Lycianthes yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029225.2 |
| Isolate |
China: Guangdong |
| Release date |
2018/12/27 |
| Submitter |
Tang,Y.F., He,Z.F. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
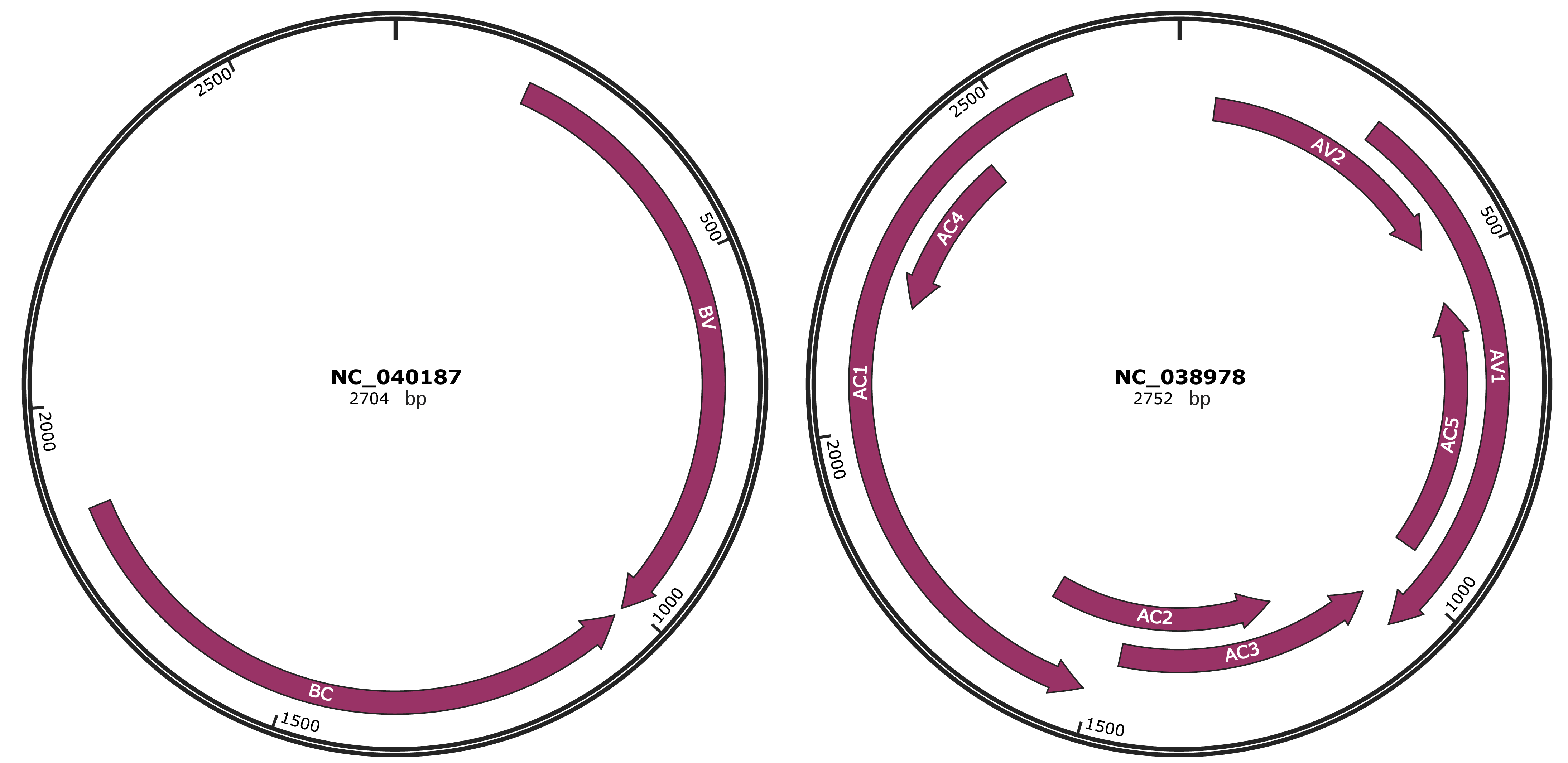
JBrowse
Genome
ACCGAGGGCCGCGAATTTTTTTTTTTTGCAGTGGTCCCGTCAAAATATCTCTGACATATGCATACGTGTATGCATCTCAACCGTTTGCAATTGACACGCGTAAGCAATCCAAGGGACCACTTGAGTAGTGGGTTCTGATATATATAGACATTATTTCTCTTTCTTCTCATTTTTTGGTAAAATGAGAATTCCCATTAGAACTCCCATGGGTCTCAATAGAGACCGAAGAAATTCTGGTGGCGGTGTATTCCGGTCTAACTATCCGTATGCCAGATATTTTGGCAGACGTGTTGGTCAGCGTGTTTATGGAATGCCATTTGGAAGTGTTAACAGGCGTTCAGGTGGTGTGTCTATGTTACGCCGGAACTTGTTTTCCGGCAGACAAGAACCGCGACAAAGAAGTCGTCAGACTATAGAGGAAGTTCAAGATGGGTCAGATTATCTGCTTTGTAACAACACTTCCAAGGTTTCTTACCTGACATTTCCGGCGAAGTCTAGGTCGGAGTTTAGCAGCAGGGTGGACTCCTACATTAAATTACTTGGTCTGAACGTATCTGGTTCGGTAATTGCGAGGCAACTTGAAAGGTCAGATGTTGCTGCTACCAATGGGATACATGGCATATTCACGACAGTGATTGTCCGTGATAAACGACCATGCCAATTCTCTTCAGTTGATCCTCTCATCCCTTTTGGCGAGATATTCGGACTTGAGAAGGGAGCATGTTCTACTCTGCGCATTCGCGACCAGCATAGGAATAGGTTTAGTTTAGTGTATCAGAAGAAGTGTGTGGTCAACACCGCACTTCCGGAACATGTATTTAGGTTTTCTTACAATGTTAGGTTTTGTTCATACCCACTTTGGGTATCATTCAAGGACACGGAGGATTCTGAGCATACAGGACTCTATAGCAACGTGTCTAAGAATGCTATAATAGTTTATTATGTTTGGCTTTGTGATGCTAATGTAACATCAGAAATACATGTAAAATACGACCTGCATTATAATGGATAAATAAAATCTCATTTTATTTGATTGGCTTTACATTGGATGTTACATTACTGCCTTCCATACACAACTCGACTGTTTTTTTGATGATGTTTATAACATCATCGTTTACAGTTTGGTTGTTGCCAACAACCTCTGAAGCAGACGGACCAGGGTCTAATGTTTTGTCCTGTAACCTGTGTAAATTGCGGTATGGAAGATCTTCTTGATCTTCATTTCCAACTGAACTAGCAGAAGCCCATGTCTGCCCTGGAAGTATAGCAGGAGTTGTGTATCTACATGACTGTGATCGTATATTTGACAACGCCTGTACAGGTTTCCTGGAAACCTGAGAATGGGGCACTGTCCAGAAATCAATGTTGGTCATGTTGTACGCCTTGGACAGTATCTCAATTTTAGGGGACTTGAACTGAATTTCGGAGGACTGTTTAGCTGAAGACATTTTCAGCTTCCCTTGCATCCTGCAGAAGTGGACTCCGTTCACCACATTTGTGTCGTCGACTCTGTACATAACCCTCCATGGATTTGGATCCTTTGGGGAAAAATAGGAGGATGAGTAGTAGTGTATGTTGCAGTTACACCCAATCGGAATGGTAAATTCCGCTTGTTTGGAATCTCCTTCATGGAGTCTTGTGTCGTGCATCTCTATTACGACATGTCCGGTGGCATTAACAGGAACTTGATTCCTGTACTCCAAAATGACATGATCAATCCTCAAACATTTACCTAGGAGTTTGGAGAATTTTTGGTCGATTGTGCTGGGAAATAGTAGGGTTACTTCGGTCTTTTCATTAGACAGCTGGAACTCTGTCCTATCCGACGTCGTATATGCTACAGCATTGTTATTATGTTCCATAATTGCTCTGTGCTTTTCCTTGCTGGAATGCACATACTTTTATAGTGGGTTGGAGCTTTACAGACGCACTAACTGATGGGTCACCATCAGAGTGAACAGATAACATTTCAAACATGGCTGAAAATCAGCCACGTCACATATGTACTGAATGGAATACAGCTGTATTCCTCTAACATTATAAACACGTGTTTATATATATTGGTAAAGTTACATAAACCCTAATTTTGACGGAGTGAACTGAGATACACAGATATGGTAAATAGATTTGAGAATCTAAACTTTTTGGTTAACATACTTGTTAACAATACAATTATCAGCTAATACTCATACTAACCATCTATAATACATGTTAAACAACAACATATAAAATTCTATTGAGAAATATCTGGCCGCGCAGCGGCATTGTTCTCTCAAATTTCTGATATACTTATCAGCTAAACAGTTATTTGCGGAAGCATAATTGTAATAAACAAGTGATAATGTATAGCAGCAGCAGTAATTACTTACGGCATTTACATTTGATTATTAGTAATTATATTGAAGACTGATGCTAATATGTTGCTTATTCTATCGATTAAAAACTTTTAATCTCAACATATTTTACTAATAATTAGCAACAGACTGTTCTCAGGGAATAAGTAGAGAGAGAATGGTAATTCTAGAGAGAGCAGCTCCTATCGGGGACACCACTAATTCTAAGGAATGGGGGACATTGGGGACGCTTATATATGGGAGTCCCTAAATGGCATAATGGTAAATACCTACTACTTTTCTGACACTGTCAGACAACTTTAATTTGAAATTCAAAATTTTTTCCGGAAAAGCGGCCCTCGTATAATATT
ACCGAGGGCCGCGAAATTTTTTTTTATAGTGGTCCCCTTTTGACTAGCCAATCAAAATGCGTGTACAATCCTTAGTTAGTGCGTCCCGCACTATAAAACTTGGGGACCACGTAGCACTACCAAACATGTGGGATCCTCTGACACACCCTTTTCCAGAAACCCTACATGGGTTTAGATGTATGCTAGCAATCAAGTACTTGCAATCCTTACAGGCGAAGTATTCTCCGGATACGAACGGTAGTGAGTTTTTGAAGGATCTAATTTGTGTACTTCGCTGTAAGAATTATGCCGAAGCGTTCAATCGATACAGTGTCATCGCTACCAATGTCCATAACACGCCGGAGGCTAAATTACGGGAGTCAGTACAGTCTCCCTGCTGCTGCCTCCACTGCCCCAGGCATGTCATACAAAAGAAGGTCTTGGGTGAATCGGCCGATGTACAGGAAGCCCAGGTTTTACAGGGGTAGACGGAGCAGTGATGTTCCTAGGGGCTGTGAAGGACCTTGCAAGGTCCAATCATTTGAACAGAGACATGACATTCTTCATACCGGCAAGGTATTATGCATTACCGATGTTACACGTGGTGGTGGTATAACGCATCGTGTTGGTAAGAGATTTTGTGTTAAGTCTGTATACGTTATTGGGAAGGTTTGGATGGATGATAATATCAAAACCAAAAATCACACTAACAATGTAATGTTTTGGCTTGTCCGAGATCGTCGACCTTATGGAACTCCTCAAGATTTTGGACAGGTTTTCAACATGTATGACAATGAACCTAGTACTGCAACAATCAAGAACGATCTCAGAGATCGTTTCCAAGTCATTCATCGATTCACAGCATCCGTGACCGGAGGTCAATATGGTAGCAAGGAACAGGCTATTGTCAAGAGGTTTTTTAGGGTGAACAACTACGTTGTATACAACCACCAAGAAGCTGGAAAGTATGAGAATCATACAGAGAATGCATTATTATTGTACATGGCATGTACTCATGCATCTAATCCAGTTTATGCAACGTTAAAAATACGTATATATTTTTACGACTCTGTAACAAATTAATAAATATTGAATTTTATTGCATATAACATTCTGGCATAAGTGGTATTGTCAAATACATTCCATAACACATGATTAACAGATCTAATAACATTATTAATAGAAACAACTCCTAAGTTGTTTAAGAATCTAATTACATTATATTTAAATACTCTTAAGAAACGCCAAGTCTGAGGACGTAAACGAGTCCAGATGCGGAAGATTAAGAAACACTTGTGAATCCCCAGAGCTCTCCGCAGGTTGTGGTTGAACTGGATTTGTATCTCCAAATAATCGTGGTCGCTGTTGAAAGGTCTGCTGGTGTGCTTCAGCACCTTGAAATAGAGGGGATTTGGAACCGTCCAGATATAGGCGCCATTCTGCGCCTGAGTTGCAGTGATGTATTCCCCTGTGCGAAAATCCACAGCCATGACAGTTGATGCTCAGATAATATGAGCATCCGCAATCTAAATCAATTCGCCTCCGGCGAGTTATCCTCTTCTTGGCAATCTTGTGTTGGATTTTCTGAGGTACCTGAGAAGAGTGGTTCCCGAAGGGTGATGAAGGTCGCATTTTTTAATGCCCACTCTTTTAATGCACTATTTTTTTCTTCGTCAAGATATTCTTTATAAGACGAAGAGGGCCCTGGATTGCATAGGAAGATAGTGGGAATGCCCCCTTTAATTTGAATTGGTTTCCCGTACTTTGTGTTGCTTTGCCAGTCTCTCTGGGCCCCCATAAACTCTTTAAAATGCTTTAGATAGTGCGGATCAACGTCATCAATGACGTTATACCAGCCATCATTGCTGTACACTTTGGGACTCAGATCCAGATGTCCGCACAAATAATTGTGTTTGCCAAGTGACCTAGCCCATAATGTTTTGCCGGTTCTAGATACACCTTCTATTACAATACTCATGGGTCTCCAAGGCCGCGCAGCGGCGTCAACAACATTCTGGTAAACCCATTGTGACAATTCATTTGGAACATTATTGAAAGTTGTCACATTAAAAGGACTAACGTATTGTTGTTGTTGAGGTTTGAATATTTTATCTAAATTGGCACTTAAATTGTGGTACTGGAAGATAAAATCCTTTGGAAGTTTTTCTTTAATAATATTTAAAGCATCTTCCTTTGAAGGTGCATTCAACGCCTCCGCCGCAACATCATGTGCTGCATGTGAACTTCTTCTAGAAGATCTTCCATCGATTTGAAAACTACCCCAGTCGACGTAATCTCCGTCCTTCTCAATATATGCCTTGACATCTGACGAGGAGCGTGCTCCTTGGAAATTAGGATGGAAGATTCTTGGAGCATGAGGATGGGAGATATCGAAATGTCTTTCATTTCGGAATTTGGCTTTACCTTTGAATTGAATAAGGGCATGGATATGCAGTGACCCATCTTGATGTTTCTCACTAGAAACCCTAATGAATAGCTTATCAGATGGACAAGAGATATTCTGGAGAATTTCAAGAACTATTTGTTTTGACAAACTACACTGGGGATATGTGAGGAATATATTCTTAGCATTCACACAGAATGAATGATGACGTGGCATTTTCAATCGGGGACACCACTAATTCTAAGGAATGGGGGACATTGGGGACGCTTATATATGGGAGTCCCTAAATGGCATAATGGTAAATAGGTAAAGTTACTTTAATTTGAATTTCAAATTTTTTTTGGGGAAAAGCGGCCCTCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547934.1
|
|
Location
|
182-1012 |
|
Gene Name
|
BV |
|
Protein Name
|
BV protein |
|
Coding Region
|
ATGAGAATTCCCATTAGAACTCCCATGGGTCTCAATAGAGACCGAAGAAATTCTGGTGGCGGTGTATTCCGGTCTAACTATCCGTATGCCAGATATTTTGGCAGACGTGTTGGTCAGCGTGTTTATGGAATGCCATTTGGAAGTGTTAACAGGCGTTCAGGTGGTGTGTCTATGTTACGCCGGAACTTGTTTTCCGGCAGACAAGAACCGCGACAAAGAAGTCGTCAGACTATAGAGGAAGTTCAAGATGGGTCAGATTATCTGCTTTGTAACAACACTTCCAAGGTTTCTTACCTGACATTTCCGGCGAAGTCTAGGTCGGAGTTTAGCAGCAGGGTGGACTCCTACATTAAATTACTTGGTCTGAACGTATCTGGTTCGGTAATTGCGAGGCAACTTGAAAGGTCAGATGTTGCTGCTACCAATGGGATACATGGCATATTCACGACAGTGATTGTCCGTGATAAACGACCATGCCAATTCTCTTCAGTTGATCCTCTCATCCCTTTTGGCGAGATATTCGGACTTGAGAAGGGAGCATGTTCTACTCTGCGCATTCGCGACCAGCATAGGAATAGGTTTAGTTTAGTGTATCAGAAGAAGTGTGTGGTCAACACCGCACTTCCGGAACATGTATTTAGGTTTTCTTACAATGTTAGGTTTTGTTCATACCCACTTTGGGTATCATTCAAGGACACGGAGGATTCTGAGCATACAGGACTCTATAGCAACGTGTCTAAGAATGCTATAATAGTTTATTATGTTTGGCTTTGTGATGCTAATGTAACATCAGAAATACATGTAAAATACGACCTGCATTATAATGGATAA |
|
Protein Sequence
|
MRIPIRTPMGLNRDRRNSGGGVFRSNYPYARYFGRRVGQRVYGMPFGSVNRRSGGVSMLRRNLFSGRQEPRQRSRQTIEEVQDGSDYLLCNNTSKVSYLTFPAKSRSEFSSRVDSYIKLLGLNVSGSVIARQLERSDVAATNGIHGIFTTVIVRDKRPCQFSSVDPLIPFGEIFGLEKGACSTLRIRDQHRNRFSLVYQKKCVVNTALPEHVFRFSYNVRFCSYPLWVSFKDTEDSEHTGLYSNVSKNAIIVYYVWLCDANVTSEIHVKYDLHYNG |
|
NCBI Accession
|
YP_009547935.1
|
|
Location
|
1026-1862 |
|
Gene Name
|
BC |
|
Protein Name
|
BC protein |
|
Coding Region
|
ATGGAACATAATAACAATGCTGTAGCATATACGACGTCGGATAGGACAGAGTTCCAGCTGTCTAATGAAAAGACCGAAGTAACCCTACTATTTCCCAGCACAATCGACCAAAAATTCTCCAAACTCCTAGGTAAATGTTTGAGGATTGATCATGTCATTTTGGAGTACAGGAATCAAGTTCCTGTTAATGCCACCGGACATGTCGTAATAGAGATGCACGACACAAGACTCCATGAAGGAGATTCCAAACAAGCGGAATTTACCATTCCGATTGGGTGTAACTGCAACATACACTACTACTCATCCTCCTATTTTTCCCCAAAGGATCCAAATCCATGGAGGGTTATGTACAGAGTCGACGACACAAATGTGGTGAACGGAGTCCACTTCTGCAGGATGCAAGGGAAGCTGAAAATGTCTTCAGCTAAACAGTCCTCCGAAATTCAGTTCAAGTCCCCTAAAATTGAGATACTGTCCAAGGCGTACAACATGACCAACATTGATTTCTGGACAGTGCCCCATTCTCAGGTTTCCAGGAAACCTGTACAGGCGTTGTCAAATATACGATCACAGTCATGTAGATACACAACTCCTGCTATACTTCCAGGGCAGACATGGGCTTCTGCTAGTTCAGTTGGAAATGAAGATCAAGAAGATCTTCCATACCGCAATTTACACAGGTTACAGGACAAAACATTAGACCCTGGTCCGTCTGCTTCAGAGGTTGTTGGCAACAACCAAACTGTAAACGATGATGTTATAAACATCATCAAAAAAACAGTCGAGTTGTGTATGGAAGGCAGTAATGTAACATCCAATGTAAAGCCAATCAAATAA |
|
Protein Sequence
|
MEHNNNAVAYTTSDRTEFQLSNEKTEVTLLFPSTIDQKFSKLLGKCLRIDHVILEYRNQVPVNATGHVVIEMHDTRLHEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWRVMYRVDDTNVVNGVHFCRMQGKLKMSSAKQSSEIQFKSPKIEILSKAYNMTNIDFWTVPHSQVSRKPVQALSNIRSQSCRYTTPAILPGQTWASASSVGNEDQEDLPYRNLHRLQDKTLDPGPSASEVVGNNQTVNDDVINIIKKTVELCMEGSNVTSNVKPIK |
|
NCBI Accession
|
YP_009508367.1
|
|
Location
|
57-467 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGCGTGTACAATCCTTAGTTAGTGCGTCCCGCACTATAAAACTTGGGGACCACGTAGCACTACCAAACATGTGGGATCCTCTGACACACCCTTTTCCAGAAACCCTACATGGGTTTAGATGTATGCTAGCAATCAAGTACTTGCAATCCTTACAGGCGAAGTATTCTCCGGATACGAACGGTAGTGAGTTTTTGAAGGATCTAATTTGTGTACTTCGCTGTAAGAATTATGCCGAAGCGTTCAATCGATACAGTGTCATCGCTACCAATGTCCATAACACGCCGGAGGCTAAATTACGGGAGTCAGTACAGTCTCCCTGCTGCTGCCTCCACTGCCCCAGGCATGTCATACAAAAGAAGGTCTTGGGTGAATCGGCCGATGTACAGGAAGCCCAGGTTTTACAGGGGTAG |
|
Protein Sequence
|
MRVQSLVSASRTIKLGDHVALPNMWDPLTHPFPETLHGFRCMLAIKYLQSLQAKYSPDTNGSEFLKDLICVLRCKNYAEAFNRYSVIATNVHNTPEAKLRESVQSPCCCLHCPRHVIQKKVLGESADVQEAQVLQG |
|
NCBI Accession
|
YP_009508368.1
|
|
Location
|
286-1062 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGCCGAAGCGTTCAATCGATACAGTGTCATCGCTACCAATGTCCATAACACGCCGGAGGCTAAATTACGGGAGTCAGTACAGTCTCCCTGCTGCTGCCTCCACTGCCCCAGGCATGTCATACAAAAGAAGGTCTTGGGTGAATCGGCCGATGTACAGGAAGCCCAGGTTTTACAGGGGTAGACGGAGCAGTGATGTTCCTAGGGGCTGTGAAGGACCTTGCAAGGTCCAATCATTTGAACAGAGACATGACATTCTTCATACCGGCAAGGTATTATGCATTACCGATGTTACACGTGGTGGTGGTATAACGCATCGTGTTGGTAAGAGATTTTGTGTTAAGTCTGTATACGTTATTGGGAAGGTTTGGATGGATGATAATATCAAAACCAAAAATCACACTAACAATGTAATGTTTTGGCTTGTCCGAGATCGTCGACCTTATGGAACTCCTCAAGATTTTGGACAGGTTTTCAACATGTATGACAATGAACCTAGTACTGCAACAATCAAGAACGATCTCAGAGATCGTTTCCAAGTCATTCATCGATTCACAGCATCCGTGACCGGAGGTCAATATGGTAGCAAGGAACAGGCTATTGTCAAGAGGTTTTTTAGGGTGAACAACTACGTTGTATACAACCACCAAGAAGCTGGAAAGTATGAGAATCATACAGAGAATGCATTATTATTGTACATGGCATGTACTCATGCATCTAATCCAGTTTATGCAACGTTAAAAATACGTATATATTTTTACGACTCTGTAACAAATTAA |
|
Protein Sequence
|
MPKRSIDTVSSLPMSITRRRLNYGSQYSLPAAASTAPGMSYKRRSWVNRPMYRKPRFYRGRRSSDVPRGCEGPCKVQSFEQRHDILHTGKVLCITDVTRGGGITHRVGKRFCVKSVYVIGKVWMDDNIKTKNHTNNVMFWLVRDRRPYGTPQDFGQVFNMYDNEPSTATIKNDLRDRFQVIHRFTASVTGGQYGSKEQAIVKRFFRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_009508369.1
|
|
Location
|
559-957 |
|
Gene Name
|
AC5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGATTCTCATACTTTCCAGCTTCTTGGTGGTTGTATACAACGTAGTTGTTCACCCTAAAAAACCTCTTGACAATAGCCTGTTCCTTGCTACCATATTGACCTCCGGTCACGGATGCTGTGAATCGATGAATGACTTGGAAACGATCTCTGAGATCGTTCTTGATTGTTGCAGTACTAGGTTCATTGTCATACATGTTGAAAACCTGTCCAAAATCTTGAGGAGTTCCATAAGGTCGACGATCTCGGACAAGCCAAAACATTACATTGTTAGTGTGATTTTTGGTTTTGATATTATCATCCATCCAAACCTTCCCAATAACGTATACAGACTTAACACAAAATCTCTTACCAACACGATGCGTTATACCACCACCACGTGTAACATCGGTAATGCATAA |
|
Protein Sequence
|
MILILSSFLVVVYNVVVHPKKPLDNSLFLATILTSGHGCCESMNDLETISEIVLDCCSTRFIVIHVENLSKILRSSIRSTISDKPKHYIVSVIFGFDIIIHPNLPNNVYRLNTKSLTNTMRYTTTTCNIGNA |
|
NCBI Accession
|
YP_009508370.1
|
|
Location
|
1059-1469 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGCTGTGGATTTTCGCACAGGGGAATACATCACTGCAACTCAGGCGCAGAATGGCGCCTATATCTGGACGGTTCCAAATCCCCTCTATTTCAAGGTGCTGAAGCACACCAGCAGACCTTTCAACAGCGACCACGATTATTTGGAGATACAAATCCAGTTCAACCACAACCTGCGGAGAGCTCTGGGGATTCACAAGTGTTTCTTAATCTTCCGCATCTGGACTCGTTTACGTCCTCAGACTTGGCGTTTCTTAAGAGTATTTAAATATAATGTAATTAGATTCTTAAACAACTTAGGAGTTGTTTCTATTAATAATGTTATTAGATCTGTTAATCATGTGTTATGGAATGTATTTGACAATACCACTTATGCCAGAATGTTATATGCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MAVDFRTGEYITATQAQNGAYIWTVPNPLYFKVLKHTSRPFNSDHDYLEIQIQFNHNLRRALGIHKCFLIFRIWTRLRPQTWRFLRVFKYNVIRFLNNLGVVSINNVIRSVNHVLWNVFDNTTYARMLYAIKFNIY |
|
NCBI Accession
|
YP_009508371.1
|
|
Location
|
1204-1611 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGACCTTCATCACCCTTCGGGAACCACTCTTCTCAGGTACCTCAGAAAATCCAACACAAGATTGCCAAGAAGAGGATAACTCGCCGGAGGCGAATTGATTTAGATTGCGGATGCTCATATTATCTGAGCATCAACTGTCATGGCTGTGGATTTTCGCACAGGGGAATACATCACTGCAACTCAGGCGCAGAATGGCGCCTATATCTGGACGGTTCCAAATCCCCTCTATTTCAAGGTGCTGAAGCACACCAGCAGACCTTTCAACAGCGACCACGATTATTTGGAGATACAAATCCAGTTCAACCACAACCTGCGGAGAGCTCTGGGGATTCACAAGTGTTTCTTAATCTTCCGCATCTGGACTCGTTTACGTCCTCAGACTTGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MRPSSPFGNHSSQVPQKIQHKIAKKRITRRRRIDLDCGCSYYLSINCHGCGFSHRGIHHCNSGAEWRLYLDGSKSPLFQGAEAHQQTFQQRPRLFGDTNPVQPQPAESSGDSQVFLNLPHLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_009508372.1
|
|
Location
|
1511-2599 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCACGTCATCATTCATTCTGTGTGAATGCTAAGAATATATTCCTCACATATCCCCAGTGTAGTTTGTCAAAACAAATAGTTCTTGAAATTCTCCAGAATATCTCTTGTCCATCTGATAAGCTATTCATTAGGGTTTCTAGTGAGAAACATCAAGATGGGTCACTGCATATCCATGCCCTTATTCAATTCAAAGGTAAAGCCAAATTCCGAAATGAAAGACATTTCGATATCTCCCATCCTCATGCTCCAAGAATCTTCCATCCTAATTTCCAAGGAGCACGCTCCTCGTCAGATGTCAAGGCATATATTGAGAAGGACGGAGATTACGTCGACTGGGGTAGTTTTCAAATCGATGGAAGATCTTCTAGAAGAAGTTCACATGCAGCACATGATGTTGCGGCGGAGGCGTTGAATGCACCTTCAAAGGAAGATGCTTTAAATATTATTAAAGAAAAACTTCCAAAGGATTTTATCTTCCAGTACCACAATTTAAGTGCCAATTTAGATAAAATATTCAAACCTCAACAACAACAATACGTTAGTCCTTTTAATGTGACAACTTTCAATAATGTTCCAAATGAATTGTCACAATGGGTTTACCAGAATGTTGTTGACGCCGCTGCGCGGCCTTGGAGACCCATGAGTATTGTAATAGAAGGTGTATCTAGAACCGGCAAAACATTATGGGCTAGGTCACTTGGCAAACACAATTATTTGTGCGGACATCTGGATCTGAGTCCCAAAGTGTACAGCAATGATGGCTGGTATAACGTCATTGATGACGTTGATCCGCACTATCTAAAGCATTTTAAAGAGTTTATGGGGGCCCAGAGAGACTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGGGGCATTCCCACTATCTTCCTATGCAATCCAGGGCCCTCTTCGTCTTATAAAGAATATCTTGACGAAGAAAAAAATAGTGCATTAAAAGAGTGGGCATTAAAAAATGCGACCTTCATCACCCTTCGGGAACCACTCTTCTCAGGTACCTCAGAAAATCCAACACAAGATTGCCAAGAAGAGGATAACTCGCCGGAGGCGAATTGA |
|
Protein Sequence
|
MPRHHSFCVNAKNIFLTYPQCSLSKQIVLEILQNISCPSDKLFIRVSSEKHQDGSLHIHALIQFKGKAKFRNERHFDISHPHAPRIFHPNFQGARSSSDVKAYIEKDGDYVDWGSFQIDGRSSRRSSHAAHDVAAEALNAPSKEDALNIIKEKLPKDFIFQYHNLSANLDKIFKPQQQQYVSPFNVTTFNNVPNELSQWVYQNVVDAAARPWRPMSIVIEGVSRTGKTLWARSLGKHNYLCGHLDLSPKVYSNDGWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPSSSYKEYLDEEKNSALKEWALKNATFITLREPLFSGTSENPTQDCQEEDNSPEAN |
|
NCBI Accession
|
YP_009508373.1
|
|
Location
|
2185-2442 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGTCACTGCATATCCATGCCCTTATTCAATTCAAAGGTAAAGCCAAATTCCGAAATGAAAGACATTTCGATATCTCCCATCCTCATGCTCCAAGAATCTTCCATCCTAATTTCCAAGGAGCACGCTCCTCGTCAGATGTCAAGGCATATATTGAGAAGGACGGAGATTACGTCGACTGGGGTAGTTTTCAAATCGATGGAAGATCTTCTAGAAGAAGTTCACATGCAGCACATGATGTTGCGGCGGAGGCGTTGA |
|
Protein Sequence
|
MGHCISMPLFNSKVKPNSEMKDISISPILMLQESSILISKEHAPRQMSRHILRRTEITSTGVVFKSMEDLLEEVHMQHMMLRRRR |