Macroptilium bright mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001777185.1 |
| Isolate |
Brazil |
| Release date |
2016/10/19 |
| Submitter |
Passos,L.S., Teixeira,J.W.M., Lima,K.J., Rodrigues,J.S., Soares,E.C.S., Xavier,C.A.D., Araujo,A.S.F., Zerbini,F.M., Beserra,J.E.A. Jr. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
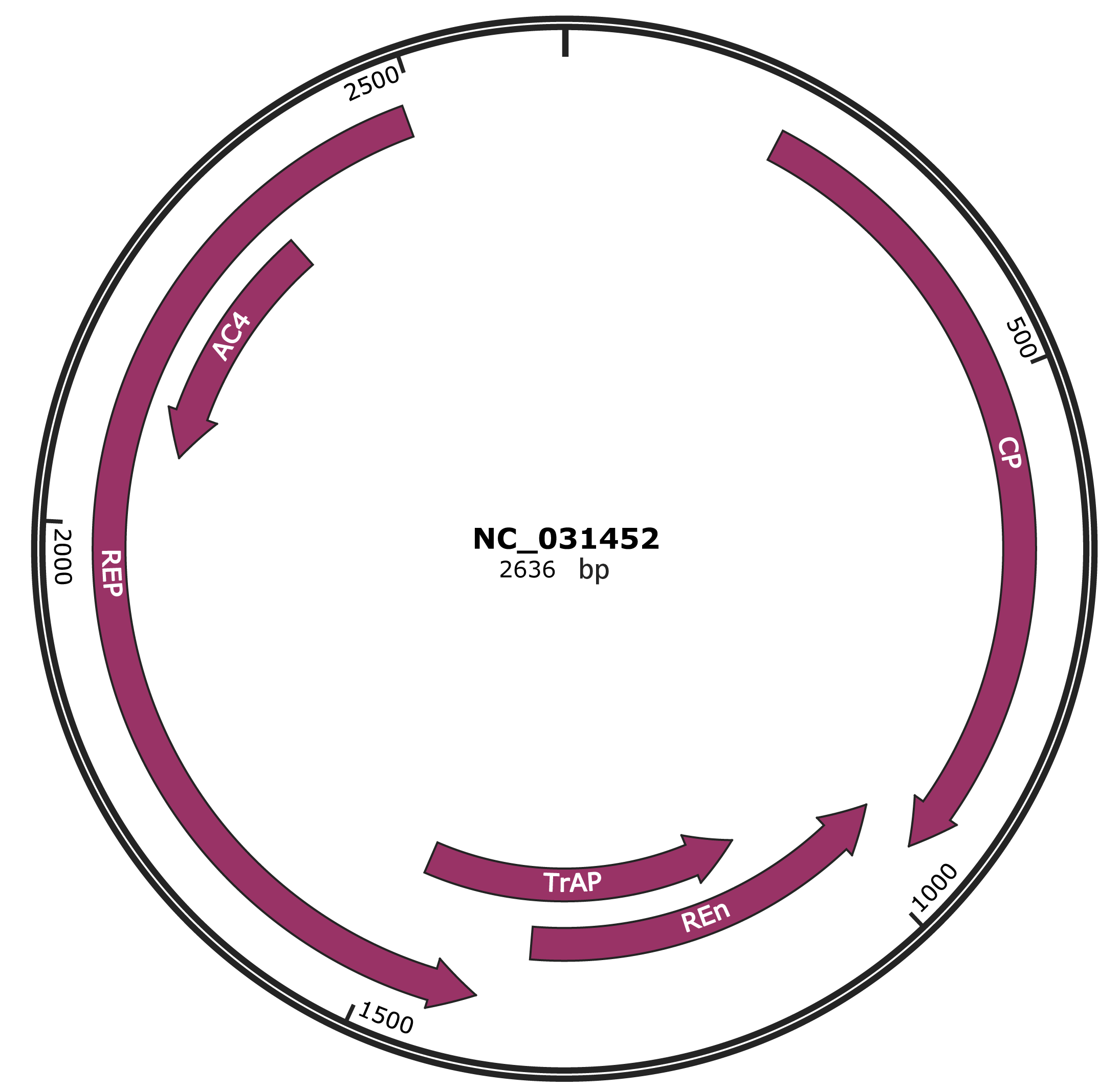
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTATGGGCCTTTTCTTTTGGGCTCGTTCTTTTGGGCCGACTTTAACTTGAATTAAAGGAATGTTTTTGTGCTGACCAATGAATTTCTGTCTGACGAGTTTAGATATGGAACAACTTGGGCCCCAAGTTGTGAGTAACGGCTATATATTTTAAGAAAAACATGCGTTATCCTTTAATTCAACATGCCCAAGCGTGACGTGCCATGGCGCCACATGGCAGGAACGTCAAAGATTTCCCGCTCGAGCAATTTCTCTCCTCGTGGTGGTGGAGGCCCAAAAACCACACGGGCCGCTGAATGGGTTAATAGGCCTATGTACAGAAAGCCCAGGATATATCGGATGTACAGAACCCCCGATGTTCCTAGGGGATGTGAAGGCCCGTGTAAGGTCCAGTCCTTTGAACAGAGGCATGATATTTCCCACACTGGGAAGGTTATATGTATTTCTGACGTGACACGTGGTAATGGTATTACTCACCGTGTTGGAAAGCGTTTTTGTGTTAAGTCTGTTTATGTTTTAGGTAAGATATGGATGGATGAGAACATCAAGCTCAAGAATCACACTAACAGTGTGATGTTTTGGTTGGTTAGAGACCGTCGTCCCTATGGTTCTCCTATGGACTTTGGCCAAGTGTTCAATTTATTTGATAATGAGCCAAGCACTGCTACGATCAAGAACGATCTACGTGATCGTTTCCAAGTCATGCACCGGTTCTATGCCAAAGTCACAGGTGGACAGTACGCGAGCAACGAGCAGGCATTGGTCAGGCGTTTTTGGAAGGTCAACAATCATGTGGTGTACAACCACCAAGAAGCCGCGAAGTACGAGAATCATACGGAGAACGCGTTACTCTTGTACATGGCATGCACTCATGCCTCAAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTCTATGATTCGATATCCAATTAATAAAATTTGAATTTTATTTCATGATTCTCAAGCACATAATTTACATATGGTTTGTCTGTTGCAAAACGAACAGCTCTAATTACATTGTTAAGCGAAACTACGCCCAAACTATCTAAATACAACAAGACTAACTGCCTAAACCTAACTAAATATGTCGTCCCAGAAGCTCGAACTGATGTCGTCCAGACTTGGAAGTTCAGGAAGGCCTTGTGTAGACCCAGTCTGTTCCTGAGGTTGTGGTTGAACCGTATCTGGACGTGGTATATTCTGGTCCTCGTGTATATTGGGTCCTCTACGTTGTACATCTTGAAATAGAGGGGATTTGATATCTCCCAGATATATACGCCACTCTCTGCCTGACGTGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGTCCTGCGCAGTTAAGGTGTACGTATATGGAGCACCCGCACTCTAGATCAATTCGTCGTCTCCTGACCGCTCTCTTCTTGGCCGCCCTGTGTTGGACTTTGATAGAGGGGGGAGTTGAGGACGACGAATTTCGCATTGTGAAGGGTCCAACTCTTTAATGCTGCGTTCTCTTCTTTGTCTAGGAAATCTTTATAGCTGGCCCCTTCACCAGGATTGCAAAGCACGATTGATGGGATGGATCCCGCCTTTAATTTGAACCGGCTTTCCGTATTTGCAGTTCGATTGCCAGTCCTTTTGAGCCCAATCAATTCTTTCCAGTGCTTTAGCTTTAGATAGAGCGGTGCGATGTCATCTATCACGTTGTATTGGGCCAAATTCGAATAGACCCTCGAATTGAAATCGAGGTGACCACTCAGGTAATTGTGGACCCCCAAGGCACGTGCCCACATGGTCTTCCCTGACCTTGAACCACCCTCTATGATGATGCTGAGTGGTCTCTCCGGCCGCGCAGCGGCACCTCTCCCAAAATAGTCGTCCGCCCAGTCTTGCATCTCCTTGGGCACGTTAGTGAATGAGGAGAGGTGAAACGGAGGAGTCCACGGCTCCGGAGCCTTTGCAAAGATACGCTCTAGGTTAGAGCGTATGTTATGGTGTTGAAGGACGAAGTCCTTCGGTTGTTCCTCCTTCAATATTTGGAGAGCCTGTTCAATGTTCTGAGCATTCAGAACCTTGGCGTATGACTCGTTCGCAGTCTGTTGGCCACCTCTTGCAGAACGAGCGTCGACCTGGAATTCTCCCCATTCAATGGTGTCTCCGTCCTTGTCGACATAGGACTTGACGTCGGAGCTCGACTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTATTTGGGGAGACAAGGTCGAAGAATCTCTGATTCTTGCAGTTGAATTTGGCCTCGAATTGAAGCAGGACATGGAGATGAGGCTGCCCATCGTCGTGAAGCTCTCTTGCGACCTTGATGAACTTCTTGTTCGTGGGCGTTTGCAATGATATGATTTGTTCGAGAGCAGCCTCTTTAGTTAGTGAGCACCGGGGATACGTGAGAAAATAATTTTTGGCGTTTATTTGAAAACGCTTTGGTGGTGGCATTCTTGTAAATAAAGGCTTGGGTACCGAATGGTTCCCTCTCCAAAACTCTATGGCAATCGGTAGAACGGTACCCCAATTTATACTAGAACCCTCAATAGAACTCTTCAATCTCAATCACCCCACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009310062.1
|
|
Location
|
203-958 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCCAAGCGTGACGTGCCATGGCGCCACATGGCAGGAACGTCAAAGATTTCCCGCTCGAGCAATTTCTCTCCTCGTGGTGGTGGAGGCCCAAAAACCACACGGGCCGCTGAATGGGTTAATAGGCCTATGTACAGAAAGCCCAGGATATATCGGATGTACAGAACCCCCGATGTTCCTAGGGGATGTGAAGGCCCGTGTAAGGTCCAGTCCTTTGAACAGAGGCATGATATTTCCCACACTGGGAAGGTTATATGTATTTCTGACGTGACACGTGGTAATGGTATTACTCACCGTGTTGGAAAGCGTTTTTGTGTTAAGTCTGTTTATGTTTTAGGTAAGATATGGATGGATGAGAACATCAAGCTCAAGAATCACACTAACAGTGTGATGTTTTGGTTGGTTAGAGACCGTCGTCCCTATGGTTCTCCTATGGACTTTGGCCAAGTGTTCAATTTATTTGATAATGAGCCAAGCACTGCTACGATCAAGAACGATCTACGTGATCGTTTCCAAGTCATGCACCGGTTCTATGCCAAAGTCACAGGTGGACAGTACGCGAGCAACGAGCAGGCATTGGTCAGGCGTTTTTGGAAGGTCAACAATCATGTGGTGTACAACCACCAAGAAGCCGCGAAGTACGAGAATCATACGGAGAACGCGTTACTCTTGTACATGGCATGCACTCATGCCTCAAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTCTATGATTCGATATCCAATTAA |
|
Protein Sequence
|
MPKRDVPWRHMAGTSKISRSSNFSPRGGGGPKTTRAAEWVNRPMYRKPRIYRMYRTPDVPRGCEGPCKVQSFEQRHDISHTGKVICISDVTRGNGITHRVGKRFCVKSVYVLGKIWMDENIKLKNHTNSVMFWLVRDRRPYGSPMDFGQVFNLFDNEPSTATIKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009310063.1
|
|
Location
|
955-1353 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCACGTCAGGCAGAGAGTGGCGTATATATCTGGGAGATATCAAATCCCCTCTATTTCAAGATGTACAACGTAGAGGACCCAATATACACGAGGACCAGAATATACCACGTCCAGATACGGTTCAACCACAACCTCAGGAACAGACTGGGTCTACACAAGGCCTTCCTGAACTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACATATTTAGTTAGGTTTAGGCAGTTAGTCTTGTTGTATTTAGATAGTTTGGGCGTAGTTTCGCTTAACAATGTAATTAGAGCTGTTCGTTTTGCAACAGACAAACCATATGTAAATTATGTGCTTGAGAATCATGAAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAESGVYIWEISNPLYFKMYNVEDPIYTRTRIYHVQIRFNHNLRNRLGLHKAFLNFQVWTTSVRASGTTYLVRFRQLVLLYLDSLGVVSLNNVIRAVRFATDKPYVNYVLENHEIKFKFY |
|
NCBI Accession
|
YP_009310064.1
|
|
Location
|
1100-1489 |
|
Gene Name
|
TrAP |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCGAAATTCGTCGTCCTCAACTCCCCCCTCTATCAAAGTCCAACACAGGGCGGCCAAGAAGAGAGCGGTCAGGAGACGACGAATTGATCTAGAGTGCGGGTGCTCCATATACGTACACCTTAACTGCGCAGGACATGGATTCACGCACCGGGGAACTCATCACTGCACGTCAGGCAGAGAGTGGCGTATATATCTGGGAGATATCAAATCCCCTCTATTTCAAGATGTACAACGTAGAGGACCCAATATACACGAGGACCAGAATATACCACGTCCAGATACGGTTCAACCACAACCTCAGGAACAGACTGGGTCTACACAAGGCCTTCCTGAACTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACATATTTAGTTAG |
|
Protein Sequence
|
MRNSSSSTPPSIKVQHRAAKKRAVRRRRIDLECGCSIYVHLNCAGHGFTHRGTHHCTSGREWRIYLGDIKSPLFQDVQRRGPNIHEDQNIPRPDTVQPQPQEQTGSTQGLPELPSLDDISSSFWDDIFS |
|
NCBI Accession
|
YP_009310065.1
|
|
Location
|
1401-2489 |
|
Gene Name
|
REP |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCACCAAAGCGTTTTCAAATAAACGCCAAAAATTATTTTCTCACGTATCCCCGGTGCTCACTAACTAAAGAGGCTGCTCTCGAACAAATCATATCATTGCAAACGCCCACGAACAAGAAGTTCATCAAGGTCGCAAGAGAGCTTCACGACGATGGGCAGCCTCATCTCCATGTCCTGCTTCAATTCGAGGCCAAATTCAACTGCAAGAATCAGAGATTCTTCGACCTTGTCTCCCCAAATAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCCTATGTCGACAAGGACGGAGACACCATTGAATGGGGAGAATTCCAGGTCGACGCTCGTTCTGCAAGAGGTGGCCAACAGACTGCGAACGAGTCATACGCCAAGGTTCTGAATGCTCAGAACATTGAACAGGCTCTCCAAATATTGAAGGAGGAACAACCGAAGGACTTCGTCCTTCAACACCATAACATACGCTCTAACCTAGAGCGTATCTTTGCAAAGGCTCCGGAGCCGTGGACTCCTCCGTTTCACCTCTCCTCATTCACTAACGTGCCCAAGGAGATGCAAGACTGGGCGGACGACTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGAGAGACCACTCAGCATCATCATAGAGGGTGGTTCAAGGTCAGGGAAGACCATGTGGGCACGTGCCTTGGGGGTCCACAATTACCTGAGTGGTCACCTCGATTTCAATTCGAGGGTCTATTCGAATTTGGCCCAATACAACGTGATAGATGACATCGCACCGCTCTATCTAAAGCTAAAGCACTGGAAAGAATTGATTGGGCTCAAAAGGACTGGCAATCGAACTGCAAATACGGAAAGCCGGTTCAAATTAAAGGCGGGATCCATCCCATCAATCGTGCTTTGCAATCCTGGTGAAGGGGCCAGCTATAAAGATTTCCTAGACAAAGAAGAGAACGCAGCATTAAAGAGTTGGACCCTTCACAATGCGAAATTCGTCGTCCTCAACTCCCCCCTCTATCAAAGTCCAACACAGGGCGGCCAAGAAGAGAGCGGTCAGGAGACGACGAATTGA |
|
Protein Sequence
|
MPPPKRFQINAKNYFLTYPRCSLTKEAALEQIISLQTPTNKKFIKVARELHDDGQPHLHVLLQFEAKFNCKNQRFFDLVSPNRSAHFHPNIQGAKSSSDVKSYVDKDGDTIEWGEFQVDARSARGGQQTANESYAKVLNAQNIEQALQILKEEQPKDFVLQHHNIRSNLERIFAKAPEPWTPPFHLSSFTNVPKEMQDWADDYFGRGAAARPERPLSIIIEGGSRSGKTMWARALGVHNYLSGHLDFNSRVYSNLAQYNVIDDIAPLYLKLKHWKELIGLKRTGNRTANTESRFKLKAGSIPSIVLCNPGEGASYKDFLDKEENAALKSWTLHNAKFVVLNSPLYQSPTQGGQEESGQETTN |
|
NCBI Accession
|
YP_009310066.1
|
|
Location
|
2075-2332 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGCAGCCTCATCTCCATGTCCTGCTTCAATTCGAGGCCAAATTCAACTGCAAGAATCAGAGATTCTTCGACCTTGTCTCCCCAAATAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCCTATGTCGACAAGGACGGAGACACCATTGAATGGGGAGAATTCCAGGTCGACGCTCGTTCTGCAAGAGGTGGCCAACAGACTGCGAACGAGTCATACGCCAAGGTTCTGA |
|
Protein Sequence
|
MGSLISMSCFNSRPNSTARIRDSSTLSPQIGQHISIQTYRELSRAPTSSPMSTRTETPLNGENSRSTLVLQEVANRLRTSHTPRF |