Macroptilium yellow mosaic Florida virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000844525.1 |
| Isolate |
USA: Florida |
| Release date |
2015/2/12 |
| Submitter |
Idris,A.M., Hiebert,E., Bird,J., Brown,J.K. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
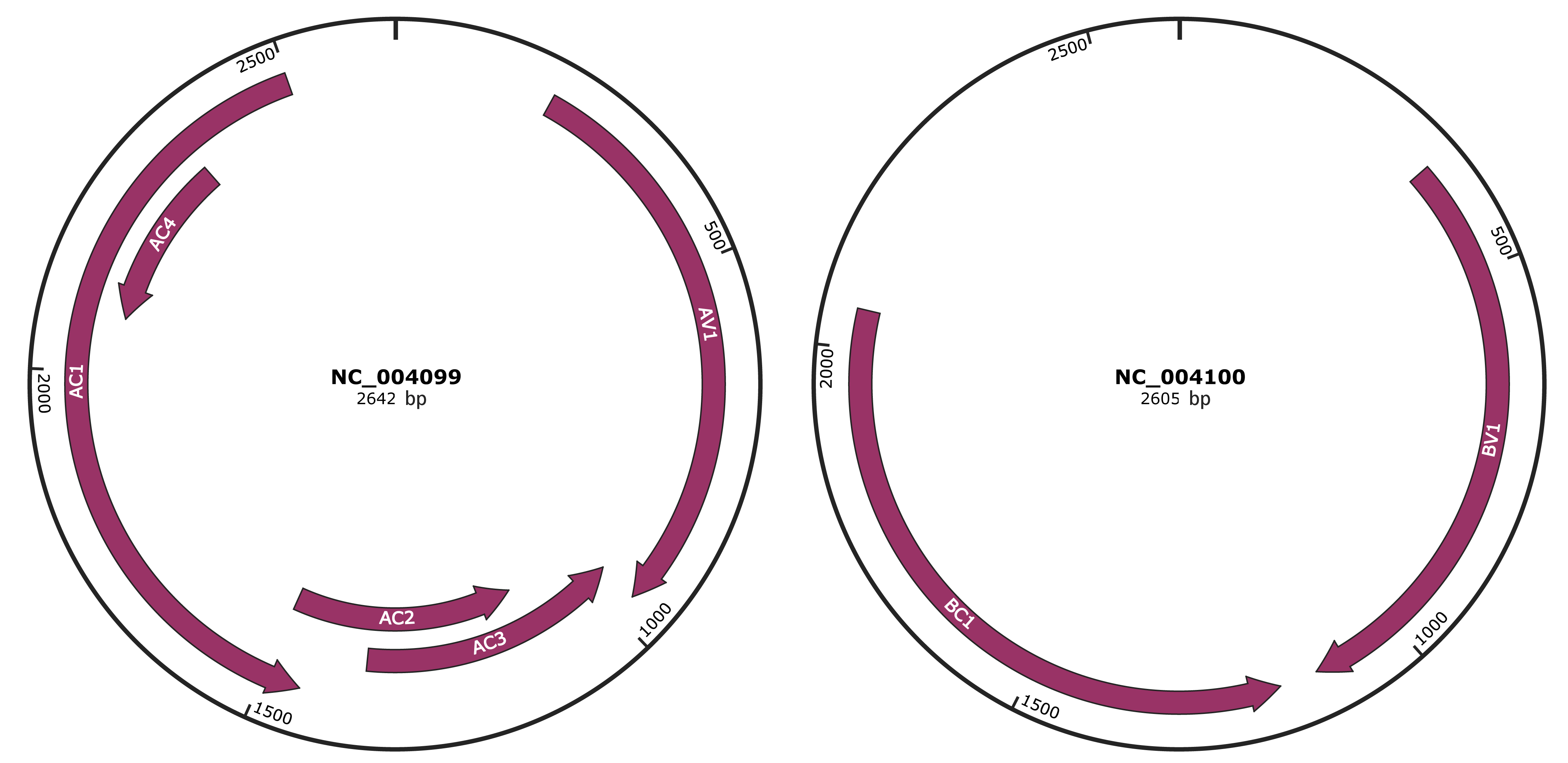
JBrowse
Genome
ACCGGATGGCCGCGCCCCGCCCCCCCACTTTCCGTACACACCCACGTGACGCTTTAATTTAAATTAAAGATAAGGATTTTTGACTGACCAATCAATTTGTTCGTGCATTGTCTATTTAATTTGTCGCAACTTGGTCACCAAGTTGCCAAATTTCCTATATAAGTTTAATTTAAATTCGAAACCCATGTGCCCAAACCACGTGTAAGTCCAGGATGCCTAAGAGGGATGCCCCATGGCGTTTGATGGCGGGAACCTCAAAGGTTTCCCGCACTGGCAATTATTCGTCTAATGGTGGTTTGGGCCAAAGATCCAACAAGGCCAACAACTGGGTCAACAGACCCATGTACAGGAAGCCCAGGATATATCGGATGTACAGATCATCCGACGTGCCGAAAGGATGTGAAGGGCCTTGTAAGGTGCAATCCTATGAACAGCGACATGATATCTCTCATGTCGGTAAGGTAATGTGTATATCTGATATTACACGTGGTAATGGTATTACTCATCGTGTAGGGAAGCGTTTTTGTGTGAAGTCTGTGTATATTTTAGGGAAGATATGGATGGATGAAAACATCAAGCTCAAGAACCACACAAATAGCGTTATTTTTTGGTTGGTGCGTGACCGTCGACCCATTGGAACACCCATGGACTTTGGACAGGTGTTCAACATGTTTGATGATGAGCCCAGTACAGCTACCGTGAAGAACGATCTTCGTGATCGTTATCAAGTCATGCACCGGTTCCATTCTAAGGTGACTGGTGGTCAATATGCGAGCAACGAGCAGGCATTGGTGAGGAGATTTTGGAGGGTCAACAATCATGTGGTGTACAACCACCAAGAAGCAGGGAAATACGAGAATCATACGGAGAACGCCTTGTTATTGTATATGGCATGTACTCATGCCTCAAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTCTATGATTCGATAACAAATTAATAAAATTTGAATTTTATTTCATGATTTTCGAGTACATAATTTACATATGATCTGTCTGTTGCAAAACGAACAGCGCGTATAATATTGTTTATTCCAACAAGCCCTACTTGGTCAAGATACATTAAAACAAGATATTTAAATCTATTTAAATATGTCGTTCCAGAAGCTGTCGTTGATGTCGTCCAGATTTGGAAGTTGAAGAAGGCTTTGTGGAGAGCCAACGCTTTCCTCACGTTGTGGTTGGCTCGGACTTGTATGTGGTAAATCCTTGTTCGAGTGAATGGTGGATCCTCCACCATGATTATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATAAAAACGGAATTCTCTGCCTGATGCGCAGTGATGTTCTCCCCTGTGCGTGAATCCATGGTCCCGGCAGTTGATGTGCATGAAGATGGAACACCCGCAGTTCAAGTCTATGCGTTTACGACGGATTGCTCTTTTCTTCGCAATCCTATGGAGTGCTTTGATAGAGGGGGGCTGTGAGGGTGACGAAGAGCGCATTCTTAATGGTCCAGTTGTGTAAAGCTCGGTTTTCTTCTTTGTCGAGGAACTCTTTATAACTGGAACCCTCACCTGGATTGCAAAGCACGATTGAGGGGATACCTCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCTTTTTGAGCCCCAATTAGCTCTTTCCAGTGCTTTAATTTCAAATAATTGGGGTTAATGTCATCAATGACGTTGTACTCCACCTCGTTGGAGTACACTTGAGAATTGAAATCGAGGTGACCACTCAGATAATTATGTGGGCCTAAGGCACGTGCCCACATGGTCTTGCCGGTTCTTGAATCACCCTCGACGATGATACTCATATATCTCTCCGACCGCGCAGCGGCACTCCTTCCAAAATATTGATCAGCCCAGTCTTGCATCTCAGCCGGAACGTTAGTAAAGGAAGAAAGTTGAAACGTAGGAACCCATGGTTCCGGAGGCTTTTGGAATATTTTGGAAGCGTTAACGACCAAGTTGTGATGTTGGAGGAAGAAATGTGCCGGTTGTTCTTCCCTTATGATCTTTAACGCCTCCTCGGCAGAGGAGGCATTTAAGGCCTTGGCATATGAGTCGTTAACCGTTTGGCAGCCTCCTCTAGCACTTCGACCGTCGACCTGGAATTCTCCCCATTCCAGTGTGTCCCCGTCCTTATCGATATAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGAACATTCGGATGGAAATATGCTGACTGGGAAGGGGACACCAGGTCGAAGAATCTGTAATTTGTGCATTGGTATTTGCCTTCGAACTGAATGAGTACATGGATATGAGGCTGTCCATTTTCGTGAAGTTCTCTTGCAATTTTGATATATTTTTTGGACGTTGGTGTGTTCAAGGCTTTAATTTGAGAAAGAGTCTCCTCTTTGGACAAGGAGCACTGCGGATAGGTGAGAAAGAAATTCTTAGCGTTTATCTTAAAACGCTTTGGACGCGATGGCATTTTGGAAAATATGAGAGTGTACCCCGAATGAGCTCTCTCAAACTTGCTCTATCAATTGGTGTAAAGGGGTACTATAAATACTAGAACCCTCAATAGAACCCTCAATCTCGTTCGCACACGTGGCGGCCATCCGAAATAATATT
ACCGGATGGCCGCGCCCCGCCCCCCCCTTTCCGTACTCTCGTCCCCCGCAATACCCTTACCCGTACCTCTTTTGTAGGGGTAATGTTGTCCTTCTATATATGAAACGTGTCAATTGTTTTATCGTTCGATAAAAGTTATCCTGACCGTTCCTTTGAAATTTGAATTTGTGGCGTTGCTTTTAATAATGTTTTGAGATAATGTGTTCTGACACATTACGCTAGATTTTACACTTGGTCGAGTCAAATTTCAATTTCGGAGTCAATGTAATTTTTTATGGCTCAATTTATTATTATAAATTGGTTGGAGAATAATTTGATAATGCACGTTTCATATTTTAACAGCACTAATGTATATGTCTAGATATGGTCAAGGGTCGTCTTATCACGTAAGACGAGGTTATTCACGTTATCAAACTTTAATATGTTCAGGTGCTGTTAAACGGAATGGTGTCAAACGTCGAGATTGTCATGTGTTCAAGGTGCATGATGAGACGAAGTTGATGGATCAACGCTTACGTGAAAATCAGTTTGGCCCTGATTTTGTTATGGCTCATAACCAGGCTATATCTACGTTTATTTCTTATCCTCATTTGGGTAAGAATTTACCAAATCGAAGCAGGTCTTATATTAAGTTGAAACGTTTACGTTTCAAGGGAACTGTGAAGATACAACGTGTTCAAGCTGATGTTAATATGGATGGTTTGGCTCCCAGGATTGAAGGCGTATTTTCCCTTGTTATTGTTTTGGATCGAAAACCTCATCTTGGTGCTTCTGGTACTCTCCATACATTTGATGAGCTATTTGGTGCAAGGATCCATAGCCATGGTCAATTGTCAATCATCCCAGCTTTGAAAGACCGATTTTACATCCGGCATGTGTTAAAGAAAATTATATCCGTGGAAAAGGATTCAACGATGATTGACATTGAGGGTTCCACTTTGTTAACTAATAGGCGTTATAAACTGTGGTCTAGTTTTAAGGATTTTGATCATGACTCGTGTAATGGTGTCTATGCTAACATTAGCAAGAACGCCTTATTAGTTTATTATTGTTGGATGTCGGACACTAGTTCAAAGGCATCTTCTTTTGTAACGTTTGATCTTGATTATGTTGGGTGATTAAGAATAAAATTATCGAGCAAATTTGAAAAGCAAAAGAAGATGTCATATTATTGCAAACTCTTGGGTTGAGAATGGTTACAATTACTATTAACACATTCTTGGACTGTTGTCCTAACAAGCTCGTTTAATTGGGCCATGGACATGGTTATGTTTGATTGGGCTCTCTGTGCCCCTAACAATTGAAGCCGAATCTCCGGGGTCCAATACGCTTGCTCCCAGCCCGATAGTTTTTTGTATGGGTGTAGTGCATTCTCCGCTTCTGAGTCCGCATCCGTTTGAGCCAATCCTATTGAACTTCTTGTTGCCCATGATTCTCCTGGTTGTAGTTCAAGTGGGCTGCGAAGCCCATATCTTGAAGTGGATGCGGACCTTATCAATTTCCTTTCCCATTTGCCATAATCCACATGAGAAAAATCGACATCTCTATTGGAAAATTGTTTGGACAGGATTTTAACTGTTGGAGCCCTGAATGGGATATCAACTGAATGTTTTGCAGTTGATAATTTCAATTTTCCCTTGAACTTCGCAAAATGGGTCCTCTGATGAACATTTGTATCGGAAACTCGATAATAGAGTTTCCATGGAATGGGGTCTTTGAGTGAGAAGAAGGACGATGAAAAATAGTGGAGATCGATGTTGCACCTGATGGGGAATGTCCATGACGCCTGTAATGATTCGTTGTCTGTCATTCTTTTGTCATGAATCTCAACTAATACTGAACCTGTTGCGTTTATAGGCACCTGCTGCCTATATCTAATTGACGCATGGTCGATTTTCATACAGCTACGACTGAGTCTGGAAGCTAATTGCGACACTGTGGAAGGAAATTGAAGGATTAACTCAGTTAGATCATGAGACAGCTGATATTCATCCCTATGAGACTCTATATAATTAAAGGCATTTGGAGGATTTGCTAACTGAGACTCCATATATCAAAGAAATGCCCGCGCGAGCTGCTTCAAGAGATAAAACCAAACAAGGAACACTTAGGGTTTTGACAGGGAGAAGAGATCAACTAAGATCAAAATCACCTGATTTTGAAAGAGGAAAAGAAAAAAACTAATAAAGAAAGAAGAAAAGAAAACTAATGAAGCCTCAAGATATTGTTTTCAAATGTATCCGTCAATTGTGTTTTATAGGCACACATGTTCTCAGGGACCGCTGTCAGAAAAGAATTAAAGAGGTTTTATCATTAAAGTCGCTTAAAATATAATAAACTCTGGTATATGGTATTTATAAGTTAAATAATTTATGAAGGAATTATTATTTGAATTTGAATATTGTTTACTAAGCAGAGTTTATTATTTGCACTACACAAAAGAGCTTCGGTATGGCATTCTGGAAAATATGAGAGTGTACCCCGAATTCGAGAGCTCTCTCAAACTTGCTCTATCAATTGGTGTAAAGGGGTACTATATATACTAGAACCCTCAATAGAACCCTCATTCTCGTTCGCACACGTGGCGGCCATCCGAAATAATATT
Gene Information
|
NCBI Accession
|
NP_671465.1
|
|
Location
|
213-968 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGAGGGATGCCCCATGGCGTTTGATGGCGGGAACCTCAAAGGTTTCCCGCACTGGCAATTATTCGTCTAATGGTGGTTTGGGCCAAAGATCCAACAAGGCCAACAACTGGGTCAACAGACCCATGTACAGGAAGCCCAGGATATATCGGATGTACAGATCATCCGACGTGCCGAAAGGATGTGAAGGGCCTTGTAAGGTGCAATCCTATGAACAGCGACATGATATCTCTCATGTCGGTAAGGTAATGTGTATATCTGATATTACACGTGGTAATGGTATTACTCATCGTGTAGGGAAGCGTTTTTGTGTGAAGTCTGTGTATATTTTAGGGAAGATATGGATGGATGAAAACATCAAGCTCAAGAACCACACAAATAGCGTTATTTTTTGGTTGGTGCGTGACCGTCGACCCATTGGAACACCCATGGACTTTGGACAGGTGTTCAACATGTTTGATGATGAGCCCAGTACAGCTACCGTGAAGAACGATCTTCGTGATCGTTATCAAGTCATGCACCGGTTCCATTCTAAGGTGACTGGTGGTCAATATGCGAGCAACGAGCAGGCATTGGTGAGGAGATTTTGGAGGGTCAACAATCATGTGGTGTACAACCACCAAGAAGCAGGGAAATACGAGAATCATACGGAGAACGCCTTGTTATTGTATATGGCATGTACTCATGCCTCAAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTCTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRTGNYSSNGGLGQRSNKANNWVNRPMYRKPRIYRMYRSSDVPKGCEGPCKVQSYEQRHDISHVGKVMCISDITRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPIGTPMDFGQVFNMFDDEPSTATVKNDLRDRYQVMHRFHSKVTGGQYASNEQALVRRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
NP_671466.1
|
|
Location
|
965-1363 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGAACATCACTGCGCATCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAATCATGGTGGAGGATCCACCATTCACTCGAACAAGGATTTACCACATACAAGTCCGAGCCAACCACAACGTGAGGAAAGCGTTGGCTCTCCACAAAGCCTTCTTCAACTTCCAAATCTGGACGACATCAACGACAGCTTCTGGAACGACATATTTAAATAGATTTAAATATCTTGTTTTAATGTATCTTGACCAAGTAGGGCTTGTTGGAATAAACAATATTATACGCGCTGTTCGTTTTGCAACAGACAGATCATATGTAAATTATGTACTCGAAAATCATGAAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGENITAHQAENSVFIWEVPNPLYFKIIMVEDPPFTRTRIYHIQVRANHNVRKALALHKAFFNFQIWTTSTTASGTTYLNRFKYLVLMYLDQVGLVGINNIIRAVRFATDRSYVNYVLENHEIKFKFY |
|
NCBI Accession
|
NP_671467.1
|
|
Location
|
1110-1499 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivation protein Trap |
|
Coding Region
|
ATGCGCTCTTCGTCACCCTCACAGCCCCCCTCTATCAAAGCACTCCATAGGATTGCGAAGAAAAGAGCAATCCGTCGTAAACGCATAGACTTGAACTGCGGGTGTTCCATCTTCATGCACATCAACTGCCGGGACCATGGATTCACGCACAGGGGAGAACATCACTGCGCATCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAATCATGGTGGAGGATCCACCATTCACTCGAACAAGGATTTACCACATACAAGTCCGAGCCAACCACAACGTGAGGAAAGCGTTGGCTCTCCACAAAGCCTTCTTCAACTTCCAAATCTGGACGACATCAACGACAGCTTCTGGAACGACATATTTAAATAG |
|
Protein Sequence
|
MRSSSPSQPPSIKALHRIAKKRAIRRKRIDLNCGCSIFMHINCRDHGFTHRGEHHCASGREFRFYLGGSKSPLFQDNHGGGSTIHSNKDLPHTSPSQPQREESVGSPQSLLQLPNLDDINDSFWNDIFK |
|
NCBI Accession
|
NP_671468.1
|
|
Location
|
1450-2499 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCGCGTCCAAAGCGTTTTAAGATAAACGCTAAGAATTTCTTTCTCACCTATCCGCAGTGCTCCTTGTCCAAAGAGGAGACTCTTTCTCAAATTAAAGCCTTGAACACACCAACGTCCAAAAAATATATCAAAATTGCAAGAGAACTTCACGAAAATGGACAGCCTCATATCCATGTACTCATTCAGTTCGAAGGCAAATACCAATGCACAAATTACAGATTCTTCGACCTGGTGTCCCCTTCCCAGTCAGCATATTTCCATCCGAATGTTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATATCGATAAGGACGGGGACACACTGGAATGGGGAGAATTCCAGGTCGACGGTCGAAGTGCTAGAGGAGGCTGCCAAACGGTTAACGACTCATATGCCAAGGCCTTAAATGCCTCCTCTGCCGAGGAGGCGTTAAAGATCATAAGGGAAGAACAACCGGCACATTTCTTCCTCCAACATCACAACTTGGTCGTTAACGCTTCCAAAATATTCCAAAAGCCTCCGGAACCATGGGTTCCTACGTTTCAACTTTCTTCCTTTACTAACGTTCCGGCTGAGATGCAAGACTGGGCTGATCAATATTTTGGAAGGAGTGCCGCTGCGCGGTCGGAGAGATATATGAGTATCATCGTCGAGGGTGATTCAAGAACCGGCAAGACCATGTGGGCACGTGCCTTAGGCCCACATAATTATCTGAGTGGTCACCTCGATTTCAATTCTCAAGTGTACTCCAACGAGGTGGAGTACAACGTCATTGATGACATTAACCCCAATTATTTGAAATTAAAGCACTGGAAAGAGCTAATTGGGGCTCAAAAAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGTATCCCCTCAATCGTGCTTTGCAATCCAGGTGAGGGTTCCAGTTATAAAGAGTTCCTCGACAAAGAAGAAAACCGAGCTTTACACAACTGGACCATTAAGAATGCGCTCTTCGTCACCCTCACAGCCCCCCTCTATCAAAGCACTCCATAG |
|
Protein Sequence
|
MPSRPKRFKINAKNFFLTYPQCSLSKEETLSQIKALNTPTSKKYIKIARELHENGQPHIHVLIQFEGKYQCTNYRFFDLVSPSQSAYFHPNVQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGCQTVNDSYAKALNASSAEEALKIIREEQPAHFFLQHHNLVVNASKIFQKPPEPWVPTFQLSSFTNVPAEMQDWADQYFGRSAAARSERYMSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSQVYSNEVEYNVIDDINPNYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKEFLDKEENRALHNWTIKNALFVTLTAPLYQSTP |
|
NCBI Accession
|
NP_671469.1
|
|
Location
|
2082-2339 |
|
Gene Name
|
AC4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGACAGCCTCATATCCATGTACTCATTCAGTTCGAAGGCAAATACCAATGCACAAATTACAGATTCTTCGACCTGGTGTCCCCTTCCCAGTCAGCATATTTCCATCCGAATGTTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATATCGATAAGGACGGGGACACACTGGAATGGGGAGAATTCCAGGTCGACGGTCGAAGTGCTAGAGGAGGCTGCCAAACGGTTAACGACTCATATGCCAAGGCCTTAA |
|
Protein Sequence
|
MDSLISMYSFSSKANTNAQITDSSTWCPLPSQHISIRMFRELNQAPTSSPISIRTGTHWNGENSRSTVEVLEEAAKRLTTHMPRP |
|
NCBI Accession
|
NP_671470.1
|
|
Location
|
354-1118 |
|
Gene Name
|
BV1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTCTAGATATGGTCAAGGGTCGTCTTATCACGTAAGACGAGGTTATTCACGTTATCAAACTTTAATATGTTCAGGTGCTGTTAAACGGAATGGTGTCAAACGTCGAGATTGTCATGTGTTCAAGGTGCATGATGAGACGAAGTTGATGGATCAACGCTTACGTGAAAATCAGTTTGGCCCTGATTTTGTTATGGCTCATAACCAGGCTATATCTACGTTTATTTCTTATCCTCATTTGGGTAAGAATTTACCAAATCGAAGCAGGTCTTATATTAAGTTGAAACGTTTACGTTTCAAGGGAACTGTGAAGATACAACGTGTTCAAGCTGATGTTAATATGGATGGTTTGGCTCCCAGGATTGAAGGCGTATTTTCCCTTGTTATTGTTTTGGATCGAAAACCTCATCTTGGTGCTTCTGGTACTCTCCATACATTTGATGAGCTATTTGGTGCAAGGATCCATAGCCATGGTCAATTGTCAATCATCCCAGCTTTGAAAGACCGATTTTACATCCGGCATGTGTTAAAGAAAATTATATCCGTGGAAAAGGATTCAACGATGATTGACATTGAGGGTTCCACTTTGTTAACTAATAGGCGTTATAAACTGTGGTCTAGTTTTAAGGATTTTGATCATGACTCGTGTAATGGTGTCTATGCTAACATTAGCAAGAACGCCTTATTAGTTTATTATTGTTGGATGTCGGACACTAGTTCAAAGGCATCTTCTTTTGTAACGTTTGATCTTGATTATGTTGGGTGA |
|
Protein Sequence
|
MSRYGQGSSYHVRRGYSRYQTLICSGAVKRNGVKRRDCHVFKVHDETKLMDQRLRENQFGPDFVMAHNQAISTFISYPHLGKNLPNRSRSYIKLKRLRFKGTVKIQRVQADVNMDGLAPRIEGVFSLVIVLDRKPHLGASGTLHTFDELFGARIHSHGQLSIIPALKDRFYIRHVLKKIISVEKDSTMIDIEGSTLLTNRRYKLWSSFKDFDHDSCNGVYANISKNALLVYYCWMSDTSSKASSFVTFDLDYVG |
|
NCBI Accession
|
NP_671471.1
|
|
Location
|
1169-2050 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGTCTCAGTTAGCAAATCCTCCAAATGCCTTTAATTATATAGAGTCTCATAGGGATGAATATCAGCTGTCTCATGATCTAACTGAGTTAATCCTTCAATTTCCTTCCACAGTGTCGCAATTAGCTTCCAGACTCAGTCGTAGCTGTATGAAAATCGACCATGCGTCAATTAGATATAGGCAGCAGGTGCCTATAAACGCAACAGGTTCAGTATTAGTTGAGATTCATGACAAAAGAATGACAGACAACGAATCATTACAGGCGTCATGGACATTCCCCATCAGGTGCAACATCGATCTCCACTATTTTTCATCGTCCTTCTTCTCACTCAAAGACCCCATTCCATGGAAACTCTATTATCGAGTTTCCGATACAAATGTTCATCAGAGGACCCATTTTGCGAAGTTCAAGGGAAAATTGAAATTATCAACTGCAAAACATTCAGTTGATATCCCATTCAGGGCTCCAACAGTTAAAATCCTGTCCAAACAATTTTCCAATAGAGATGTCGATTTTTCTCATGTGGATTATGGCAAATGGGAAAGGAAATTGATAAGGTCCGCATCCACTTCAAGATATGGGCTTCGCAGCCCACTTGAACTACAACCAGGAGAATCATGGGCAACAAGAAGTTCAATAGGATTGGCTCAAACGGATGCGGACTCAGAAGCGGAGAATGCACTACACCCATACAAAAAACTATCGGGCTGGGAGCAAGCGTATTGGACCCCGGAGATTCGGCTTCAATTGTTAGGGGCACAGAGAGCCCAATCAAACATAACCATGTCCATGGCCCAATTAAACGAGCTTGTTAGGACAACAGTCCAAGAATGTGTTAATAGTAATTGTAACCATTCTCAACCCAAGAGTTTGCAATAA |
|
Protein Sequence
|
MESQLANPPNAFNYIESHRDEYQLSHDLTELILQFPSTVSQLASRLSRSCMKIDHASIRYRQQVPINATGSVLVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSNRDVDFSHVDYGKWERKLIRSASTSRYGLRSPLELQPGESWATRSSIGLAQTDADSEAENALHPYKKLSGWEQAYWTPEIRLQLLGAQRAQSNITMSMAQLNELVRTTVQECVNSNCNHSQPKSLQ |