Melochia mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001430075.1 |
| Isolate |
Brazil |
| Release date |
2015/11/3 |
| Submitter |
Fiallo-Olive,E., Zerbini,F.M., Navas-Castillo,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
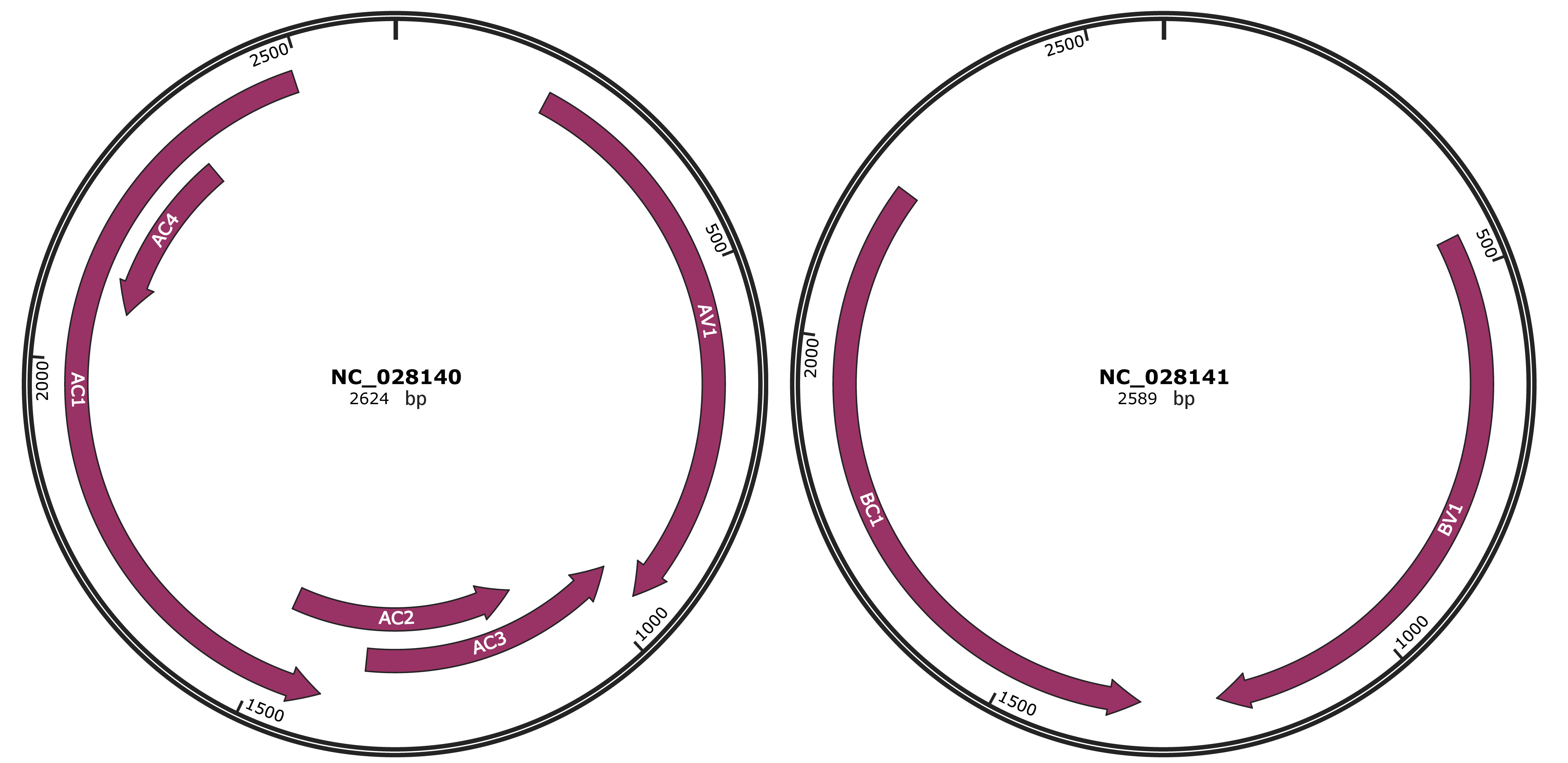
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCGACCCGCTCCCGCATATCGCGCCGCTTTGTCTGCCACTAGCATTATGGGCCCACTGTAATAATGACCGTCCAATGAGAAGTGGTCCTGAAAGCTTATTTGTTTTGAACTACTTCCCGCCCAAGTAGTTAAACAGCTATATAGTGGGCCATTAATTATGTCGACTCATCAATTCAGAATGCCTAAGCGGGAAGCCCCTTGGCGCGCGATGGCGGGATCCTCTAAGGTTAGTCGCAATCTCAATTATTCCCCTCGTGGAGGTATGAGGCCCAAATTTGACAAGGCCTCTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACTATGAGAGGACCCGATGTCCCTAAAGGCTGTGAAGGCCCTTGTAAGGTCCAGTCCTACGAACAGCGTCATGATGTCTCGCACGTGGGTAAGGTTATTTGTGTATCTGATGTCACACGTGGTAACGGTATTACTCACCGTGTAGGTAAGCGATTCTGTGTCAAGTCTGTCTACATCCTAGGTAAGATCTGGATGGACGAGAACATCAAATTGAAGAACCACACCAACAGCGTCATGTTTTGGTTGGTGAGAGACAGGAGACCCTATGGCACGCCCATGGATTTTGGCCAGGTGTTTAACATGTTTGACAATGAGCCCAGCACTGCGACAGTTAAGAACGATCTCCGCGATCGTTTTCAAGTCATGCACAAGTTCTATGCCAAGGTGACAGGTGGACAGTATGCGAGCAACGAACAGGCCCTTGTGAGGCGTTTCTGGAAGGTCAACAACCACGTGACTTATAACCATCAGGAGAGAGGGATATATGAGAACCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCCGTGTATGCTACGCTTAAGATTCGGATCTATTTTTACGATTCGATATCAAATTAATAAAGTTTGAATTTTATTGAATGATCTTCGAGTACATGATTTACATAACACCGGTCCGTCGCAAAACGAACGGCTCTGATTACATTATTAATTGAGATAACGCCTAATTGATCTAAGTACAACATGACTAAGTGCCTAAATCTAGCTAAATATGTCGTCCCAGAAGCTGTCAGGGATGTCGTCCAGACTTGGAAGTTGAAGTACGCCTTGTGGAGATCCAACGCTCTCCTCAGGTTGTGGTTGAACCGGACTTGGACGTGGTAGACCCTGGTGTTGGTGTTCAGGGGGTCTTCCACGTTGGTTATCTTGAAATACAGGGGATTTTGCAGCTCCCAGATAAACACGCCATTCTCCGCTTGAGGCGCAGTGATGAGTTCCCCTGTGCGTGAATCCATTGTTGGCGCAGTTGAGGTGGAGGAAGAAAGAGCACCCGCACTCCAAGTCGATGCGTCTACGGCGAGTTGCTCTGCGCTTGGCCGCCCTGTGTTGAGGCTTGATAGAGGGGGGAGTCGAGGAAGACGAATGTCGCATTGTGAAGGGTCCAGGCTTTGAGAGATGCGTTTTCCTCTTTGTCGAGGAAATCTTTATAACTGGCCCCCTCGCCTGGATTGCAGAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTTCCATATTTACAGTTGCTTTGCCAGTCCCGTTGGGCCCCAATGAGCTCTTTCCAATGTTTCATCTTTTTATGGGGCGGGCTGACGTCATCGATGACGTTGTATTGGGCCTCGTTTGAGTAGACTCTTGGGTTGAAGTCCAGATGCCCGCTTAGATAATTATGTGGGCCCAATGCACGAGCCCACATCGTCTTCCCCGTCCGACTATCACCTTCAACTATGATACTAATAGGTCTGTCAGGCCGCGCAGCGGGATCAACACCGAAATAACTGTCCGCCCACTCTTGCATCTCGTCTGGCACGTTAGTGAAGGAGGAGAGTGGAAACGGAGGAGCCCATGGTGACGGAGCCTTTGCAAATATCCTGTCTAAGTTAGCCGACAGGTTGTGATATTGAAAGAGAAACTTTTCCGGCAGCTTCTCTTTGATTATTTGCATCGCCTGATCTTTTGAGGAGGCGTTTAGTGCCTCGGCGGCAGCGTCATTAGCCGTCTGTTGACCTCCTCTAGCACTTCTACCGTCGACCTGGAATTCACCCCATTCGAGGGTGTCACCGTCCTTGTCGATATAGGACTTGACGTCTGACGATGATTTAGCTCCCTGAATGTTAGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAATAATCTGTTATTCGTGCAGACGAACTTTCCCTCGAACTGAATAAGCACGTGGAGATGTGGCTCCCCATTTTCGTGAAGTTCTCTGCAGATTTTGATGAACTTCTTGTTCGTTGGGATAGTTAGGGTTTGTATTTGGGAAAGTGCCTCTTCTTTGGATAAAGAGCACTGTGGATAAGTAAGGAAATAGTTTTTAGAAGAGATACGGAAGCGTTTTGGAGCTGATGGCATTTTTGTAATAAGAGCGATGTCACCAATTGAGCTCTCTCTCAAAACTCTAAAGCAATTGGTGACATTGGTGACAATTTATATGTAGGAGTTCCATAACCTCCAGGGACACGTGGCGGCCATCCGATATAATATT
ACCGGATGGCCGCCCGATTTTTCCCCCCCCCCCACGTGGCGCGCTCGTGGCCGCTGGATCTCCCTCCCCCTGGCGTGCTCTCTCTCTCTGTCATGCATCTCAATTCAGTTAAGCGCTTATTTGGAGTCCGCGAAATGAGTTCACCGCTTTGTTTGAGATCCGTGTACTGAGTCAAGGCGCTTTAATTCAAATTAAAGTTGGGCATTTTATACTGACCAATCAAATTTCGTGTGGGGAGTCTAGTTAATATAAACATGTTAAATGTATCAGCCCCATCTGTTTTGGAATTTGAATTATTGTGGCGCGCCTTGACAGCTTGGGTCATATTGTGATTGATTATGTCGCGTGACGTGTACCAATTATATTTATTATCTGGAGTCATTTTAAGATCATATGGATACAGGAATTTCATATTTAAATTCCGTTGTGAATTAGCATATGTGTATTAACTAAAATGTATGCTCCTAAATATAGACGTTGTTGGTCCTCTACACAACGACGAGGGCATACACGACCGTCATTGTTCAAACGATTTAATGCTGGAAAGCGATACGATGGGAAACGTCGCATCAGCAATCCTAGTCAGGCGAGTGATGAGACCAAGATGACCCCACAGCGTATTCATGAGAACCAGTTTGGCCCAGATTTTGTTATGGGTCATAATACTGCCATATCTACGTTTATCACATACCCCACAATTGGTAAGAATGAGCCATGCCGATCCAGGTCATATATTAAGTTGAAACGGCTACGTTTCAAAGGCACTGTGAAGATTGAGCGTGTACAAGCCGATGTGCTCATGGATGGTCCCCTACCAAAGATTGAGGGAGTATTCTCCTTGGTGGTTGTGGTGGATCGCAAACCTCATTTGAGCTCCTCTGGTTGCCTGCATACGTTTGATGAGATATTTGGTGCTAGGATCAACAGTCATGGAAATCTTGCCATAAGCCCTGCTTTCAAGGACAGATTCTATATACGTCATGTCCTTAAACGTGTCATATCAGTGGAGAAGGATTCTATGATGATGGATCTTGAAGGGACAACATCTCTGTCTAACAGGCGTTATAACTGTTGGTCCTCGTTTAGGGATCTAGAACGTGAATCATGTAATGGGGTCTATGCTAATATAAGCAAGAACGCCCTGTTAGTTTATTATTGCTGGATGTCGGACACTTTGTCAAAGGCATCGACATTTGTATCATTTGATCTTGACTATGTCGGATAGACATATTTAATTGAGAATATAATAAGAGTTTTAATACTAATATTAAGAGATATGTTCAGTAACATGGTAATACTGAGGTTAAGCATTTAAATCTTATAATTATTGCAAAGATTTGGGCTGAGATGGAGTACAGTTGGTGTTAATACATTCTTGGACCGTGGATCTAACCAGGTCGTTTAACTGGGCTATTGACATGGTTATGTTGGACTGGGCCCTTTGTGCCCCAACTATTGAGGCTGAGTCGCCCGGGTCCAATACGGTGGATCCTAATCTGTTCAGCTCTCTATAGGGATGCAGCCTATCACCTATGTCTGATTCCGCATCATTAAGGCCCGTTCCTATTGTGCTCCTGGAAGCCCATGACTCACCGGGCTTTATTTCAATTGGGCCTTGAAGTCCAAACCTTGATGTTGATGCGGACCTGATCATCTTTCTCTCCCATTTCCCATAGCCCACGTGAGAGAAGTCGATATCCTTCTCATTGAATTGTTTGGATAGGATCTTAACGGTGGGAGCGCGGAAAGGGATATCAACGGAATGTTTTGCCGTCGACAGTTTCAGTTTCCCTTTGAATTTTGCGAAATGGGTTCTCTGATGAACATTTGAGTCGCAAACCTTGTAATAGAGCTTCCATGGGATTGGGTCTTTGAGAGAGAAGAATGAGGACGAGAAATAGTGGAGATCTATGTTGCATCTTATCGGGAAAGTCCATGACGCCTGTAGGGACTCGTTGTCTGTCATTCTCTTGTCGTGGATCTCCACAACCACCGTCCCGGCGGCGTTGATTGGAACCTGTTGCCTGTATTCTATGACGCAATGGTCTATCTTCATACAGCTACGACTGAGCCTTGCGCTTAATTGAGCCGCCGTCGAAGGAAATTGCAGGATTATCTCAGTTAGGTCATGAGATAGCTGATATTCGTCGCGGTGCGATTCTATGTAGTTAAAGGCGTTTGGAGCTTGAGCTAACTGAGAATCCATATATGTGAAAAAAGGTCGCGCAGCGACAGCGATTGAGTTAATTTAATGTGTCTGAGAGAAATTCTGAAGAGAATTTAGATTTGTTTTGGTAACTAAAGGATACGTTTTGGGAATATGATAATTAAGAGAAGTTTAACTGGATTTGTATTAGAGGAATTGAGAGGAGATATTCTCTGTCTAAGTTGTTATGAATAAGAGCTGTTATGTTAGCCTCTTTAAATAGAACGACGCGTTTTGGAGCTGATGGCATTTTTGTAATAAGAGGGATGTCACCAATTGAGCTCTCTCTCAAAACTCTAAAGCAATTGGTGACATTGGTGACAATTTATATGTAGGAGTTCCATAACCTCCAGGGGCACGTGGCGGCCATCCGATATAATATT
Gene Information
|
NCBI Accession
|
YP_009175075.1
|
|
Location
|
205-960 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGAAGCCCCTTGGCGCGCGATGGCGGGATCCTCTAAGGTTAGTCGCAATCTCAATTATTCCCCTCGTGGAGGTATGAGGCCCAAATTTGACAAGGCCTCTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACTATGAGAGGACCCGATGTCCCTAAAGGCTGTGAAGGCCCTTGTAAGGTCCAGTCCTACGAACAGCGTCATGATGTCTCGCACGTGGGTAAGGTTATTTGTGTATCTGATGTCACACGTGGTAACGGTATTACTCACCGTGTAGGTAAGCGATTCTGTGTCAAGTCTGTCTACATCCTAGGTAAGATCTGGATGGACGAGAACATCAAATTGAAGAACCACACCAACAGCGTCATGTTTTGGTTGGTGAGAGACAGGAGACCCTATGGCACGCCCATGGATTTTGGCCAGGTGTTTAACATGTTTGACAATGAGCCCAGCACTGCGACAGTTAAGAACGATCTCCGCGATCGTTTTCAAGTCATGCACAAGTTCTATGCCAAGGTGACAGGTGGACAGTATGCGAGCAACGAACAGGCCCTTGTGAGGCGTTTCTGGAAGGTCAACAACCACGTGACTTATAACCATCAGGAGAGAGGGATATATGAGAACCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCCGTGTATGCTACGCTTAAGATTCGGATCTATTTTTACGATTCGATATCAAATTAA |
|
Protein Sequence
|
MPKREAPWRAMAGSSKVSRNLNYSPRGGMRPKFDKASAWVNRPMYRKPRIYRTMRGPDVPKGCEGPCKVQSYEQRHDVSHVGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVRRFWKVNNHVTYNHQERGIYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009175076.1
|
|
Location
|
957-1355 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAAGCGGAGAATGGCGTGTTTATCTGGGAGCTGCAAAATCCCCTGTATTTCAAGATAACCAACGTGGAAGACCCCCTGAACACCAACACCAGGGTCTACCACGTCCAAGTCCGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCGTACTTCAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACATATTTAGCTAGATTTAGGCACTTAGTCATGTTGTACTTAGATCAATTAGGCGTTATCTCAATTAATAATGTAATCAGAGCCGTTCGTTTTGCGACGGACCGGTGTTATGTAAATCATGTACTCGAAGATCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGVFIWELQNPLYFKITNVEDPLNTNTRVYHVQVRFNHNLRRALDLHKAYFNFQVWTTSLTASGTTYLARFRHLVMLYLDQLGVISINNVIRAVRFATDRCYVNHVLEDHSIKFKLY |
|
NCBI Accession
|
YP_009175077.1
|
|
Location
|
1102-1491 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGACATTCGTCTTCCTCGACTCCCCCCTCTATCAAGCCTCAACACAGGGCGGCCAAGCGCAGAGCAACTCGCCGTAGACGCATCGACTTGGAGTGCGGGTGCTCTTTCTTCCTCCACCTCAACTGCGCCAACAATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAAGCGGAGAATGGCGTGTTTATCTGGGAGCTGCAAAATCCCCTGTATTTCAAGATAACCAACGTGGAAGACCCCCTGAACACCAACACCAGGGTCTACCACGTCCAAGTCCGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCGTACTTCAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MRHSSSSTPPSIKPQHRAAKRRATRRRRIDLECGCSFFLHLNCANNGFTHRGTHHCASSGEWRVYLGAAKSPVFQDNQRGRPPEHQHQGLPRPSPVQPQPEESVGSPQGVLQLPSLDDIPDSFWDDIFS |
|
NCBI Accession
|
YP_009175078.1
|
|
Location
|
1412-2491 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCAGCTCCAAAACGCTTCCGTATCTCTTCTAAAAACTATTTCCTTACTTATCCACAGTGCTCTTTATCCAAAGAAGAGGCACTTTCCCAAATACAAACCCTAACTATCCCAACGAACAAGAAGTTCATCAAAATCTGCAGAGAACTTCACGAAAATGGGGAGCCACATCTCCACGTGCTTATTCAGTTCGAGGGAAAGTTCGTCTGCACGAATAACAGATTATTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCTAACATTCAGGGAGCTAAATCATCGTCAGACGTCAAGTCCTATATCGACAAGGACGGTGACACCCTCGAATGGGGTGAATTCCAGGTCGACGGTAGAAGTGCTAGAGGAGGTCAACAGACGGCTAATGACGCTGCCGCCGAGGCACTAAACGCCTCCTCAAAAGATCAGGCGATGCAAATAATCAAAGAGAAGCTGCCGGAAAAGTTTCTCTTTCAATATCACAACCTGTCGGCTAACTTAGACAGGATATTTGCAAAGGCTCCGTCACCATGGGCTCCTCCGTTTCCACTCTCCTCCTTCACTAACGTGCCAGACGAGATGCAAGAGTGGGCGGACAGTTATTTCGGTGTTGATCCCGCTGCGCGGCCTGACAGACCTATTAGTATCATAGTTGAAGGTGATAGTCGGACGGGGAAGACGATGTGGGCTCGTGCATTGGGCCCACATAATTATCTAAGCGGGCATCTGGACTTCAACCCAAGAGTCTACTCAAACGAGGCCCAATACAACGTCATCGATGACGTCAGCCCGCCCCATAAAAAGATGAAACATTGGAAAGAGCTCATTGGGGCCCAACGGGACTGGCAAAGCAACTGTAAATATGGAAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTCTGCAATCCAGGCGAGGGGGCCAGTTATAAAGATTTCCTCGACAAAGAGGAAAACGCATCTCTCAAAGCCTGGACCCTTCACAATGCGACATTCGTCTTCCTCGACTCCCCCCTCTATCAAGCCTCAACACAGGGCGGCCAAGCGCAGAGCAACTCGCCGTAG |
|
Protein Sequence
|
MPSAPKRFRISSKNYFLTYPQCSLSKEEALSQIQTLTIPTNKKFIKICRELHENGEPHLHVLIQFEGKFVCTNNRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGQQTANDAAAEALNASSKDQAMQIIKEKLPEKFLFQYHNLSANLDRIFAKAPSPWAPPFPLSSFTNVPDEMQEWADSYFGVDPAARPDRPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEAQYNVIDDVSPPHKKMKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENASLKAWTLHNATFVFLDSPLYQASTQGGQAQSNSP |
|
NCBI Accession
|
YP_009175079.1
|
|
Location
|
2074-2331 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCACATCTCCACGTGCTTATTCAGTTCGAGGGAAAGTTCGTCTGCACGAATAACAGATTATTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCTAACATTCAGGGAGCTAAATCATCGTCAGACGTCAAGTCCTATATCGACAAGGACGGTGACACCCTCGAATGGGGTGAATTCCAGGTCGACGGTAGAAGTGCTAGAGGAGGTCAACAGACGGCTAATGACGCTGCCGCCGAGGCACTAA |
|
Protein Sequence
|
MGSHISTCLFSSRESSSARITDYSTWYPQPGQHISILTFRELNHRQTSSPISTRTVTPSNGVNSRSTVEVLEEVNRRLMTLPPRH |
|
NCBI Accession
|
YP_009175080.1
|
|
Location
|
455-1225 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATGCTCCTAAATATAGACGTTGTTGGTCCTCTACACAACGACGAGGGCATACACGACCGTCATTGTTCAAACGATTTAATGCTGGAAAGCGATACGATGGGAAACGTCGCATCAGCAATCCTAGTCAGGCGAGTGATGAGACCAAGATGACCCCACAGCGTATTCATGAGAACCAGTTTGGCCCAGATTTTGTTATGGGTCATAATACTGCCATATCTACGTTTATCACATACCCCACAATTGGTAAGAATGAGCCATGCCGATCCAGGTCATATATTAAGTTGAAACGGCTACGTTTCAAAGGCACTGTGAAGATTGAGCGTGTACAAGCCGATGTGCTCATGGATGGTCCCCTACCAAAGATTGAGGGAGTATTCTCCTTGGTGGTTGTGGTGGATCGCAAACCTCATTTGAGCTCCTCTGGTTGCCTGCATACGTTTGATGAGATATTTGGTGCTAGGATCAACAGTCATGGAAATCTTGCCATAAGCCCTGCTTTCAAGGACAGATTCTATATACGTCATGTCCTTAAACGTGTCATATCAGTGGAGAAGGATTCTATGATGATGGATCTTGAAGGGACAACATCTCTGTCTAACAGGCGTTATAACTGTTGGTCCTCGTTTAGGGATCTAGAACGTGAATCATGTAATGGGGTCTATGCTAATATAAGCAAGAACGCCCTGTTAGTTTATTATTGCTGGATGTCGGACACTTTGTCAAAGGCATCGACATTTGTATCATTTGATCTTGACTATGTCGGATAG |
|
Protein Sequence
|
MYAPKYRRCWSSTQRRGHTRPSLFKRFNAGKRYDGKRRISNPSQASDETKMTPQRIHENQFGPDFVMGHNTAISTFITYPTIGKNEPCRSRSYIKLKRLRFKGTVKIERVQADVLMDGPLPKIEGVFSLVVVVDRKPHLSSSGCLHTFDEIFGARINSHGNLAISPAFKDRFYIRHVLKRVISVEKDSMMMDLEGTTSLSNRRYNCWSSFRDLERESCNGVYANISKNALLVYYCWMSDTLSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009175081.1
|
|
Location
|
1325-2206 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGCTCAAGCTCCAAACGCCTTTAACTACATAGAATCGCACCGCGACGAATATCAGCTATCTCATGACCTAACTGAGATAATCCTGCAATTTCCTTCGACGGCGGCTCAATTAAGCGCAAGGCTCAGTCGTAGCTGTATGAAGATAGACCATTGCGTCATAGAATACAGGCAACAGGTTCCAATCAACGCCGCCGGGACGGTGGTTGTGGAGATCCACGACAAGAGAATGACAGACAACGAGTCCCTACAGGCGTCATGGACTTTCCCGATAAGATGCAACATAGATCTCCACTATTTCTCGTCCTCATTCTTCTCTCTCAAAGACCCAATCCCATGGAAGCTCTATTACAAGGTTTGCGACTCAAATGTTCATCAGAGAACCCATTTCGCAAAATTCAAAGGGAAACTGAAACTGTCGACGGCAAAACATTCCGTTGATATCCCTTTCCGCGCTCCCACCGTTAAGATCCTATCCAAACAATTCAATGAGAAGGATATCGACTTCTCTCACGTGGGCTATGGGAAATGGGAGAGAAAGATGATCAGGTCCGCATCAACATCAAGGTTTGGACTTCAAGGCCCAATTGAAATAAAGCCCGGTGAGTCATGGGCTTCCAGGAGCACAATAGGAACGGGCCTTAATGATGCGGAATCAGACATAGGTGATAGGCTGCATCCCTATAGAGAGCTGAACAGATTAGGATCCACCGTATTGGACCCGGGCGACTCAGCCTCAATAGTTGGGGCACAAAGGGCCCAGTCCAACATAACCATGTCAATAGCCCAGTTAAACGACCTGGTTAGATCCACGGTCCAAGAATGTATTAACACCAACTGTACTCCATCTCAGCCCAAATCTTTGCAATAA |
|
Protein Sequence
|
MDSQLAQAPNAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLSARLSRSCMKIDHCVIEYRQQVPINAAGTVVVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFNEKDIDFSHVGYGKWERKMIRSASTSRFGLQGPIEIKPGESWASRSTIGTGLNDAESDIGDRLHPYRELNRLGSTVLDPGDSASIVGAQRAQSNITMSIAQLNDLVRSTVQECINTNCTPSQPKSLQ |