Luffa yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000841445.1 |
| Isolate |
Viet Nam |
| Release date |
2015/2/12 |
| Submitter |
Revill,P.A., Ha,C.V., Porchun,S.C., Vu,M.T., Dale,J.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
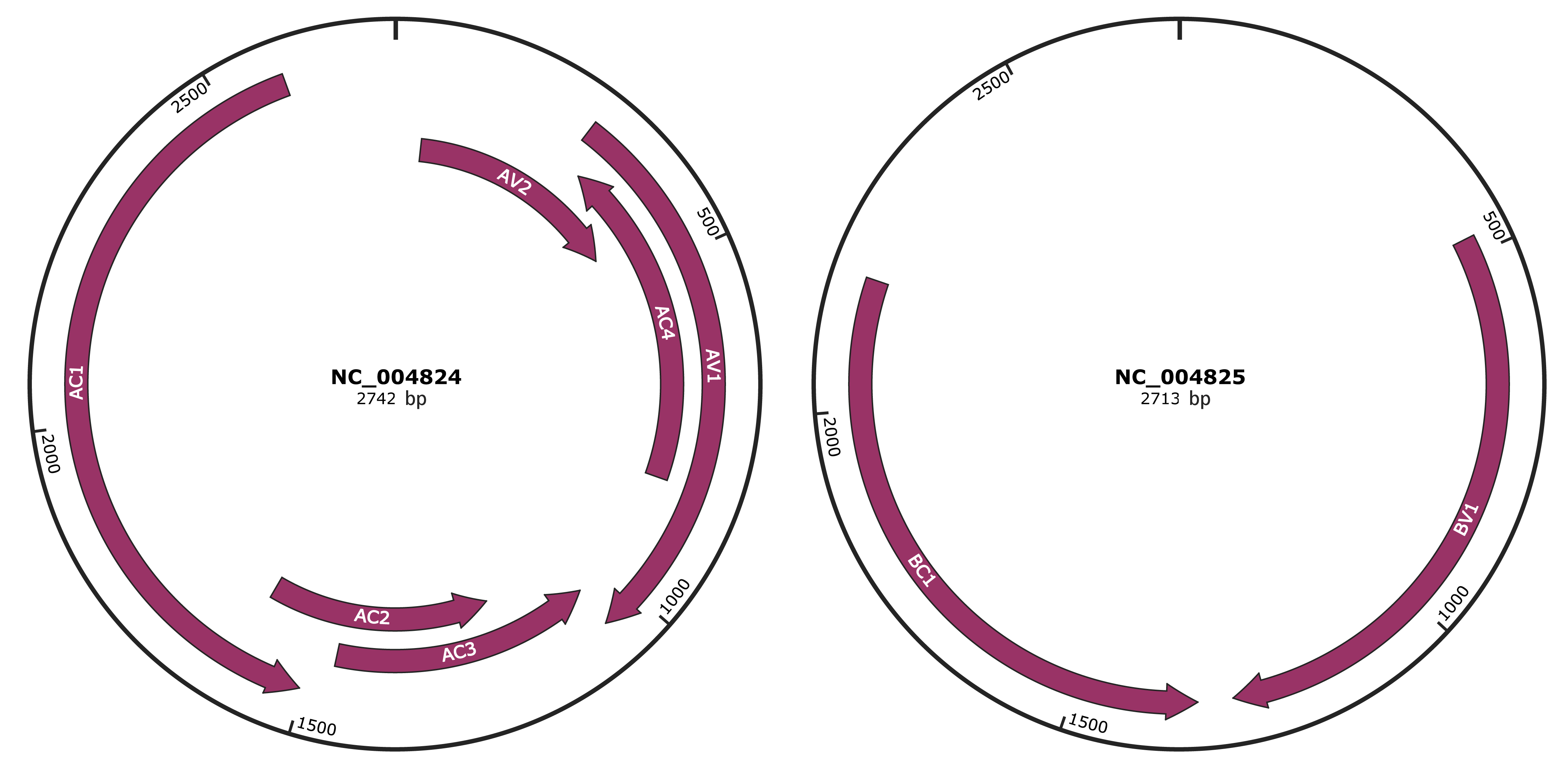
JBrowse
Genome
TAATATTACCGGAAGGCCGCGCGATTTTTTTTGTGGGCCCTTGACCAATGAAATTCAAGCTACATGGCTTATTTATTACCTGGGGACCATTAAATAGACTTCCTCACCAAGTTTGGATTCAAAACATGTGGGATCCATTATTGCACGAATTTCCTGAAAGCGTTCATGGTCTACGGTGCATGCTAGCGGTGAAATATCTTCAGGAAGTGGAAAAGACATATTCCCCGGACACAGTCGGCTACGATCTTGTCCGTGATCTGATTTTAGTTCTCCGCGCGAAGAACTATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCATCGAAGGTACGTCGACGTCTGAACTTCGACAGCCCATATGTATCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCTAGAATGTACAGGATGTACAGAAGTCCTGACGTGCCCAGGGGCTGTGAAGGCCCTTGTAAGGTTCAATCCTTCGAATCTAGGCACGATGTTTCTCATATTGGGAAGGTGATGTGCATCAGCGATGTTACACGAGGAACCGGACTCACACATCGCGTTGGGAAGCGATTTTGTGTGAAATCTGTTTACGTGTTGGGAAAAATATGGATGGACGAAAATATCAAGACTAAAAATCATACTAATAGCGTCATATTTTTTCTGGTTCGAGACCGTCGTCCTACAGGAACGCCACAGGATTTTGGGGAGGTTTTTAATATGTTCGACAATGAACCGAGCACTGCAACGGTGAAGAATATGCATCGTGATCGATATCAAGTGCTGCGCAAATGGCATGCTACTGTGACGGGAGGAACATACGCATCGAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTTGTCTACAATCAACAGGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCACGCATCGAACCCTGTATATGCAACTCTGAAAATCCGGATCTATTTTTATGATTCGGTAACAAATTAATATATATTCACTTTCACATCATACGAGCTTCTTACATCAATTGTTCTTTCCAATACATTGTCTAAAACATGATAAACAGATCTTATTACATTGTAAATAGAGAGCACCCCTAACATATCCAGGTACTTAAGGACCTGGGTTTTAAAGACTCTCAAGAAAATCCCAATCGGAGGGCGTAAGCCCGTCCAGATTTGGAAAGTTAGAGCACACTTGTGAAGTCCCAGCGCTTTCCTCAGGTTGTGGTTGAACAGTATCTGTACCACTATTATGTCGTGTTCTGTCATGAAGGGTCGGCTGTCGTGTTTCAATATTTTGAAATACAGGGGATTTGGAATTTCCCAAATAAAGACGCCACTCTCTGCTCGATCCGCAGTGATGTACTCCCCTGTGCGTGAATCCGTGATCATGGCAGTTTATTGACATGTAATACGAGCATCCGCACCGCAGATCAATCCGTTTGCGTCTGATGTTCCTCTTCTTCTTCTGTGGGAGCGTTGTTTGAGCGACCGGAATAGAGTGGTTCTTCGAGTTGGATGAAGACTGCATTCTTTATTGCCCACTGTTTTAGTGCTGAATTTTTTTCTTCGTCCAGATATTCTTTATAGCTGCTATTTGGTCCTTTATTGCAGAGGAAGATAGTGGGTATTCCACCTTTAATCATGACTGGCTTTCCGTATTTCGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAATTCTTTAAAATGCTTTAGGTAGTGCGGGTCGACGTCATCAATGACGTTGTACCAAGCTTCATTATTGTACACTCTCGGGCTCAGATCCAGATGACCGCATAGATAATTGTGTGGGCCTAAAGACCTGGCCCACATTGTCTTGCCCGTACGACTATCACCCTCAATGACAATACTCTTGGGTCTCCACGGCCGCGCAGCGGCATCCCTTACATTCTCAGACACCCAGACCTCAAGTTCCTCTGGAACTTGATCGAATGAAGAAGACAAAAAAGGACAAACAAAAACCTCTAAAGGAGGTGCAAAAATCCTATCTAAATTAGAATTCAAATTATGAAATTGGAAAATATAATCTTTTGGGAGTTTTTCCCTTATTATACTAAGTGCTGCTTCTTTAGAACCTGCGTTTAGGGCCTCTGCTGCTGCATCATTTGCTGTCTGTTGACCTCCTCTAGCAGATCGTCCATCGATCTGAAACTGACCCCAGTCAATGTAATCACCGTCTTTCTCGATGTAGGACTTGACATCGGAGCTGGACTTAGCTCCCTGGAAGTTTGGGTGGTATTGTGTGGAGGTATTAGGGTGAGTGACATCGAAATGTCTAGGGTTTCTGAACTGGCATTTACCTTTGAATTGGATGAGCGCGTGGATATGCAGAGACCCATCTTGGTGTTTTTCTTGTGATACTCTGATAAATAATTTGTCAGATGGACATGAAATGTTTCGAAGGAGTTCGAGCATATGCTCTTTTGGTATTGGGCATTTTGGGAAAGTGAGAAATATATTTTTTGCCTTAACTTGGAATTGGTTTGTTCGTGGCATATTGAATCGGGTGCTCTACAAAGCTCATAGGAATGGGGTGCTTTGGGTGCCTATTTATATTGAGCTCCCAAATGGCAATTTTGTAATTACGAAAAGTATTTCAAAACCCTAACGCTCCACTTTAATTCAAATCCATAAAGCGGCCTTCCGTA
TAATATTACCGGAAGGCCGCGCAAATTTTTCCTCTCCCCACAGTCGTTGATTTGTTCTAAAGGCGCGCACGATTGCATGTTTTCGCAACACGTGTCCTCTTATGATTACTTTATGAAAATAAAGTTAGCTGTGTTCTGAAATTTCGCACATGGTGGTCCCCCAGATACTAGATAGAAATATCTAGTTATATCGCTCTTTGTTCCCAATTTATCTGATATGGTTCGTATTTTGCACGGCTGAGATCAAAATAGGAATGATAAGAAAAAGTCTGTCATACATTTCCGACTAATTTTGAACGACTGAGATCAAAATAGGAATTCCATCAAATTTAACCCATTCAATTATCCCACTATACATATAACTCCATTTAACATGTTCTATTTTAATGTTTGCTATATTATTCTAATTGGAATAATATTTCTATATATTGTACTATGTGGCATATTGGTTGCCACATTTAAATCTTAACATCCAAATGCCTTTTCACTCCCCCTATTCTATGTCCAAACGTTTTTCGTTTGCAGGGAACAGACCTCACAACCCGGTCAAGAGATGGAGATCATGGAAACCACGGAAATTCCATGGATTGAATCGGTATCGTAATATCTGTTCCGCCGGCAGAACACCAACAGAACTGTTTGGGGATCAGATCTCCAAACAATATACGCGTAAGGAAATTTCTGAAACTCAGCAGGGTTCCGAATATGTTCTTCATAACAACCGTTACATTACTTCCTATGTGACATATCCTGCTAAGACAAGAACCGGAACGAACAACCGAGTTCGTTCTTATATCAAGCTTACGGGACTTAGCTTATCTGGAACATTTGGCATACGAACTTCGGACGTGATGCGCGATGTCGATCAAACTGGTGGATTATATGGCGTGATGTCTGTGGTTATAGTCCGAGATAAATCACCGAAGATTTATTCTACAGCACAACCACTCATGCCGTTTGTGGATTTATTTGGTTCTGTTAATGCATGTCGTGGGATTCTGAAGGTGGCAGAACGCCACCGAGAAAGGTTCGTGGTGCTGAATCAATCATCCATATTGATCAACACGCCTCATTGCAATACAATGAAGAAATTCTCCATTCGTAACTGCATACCACGTACCTACTCTACCTGGGTTAATTTCAAAGACGAAGAAGATGACAGTTGTACTGGTCTCTACTCAAATACTCTCCGGAATGCTATTCTTATTTATTATGTGTGGTTAAGCGATGTACGTTCACAAGTTGATTTATACAGCAATGTAATACTTAATTACATTGGTTAGATGTACTAAAATCAAACTATTCCATTGCAAATTTGAGAAATAAATTTATCATACGCCCTTTATTAATGGAGCATTTACATTAGATTTCATACATTGTTCGACCGTTTTAGTTATTATTTCTGTTATTTCGTCCCTGGTTATGCTTCCCACCTGTGAAGCCGACGGGCCTGGATCTATTGCGGATTCGTCTAATCCGCTTAGGTTTTTGTATGGTCTACTGCACACCGATGTCTGTCCAACCTCGGATCTACTTGCCCACGATTCATTCGGCCCAATCGCTAGATGTGGGACTCGTAAGGATCTGGAACTATGACCCATTAGTTTTGAACCGTCTACTAGTCTCCGGCTTTGTGCTTTCGATCCCACGGACCAGAAATCTATGTCGTTGACAGTGAACTCCTTGCTCTGTATCTCTATTCTTGGTGGTCGGAATTCGACGTGAGTCGAATGTTTTGCCGACGATAATTTCAATTTGCCTAAGATCTTACAAAAATGAACACCATTGACGACGTTTGTGTTCTCCACTCTGTATTCCACTCTCCAAGGATTGTTATCCTTAACGGAGAAGTATGTGGATGAATAGTAGTGTAAGTTGCAATTGCACTTTATTGGAATTGTGAATTCTGCTTGTTTTGTGTACCCTCGGTCAATCTCAATGTCGTGTATTTCGATAACGACATGCCCCACAGCATTTATTGGCACCTGGCTTCTATATTCCAGTACAACATGATCGATTTTCATGCATCTGTTTCTCAGCTGGCTGATTTTCTGTTCGAAGATTGAAGGGAACGTCAAAGTTACCTCTGAAGCGTCGTTTGTCAGAGCGTATTCAACGCGATTTGACTGTATATAGCCTCCAACGCCCATCACCATTTTATCATTGCCTATGGACATTTCGGGCGCGCAGCGGAAGACCACTGTAAATATGGATGGACGAAGAATGTGAAGAAGAGAAAGGAAAGAACACTTAAAGCTAACTGATTGCGTTACTAGGCAACGACGAGCATTCTTTTATATCCTACCCCGTGTATTGTCCCTATCTTTAGAACTGTCGTCCGATTCATGCTATTTAAACGAATAGCCATTTATGGACGGTCCAGATTCAGTTATGCCTTATAACATTCCAATGCCGAATATGTAAAAATTGGGCTTATACAACATATGGAGATGCAGTCCACAAAAAATGTGCCCGTATATGAAGCCCATTTATAAAATGATATCATTGGATAGTTGCAGGGACCAGACTTGTAGAGAGAAGCGGGAGTTTCTCTCTCTAGAATGGAATCGGGTGCTCTACAAACCTCATAGGAATGGGGTGCTTTGGGTGCCTATTTATATTGAGCTCCCAAATGGCAATTTTGTAATTACGAAAAGTATTTCAAAACCCTAACGCTCCACTTTAATTCAAATCCATAAAGCGGCCTTCCGTA
Gene Information
|
NCBI Accession
|
NP_852649.1
|
|
Location
|
48-446 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGAAATTCAAGCTACATGGCTTATTTATTACCTGGGGACCATTAAATAGACTTCCTCACCAAGTTTGGATTCAAAACATGTGGGATCCATTATTGCACGAATTTCCTGAAAGCGTTCATGGTCTACGGTGCATGCTAGCGGTGAAATATCTTCAGGAAGTGGAAAAGACATATTCCCCGGACACAGTCGGCTACGATCTTGTCCGTGATCTGATTTTAGTTCTCCGCGCGAAGAACTATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCATCGAAGGTACGTCGACGTCTGAACTTCGACAGCCCATATGTATCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCTAG |
|
Protein Sequence
|
MKFKLHGLFITWGPLNRLPHQVWIQNMWDPLLHEFPESVHGLRCMLAVKYLQEVEKTYSPDTVGYDLVRDLILVLRAKNYVEATSRYYHFNSRIEGTSTSELRQPICIPCSCPHCPRHKGKGLDKQADEQKT |
|
NCBI Accession
|
NP_852650.1
|
|
Location
|
286-1056 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCATCGAAGGTACGTCGACGTCTGAACTTCGACAGCCCATATGTATCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCTAGAATGTACAGGATGTACAGAAGTCCTGACGTGCCCAGGGGCTGTGAAGGCCCTTGTAAGGTTCAATCCTTCGAATCTAGGCACGATGTTTCTCATATTGGGAAGGTGATGTGCATCAGCGATGTTACACGAGGAACCGGACTCACACATCGCGTTGGGAAGCGATTTTGTGTGAAATCTGTTTACGTGTTGGGAAAAATATGGATGGACGAAAATATCAAGACTAAAAATCATACTAATAGCGTCATATTTTTTCTGGTTCGAGACCGTCGTCCTACAGGAACGCCACAGGATTTTGGGGAGGTTTTTAATATGTTCGACAATGAACCGAGCACTGCAACGGTGAAGAATATGCATCGTGATCGATATCAAGTGCTGCGCAAATGGCATGCTACTGTGACGGGAGGAACATACGCATCGAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTTGTCTACAATCAACAGGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCACGCATCGAACCCTGTATATGCAACTCTGAAAATCCGGATCTATTTTTATGATTCGGTAACAAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYVSRAVVPIARVTKGKAWTNRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVIFFLVRDRRPTGTPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGTYASREQALVRKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
NP_852651.1
|
|
Location
|
316-834 |
|
Gene Name
|
AC4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGCCATTTGCGCAGCACTTGATATCGATCACGATGCATATTCTTCACCGTTGCAGTGCTCGGTTCATTGTCGAACATATTAAAAACCTCCCCAAAATCCTGTGGCGTTCCTGTAGGACGACGGTCTCGAACCAGAAAAAATATGACGCTATTAGTATGATTTTTAGTCTTGATATTTTCGTCCATCCATATTTTTCCCAACACGTAAACAGATTTCACACAAAATCGCTTCCCAACGCGATGTGTGAGTCCGGTTCCTCGTGTAACATCGCTGATGCACATCACCTTCCCAATATGAGAAACATCGTGCCTAGATTCGAAGGATTGAACCTTACAAGGGCCTTCACAGCCCCTGGGCACGTCAGGACTTCTGTACATCCTGTACATTCTAGGTTTTCTGTTCATCGGCCTGTTTGTCCAGGCCTTTCCCTTTGTGACGCGGGCAATGGGGACAACTGCACGGGATACATATGGGCTGTCGAAGTTCAGACGTCGACGTACCTTCGATGCGGGAGTTGA |
|
Protein Sequence
|
MPFAQHLISITMHILHRCSARFIVEHIKNLPKILWRSCRTTVSNQKKYDAISMIFSLDIFVHPYFSQHVNRFHTKSLPNAMCESGSSCNIADAHHLPNMRNIVPRFEGLNLTRAFTAPGHVRTSVHPVHSRFSVHRPVCPGLSLCDAGNGDNCTGYIWAVEVQTSTYLRCGS |
|
NCBI Accession
|
NP_852652.1
|
|
Location
|
1053-1463 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGATCACGGATTCACGCACAGGGGAGTACATCACTGCGGATCGAGCAGAGAGTGGCGTCTTTATTTGGGAAATTCCAAATCCCCTGTATTTCAAAATATTGAAACACGACAGCCGACCCTTCATGACAGAACACGACATAATAGTGGTACAGATACTGTTCAACCACAACCTGAGGAAAGCGCTGGGACTTCACAAGTGTGCTCTAACTTTCCAAATCTGGACGGGCTTACGCCCTCCGATTGGGATTTTCTTGAGAGTCTTTAAAACCCAGGTCCTTAAGTACCTGGATATGTTAGGGGTGCTCTCTATTTACAATGTAATAAGATCTGTTTATCATGTTTTAGACAATGTATTGGAAAGAACAATTGATGTAAGAAGCTCGTATGATGTGAAAGTGAATATATATTAA |
|
Protein Sequence
|
MITDSRTGEYITADRAESGVFIWEIPNPLYFKILKHDSRPFMTEHDIIVVQILFNHNLRKALGLHKCALTFQIWTGLRPPIGIFLRVFKTQVLKYLDMLGVLSIYNVIRSVYHVLDNVLERTIDVRSSYDVKVNIY |
|
NCBI Accession
|
NP_852653.1
|
|
Location
|
1198-1602 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator |
|
Coding Region
|
ATGCAGTCTTCATCCAACTCGAAGAACCACTCTATTCCGGTCGCTCAAACAACGCTCCCACAGAAGAAGAAGAGGAACATCAGACGCAAACGGATTGATCTGCGGTGCGGATGCTCGTATTACATGTCAATAAACTGCCATGATCACGGATTCACGCACAGGGGAGTACATCACTGCGGATCGAGCAGAGAGTGGCGTCTTTATTTGGGAAATTCCAAATCCCCTGTATTTCAAAATATTGAAACACGACAGCCGACCCTTCATGACAGAACACGACATAATAGTGGTACAGATACTGTTCAACCACAACCTGAGGAAAGCGCTGGGACTTCACAAGTGTGCTCTAACTTTCCAAATCTGGACGGGCTTACGCCCTCCGATTGGGATTTTCTTGAGAGTCTTTAA |
|
Protein Sequence
|
MQSSSNSKNHSIPVAQTTLPQKKKRNIRRKRIDLRCGCSYYMSINCHDHGFTHRGVHHCGSSREWRLYLGNSKSPVFQNIETRQPTLHDRTRHNSGTDTVQPQPEESAGTSQVCSNFPNLDGLTPSDWDFLESL |
|
NCBI Accession
|
NP_852654.1
|
|
Location
|
1505-2590 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication initiation protein |
|
Coding Region
|
ATGCCACGAACAAACCAATTCCAAGTTAAGGCAAAAAATATATTTCTCACTTTCCCAAAATGCCCAATACCAAAAGAGCATATGCTCGAACTCCTTCGAAACATTTCATGTCCATCTGACAAATTATTTATCAGAGTATCACAAGAAAAACACCAAGATGGGTCTCTGCATATCCACGCGCTCATCCAATTCAAAGGTAAATGCCAGTTCAGAAACCCTAGACATTTCGATGTCACTCACCCTAATACCTCCACACAATACCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCCGATGTCAAGTCCTACATCGAGAAAGACGGTGATTACATTGACTGGGGTCAGTTTCAGATCGATGGACGATCTGCTAGAGGAGGTCAACAGACAGCAAATGATGCAGCAGCAGAGGCCCTAAACGCAGGTTCTAAAGAAGCAGCACTTAGTATAATAAGGGAAAAACTCCCAAAAGATTATATTTTCCAATTTCATAATTTGAATTCTAATTTAGATAGGATTTTTGCACCTCCTTTAGAGGTTTTTGTTTGTCCTTTTTTGTCTTCTTCATTCGATCAAGTTCCAGAGGAACTTGAGGTCTGGGTGTCTGAGAATGTAAGGGATGCCGCTGCGCGGCCGTGGAGACCCAAGAGTATTGTCATTGAGGGTGATAGTCGTACGGGCAAGACAATGTGGGCCAGGTCTTTAGGCCCACACAATTATCTATGCGGTCATCTGGATCTGAGCCCGAGAGTGTACAATAATGAAGCTTGGTACAACGTCATTGATGACGTCGACCCGCACTACCTAAAGCATTTTAAAGAATTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACGAAATACGGAAAGCCAGTCATGATTAAAGGTGGAATACCCACTATCTTCCTCTGCAATAAAGGACCAAATAGCAGCTATAAAGAATATCTGGACGAAGAAAAAAATTCAGCACTAAAACAGTGGGCAATAAAGAATGCAGTCTTCATCCAACTCGAAGAACCACTCTATTCCGGTCGCTCAAACAACGCTCCCACAGAAGAAGAAGAGGAACATCAGACGCAAACGGATTGA |
|
Protein Sequence
|
MPRTNQFQVKAKNIFLTFPKCPIPKEHMLELLRNISCPSDKLFIRVSQEKHQDGSLHIHALIQFKGKCQFRNPRHFDVTHPNTSTQYHPNFQGAKSSSDVKSYIEKDGDYIDWGQFQIDGRSARGGQQTANDAAAEALNAGSKEAALSIIREKLPKDYIFQFHNLNSNLDRIFAPPLEVFVCPFLSSSFDQVPEELEVWVSENVRDAAARPWRPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYNNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVMIKGGIPTIFLCNKGPNSSYKEYLDEEKNSALKQWAIKNAVFIQLEEPLYSGRSNNAPTEEEEEHQTQTD |
|
NCBI Accession
|
NP_852655.1
|
|
Location
|
477-1283 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGCCTTTTCACTCCCCCTATTCTATGTCCAAACGTTTTTCGTTTGCAGGGAACAGACCTCACAACCCGGTCAAGAGATGGAGATCATGGAAACCACGGAAATTCCATGGATTGAATCGGTATCGTAATATCTGTTCCGCCGGCAGAACACCAACAGAACTGTTTGGGGATCAGATCTCCAAACAATATACGCGTAAGGAAATTTCTGAAACTCAGCAGGGTTCCGAATATGTTCTTCATAACAACCGTTACATTACTTCCTATGTGACATATCCTGCTAAGACAAGAACCGGAACGAACAACCGAGTTCGTTCTTATATCAAGCTTACGGGACTTAGCTTATCTGGAACATTTGGCATACGAACTTCGGACGTGATGCGCGATGTCGATCAAACTGGTGGATTATATGGCGTGATGTCTGTGGTTATAGTCCGAGATAAATCACCGAAGATTTATTCTACAGCACAACCACTCATGCCGTTTGTGGATTTATTTGGTTCTGTTAATGCATGTCGTGGGATTCTGAAGGTGGCAGAACGCCACCGAGAAAGGTTCGTGGTGCTGAATCAATCATCCATATTGATCAACACGCCTCATTGCAATACAATGAAGAAATTCTCCATTCGTAACTGCATACCACGTACCTACTCTACCTGGGTTAATTTCAAAGACGAAGAAGATGACAGTTGTACTGGTCTCTACTCAAATACTCTCCGGAATGCTATTCTTATTTATTATGTGTGGTTAAGCGATGTACGTTCACAAGTTGATTTATACAGCAATGTAATACTTAATTACATTGGTTAG |
|
Protein Sequence
|
MPFHSPYSMSKRFSFAGNRPHNPVKRWRSWKPRKFHGLNRYRNICSAGRTPTELFGDQISKQYTRKEISETQQGSEYVLHNNRYITSYVTYPAKTRTGTNNRVRSYIKLTGLSLSGTFGIRTSDVMRDVDQTGGLYGVMSVVIVRDKSPKIYSTAQPLMPFVDLFGSVNACRGILKVAERHRERFVVLNQSSILINTPHCNTMKKFSIRNCIPRTYSTWVNFKDEEDDSCTGLYSNTLRNAILIYYVWLSDVRSQVDLYSNVILNYIG |
|
NCBI Accession
|
NP_852656.1
|
|
Location
|
1332-2177 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGTCCATAGGCAATGATAAAATGGTGATGGGCGTTGGAGGCTATATACAGTCAAATCGCGTTGAATACGCTCTGACAAACGACGCTTCAGAGGTAACTTTGACGTTCCCTTCAATCTTCGAACAGAAAATCAGCCAGCTGAGAAACAGATGCATGAAAATCGATCATGTTGTACTGGAATATAGAAGCCAGGTGCCAATAAATGCTGTGGGGCATGTCGTTATCGAAATACACGACATTGAGATTGACCGAGGGTACACAAAACAAGCAGAATTCACAATTCCAATAAAGTGCAATTGCAACTTACACTACTATTCATCCACATACTTCTCCGTTAAGGATAACAATCCTTGGAGAGTGGAATACAGAGTGGAGAACACAAACGTCGTCAATGGTGTTCATTTTTGTAAGATCTTAGGCAAATTGAAATTATCGTCGGCAAAACATTCGACTCACGTCGAATTCCGACCACCAAGAATAGAGATACAGAGCAAGGAGTTCACTGTCAACGACATAGATTTCTGGTCCGTGGGATCGAAAGCACAAAGCCGGAGACTAGTAGACGGTTCAAAACTAATGGGTCATAGTTCCAGATCCTTACGAGTCCCACATCTAGCGATTGGGCCGAATGAATCGTGGGCAAGTAGATCCGAGGTTGGACAGACATCGGTGTGCAGTAGACCATACAAAAACCTAAGCGGATTAGACGAATCCGCAATAGATCCAGGCCCGTCGGCTTCACAGGTGGGAAGCATAACCAGGGACGAAATAACAGAAATAATAACTAAAACGGTCGAACAATGTATGAAATCTAATGTAAATGCTCCATTAATAAAGGGCGTATGA |
|
Protein Sequence
|
MSIGNDKMVMGVGGYIQSNRVEYALTNDASEVTLTFPSIFEQKISQLRNRCMKIDHVVLEYRSQVPINAVGHVVIEIHDIEIDRGYTKQAEFTIPIKCNCNLHYYSSTYFSVKDNNPWRVEYRVENTNVVNGVHFCKILGKLKLSSAKHSTHVEFRPPRIEIQSKEFTVNDIDFWSVGSKAQSRRLVDGSKLMGHSSRSLRVPHLAIGPNESWASRSEVGQTSVCSRPYKNLSGLDESAIDPGPSASQVGSITRDEITEIITKTVEQCMKSNVNAPLIKGV |