Lisianthus enation leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001806215.1 |
| Isolate |
Taiwan |
| Release date |
2016/10/21 |
| Submitter |
Chen,Y.K., Chao,H.Y., Chen,Y., Chao,H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
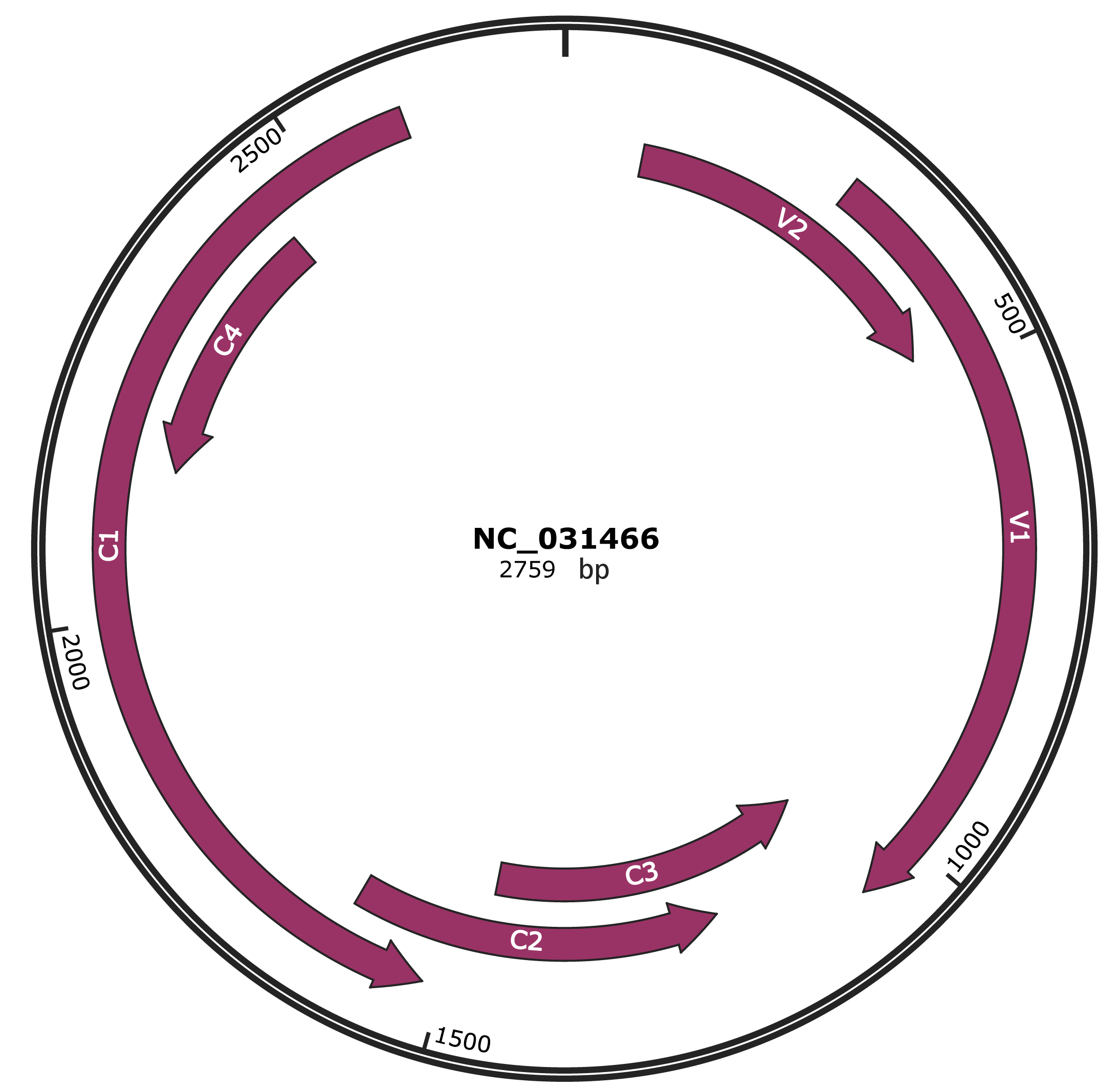
JBrowse
Genome
ACCGGATGGCCGCGAATGTTTTTGAAGTGGTCCCCTTGATGTGATGTTTCATCCAATTAAAACGCTCGGCGAAAGCTTAATTATTTATGGTCCCCTATTTAAGACTTAGTCACCAAGTTTCTGCGAAATGCAAAATGTGGGATCCACTCCTAAACGAATTTCCGGAAAGCGTCCACGGTTTCCGTTGTATGTTAGCGGTTAAGTATCTGCAAGCGGTCGAGAAGACGTATTCACCCGATACCCTAGGGTTTGATCTCATCCGTGATCTCATCGGTGTAATTCGTGCGAAGAACTATGTCGAAGCGTCCAGCAGATATTCTCATTTCCACGCCCGTCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCATACAACAGCCGTGCTGCTGTCCCCACTGTCCGCGTCACAAAAGGGCAGATATGGAAGAACCGACCTGCATACAGAAAGCCCAGGTTCTACAGAATGTATAGAAGTCCTGATGTCCCTAAGGGATGTGAGGGTCCATGTAAAGTGCAATCTTTCGATGCGAAGAACGACATTGGTCATATGGGCAAGGTAATCTGTCTGTCTGACGTTACCCGTGGTATGGGGCTTACTCATCGAGTTGGCAAGCGTTTCTGTGTCAAGTCACTTTATTTTGTCGGGAAGATCTGGATGGATGAAAATATTAAGGTTAAGAATCACACTAATACCGTTTTATTTTGGATAGTTAGGGATCGGCGTCCTACTGGAACGCCTAATGATTTTCAGCAGGTCTTTAATGTATATGATAATGAACCCAGCACTGCTACTGTAAAGAACGACCAGCGTGATCGTTTCCAGGTTATAAGGAGGTTTCAGGCAACGGTGACTGGTGGACAATATGCAGCTAAGGAGCAGGCGATTATTAGAAAGTTTTATCGTGTTAATAATTATGTAGTTTACAATCACCAGGAAGCTGGGAAGTACGAGAACCATACTGAAAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAGTCAGAAGTTATTTCTATGACTCAGTGACGAATTAATAAATATTAAATTTTATATCGTGTTTTTCAATTACATCACTTGTTCCTTCTAATACATTGTACAGTACATGAGACATTGCCCTAATTACATTATTAATACTAATCACGCCTAATCTATCTAAATATTTAATACATTGATATTTAAATACTCTTAAGAAACGCCAAGTCTGAGGATGTAAATGAGTCCAGATCTGGAAGTTCAGAAAACATTGATGCATCCCCAACGCTTTCCTCAGGTTGTGATTGAACCTGATCTGGATTGTTATTATGTCGTGGTTCATCAGGAATGGTCTCTCGTGGTGTTGGGTTATCTTGAAATAGAGGGGATTTGGTACCGTCCAGATATATACGCCATTCTCTGCTTGAGCTGCAGTGATGGGATCCCCTGTGCGTGAATCCATGATTGTGGCAGTTAATGGATACAAAGTATGTGCACCCGCAAGGAAGATCAACTCTACGCCTGCGAATTGATTTCCTCTTCGCAATTCTGTGTTGGACTTTGATGGGTACCTGAGTACAATGGTTGTGTGATGGTGATGAATTCTGCATTCTTTAATGACCAGTCTTTGAGTGCAGAATTTTTATCCTCATCCAAGTACTCTTTGTATGATGACGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGCTTCCCGTACTTTGTGTTGCTTTGCCAGTCCCTTTGTGCCCCCATAAATTCTTTAAAATGCTTTAGGTAGTGGGGGTCGACGTCATCAATGACGTTGTACCAGGCATCATTACTGTAGACTTTTGGGCTCAGGTCCAGATGTCCACATAAATAATTGTGTGGGCCTAAAGACCTGGCCCACATTGTCTTCCCTGTACGACTCTCGCCCTCTATGACAATACTTTTAGGTCTCCATGGCCGCGCAGCGGCACCAACAACATTCTCAGCCGCCCACTCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGAAGAAAAAGGAGAAATAAAAACCTCCAAAGGAGGAGCAAAAATCCTATCTAAATTGGCATTTAAATTATGAAATTGTAAAACAAAATCTTTGGGCGCTAATTCTTTGATTACATTAAGAGCCTCTGACTTACTTCCTGCGTTAAGCGCTTGGGCGTAAGCGTCGTTGGCTGATTGTTGTCCTCCTCTTGCAGATCTACCGTCGATCTGAAACTCTCCCCATTCGAAGGTGTCTCCGTCCTTGTCCAAATAGGACTTGACGTCCGAGCTCGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTTGTTGGGGATACCAAATCGAAGAATCGTTGATTCGTGCATCTGAATTTCCCCTCGAATTGGATAAGCACGTGGAGATGAGGGCTCCCATCTTCGTGTAGTTCTCTACAGACTTTGATGAACTTCTTGTTAGTTGCGGTGTCTAGGGCTTTTATTTGGTCAAGGGTTTCCTCTTTTGTAAGCGAACAGTGTGGATAAGTTAGGAAATAATTTTTGGCATTTATTTGGAATTTTCTGGGTGGTGCCATTTGACTTGGTCAATGGGTACCCAATGAGAGGATTTCATAATGCTCTGGGTATCGGTGCATTGGTACCCTTATATACTCGGTTACCTAATGGCATTATCGTAATTCTCAAAATTAAATTCAAATTTCGAATTTGTAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009310414.1
|
|
Location
|
87-473 |
|
Gene Name
|
V2 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGTCCCCTATTTAAGACTTAGTCACCAAGTTTCTGCGAAATGCAAAATGTGGGATCCACTCCTAAACGAATTTCCGGAAAGCGTCCACGGTTTCCGTTGTATGTTAGCGGTTAAGTATCTGCAAGCGGTCGAGAAGACGTATTCACCCGATACCCTAGGGTTTGATCTCATCCGTGATCTCATCGGTGTAATTCGTGCGAAGAACTATGTCGAAGCGTCCAGCAGATATTCTCATTTCCACGCCCGTCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCATACAACAGCCGTGCTGCTGTCCCCACTGTCCGCGTCACAAAAGGGCAGATATGGAAGAACCGACCTGCATACAGAAAGCCCAGGTTCTACAGAATGTATAG |
|
Protein Sequence
|
MVPYLRLSHQVSAKCKMWDPLLNEFPESVHGFRCMLAVKYLQAVEKTYSPDTLGFDLIRDLIGVIRAKNYVEASSRYSHFHARLESTSPSELRQPIQQPCCCPHCPRHKRADMEEPTCIQKAQVLQNV |
|
NCBI Accession
|
YP_009310415.1
|
|
Location
|
295-1065 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCAGCAGATATTCTCATTTCCACGCCCGTCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCATACAACAGCCGTGCTGCTGTCCCCACTGTCCGCGTCACAAAAGGGCAGATATGGAAGAACCGACCTGCATACAGAAAGCCCAGGTTCTACAGAATGTATAGAAGTCCTGATGTCCCTAAGGGATGTGAGGGTCCATGTAAAGTGCAATCTTTCGATGCGAAGAACGACATTGGTCATATGGGCAAGGTAATCTGTCTGTCTGACGTTACCCGTGGTATGGGGCTTACTCATCGAGTTGGCAAGCGTTTCTGTGTCAAGTCACTTTATTTTGTCGGGAAGATCTGGATGGATGAAAATATTAAGGTTAAGAATCACACTAATACCGTTTTATTTTGGATAGTTAGGGATCGGCGTCCTACTGGAACGCCTAATGATTTTCAGCAGGTCTTTAATGTATATGATAATGAACCCAGCACTGCTACTGTAAAGAACGACCAGCGTGATCGTTTCCAGGTTATAAGGAGGTTTCAGGCAACGGTGACTGGTGGACAATATGCAGCTAAGGAGCAGGCGATTATTAGAAAGTTTTATCGTGTTAATAATTATGTAGTTTACAATCACCAGGAAGCTGGGAAGTACGAGAACCATACTGAAAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAGTCAGAAGTTATTTCTATGACTCAGTGACGAATTAA |
|
Protein Sequence
|
MSKRPADILISTPVSKVRRRLNFDSPYNSRAAVPTVRVTKGQIWKNRPAYRKPRFYRMYRSPDVPKGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGMGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVLFWIVRDRRPTGTPNDFQQVFNVYDNEPSTATVKNDQRDRFQVIRRFQATVTGGQYAAKEQAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_009310416.1
|
|
Location
|
1062-1466 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGATCCCATCACTGCAGCTCAAGCAGAGAATGGCGTATATATCTGGACGGTACCAAATCCCCTCTATTTCAAGATAACCCAACACCACGAGAGACCATTCCTGATGAACCACGACATAATAACAATCCAGATCAGGTTCAATCACAACCTGAGGAAAGCGTTGGGGATGCATCAATGTTTTCTGAACTTCCAGATCTGGACTCATTTACATCCTCAGACTTGGCGTTTCTTAAGAGTATTTAAATATCAATGTATTAAATATTTAGATAGATTAGGCGTGATTAGTATTAATAATGTAATTAGGGCAATGTCTCATGTACTGTACAATGTATTAGAAGGAACAAGTGATGTAATTGAAAAACACGATATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDSRTGDPITAAQAENGVYIWTVPNPLYFKITQHHERPFLMNHDIITIQIRFNHNLRKALGMHQCFLNFQIWTHLHPQTWRFLRVFKYQCIKYLDRLGVISINNVIRAMSHVLYNVLEGTSDVIEKHDIKFNIY |
|
NCBI Accession
|
YP_009310417.1
|
|
Location
|
1207-1614 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAGAATTCATCACCATCACACAACCATTGTACTCAGGTACCCATCAAAGTCCAACACAGAATTGCGAAGAGGAAATCAATTCGCAGGCGTAGAGTTGATCTTCCTTGCGGGTGCACATACTTTGTATCCATTAACTGCCACAATCATGGATTCACGCACAGGGGATCCCATCACTGCAGCTCAAGCAGAGAATGGCGTATATATCTGGACGGTACCAAATCCCCTCTATTTCAAGATAACCCAACACCACGAGAGACCATTCCTGATGAACCACGACATAATAACAATCCAGATCAGGTTCAATCACAACCTGAGGAAAGCGTTGGGGATGCATCAATGTTTTCTGAACTTCCAGATCTGGACTCATTTACATCCTCAGACTTGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSPSHNHCTQVPIKVQHRIAKRKSIRRRRVDLPCGCTYFVSINCHNHGFTHRGSHHCSSSREWRIYLDGTKSPLFQDNPTPRETIPDEPRHNNNPDQVQSQPEESVGDASMFSELPDLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_009310418.1
|
|
Location
|
1520-2602 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCACCACCCAGAAAATTCCAAATAAATGCCAAAAATTATTTCCTAACTTATCCACACTGTTCGCTTACAAAAGAGGAAACCCTTGACCAAATAAAAGCCCTAGACACCGCAACTAACAAGAAGTTCATCAAAGTCTGTAGAGAACTACACGAAGATGGGAGCCCTCATCTCCACGTGCTTATCCAATTCGAGGGGAAATTCAGATGCACGAATCAACGATTCTTCGATTTGGTATCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCGAGCTCGGACGTCAAGTCCTATTTGGACAAGGACGGAGACACCTTCGAATGGGGAGAGTTTCAGATCGACGGTAGATCTGCAAGAGGAGGACAACAATCAGCCAACGACGCTTACGCCCAAGCGCTTAACGCAGGAAGTAAGTCAGAGGCTCTTAATGTAATCAAAGAATTAGCGCCCAAAGATTTTGTTTTACAATTTCATAATTTAAATGCCAATTTAGATAGGATTTTTGCTCCTCCTTTGGAGGTTTTTATTTCTCCTTTTTCTTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCGGCTGAGAATGTTGTTGGTGCCGCTGCGCGGCCATGGAGACCTAAAAGTATTGTCATAGAGGGCGAGAGTCGTACAGGGAAGACAATGTGGGCCAGGTCTTTAGGCCCACACAATTATTTATGTGGACATCTGGACCTGAGCCCAAAAGTCTACAGTAATGATGCCTGGTACAACGTCATTGATGACGTCGACCCCCACTACCTAAAGCATTTTAAAGAATTTATGGGGGCACAAAGGGACTGGCAAAGCAACACAAAGTACGGGAAGCCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCAACGTCATCATACAAAGAGTACTTGGATGAGGATAAAAATTCTGCACTCAAAGACTGGTCATTAAAGAATGCAGAATTCATCACCATCACACAACCATTGTACTCAGGTACCCATCAAAGTCCAACACAGAATTGCGAAGAGGAAATCAATTCGCAGGCGTAG |
|
Protein Sequence
|
MAPPRKFQINAKNYFLTYPHCSLTKEETLDQIKALDTATNKKFIKVCRELHEDGSPHLHVLIQFEGKFRCTNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYLDKDGDTFEWGEFQIDGRSARGGQQSANDAYAQALNAGSKSEALNVIKELAPKDFVLQFHNLNANLDRIFAPPLEVFISPFSSSSFDQVPEELEEWAAENVVGAAARPWRPKSIVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNSALKDWSLKNAEFITITQPLYSGTHQSPTQNCEEEINSQA |
|
NCBI Accession
|
YP_009310419.1
|
|
Location
|
2155-2445 |
|
Gene Name
|
C4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGCTTATCCAATTCGAGGGGAAATTCAGATGCACGAATCAACGATTCTTCGATTTGGTATCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCGAGCTCGGACGTCAAGTCCTATTTGGACAAGGACGGAGACACCTTCGAATGGGGAGAGTTTCAGATCGACGGTAGATCTGCAAGAGGAGGACAACAATCAGCCAACGACGCTTACGCCCAAGCGCTTAACGCAGGAAGTAAGTCAGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGALISTCLSNSRGNSDARINDSSIWYPQQGQHISIQTFRELNRARTSSPIWTRTETPSNGESFRSTVDLQEEDNNQPTTLTPKRLTQEVSQRLLM |