQEKHQDGSLHIHALIQFKGKAQFRNPRHFDVTHPHNSSHFHPNFQGAKSSSDVKSYIEKDGDYIDWGEFQVDGRSARGGQQRVNDAAAEALNSGSADAALAIIREKLPKDFIFQYHNLKNNLDRIFAPPMEVYVSPFLSSSFDQVPEPIEEWASANVMGPAARPLRPKSIVIEGDSRTGQTMWARSLGPHNYLCGHLDLSPKIYSNASWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALRSWAIKNAEFITLTEPLYSGANQGPTQSC |
|
NCBI Accession
|
YP_009026397.1
|
|
Location
|
2196-2453 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAGGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTCATAACTCCTCCCATTTCCACCCAAATTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGAGTTTCAGGTCGATGGAAGATCTGCTAGAGGAGGTCAACAGAGAGTTAATGATGCTGCTGCAGAAGCTCTGA |
|
Protein Sequence
|
MGLCISMPSSSSRVRPSSETPDISMSLTLITPPISTQISRELSPHPMSSPTSRRTVITSTGVSFRSMEDLLEEVNRELMMLLQKL |