Malvastrum yellow vein Lahore virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013087685.1 |
| Isolate |
Pakistan: Lahore |
| Release date |
2021/6/1 |
| Submitter |
Zia Ur Rehman,M., Hameed,U., Iqbal,M.J., Ilyas,M., Haider,M.S., Brown,J.K. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
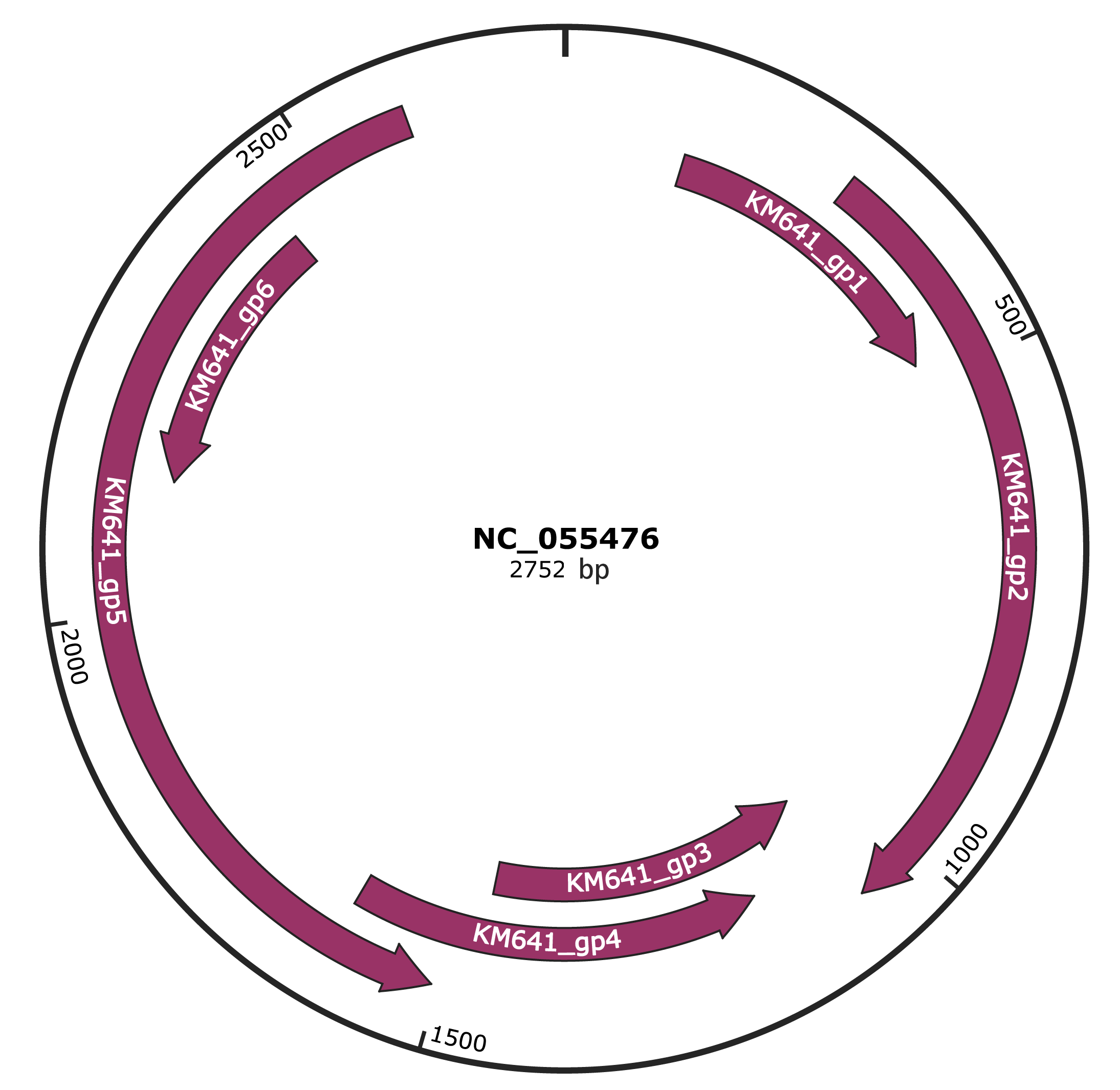
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTGTGGGTCCCTCCACTAACTCCTGTCTGCCAATCAAATTACGCGCTCAAAGCTTAAATAATATCCCGCCTATTATAAGTACTTCTTCGACAAGTTTCATTTTGAAAATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGTATGCTTGCAATAAAATACCTGCAATTATTATCTGAGGAATACTCTCCTGATACGGTAGGTTACGATTTAATTCGCGATTTAATTTCTATTTTACGGTCTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCATTGTCCGCGTCACCAAATCAAGAATATGGGCGAACAGGCCCATGAACAGAAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTAAGGGATGTGAAGGCCCATGTAAGGTGCAGTCCTTTGAGTCCAGACATGATATTCAGCATATAGGTAAAGTAATGTGTATTAGTGATGTTACACGTGGTATTGGGCTGACCCATAGAGTTGGTAAGAGATTTTGTGTTAAATCTGTTTATGTATTGGGTAAGATCTGGATGGATGAGAACATTAAGACGAAGAACCATACGAATAGTGTGATGTTTTTTTTGGTTAGAGATCGTAGACCTGTTGATAAACCTCAGGATTTTGGAGAGGTATTTAATATGTTTGATAACGAGCCTAGTACGGCGACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTTCTGCGCAAATGGTATGCAACTGTCACCGGTGGACAATACGCTTCAAAGGAACAAGCACTCGTGAAGAAGTTTATTAGAGTTAATAATTATGTTGTGTATAACCAGCAGGAAGCTGGCAAGTATGAGAATCATTCTGAAAATGCTTTAATGTTGTATATGGCGTGTACTCACGCCTCTAATCCAGTGTATGCTACCTTAAAGATACGGATCTACTTCTATGATTCTGTGACAAATTATTAATAAATATTGAATTTTATTTCTAAAGATTGCTTTACATACATAGTTTGTTCTATTTTATTGTACAATACATATTCTACAGCCCTAATAATTGAATTAAGTGAGATTACTCCTAGATTGTTTAGATATTTGATGACTTGGGTTTTCAATACCCTTAAGAAAAGACCAGTCGGAGGGCGTAAGGTCGTCCAGATTTGGAAGGTCAGAAAACACTTGTGCACTCCCAGAGCTTTCCGAAGGTTGTAGTTGAATTGGATCCTGATTGTTATTATGTCCATGTTGCTCGTGAATGGACGTTCTTGGTGGCTGAGGATTTTGAAATAAAGGGGATTTGGAACTTCCCAGATATATGCGCCACTCCATGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTAAATCCATGGTTGAAGCAGTTAATAGATAGATAATAAGAACACCCGCATTCAAGATCTACTCTCCTCCTCCTGTTGCGCCTCTTCGCTTCCCTGTGCTGTACTTTGATTGGAACCGGAGTACAGTGGTCCTTCAAGGGTGATAAAGATCGCATTCTTTTCTGCCCAGTTCTTTAGTGCGGTGTTCTTTTCCTCGTCTAGGAATTCTTTATAACTGCTGTTGTGACCAGGATTGCAGAGGAAGATTGTTGGTATTCCGCCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTGGATTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTGAGGAAGTGCGGATCTACGTCATCAATGACGTTATACCAAGCGTCATTACTGTACACCTTTGGGCTTAGATCTAAATGCCCACATAAATAGTTATGTGGGCCTAAAGACCTAGCCCACATCGTCTTCCCAGTACGACTATCACCCTCGATTACTATACTTTGAGGTCTTAGGGGCCGCGCAGCGGCGTCGACAACATTGTCACACGCCCACTCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGATGAAAAAGGAGAAACATAAGGAGCTGGTGGCTCCTGAAAGATTCTGTCTAGATTTGCATTTAAATTATGAAATTGTAGTACAAAATCTTTAGGAGCTAGCTCCTTAATGACTCTAAGAGCCTCTGACTTACTGCCTGCGTTAAGTGCTGCGGCGTAAGCGTCATTGGCTGTCTGTTGTCCTCCTCTTGCTGATCTTCCATCGATCTGAAATTCCCCCCACTCGAGAATGTCCCCGTCCTTGGCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTAGTTGGGGATACGAGGTCGAAGAATCTCTGATTCTTGCACTGGTATTTGCCTTCGAACTGGAGGAGCACGTGAAGATGAGGTTCCCCATTCTCGTGAAGCTCTCTGCAGATTCTAATGTATTTTTTGTTTACTGGGGTTTGTAGATTTTGTAATTGGGAAAGTGCTTCCTCTTTAGTAAGAGAGCATGTGGGATAAGTGATGAAATAATTTTTGGCATTTATTTTAAATGGTTTTGGAGGAGCCATGGTCAATGGACACCGATTGACTCTTCAGAACAACTTACTATATGAATCGGTATCTGGGGTCTTATTTATACTTGGACACCAAATGGCATTTTGGTAAAAATTAAAAAGAAATTCAAATCCCACAGGCTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010086776.1
|
|
Location
|
131-478 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGTATGCTTGCAATAAAATACCTGCAATTATTATCTGAGGAATACTCTCCTGATACGGTAGGTTACGATTTAATTCGCGATTTAATTTCTATTTTACGGTCTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCATTGTCCGCGTCACCAAATCAAGAATATGGGCGAACAGGCCCATGAACAGAAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASASELRQPLCNPCSCPHCPRHQIKNMGEQAHEQKAQNVQDVQKP |
|
NCBI Accession
|
YP_010086777.1
|
|
Location
|
291-1064 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCATTGTCCGCGTCACCAAATCAAGAATATGGGCGAACAGGCCCATGAACAGAAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTAAGGGATGTGAAGGCCCATGTAAGGTGCAGTCCTTTGAGTCCAGACATGATATTCAGCATATAGGTAAAGTAATGTGTATTAGTGATGTTACACGTGGTATTGGGCTGACCCATAGAGTTGGTAAGAGATTTTGTGTTAAATCTGTTTATGTATTGGGTAAGATCTGGATGGATGAGAACATTAAGACGAAGAACCATACGAATAGTGTGATGTTTTTTTTGGTTAGAGATCGTAGACCTGTTGATAAACCTCAGGATTTTGGAGAGGTATTTAATATGTTTGATAACGAGCCTAGTACGGCGACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTTCTGCGCAAATGGTATGCAACTGTCACCGGTGGACAATACGCTTCAAAGGAACAAGCACTCGTGAAGAAGTTTATTAGAGTTAATAATTATGTTGTGTATAACCAGCAGGAAGCTGGCAAGTATGAGAATCATTCTGAAAATGCTTTAATGTTGTATATGGCGTGTACTCACGCCTCTAATCCAGTGTATGCTACCTTAAAGATACGGATCTACTTCTATGATTCTGTGACAAATTATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYATRAVAPIVRVTKSRIWANRPMNRKPRMYRMYRSPDVPKGCEGPCKVQSFESRHDIQHIGKVMCISDVTRGIGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWYATVTGGQYASKEQALVKKFIRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTNY |
|
NCBI Accession
|
YP_010086778.1
|
|
Location
|
1061-1465 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCATATATCTGGGAAGTTCCAAATCCCCTTTATTTCAAAATCCTCAGCCACCAAGAACGTCCATTCACGAGCAACATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAAAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCAAATCTGGACGACCTTACGCCCTCCGACTGGTCTTTTCTTAAGGGTATTGAAAACCCAAGTCATCAAATATCTAAACAATCTAGGAGTAATCTCACTTAATTCAATTATTAGGGCTGTAGAATATGTATTGTACAATAAAATAGAACAAACTATGTATGTAAAGCAATCTTTAGAAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDLRTGEPITAAQAWSGAYIWEVPNPLYFKILSHQERPFTSNMDIITIRIQFNYNLRKALGVHKCFLTFQIWTTLRPPTGLFLRVLKTQVIKYLNNLGVISLNSIIRAVEYVLYNKIEQTMYVKQSLEIKFNIY |
|
NCBI Accession
|
YP_010086779.1
|
|
Location
|
1158-1610 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGATCTTTATCACCCTTGAAGGACCACTGTACTCCGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACAGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTATCTATTAACTGCTTCAACCATGGATTTACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCATATATCTGGGAAGTTCCAAATCCCCTTTATTTCAAAATCCTCAGCCACCAAGAACGTCCATTCACGAGCAACATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAAAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCAAATCTGGACGACCTTACGCCCTCCGACTGGTCTTTTCTTAAGGGTATTGAAAACCCAAGTCATCAAATATCTAAACAATCTAGGAGTAATCTCACTTAA |
|
Protein Sequence
|
MRSLSPLKDHCTPVPIKVQHREAKRRNRRRRVDLECGCSYYLSINCFNHGFTHRGTHHCSSSMEWRIYLGSSKSPLFQNPQPPRTSIHEQHGHNNNQDPIQLQPSESSGSAQVFSDLPNLDDLTPSDWSFLKGIENPSHQISKQSRSNLT |
|
NCBI Accession
|
YP_010086780.1
|
|
Location
|
1507-2598 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTCCTCCAAAACCATTTAAAATAAATGCCAAAAATTATTTCATCACTTATCCCACATGCTCTCTTACTAAAGAGGAAGCACTTTCCCAATTACAAAATCTACAAACCCCAGTAAACAAAAAATACATTAGAATCTGCAGAGAGCTTCACGAGAATGGGGAACCTCATCTTCACGTGCTCCTCCAGTTCGAAGGCAAATACCAGTGCAAGAATCAGAGATTCTTCGACCTCGTATCCCCAACTAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGCCAAGGACGGGGACATTCTCGAGTGGGGGGAATTTCAGATCGATGGAAGATCAGCAAGAGGAGGACAACAGACAGCCAATGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAGCTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGAATCTTTCAGGAGCCACCAGCTCCTTATGTTTCTCCTTTTTCATCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCGTGTGACAATGTTGTCGACGCCGCTGCGCGGCCCCTAAGACCTCAAAGTATAGTAATCGAGGGTGATAGTCGTACTGGGAAGACGATGTGGGCTAGGTCTTTAGGCCCACATAACTATTTATGTGGGCATTTAGATCTAAGCCCAAAGGTGTACAGTAATGACGCTTGGTATAACGTCATTGATGACGTAGATCCGCACTTCCTCAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGAATACCAACAATCTTCCTCTGCAATCCTGGTCACAACAGCAGTTATAAAGAATTCCTAGACGAGGAAAAGAACACCGCACTAAAGAACTGGGCAGAAAAGAATGCGATCTTTATCACCCTTGAAGGACCACTGTACTCCGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACAGGAGGAGGAGAGTAGATCTTGA |
|
Protein Sequence
|
MAPPKPFKINAKNYFITYPTCSLTKEEALSQLQNLQTPVNKKYIRICRELHENGEPHLHVLLQFEGKYQCKNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIAKDGDILEWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSSSSFDQVPEELEEWACDNVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGHNSSYKEFLDEEKNTALKNWAEKNAIFITLEGPLYSGSNQSTAQGSEEAQQEEESRS |
|
NCBI Accession
|
YP_010086781.1
|
|
Location
|
2139-2441 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTTCACGTGCTCCTCCAGTTCGAAGGCAAATACCAGTGCAAGAATCAGAGATTCTTCGACCTCGTATCCCCAACTAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGCCAAGGACGGGGACATTCTCGAGTGGGGGGAATTTCAGATCGATGGAAGATCAGCAAGAGGAGGACAACAGACAGCCAATGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAGCTAG |
|
Protein Sequence
|
MGNLIFTCSSSSKANTSARIRDSSTSYPQLGQHISIRTYRELNPAPTSSPISPRTGTFSSGGNFRSMEDQQEEDNRQPMTLTPQHLTQAVSQRLLESLRS |