Malvastrum yellow vein Honghe virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001706885.1 |
| Isolate |
China:Yunnan Province |
| Release date |
2016/8/18 |
| Submitter |
Liu,P., Zhou,X.P. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
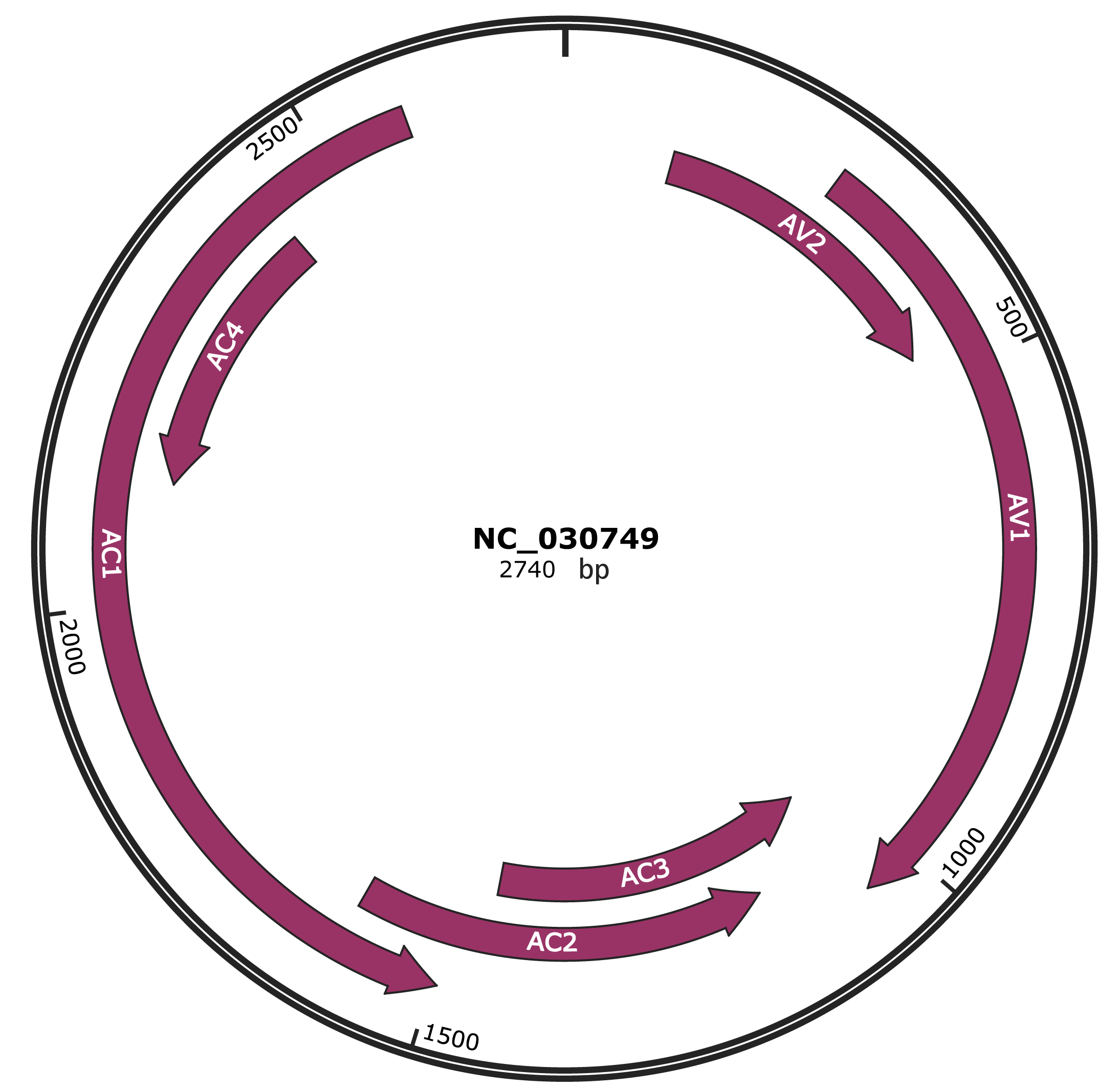
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTGGGTGGGCCCTTGGCCAATCAGATGATGCGCTGAAAGCTTAAATAAATCTCCCGCCCTTATAAATACTTCGGGCCTAAGTATCCGCTTTGAAAATGTGGGATCCACTTGTAAACGAGTTCCCCGAGACGGTTCATGGTTTTCGGTGCATGCTTTCTATCAAATATCTTCAGTTGCTCTCTGAAGGTTATTCTCCAGATACGGTAGGTTACGATCTAATACGTGAATTAATTGCAATTTTGCGTTCCAGGAATTATGTCGAAGCGTCCTGCAGATATCGTAATTTCTACCCCCGCGTCGAAGGTTCGTCGTCGTCTGAACTTCGACAGTCCTTACTCAACCCGTGTAGTAACTGTCCCTACTGTCCGCGCCACAAAATCTCGAATGTGGGCGAACCGGCCCATGAATCGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGATGTTCCTCGTGGTTGTGAGGGTCCATGTAAGGTCCAATCTTTTGATGCGAAGAACGATATTGGTCACATGGGTAAGGTGGTATGTTTGTCCGATGTAACTAGGGGAATGGGTTTGACTCATCGTGTTGGTAAACGTTTCTGCGTTAAGTCGTTGTATTTTGTTGGCAAGATCTGGATGGATGAAAATATCAAGGTTAAGAATCACACTAACACCGTTTTGTTTTGGATTGTTCGAGATAGGCGTCCTACTGGCACTCCTAATGACTTTCAGCAGGTTTTTAATGTGTATGATAATGAACCGTCTACTGCGACTGTTAAGAATGACCAACGTGATCGCTATCAAGTCTTGCGGAGGTTTCAGGCAACGGTGACTGGTGGACAATATGCAGCTAAGGAACAGGCTATCATTAGGAGATTTTATCGTGTTAATAATTATGTAGTTTATAATCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAGTGAGGAGTTATTTTTATGACTCTGTCACGAATTAATAAAGATTAAATTTTATTTCTGAATTCATGTCTACATACATAGTTTGTTCTATTTTTTTCCATAATACATGATCTATAGCCCTAATAATTGAATTAATGGAGATTACACCCAGATTGTTTAGATATTTGAGGACTTGGGTTTTGAATACCCTTAAGAAAAGACCAGTCCGAGGGTGTAAGGTCGTCCATATTCGGTAGGTCAGAAAACACTTGTGCACTTCCAGAGCTCTCCGAAGGTTGTAGTTGAATTGGATCCTGATTGTTATTATGTCCATGTTCATCGTGAATGGACGGTTGTCGTGGTTGAGGATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATATAGGCGCCATTCCATGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTAAATCCATGGTTGAAGCAGTTGATTGACAGGTAATAAGAGCACCCGCATTCAAGATCTACTCTCCTCCTCCTGTTGCGTCTCTTCGCTTCCCTGTGCTGTACTTTGATTGGAACCTGAGTACAGTGGTCTTTCGAGGGTGATGAAGATCGCATTCTTGAGAGTCCAGTTCTTTAGTGCGGTGTTCTTCTCCTCGTCGAGGAATTCTTTATAACTGCTGTTGGGGCCAGGATTGCACAGGAAGATTGTCGGTATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTCGTATTTGATTGCCAGTCCCGTTGGGCCCCCATGAATTCTTTAAAGTGTTTGAGGAAGTGGGGATCTACGTCATCAATGACGTTGTACCAAGCATCGTTGCTGTAGACCTTTGGGCTTAGATCCAAATGGCCACATAGATAGTTGTGTGGGCCTAGAGACCTAGCCCACATCGTCTTCCCGGTACGACTGTCTCCCTCAATCACTATACTCATTGGTCTTAGGGGCCGCGCAGCGGCGTCGACGACGTTCTCGGACGCCCACTCTTCAAGTTCTTCTGGAACTTGATCGAACGAAGAAGAAGAAAAAGGAGAAACATAAACCTCCAGCGGAGGTGTAAAAATCCTATCTAAATTAGCATTTAAATTATGAAATTGTAATACATAATCCTTAGGGGCTAATTCCCTAAGTACGCTAAGAGCCTCTGACTTATTGCCTGTGTTAAGTGCTGCTGCGTAAGCGTCGTTGGCTGATTGTTGACCTCCTCTTGCAGATCGCCCATCGATCTGAAATTCTCCCCATTCGAGAATGTCTCCGTCCTTGTGGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCGGTTATTTTTGCATTGGAATTTGCCCTCGAACTGGATGAGCACGTGCAAATGAGGTTCCCCATTTTCATGAAACTCTCTGCATATTTTGATGTATTTTTTGGAAGTTGGGGTTTGAAGGTTTTGTAATTGGGAAAGTGCTTCGTCTTTTGTGAGAGAGCATTTAGGATAAGTAAGGAAATAGTTTTTGGCATTTATTTTAAATTGTTTTGTAGGATGCATGGTCAATGGACACCGATTGACTCTCCAAAACAACTTGTCTATGCAATCGGTGTATTGGGGTCTTATTTATACCTGGACACCAAATGGCAAAGTCGTAATTCACATAAGAAATTCATACCCTTACGGTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009270643.1
|
|
Location
|
119-469 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCACTTGTAAACGAGTTCCCCGAGACGGTTCATGGTTTTCGGTGCATGCTTTCTATCAAATATCTTCAGTTGCTCTCTGAAGGTTATTCTCCAGATACGGTAGGTTACGATCTAATACGTGAATTAATTGCAATTTTGCGTTCCAGGAATTATGTCGAAGCGTCCTGCAGATATCGTAATTTCTACCCCCGCGTCGAAGGTTCGTCGTCGTCTGAACTTCGACAGTCCTTACTCAACCCGTGTAGTAACTGTCCCTACTGTCCGCGCCACAAAATCTCGAATGTGGGCGAACCGGCCCATGAATCGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLSIKYLQLLSEGYSPDTVGYDLIRELIAILRSRNYVEASCRYRNFYPRVEGSSSSELRQSLLNPCSNCPYCPRHKISNVGEPAHESKAQNVQDVQKP |
|
NCBI Accession
|
YP_009270644.1
|
|
Location
|
279-1052 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCAGATATCGTAATTTCTACCCCCGCGTCGAAGGTTCGTCGTCGTCTGAACTTCGACAGTCCTTACTCAACCCGTGTAGTAACTGTCCCTACTGTCCGCGCCACAAAATCTCGAATGTGGGCGAACCGGCCCATGAATCGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGATGTTCCTCGTGGTTGTGAGGGTCCATGTAAGGTCCAATCTTTTGATGCGAAGAACGATATTGGTCACATGGGTAAGGTGGTATGTTTGTCCGATGTAACTAGGGGAATGGGTTTGACTCATCGTGTTGGTAAACGTTTCTGCGTTAAGTCGTTGTATTTTGTTGGCAAGATCTGGATGGATGAAAATATCAAGGTTAAGAATCACACTAACACCGTTTTGTTTTGGATTGTTCGAGATAGGCGTCCTACTGGCACTCCTAATGACTTTCAGCAGGTTTTTAATGTGTATGATAATGAACCGTCTACTGCGACTGTTAAGAATGACCAACGTGATCGCTATCAAGTCTTGCGGAGGTTTCAGGCAACGGTGACTGGTGGACAATATGCAGCTAAGGAACAGGCTATCATTAGGAGATTTTATCGTGTTAATAATTATGTAGTTTATAATCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAGTGAGGAGTTATTTTTATGACTCTGTCACGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYSTRVVTVPTVRATKSRMWANRPMNRKPRMYRMYKSPDVPRGCEGPCKVQSFDAKNDIGHMGKVVCLSDVTRGMGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVLFWIVRDRRPTGTPNDFQQVFNVYDNEPSTATVKNDQRDRYQVLRRFQATVTGGQYAAKEQAIIRRFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_009270645.1
|
|
Location
|
1049-1453 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAACCACGACAACCGTCCATTCACGATGAACATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGAAGTGCACAAGTGTTTTCTGACCTACCGAATATGGACGACCTTACACCCTCGGACTGGTCTTTTCTTAAGGGTATTCAAAACCCAAGTCCTCAAATATCTAAACAATCTGGGTGTAATCTCCATTAATTCAATTATTAGGGCTATAGATCATGTATTATGGAAAAAAATAGAACAAACTATGTATGTAGACATGAATTCAGAAATAAAATTTAATCTTTATTAA |
|
Protein Sequence
|
MDLRTGEPITAAQAWNGAYIWEVPNPLYFKILNHDNRPFTMNMDIITIRIQFNYNLRRALEVHKCFLTYRIWTTLHPRTGLFLRVFKTQVLKYLNNLGVISINSIIRAIDHVLWKKIEQTMYVDMNSEIKFNLY |
|
NCBI Accession
|
YP_009270646.1
|
|
Location
|
1146-1598 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCGAAAGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGACGCAACAGGAGGAGGAGAGTAGATCTTGAATGCGGGTGCTCTTATTACCTGTCAATCAACTGCTTCAACCATGGATTTACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAACCACGACAACCGTCCATTCACGATGAACATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGAAGTGCACAAGTGTTTTCTGACCTACCGAATATGGACGACCTTACACCCTCGGACTGGTCTTTTCTTAAGGGTATTCAAAACCCAAGTCCTCAAATATCTAAACAATCTGGGTGTAATCTCCATTAA |
|
Protein Sequence
|
MRSSSPSKDHCTQVPIKVQHREAKRRNRRRRVDLECGCSYYLSINCFNHGFTHRGTHHCSSSMEWRLYLGGSKSPLFQDPQPRQPSIHDEHGHNNNQDPIQLQPSESSGSAQVFSDLPNMDDLTPSDWSFLKGIQNPSPQISKQSGCNLH |
|
NCBI Accession
|
YP_009270647.1
|
|
Location
|
1495-2586 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCATCCTACAAAACAATTTAAAATAAATGCCAAAAACTATTTCCTTACTTATCCTAAATGCTCTCTCACAAAAGACGAAGCACTTTCCCAATTACAAAACCTTCAAACCCCAACTTCCAAAAAATACATCAAAATATGCAGAGAGTTTCATGAAAATGGGGAACCTCATTTGCACGTGCTCATCCAGTTCGAGGGCAAATTCCAATGCAAAAATAACCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCCACAAGGACGGAGACATTCTCGAATGGGGAGAATTTCAGATCGATGGGCGATCTGCAAGAGGAGGTCAACAATCAGCCAACGACGCTTACGCAGCAGCACTTAACACAGGCAATAAGTCAGAGGCTCTTAGCGTACTTAGGGAATTAGCCCCTAAGGATTATGTATTACAATTTCATAATTTAAATGCTAATTTAGATAGGATTTTTACACCTCCGCTGGAGGTTTATGTTTCTCCTTTTTCTTCTTCTTCGTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCGTCCGAGAACGTCGTCGACGCCGCTGCGCGGCCCCTAAGACCAATGAGTATAGTGATTGAGGGAGACAGTCGTACCGGGAAGACGATGTGGGCTAGGTCTCTAGGCCCACACAACTATCTATGTGGCCATTTGGATCTAAGCCCAAAGGTCTACAGCAACGATGCTTGGTACAACGTCATTGATGACGTAGATCCCCACTTCCTCAAACACTTTAAAGAATTCATGGGGGCCCAACGGGACTGGCAATCAAATACGAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATACCGACAATCTTCCTGTGCAATCCTGGCCCCAACAGCAGTTATAAAGAATTCCTCGACGAGGAGAAGAACACCGCACTAAAGAACTGGACTCTCAAGAATGCGATCTTCATCACCCTCGAAAGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGACGCAACAGGAGGAGGAGAGTAGATCTTGA |
|
Protein Sequence
|
MHPTKQFKINAKNYFLTYPKCSLTKDEALSQLQNLQTPTSKKYIKICREFHENGEPHLHVLIQFEGKFQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIHKDGDILEWGEFQIDGRSARGGQQSANDAYAAALNTGNKSEALSVLRELAPKDYVLQFHNLNANLDRIFTPPLEVYVSPFSSSSFDQVPEELEEWASENVVDAAARPLRPMSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNTALKNWTLKNAIFITLERPLYSGSNQSTAQGSEETQQEEESRS |
|
NCBI Accession
|
YP_009270648.1
|
|
Location
|
2127-2429 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATTTGCACGTGCTCATCCAGTTCGAGGGCAAATTCCAATGCAAAAATAACCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCCACAAGGACGGAGACATTCTCGAATGGGGAGAATTTCAGATCGATGGGCGATCTGCAAGAGGAGGTCAACAATCAGCCAACGACGCTTACGCAGCAGCACTTAACACAGGCAATAAGTCAGAGGCTCTTAGCGTACTTAGGGAATTAG |
|
Protein Sequence
|
MGNLICTCSSSSRANSNAKITDSSTWYPQPGQHISIQTFRELNPAPTSSPTSTRTETFSNGENFRSMGDLQEEVNNQPTTLTQQHLTQAISQRLLAYLGN |