Malvastrum yellow mosaic Helshire virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002822785.1 |
| Isolate |
Jamaica |
| Release date |
2018/8/25 |
| Submitter |
Graham,A.P., Roye,M.E. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
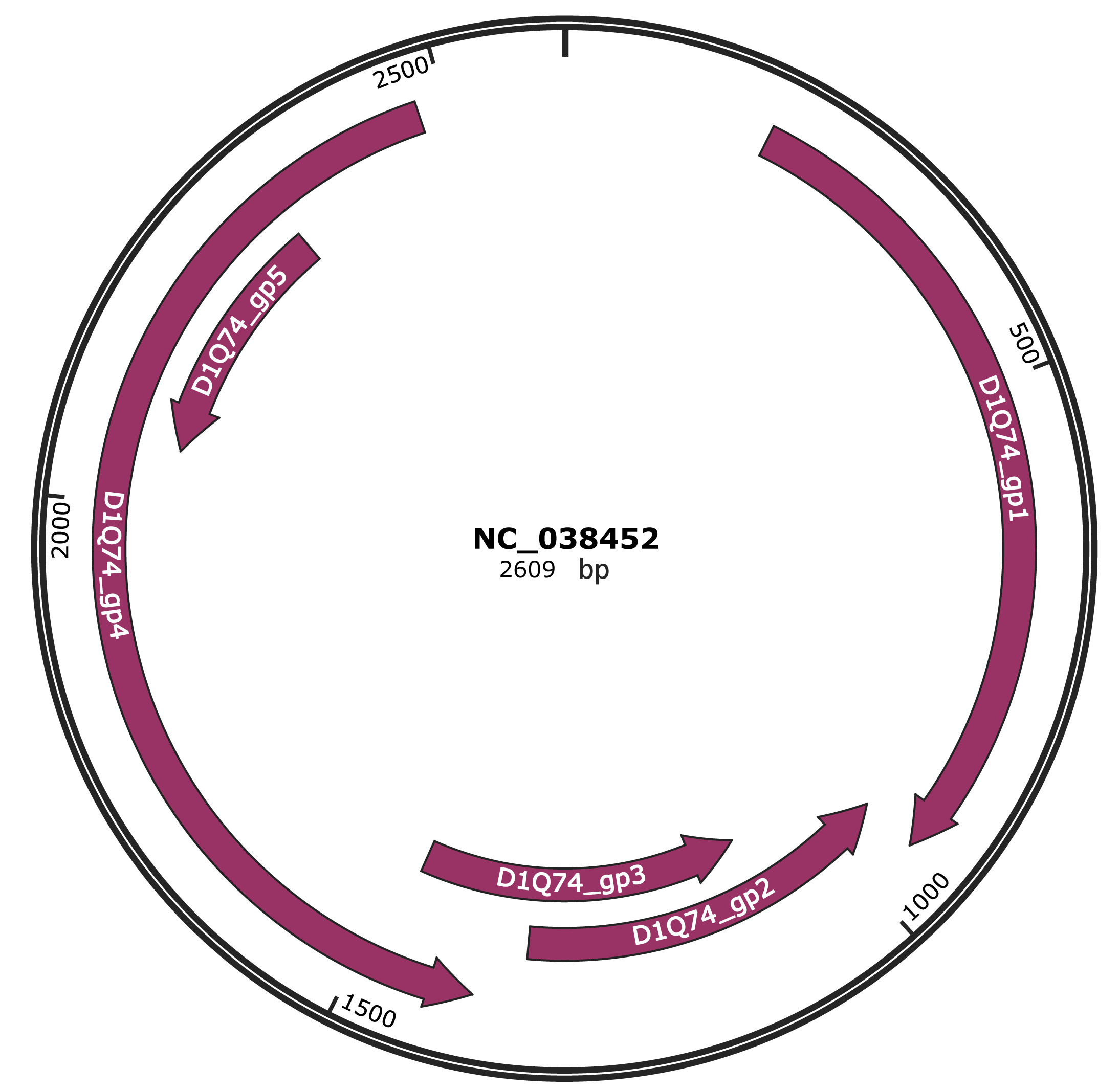
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCCCTTTTGTTCCCCCCTTTGGTTTCTCACGCGCGCTTCGCTTTTCTCACTCGCGCTCTTGTCCAATCATATTCCGCCTACCGCGCCTAGATATTTCAAACAACTTGGGCCCTAAGTTGTTGTCTGGCCTATATATGAAAAGCGTATTGGGCCATTGTGTCTAACCCAATATGTCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAATGTCAAAGGTCCGCCGTACTCTAAATTACTCCCCTCGTGCAGGTTTGGGCCCTAGGAACAACAAGGCCGCTGAGTGGGTCAACAGGCCCATGTACAGGAAGCCCAAGATCTATCGGACGCTAAGGACTCCCGATGTGCCCAGAGGATGTGAAGGCCCATGCAAGGTCCAGTCCTATGAACAGCGTCATGACATCTCCCACGTTGGCAAGGTGATGTGTATTTCTGATGTCACCCGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTCGACCCTATGGCACTCCAATGGACTTTGGCCAGGTGTTCAACATGTATGACAACGAGCCTAGCACTGCCACGATTAAGAACGATCTCAGGGATCGTTTTCAGGTTATGCACAGGTTCTATGGCAAAGTCACTGGTGGACAATATGCCAGCAACGAGCAGGCTTTGGTCAGGCGGTTTTGGAAGGTCAACAATCATGTGGTCTACAACCACCAAGAGGCTGGCAAATACGAGAATCACACTGAGAATGCCTTATTATTGTACATGGCATGTACTCATGCTTCTAACCCCGTGTATGCAACATTGAAAATTCGAATCTATTTCTACGATTCGATAACTAATTAATAAAATTTTAATTTTATTTCATGGTTTTCAAGTACATATCTTACATAAACTCGGTCTGTTGCAAACCGAACAGCCCTAATTACATTGTTAAGTGAAATTACACCTAACTCGTCTAAATACATATTAACTAAGCGTCTAAACCTAACTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGACCCAACACTTTCCTCAGGTTGTGGTTGAATCGTATCTGGATATTGTACACCCTTGTTCTGGTGTATAGCAGGTCCACTACTCTGTATATCCTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCATGAGGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCTGTACAGCCTATGTGGAAGTAGATGGAGCACCCGCACTCTAGATCAATCCTGCGCCTCCTGATGGCCCTCCTCTTGGCTTGCCTGTGTGCCTTCTTGATACAGGGGGGCTGTGAGGGTGATGAAGATCGCATTCTTGAGAGTCCAGTTCCTGAGACCTATGTTTTCCTCTTTGTCTAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCGCCTTTAATTTGAACTGGCTTGCCGTACTTGCAATTTGATTGCCAGTCTTTCTGGGCCCCCAGAAGCTCTTTCCAGTGCTTTAACTTTAGATAATGCGGTGCGACATCATCAATGATGTTATACTCCACATCGTTTGAGAAGACTTTTGAATTAAAGTCTAGGTGGCCACTGAGATAATTATGTGGGCCTAAGGCACGAGCCCACATCGTCTTCCCTGTCCTCGAGTCACCTTCTACAATGAGACTTACTGGTCTCTCCGGCCGCGCAGCGGCACCTCTCCCAAAATAACTGTCCGACCATTCTTGCATCTCGTCCGGCACGTTAGTGAAAGAGGAGAGGGGAAACGGAGGAGACCATGGCTCCGGAGCCTTCATGAAAATCCTATCGAGGTTACTGGATAGGTTATGATACTGGAAAAGAAACTTCTCCGGCAACTTCTCTTTGATGATTTTCATGGCCTCCTCCTTTGTTCCAGCATTTAACGCCTCGGCGGCTGCATCATTAGCTGTCTGCTGACCGCCACGAGCACTTCTTCCGTCGATCTCGAACACTCCCCATTCGATGGTGTCACCGTCTTTCGCGACATAGGACTTGACATCGGAGCTCGACCGAGCTCCCTGAATGTTTGGATGGAAAGGTGCTGACCTGGTTGGGGACACCATGTCGAAGAGTCTGTTATTCGTGCAGTTGAACTTGCCTTCGAGCTGCATGAGCACATGGAGATGAGGCTCCCCATTTTCGTGAAACTCTCGTGAAATTTTGATAAATTTCTTATTTACTGGTGTATGGATTTTTCTAAGTTGTTCTAAGGCTTCCTCTTTGCCAAGAGAGCAACGAGGGTATGTGATGAAATAGTTTTTGGCTTTAATAGAAAATACTCCTTTCCGTGGCATTTTCTGTAAATATTGGTGTTCCCCCAATTGCTCTCTCGCTCAAAACTCTTGTGAATTGGGGGAAATGGGGGAAAACATATAGTAGAAGTTCCATGGGTTAGATCTGCCACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506437.1
|
|
Location
|
192-947 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGTCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAATGTCAAAGGTCCGCCGTACTCTAAATTACTCCCCTCGTGCAGGTTTGGGCCCTAGGAACAACAAGGCCGCTGAGTGGGTCAACAGGCCCATGTACAGGAAGCCCAAGATCTATCGGACGCTAAGGACTCCCGATGTGCCCAGAGGATGTGAAGGCCCATGCAAGGTCCAGTCCTATGAACAGCGTCATGACATCTCCCACGTTGGCAAGGTGATGTGTATTTCTGATGTCACCCGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTCGACCCTATGGCACTCCAATGGACTTTGGCCAGGTGTTCAACATGTATGACAACGAGCCTAGCACTGCCACGATTAAGAACGATCTCAGGGATCGTTTTCAGGTTATGCACAGGTTCTATGGCAAAGTCACTGGTGGACAATATGCCAGCAACGAGCAGGCTTTGGTCAGGCGGTTTTGGAAGGTCAACAATCATGTGGTCTACAACCACCAAGAGGCTGGCAAATACGAGAATCACACTGAGAATGCCTTATTATTGTACATGGCATGTACTCATGCTTCTAACCCCGTGTATGCAACATTGAAAATTCGAATCTATTTCTACGATTCGATAACTAATTAA |
|
Protein Sequence
|
MSKRDAPWRSMAGMSKVRRTLNYSPRAGLGPRNNKAAEWVNRPMYRKPKIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATIKNDLRDRFQVMHRFYGKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009506438.1
|
|
Location
|
944-1342 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCATGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGAGTAGTGGACCTGCTATACACCAGAACAAGGGTGTACAATATCCAGATACGATTCAACCACAACCTGAGGAAAGTGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAGGTTTAGACGCTTAGTTAATATGTATTTAGACGAGTTAGGTGTAATTTCACTTAACAATGTAATTAGGGCTGTTCGGTTTGCAACAGACCGAGTTTATGTAAGATATGTACTTGAAAACCATGAAATAAAATTAAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPHAENGVYIWEIENPLYFRIYRVVDLLYTRTRVYNIQIRFNHNLRKVLGLHKAYLNFQVWTTSMTASGSTYLVRFRRLVNMYLDELGVISLNNVIRAVRFATDRVYVRYVLENHEIKLKFY |
|
NCBI Accession
|
YP_009506439.1
|
|
Location
|
1089-1478 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACAGCCCCCCTGTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGCGCAGGATTGATCTAGAGTGCGGGTGCTCCATCTACTTCCACATAGGCTGTACAGGACATGGATTCACGCACAGGGGAACTCATCACTGCACCTCATGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGAGTAGTGGACCTGCTATACACCAGAACAAGGGTGTACAATATCCAGATACGATTCAACCACAACCTGAGGAAAGTGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAG |
|
Protein Sequence
|
MRSSSPSQPPCIKKAHRQAKRRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSCREWRVYLGDRKSPLFQDIQSSGPAIHQNKGVQYPDTIQPQPEESVGSPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
YP_009506440.1
|
|
Location
|
1390-2475 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACGGAAAGGAGTATTTTCTATTAAAGCCAAAAACTATTTCATCACATACCCTCGTTGCTCTCTTGGCAAAGAGGAAGCCTTAGAACAACTTAGAAAAATCCATACACCAGTAAATAAGAAATTTATCAAAATTTCACGAGAGTTTCACGAAAATGGGGAGCCTCATCTCCATGTGCTCATGCAGCTCGAAGGCAAGTTCAACTGCACGAATAACAGACTCTTCGACATGGTGTCCCCAACCAGGTCAGCACCTTTCCATCCAAACATTCAGGGAGCTCGGTCGAGCTCCGATGTCAAGTCCTATGTCGCGAAAGACGGTGACACCATCGAATGGGGAGTGTTCGAGATCGACGGAAGAAGTGCTCGTGGCGGTCAGCAGACAGCTAATGATGCAGCCGCCGAGGCGTTAAATGCTGGAACAAAGGAGGAGGCCATGAAAATCATCAAAGAGAAGTTGCCGGAGAAGTTTCTTTTCCAGTATCATAACCTATCCAGTAACCTCGATAGGATTTTCATGAAGGCTCCGGAGCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCACTAACGTGCCGGACGAGATGCAAGAATGGTCGGACAGTTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGAGAGACCAGTAAGTCTCATTGTAGAAGGTGACTCGAGGACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACATAATTATCTCAGTGGCCACCTAGACTTTAATTCAAAAGTCTTCTCAAACGATGTGGAGTATAACATCATTGATGATGTCGCACCGCATTATCTAAAGTTAAAGCACTGGAAAGAGCTTCTGGGGGCCCAGAAAGACTGGCAATCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGCGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTAGACAAAGAGGAAAACATAGGTCTCAGGAACTGGACTCTCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTGTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGCGCAGGATTGA |
|
Protein Sequence
|
MPRKGVFSIKAKNYFITYPRCSLGKEEALEQLRKIHTPVNKKFIKISREFHENGEPHLHVLMQLEGKFNCTNNRLFDMVSPTRSAPFHPNIQGARSSSDVKSYVAKDGDTIEWGVFEIDGRSARGGQQTANDAAAEALNAGTKEEAMKIIKEKLPEKFLFQYHNLSSNLDRIFMKAPEPWSPPFPLSSFTNVPDEMQEWSDSYFGRGAAARPERPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNDVEYNIIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENIGLRNWTLKNAIFITLTAPLYQEGTQASQEEGHQEAQD |
|
NCBI Accession
|
YP_009506441.1
|
|
Location
|
2061-2318 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTCATGCAGCTCGAAGGCAAGTTCAACTGCACGAATAACAGACTCTTCGACATGGTGTCCCCAACCAGGTCAGCACCTTTCCATCCAAACATTCAGGGAGCTCGGTCGAGCTCCGATGTCAAGTCCTATGTCGCGAAAGACGGTGACACCATCGAATGGGGAGTGTTCGAGATCGACGGAAGAAGTGCTCGTGGCGGTCAGCAGACAGCTAATGATGCAGCCGCCGAGGCGTTAA |
|
Protein Sequence
|
MGSLISMCSCSSKASSTARITDSSTWCPQPGQHLSIQTFRELGRAPMSSPMSRKTVTPSNGECSRSTEEVLVAVSRQLMMQPPRR |