Macroptilium yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000848005.1 |
| Isolate |
Jamaica |
| Release date |
2015/2/12 |
| Submitter |
Amarakoon,I.I., Roye,M.E., Briddon,R.W., Bedford,I.D., Stanley,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
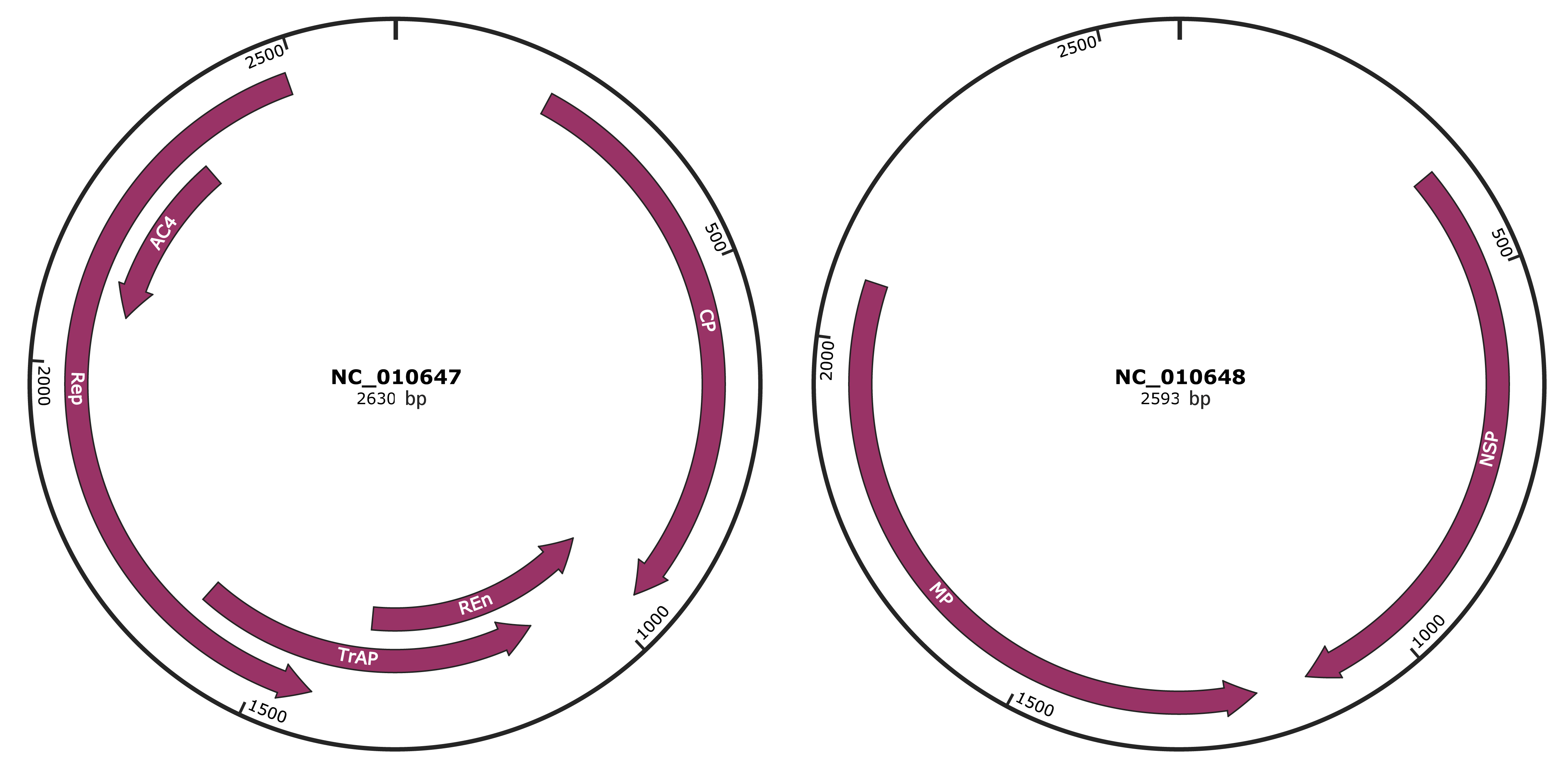
JBrowse
Genome
ACCGGATGGCCGCGCCCCCCCCCCTTCTTTTCCGTACGCCAACCACGTGCGCCTTTAATTTAAATTAAAGATAACTATTTTTGACTGACCAATCATATTGCTTGTGTGTGGTCTTTTTAATGCGTTACAACTTGGTCCCCAAGTTGTTCGCCTATAAGTTTAATTTAAATTAAGAATTGTTGTGCCCAAACCACGTGTAAGTCCAGGATGCCCAAGAGGGATGCCCCGTGGCGTTTGATGGCGGGAACCTCAAAGGTTTCCCGCACTGGCAATTATTCTCGAAATGGTGGTTTGGGCCAATCCTCCAACAAAAACGCTTGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGGATGTACAGATCATCCGCTGTGCCCAAGGGATGTGAAGGACCTTGCAAGGTCCAATCCTATGAACAACGACATGATATATCTCATGTTGGTAAGGTGATATGTATTTCTGACATTACTCGTGGTAATGGTATTACTCATCGTGTAGGGAAGCGTTTTTGTGTGAAATCTGTGTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACAAACAGCGTTATTTTTTGGTTGGTGCGTGATCGTCGTCCCTATGGAACACCTATGGACTTTGGACAGGTGTTCAACATGTTTGATAATGAGCCCAGTACAGCTACTGTGAAGAACGATCTTCGTGATCGTTTCCGAGTGATACACAGATTTCATGCTAAGGTGACTGGTGGCCAATATGCAAGTAATGAACAGGCATTGGTAAGGCGATTTTGGAAGGTGAACAACCATGTCGTGTACAACCACCAGGAATCCGGAAAATACGAGAATCATACGGAGAACGCCTTATTATTGTATATGGCATGTACACATGCCTCAAACCCTGTATATGCAACATTGAAAATTCGGATCTATTTCTATGATTCGATAACAAATTAATAAAATTTGAATTTTATTTCATGACTTTCGAGCACATAATTTACATATGATTTGTCCGTGGCAAAACGAACAGCTCTAATTACATTGTTTATTCCGACAAGCCCTATTTGATCAGGATACATATGAACAAGATATTTAAATCTATTTAAATATGTCGTCCCAGAAGCTGTCGTTAATGTCGTCCAGACTTGGAAGTTGAAGAAGGCTTTGTGGAGACCCAACACTTTCCGCACGTTGTGGTTGGCTCTGACTTGTATGTGGTAGATCCTTGTTCGAGTGAATGGTGGATCCTCCACCATGATGATCTTGAAATAGGGGGGATTTGGAACCTCCCAGATAAAAACGGAATTCTCTGCCTGACGCGCAGTGATGTTCTCCCCTGTGCGTGAATCCATGGTCGTGGCAATTGATATGGAGAAATATGGAACAGCCGCAGTTCAAGTCTAAGCGTCGTCGACGGATGGCCCTACGTTTGGCAAGGCGATGCTGTGCTTTGATAGAGGGGGGCTGTGAAGGTGATGAATAGCGCATTATGAATGGTCCAGTTGTGTAAAGCTCGGTTTTCTTCTTTACCGAGGAAGTCTTTATAACTGGCACCCTCACCAGGATTGCACAGCACGATTGAAGGGATACCTCCTTTAATTTGAACCGGCTTTCCATATTTACAGTTTGACTGCCAGTCCCTTTGAGCCCCAATTAACTCTTTCCAATGCTTTAATTTCAAATAATTGGGGCTTATGTCATCAATGACGTTGTACTCAGCGGCATTGGAATAGACACGCGAATTGAAGTCGAGGTGACCCATGAGATAATTGTGTGGTCCCAATGAACGAGCCCACATTGTTTTGCCTGTTCTTGAGTCACCCTCGACGATGATACTCATATATCTCTCCGGCCGCGCAGCGGCACCCCTTCCGAAATAACCATCGACCCACGCTTGCATCTCAGCCGGAACGTGAGTAAAGGAGGAGAGGTGAAATGGAGGAACCCATGGTTCCGGAACCTTGGTAAAGATCCGTTCTAGGTTAGAACGGATGTTATGATGTTGGAGAAGATAATCCTTGGGCTGCTCCTCCTTTAATATTTGAAGTGCCTGTTCGACTGATGAGGCATTCAATGCCTTGGCATATGAGTCGTTAGCACTCTGGCAGCCTCCTCTAGCACTTCGACCGTCGACCTGGAATTCTCCCCATTCGACTGTGACTCCATCCTTGTCGAGATAGGACTTGACGTCGGAGCTCGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCGGGATGGGGAGACCAGGTCGAATAATCTGTTATTCGTGCGGACGAATTTTCCTTCGAACTGGATAAGCACATGGAGATGAGGCTGCCCATCCTCGTGTAATTCCTCACATATCTTGATGAACTTCTTGTTGGTGGCAGTGAAAATATTTTGTAATTGGGAAAGAGCCTCTTCTTTTGAAAGAGAACACTGAGGATATGTGAGGAAATAGTTTTTTGCGCTCACTCTAAATCTCTTTGGTGGTGGCATATTTGTAAATAAGAGAGTGTCACCGCTTCGAGCTCTCTCAAACTTGCTCTATGAATTGGTGATAAGTGTACAATATATACTACAACCCTCAATCTCGTGAATAACGAGATTCACACACGTGGCGGCCATCCGATATAATATT
ACCGGATGGCCGCGCCCCCCCCGCCTTTCCCGTACGTTTATGCCCGCGCATACCCCTCTCCGTACTCTTCATCTAAGGGCTTTTTAGTCTTTTGGTTGTTGAAACGTGGCACGTTTTGAACCATTGGATAAGATTATAGTGTATGGCCTATTTGAATTTTGTACAATGCTTTTTATTCTTTTGATAAGTGTCGCTTTTGTATTGTTTGTGTTTCTGAGGCATTGTACGACATGTGGCACGTGTTCCACTCAAAATTCAATATAGGAGTCAAGGAAAACATTTGTCTGTTTAATGTTTTCTATAAATGCGTGAATTTGTTTAGGATCAAAACGTGCATTATTTTTAACAGCACCTTTGATCATGTCTTTTGTAAAATACAGGTATGGTGCATCATATACGACAAGACGTTTTTTACGTCAACAGGCTACTAAGAAAAGGAGTGCTGTTAAACGCAATGATTTTAAGCGTGGTTACAGACAAGTGAGCAAGTCTAATGAAGAGGCAAAGATGATTAGCCAATCATTGCATGAAAATCAGCTTGGTCCTGATTTTGTTATGACTCACAATAACGCTCTATCTACGTTCATTAATTTTCCATGTTTGGGTAAGACTTTACCCAACCGAAACAGGTCATATATTAAGTTGAAACGCTTGCGTTTCAAAGGTACGGTGAAGATAGAGCGTGTTCATGTGGATGTTAATATGGATGGTTTATCCCCTAAGATTGAAGGCGTATTTTCGCTTGTTATCGTCATCGACCGGAAACCACATCTTAACCCGAATGGCTGTCTACACTCATTTGATGAACTATTTGGAGCAAGGATACACAGCCATGGAAATCTTGCCATTACGTCGTCATTGAAAGATCGTTACTACATTCGTCATGTGTTCAAGAGTGTTATTTCTGTGATCAAAGACACTACAATGATCGACGTTGAGGGTTCCACTTTGTTGTCTAATAGGCGTTCGAACATGTGGTCGAGTTTTAAGGATCATGATCATGACTCTTGTAATGGTGTTTATGACAATATTAGCAAGAACGCCATATTAGTTTATTATTGTTGGATGTCCGACACCAACTCCAAGGCTTCCACTTTTGTATCGTTTGACCTTGACTATGTTGGATGAATAACAATGTACTGAACAAGAACATTTGAACAAGCAAATTTGAACAAGCAAAAGTGTTTTTATTTATTTATTTCAACGACTTTGGCTGAGAAGGGATACAATTACTGTTAATACATTCTTGAACTGTCGCCTTAACAATCTCGCTTAATTGGGTCATTGACATTGTTATGTTTGATTGGGCCCTCTGTGCTCCTACAATTGATGCTGAATCTCCCGGGTCTAGGACGCTTGTTCCGAGCCTGTTTAGTTGTCTGTATGGGTGTATTGCGTTTTCTAATTCAGAGTCCGCATCGGTATGAGACACTCCTATTGAACTTTTTGTGGCCCAAGACTCTCCTGGTTTTAATTCAATTGGGCCATGTAGTCCAAACTGGTTAGTCGATGCGGACCTGATCAATTTCCTTTCCCACCGCCCATAGTCCACATGAGAAAAATCGACATCTCTATTGGAAAACTGTTTTGAGAGGATCTTGACTGTTGGAGCCCTGAATGGGATATCAACTGAATGTTTGGCCGTTGATAATTTCAGTTTTCCCTTGAATTTGGCGAAATGTGTTCTCTGATGGACATTCGTATCGGAAACTCTGTAATAGAGTTTCCATGGTATTGGGTCTTTTAACGAGAAGAAAGACGATGAAAAATAGTGGAGATCGATGTTGCACCGGATGGGAAAAGTCCATGAAGCTTGTAAGGACTCGTTGTCCGTCATTCTCTTGTCATGAATCTCCACTATGACTGCTCCAGTGGCGTTGATAGGCACCTGTTGCCTATATTCTATGACGCAATGGTCGATTTTCATACAACTACGACTGAGTCTAGCTGTTAATTGTGAAGCGGTGGAAGGAAATTGAAGGACTATCTCAGTTAGATCATGAGACAGCTGATATTCATCCCTATGAGACTCAATATAATTAAAGGCACTCGGTGGACAAGCTAACTGAGAATCCATATATGAAAATATGGCCGCGCAGCGGAAGGGCTTACAGGAGATAAACCCAGAAGAAGGAAAGGAAAGTTTTATTTAAGAGGAAAAGAAAAAACTATGAATTGGAGATTGTGTGTTCAACTGTGACGAGGTTTATCTCTTATATAGACTATTTTTGGACGCTAATTTTCTCAAATGGTCCATCTTATTTGAACTTTTTTAAATAAAAAAGGCGATATACAAGAACAGGAGTCCAAAAATAACGCAATACATAAGAATTTATTTATTTGAAATAGAATTGATTGAATGCCTCATCAGTCGATCAAGTATTTAAATTTAAAGAGAGCACTGAGAAAATCTCTTTGGATATCACTCTGAACCTCTTTGGTGATGGCATATTTGTAAATAAAAGGTTGTACTCCGAATGAGCTCTCGCAAAACTCGCTCTGCAATTGGAGTATTGGAGTGCAATTTATACTAGAACCCTCAATCTCGCGAATAGCGAGATTCACACACGTGGCGGCCATCCGATATAATATT
Gene Information
|
NCBI Accession
|
YP_001876449.1
|
|
Location
|
208-960 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCCAAGAGGGATGCCCCGTGGCGTTTGATGGCGGGAACCTCAAAGGTTTCCCGCACTGGCAATTATTCTCGAAATGGTGGTTTGGGCCAATCCTCCAACAAAAACGCTTGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGGATGTACAGATCATCCGCTGTGCCCAAGGGATGTGAAGGACCTTGCAAGGTCCAATCCTATGAACAACGACATGATATATCTCATGTTGGTAAGGTGATATGTATTTCTGACATTACTCGTGGTAATGGTATTACTCATCGTGTAGGGAAGCGTTTTTGTGTGAAATCTGTGTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACAAACAGCGTTATTTTTTGGTTGGTGCGTGATCGTCGTCCCTATGGAACACCTATGGACTTTGGACAGGTGTTCAACATGTTTGATAATGAGCCCAGTACAGCTACTGTGAAGAACGATCTTCGTGATCGTTTCCGAGTGATACACAGATTTCATGCTAAGGTGACTGGTGGCCAATATGCAAGTAATGAACAGGCATTGGTAAGGCGATTTTGGAAGGTGAACAACCATGTCGTGTACAACCACCAGGAATCCGGAAAATACGAGAATCATACGGAGAACGCCTTATTATTGTATATGGCATGTACACATGCCTCAAACCCTGTATATGCAACATTGAAAATTCGGATCTATTTCTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRTGNYSRNGGLGQSSNKNAWVNRPMYRKPRIYRMYRSSAVPKGCEGPCKVQSYEQRHDISHVGKVICISDITRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFRVIHRFHAKVTGGQYASNEQALVRRFWKVNNHVVYNHQESGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_001876450.1
|
|
Location
|
957-1355 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGAACATCACTGCGCGTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCCCTATTTCAAGATCATCATGGTGGAGGATCCACCATTCACTCGAACAAGGATCTACCACATACAAGTCAGAGCCAACCACAACGTGCGGAAAGTGTTGGGTCTCCACAAAGCCTTCTTCAACTTCCAAGTCTGGACGACATTAACGACAGCTTCTGGGACGACATATTTAAATAGATTTAAATATCTTGTTCATATGTATCCTGATCAAATAGGGCTTGTCGGAATAAACAATGTAATTAGAGCTGTTCGTTTTGCCACGGACAAATCATATGTAAATTATGTGCTCGAAAGTCATGAAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGENITARQAENSVFIWEVPNPPYFKIIMVEDPPFTRTRIYHIQVRANHNVRKVLGLHKAFFNFQVWTTLTTASGTTYLNRFKYLVHMYPDQIGLVGINNVIRAVRFATDKSYVNYVLESHEIKFKFY |
|
NCBI Accession
|
YP_001876451.1
|
|
Location
|
1102-1620 |
|
Gene Name
|
TrAP |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGGAAAGCCGGTTCAAATTAAAGGAGGTATCCCTTCAATCGTGCTGTGCAATCCTGGTGAGGGTGCCAGTTATAAAGACTTCCTCGGTAAAGAAGAAAACCGAGCTTTACACAACTGGACCATTCATAATGCGCTATTCATCACCTTCACAGCCCCCCTCTATCAAAGCACAGCATCGCCTTGCCAAACGTAGGGCCATCCGTCGACGACGCTTAGACTTGAACTGCGGCTGTTCCATATTTCTCCATATCAATTGCCACGACCATGGATTCACGCACAGGGGAGAACATCACTGCGCGTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCCCTATTTCAAGATCATCATGGTGGAGGATCCACCATTCACTCGAACAAGGATCTACCACATACAAGTCAGAGCCAACCACAACGTGCGGAAAGTGTTGGGTCTCCACAAAGCCTTCTTCAACTTCCAAGTCTGGACGACATTAACGACAGCTTCTGGGACGACATATTTAAATAG |
|
Protein Sequence
|
MESRFKLKEVSLQSCCAILVRVPVIKTSSVKKKTELYTTGPFIMRYSSPSQPPSIKAQHRLAKRRAIRRRRLDLNCGCSIFLHINCHDHGFTHRGEHHCASGREFRFYLGGSKSPLFQDHHGGGSTIHSNKDLPHTSQSQPQRAESVGSPQSLLQLPSLDDINDSFWDDIFK |
|
NCBI Accession
|
YP_001876452.1
|
|
Location
|
1427-2488 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCACCAAAGAGATTTAGAGTGAGCGCAAAAAACTATTTCCTCACATATCCTCAGTGTTCTCTTTCAAAAGAAGAGGCTCTTTCCCAATTACAAAATATTTTCACTGCCACCAACAAGAAGTTCATCAAGATATGTGAGGAATTACACGAGGATGGGCAGCCTCATCTCCATGTGCTTATCCAGTTCGAAGGAAAATTCGTCCGCACGAATAACAGATTATTCGACCTGGTCTCCCCATCCCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATCTCGACAAGGATGGAGTCACAGTCGAATGGGGAGAATTCCAGGTCGACGGTCGAAGTGCTAGAGGAGGCTGCCAGAGTGCTAACGACTCATATGCCAAGGCATTGAATGCCTCATCAGTCGAACAGGCACTTCAAATATTAAAGGAGGAGCAGCCCAAGGATTATCTTCTCCAACATCATAACATCCGTTCTAACCTAGAACGGATCTTTACCAAGGTTCCGGAACCATGGGTTCCTCCATTTCACCTCTCCTCCTTTACTCACGTTCCGGCTGAGATGCAAGCGTGGGTCGATGGTTATTTCGGAAGGGGTGCCGCTGCGCGGCCGGAGAGATATATGAGTATCATCGTCGAGGGTGACTCAAGAACAGGCAAAACAATGTGGGCTCGTTCATTGGGACCACACAATTATCTCATGGGTCACCTCGACTTCAATTCGCGTGTCTATTCCAATGCCGCTGAGTACAACGTCATTGATGACATAAGCCCCAATTATTTGAAATTAAAGCATTGGAAAGAGTTAATTGGGGCTCAAAGGGACTGGCAGTCAAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGAGGTATCCCTTCAATCGTGCTGTGCAATCCTGGTGAGGGTGCCAGTTATAAAGACTTCCTCGGTAAAGAAGAAAACCGAGCTTTACACAACTGGACCATTCATAATGCGCTATTCATCACCTTCACAGCCCCCCTCTATCAAAGCACAGCATCGCCTTGCCAAACGTAG |
|
Protein Sequence
|
MPPPKRFRVSAKNYFLTYPQCSLSKEEALSQLQNIFTATNKKFIKICEELHEDGQPHLHVLIQFEGKFVRTNNRLFDLVSPSRSAHFHPNIQGAKSSSDVKSYLDKDGVTVEWGEFQVDGRSARGGCQSANDSYAKALNASSVEQALQILKEEQPKDYLLQHHNIRSNLERIFTKVPEPWVPPFHLSSFTHVPAEMQAWVDGYFGRGAAARPERYMSIIVEGDSRTGKTMWARSLGPHNYLMGHLDFNSRVYSNAAEYNVIDDISPNYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLGKEENRALHNWTIHNALFITFTAPLYQSTASPCQT |
|
NCBI Accession
|
YP_001876453.1
|
|
Location
|
2074-2331 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAGCCTCATCTCCATGTGCTTATCCAGTTCGAAGGAAAATTCGTCCGCACGAATAACAGATTATTCGACCTGGTCTCCCCATCCCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATCTCGACAAGGATGGAGTCACAGTCGAATGGGGAGAATTCCAGGTCGACGGTCGAAGTGCTAGAGGAGGCTGCCAGAGTGCTAACGACTCATATGCCAAGGCATTGA |
|
Protein Sequence
|
MGSLISMCLSSSKENSSARITDYSTWSPHPGQHISIRTFRELNRAPTSSPISTRMESQSNGENSRSTVEVLEEAARVLTTHMPRH |
|
NCBI Accession
|
YP_001876454.1
|
|
Location
|
361-1128 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTCTTTTGTAAAATACAGGTATGGTGCATCATATACGACAAGACGTTTTTTACGTCAACAGGCTACTAAGAAAAGGAGTGCTGTTAAACGCAATGATTTTAAGCGTGGTTACAGACAAGTGAGCAAGTCTAATGAAGAGGCAAAGATGATTAGCCAATCATTGCATGAAAATCAGCTTGGTCCTGATTTTGTTATGACTCACAATAACGCTCTATCTACGTTCATTAATTTTCCATGTTTGGGTAAGACTTTACCCAACCGAAACAGGTCATATATTAAGTTGAAACGCTTGCGTTTCAAAGGTACGGTGAAGATAGAGCGTGTTCATGTGGATGTTAATATGGATGGTTTATCCCCTAAGATTGAAGGCGTATTTTCGCTTGTTATCGTCATCGACCGGAAACCACATCTTAACCCGAATGGCTGTCTACACTCATTTGATGAACTATTTGGAGCAAGGATACACAGCCATGGAAATCTTGCCATTACGTCGTCATTGAAAGATCGTTACTACATTCGTCATGTGTTCAAGAGTGTTATTTCTGTGATCAAAGACACTACAATGATCGACGTTGAGGGTTCCACTTTGTTGTCTAATAGGCGTTCGAACATGTGGTCGAGTTTTAAGGATCATGATCATGACTCTTGTAATGGTGTTTATGACAATATTAGCAAGAACGCCATATTAGTTTATTATTGTTGGATGTCCGACACCAACTCCAAGGCTTCCACTTTTGTATCGTTTGACCTTGACTATGTTGGATGA |
|
Protein Sequence
|
MSFVKYRYGASYTTRRFLRQQATKKRSAVKRNDFKRGYRQVSKSNEEAKMISQSLHENQLGPDFVMTHNNALSTFINFPCLGKTLPNRNRSYIKLKRLRFKGTVKIERVHVDVNMDGLSPKIEGVFSLVIVIDRKPHLNPNGCLHSFDELFGARIHSHGNLAITSSLKDRYYIRHVFKSVISVIKDTTMIDVEGSTLLSNRRSNMWSSFKDHDHDSCNGVYDNISKNAILVYYCWMSDTNSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_001876455.1
|
|
Location
|
1196-2077 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGCTTGTCCACCGAGTGCCTTTAATTATATTGAGTCTCATAGGGATGAATATCAGCTGTCTCATGATCTAACTGAGATAGTCCTTCAATTTCCTTCCACCGCTTCACAATTAACAGCTAGACTCAGTCGTAGTTGTATGAAAATCGACCATTGCGTCATAGAATATAGGCAACAGGTGCCTATCAACGCCACTGGAGCAGTCATAGTGGAGATTCATGACAAGAGAATGACGGACAACGAGTCCTTACAAGCTTCATGGACTTTTCCCATCCGGTGCAACATCGATCTCCACTATTTTTCATCGTCTTTCTTCTCGTTAAAAGACCCAATACCATGGAAACTCTATTACAGAGTTTCCGATACGAATGTCCATCAGAGAACACATTTCGCCAAATTCAAGGGAAAACTGAAATTATCAACGGCCAAACATTCAGTTGATATCCCATTCAGGGCTCCAACAGTCAAGATCCTCTCAAAACAGTTTTCCAATAGAGATGTCGATTTTTCTCATGTGGACTATGGGCGGTGGGAAAGGAAATTGATCAGGTCCGCATCGACTAACCAGTTTGGACTACATGGCCCAATTGAATTAAAACCAGGAGAGTCTTGGGCCACAAAAAGTTCAATAGGAGTGTCTCATACCGATGCGGACTCTGAATTAGAAAACGCAATACACCCATACAGACAACTAAACAGGCTCGGAACAAGCGTCCTAGACCCGGGAGATTCAGCATCAATTGTAGGAGCACAGAGGGCCCAATCAAACATAACAATGTCAATGACCCAATTAAGCGAGATTGTTAAGGCGACAGTTCAAGAATGTATTAACAGTAATTGTATCCCTTCTCAGCCAAAGTCGTTGAAATAA |
|
Protein Sequence
|
MDSQLACPPSAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGAVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSNRDVDFSHVDYGRWERKLIRSASTNQFGLHGPIELKPGESWATKSSIGVSHTDADSELENAIHPYRQLNRLGTSVLDPGDSASIVGAQRAQSNITMSMTQLSEIVKATVQECINSNCIPSQPKSLK |