Ageratum yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000845825.1 |
| Isolate |
China:Hainan province |
| Release date |
2015/2/12 |
| Submitter |
Xiong,Q., Fan,S., Wu,J., Zhou,X. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
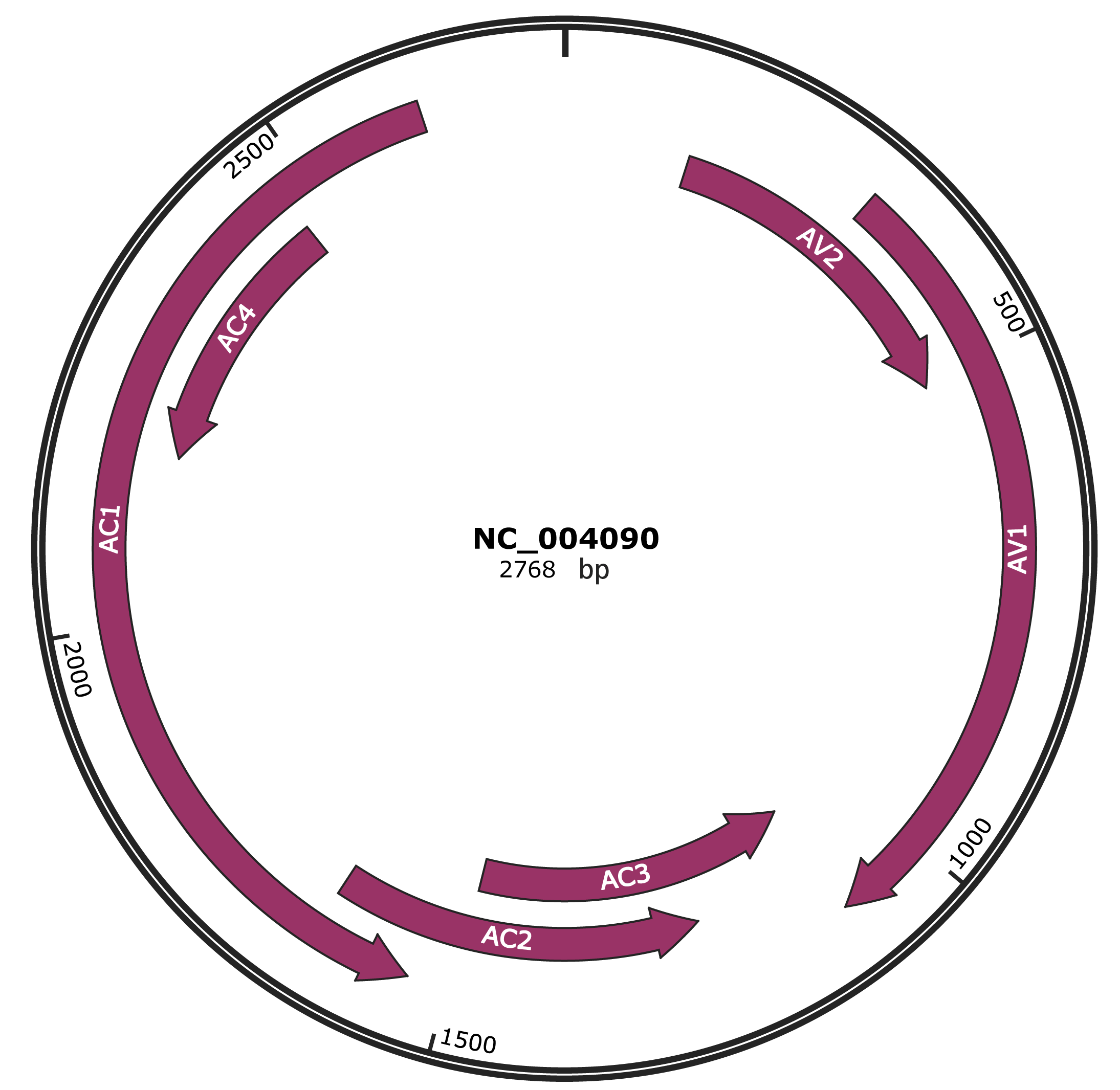
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTTTTAAAGTGGTCCCCACCACTAACAAAAATCCCCCACTTAGAACGCTCCCTCAAAGCCTATTTAATTCAAATCGACTATAAATACTTGGTCCCTACGTTTTTAAATTAAAGCAATGTGGGATCCTCTTTTGAACGAGTTTCCCCCGAAACCTGTAACCACCCGGGGTCCTTTAAGGGTGTTAATGCCTTTTGCCCGTAAAATATTGTCAGTTAATTCCGAACAGACATACTCTCCAGATACGGTTGGTTACGATCTTATACGAGATTTAATTTCCGTAATTCGTGCTCGCAATTATGTCGAAGCGACCCGCCGATATAGTCATTTCCACTCCCGCCTCGAAGGTACGACGCCGTCTGAACTTCGACACCCCCGTGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGAAGGACGTGGATCAACAGGCCCGTGTATCGCAAGCCCAGAGTCTTCAGAATGTACAGAAGCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTCCAATCGTATGAACAGAAGCACGACATATCCCATGTGGGTAAAGTATTATGTGTTAGTGATGTCACTCGTGGTAGTGGTCTTACCCATCGTGTTGGTAAGAGATTCTGTGTGAAGTCCGTTTATGTATTGGGTAAAATATGGATGGATGAAAATATCAAAACGAAGAACCATACGAACACTGTGATGTTTTATCTTGTTCGTGACAGAAGGCCCTTTGGTACTGCCATGGATTTTGGTCAGGTGTTTAACATGTATGATAATGAGCCCAGTACTGCTACTGTCAAGAATGATCTTCGAGATCGTTATCAAGTTTTAAGGAAATTCACTTCAACAGTCACAGGTGGTCAATATGCTTCTAAGGAACAGGCGTTAGTTAGGAAATTTATGAAGATTAATAATTATGTAGTTTATAATCATCAAGAAGCTGCTAAGTATGAAAATCATACTGAAAATGCCTTGTTATTGTATATGGCTTGTACTCATGCCAGTAATCCAGTGTATACTACTTTGAAGATCAGAATCTATTTCTATGATTCTGTTCAGAATTAATAAAGATTGAATTTTATTATATTTGAATGTGTTACATATTCTGTGTTTTCCAATACATCCCATAATACATGATTACATGCTCTAATTACATTGTTAATACTAATTACACCCAAATTATCTAAATATTTCATACATTGAACCCTAAATACTCTTAAGAAACGCCAAGTCTGAGGTTGTAAGCGAGTCCAGATCTGGAAGATTAGAAAACACTGGTGTATTCCCAATGCTTTCCTCAGGTTGTGGTTGAATTGTATTTGGATCGTTATGATGTCGTGGTTGGTGTTGAATGGTCTCTCGTGGTGCTTGGTTATCTTGAAATATAGGGGATTTTTGATCGTCCAGGTATACACGCCACTCTCGCATTGAGTTGCAGTGAGTAATTCCCCTGTGCGAAAATCCATGATTTGCACAATCTATGCCGAAGTAGTATGAGCACCCGCACGTTAGATCAACTCTCCGTCTCCGAATAGGCTTCCTCTTGGCTATTCTGTGTTGCACTTTGATTGGTACCTGAGTACAATGGGCTGTTGAGGGTGATGAATTCTGCATTCTTTAATGCCCAATCTTTTAAAGCTGAATTTTTATCCTCATTCAAGTACTCTTTATATGATGATGTTGGTCCTGGATTGCAAAGGAAGATAGTTGGGATTCCACCTTTAATTTGAACTGGCTTCCCGTACTTAGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATAAATTCTTTAAAGTGCTTTAGATAGTGCGGGTCTACGTCATCAATGACGTTATACCAAGCATCATTACTGTATACTTTAGGGCTTAGATCAAGATGTCCACACAAATAATTGTGTGGTCCCAATGATCTGGCCCACATTGTTTTACCTGTACGACTATCACCTTCTATCACAATACTTTTGGGTCCCCAAGGCCGCGCAGCGGCACCACTCACATTCTCAGAAACCCACTCTTCAAGTTCTTCTGGAACTTGATCGAATGAAGAAGAAAGAAATGGACAAACAAAAACCTCTAAAGGAGGTGCAAAAATCCTATCTAAATTACTATTTAAATTATGAAACTGTAAAACAAAATCTTTAGGAGCCTTTTCCTTTAATATATTGAGGGCCTCTGCTTTGGACCCTGAATTGATTGCCTCGGCATATGCGTCGTTGGCAGTTTGGCAACCTCCTCTAGCTGATCTTCCATCGATTTGGAAAACTCCATGATCAAGCACGTCTCCGTCTTTTTCCATGTATGCTTTAACATCTGTTGAGCTTTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTACTTGGGGAGGTGAGATCGAAGAATCTTTGATTCTTGCATTGGAATTTTCCTTCGAACTGGATGAGAACATGCAGGTGTGGAGTCCCATCTTCATGTAGCTCTCTGCAGATTCTGATGAATAGTTTATTTGTAGGTGTTTCTAGGGCTTTTAATTGGGAAAGTGCTTCCTCTTTTGTGAGTGAGCAGTGAGGGTATGTTAGGAAATAATTTTTTGCATTTATTCTGAATTTTGTAGGTGGAGGCATGTTGACTTGGTCAATTGGTGTCTCTCAAACTTGGATATGTAATTGGTGTCTGGGGTCTTATTTATATGTAGACACCAAATGGCATTATTGTAATTTCTTAAAGAAATTCAAATTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
NP_671442.1
|
|
Location
|
137-508 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCTCTTTTGAACGAGTTTCCCCCGAAACCTGTAACCACCCGGGGTCCTTTAAGGGTGTTAATGCCTTTTGCCCGTAAAATATTGTCAGTTAATTCCGAACAGACATACTCTCCAGATACGGTTGGTTACGATCTTATACGAGATTTAATTTCCGTAATTCGTGCTCGCAATTATGTCGAAGCGACCCGCCGATATAGTCATTTCCACTCCCGCCTCGAAGGTACGACGCCGTCTGAACTTCGACACCCCCGTGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGAAGGACGTGGATCAACAGGCCCGTGTATCGCAAGCCCAGAGTCTTCAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPPKPVTTRGPLRVLMPFARKILSVNSEQTYSPDTVGYDLIRDLISVIRARNYVEATRRYSHFHSRLEGTTPSELRHPRDEPCCCPHCPRHQQKKDVDQQARVSQAQSLQNVQKP |
|
NCBI Accession
|
NP_671443.1
|
|
Location
|
318-1091 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGCCGATATAGTCATTTCCACTCCCGCCTCGAAGGTACGACGCCGTCTGAACTTCGACACCCCCGTGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGAAGGACGTGGATCAACAGGCCCGTGTATCGCAAGCCCAGAGTCTTCAGAATGTACAGAAGCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTCCAATCGTATGAACAGAAGCACGACATATCCCATGTGGGTAAAGTATTATGTGTTAGTGATGTCACTCGTGGTAGTGGTCTTACCCATCGTGTTGGTAAGAGATTCTGTGTGAAGTCCGTTTATGTATTGGGTAAAATATGGATGGATGAAAATATCAAAACGAAGAACCATACGAACACTGTGATGTTTTATCTTGTTCGTGACAGAAGGCCCTTTGGTACTGCCATGGATTTTGGTCAGGTGTTTAACATGTATGATAATGAGCCCAGTACTGCTACTGTCAAGAATGATCTTCGAGATCGTTATCAAGTTTTAAGGAAATTCACTTCAACAGTCACAGGTGGTCAATATGCTTCTAAGGAACAGGCGTTAGTTAGGAAATTTATGAAGATTAATAATTATGTAGTTTATAATCATCAAGAAGCTGCTAAGTATGAAAATCATACTGAAAATGCCTTGTTATTGTATATGGCTTGTACTCATGCCAGTAATCCAGTGTATACTACTTTGAAGATCAGAATCTATTTCTATGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDTPVMSRAAAPTVLVTNKRRTWINRPVYRKPRVFRMYRSPDVPKGCEGPCKVQSYEQKHDISHVGKVLCVSDVTRGSGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNTVMFYLVRDRRPFGTAMDFGQVFNMYDNEPSTATVKNDLRDRYQVLRKFTSTVTGGQYASKEQALVRKFMKINNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYTTLKIRIYFYDSVQN |
|
NCBI Accession
|
NP_671444.1
|
|
Location
|
1088-1492 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTTCGCACAGGGGAATTACTCACTGCAACTCAATGCGAGAGTGGCGTGTATACCTGGACGATCAAAAATCCCCTATATTTCAAGATAACCAAGCACCACGAGAGACCATTCAACACCAACCACGACATCATAACGATCCAAATACAATTCAACCACAACCTGAGGAAAGCATTGGGAATACACCAGTGTTTTCTAATCTTCCAGATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAGGGTTCAATGTATGAAATATTTAGATAATTTGGGTGTAATTAGTATTAACAATGTAATTAGAGCATGTAATCATGTATTATGGGATGTATTGGAAAACACAGAATATGTAACACATTCAAATATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDFRTGELLTATQCESGVYTWTIKNPLYFKITKHHERPFNTNHDIITIQIQFNHNLRKALGIHQCFLIFQIWTRLQPQTWRFLRVFRVQCMKYLDNLGVISINNVIRACNHVLWDVLENTEYVTHSNIIKFNLY |
|
NCBI Accession
|
NP_671445.1
|
|
Location
|
1233-1640 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAGAATTCATCACCCTCAACAGCCCATTGTACTCAGGTACCAATCAAAGTGCAACACAGAATAGCCAAGAGGAAGCCTATTCGGAGACGGAGAGTTGATCTAACGTGCGGGTGCTCATACTACTTCGGCATAGATTGTGCAAATCATGGATTTTCGCACAGGGGAATTACTCACTGCAACTCAATGCGAGAGTGGCGTGTATACCTGGACGATCAAAAATCCCCTATATTTCAAGATAACCAAGCACCACGAGAGACCATTCAACACCAACCACGACATCATAACGATCCAAATACAATTCAACCACAACCTGAGGAAAGCATTGGGAATACACCAGTGTTTTCTAATCTTCCAGATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MQNSSPSTAHCTQVPIKVQHRIAKRKPIRRRRVDLTCGCSYYFGIDCANHGFSHRGITHCNSMREWRVYLDDQKSPIFQDNQAPRETIQHQPRHHNDPNTIQPQPEESIGNTPVFSNLPDLDSLTTSDLAFLKSI |
|
NCBI Accession
|
NP_671446.1
|
|
Location
|
1540-2628 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGCCTCCACCTACAAAATTCAGAATAAATGCAAAAAATTATTTCCTAACATACCCTCACTGCTCACTCACAAAAGAGGAAGCACTTTCCCAATTAAAAGCCCTAGAAACACCTACAAATAAACTATTCATCAGAATCTGCAGAGAGCTACATGAAGATGGGACTCCACACCTGCATGTTCTCATCCAGTTCGAAGGAAAATTCCAATGCAAGAATCAAAGATTCTTCGATCTCACCTCCCCAAGTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAACAGATGTTAAAGCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAGTTTTCCAAATCGATGGAAGATCAGCTAGAGGAGGTTGCCAAACTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAAGCAGAGGCCCTCAATATATTAAAGGAAAAGGCTCCTAAAGATTTTGTTTTACAGTTTCATAATTTAAATAGTAATTTAGATAGGATTTTTGCACCTCCTTTAGAGGTTTTTGTTTGTCCATTTCTTTCTTCTTCATTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGTTTCTGAGAATGTGAGTGGTGCCGCTGCGCGGCCTTGGGGACCCAAAAGTATTGTGATAGAAGGTGATAGTCGTACAGGTAAAACAATGTGGGCCAGATCATTGGGACCACACAATTATTTGTGTGGACATCTTGATCTAAGCCCTAAAGTATACAGTAATGATGCTTGGTATAACGTCATTGATGACGTAGACCCGCACTATCTAAAGCACTTTAAAGAATTTATGGGGGCCCAAAGGGACTGGCAAAGCAACACTAAGTACGGGAAGCCAGTTCAAATTAAAGGTGGAATCCCAACTATCTTCCTTTGCAATCCAGGACCAACATCATCATATAAAGAGTACTTGAATGAGGATAAAAATTCAGCTTTAAAAGATTGGGCATTAAAGAATGCAGAATTCATCACCCTCAACAGCCCATTGTACTCAGGTACCAATCAAAGTGCAACACAGAATAGCCAAGAGGAAGCCTATTCGGAGACGGAGAGTTGA |
|
Protein Sequence
|
MPPPTKFRINAKNYFLTYPHCSLTKEEALSQLKALETPTNKLFIRICRELHEDGTPHLHVLIQFEGKFQCKNQRFFDLTSPSRSAHFHPNIQGAKSSTDVKAYMEKDGDVLDHGVFQIDGRSARGGCQTANDAYAEAINSGSKAEALNILKEKAPKDFVLQFHNLNSNLDRIFAPPLEVFVCPFLSSSFDQVPEELEEWVSENVSGAAARPWGPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPTSSYKEYLNEDKNSALKDWALKNAEFITLNSPLYSGTNQSATQNSQEEAYSETES |
|
NCBI Accession
|
NP_671447.1
|
|
Location
|
2178-2471 |
|
Gene Name
|
AC4 |
|
Protein Name
|
transcriptional regulator protein |
|
Coding Region
|
ATGGGACTCCACACCTGCATGTTCTCATCCAGTTCGAAGGAAAATTCCAATGCAAGAATCAAAGATTCTTCGATCTCACCTCCCCAAGTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAACAGATGTTAAAGCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAGTTTTCCAAATCGATGGAAGATCAGCTAGAGGAGGTTGCCAAACTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAAGCAGAGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGLHTCMFSSSSKENSNARIKDSSISPPQVGQHISIRTFRELKAQQMLKHTWKKTETCLIMEFSKSMEDQLEEVAKLPTTHMPRQSIQGPKQRPSIY |