Kudzu mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000870965.1 |
| Isolate |
Viet Nam: Hoabinh |
| Release date |
2015/2/13 |
| Submitter |
Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
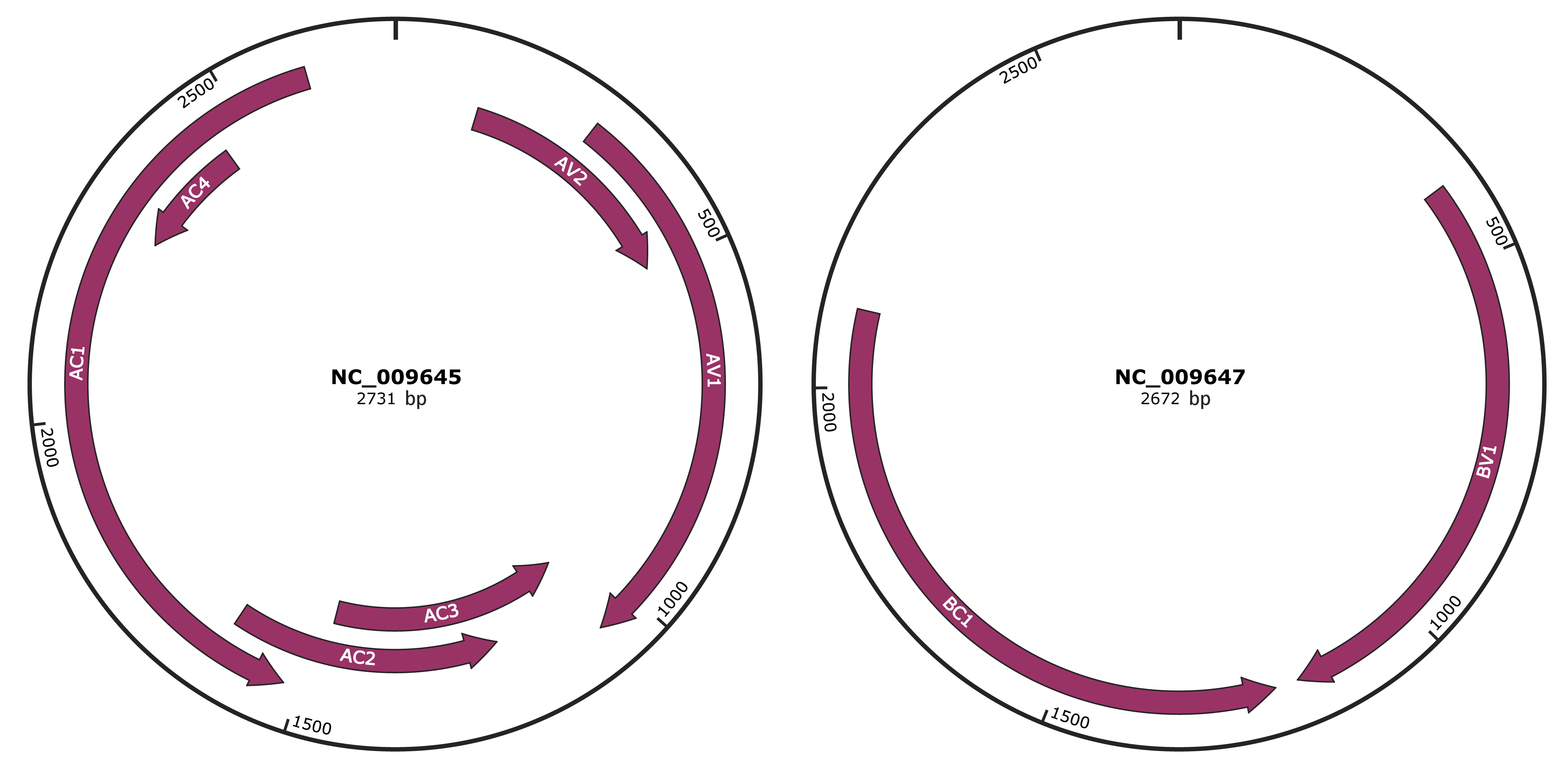
JBrowse
Genome
ACCGGATGGCCGCGCTTCGGTGTCCCTCAAATCCCCTGACGTGGCGTTCTATGGCGCCTCGCACATGGCTTAGATAATTTGAAATTTGAATTATAAACGTGCGCTCTAAGGCGCCTTTGCTTTAAACATGTGGGATCCTTTGTTGAACGCCTTTCCGGACAGGTTGCATGGATTCCGCTGCATGTTAGCAGTGAAGTACTTGCACTTAGTGCTGCCAACATATCCCGAGAATACCGTAGGGTATTGGTTTTTGCGTGATTTGATACAGGTATTACGCTCCAAGGATCATGACAAAGCGGAATTTCGAGACGGCGTTCTCAAGTCCGATATCCTCGGCACGGCGGAGACTGAGCTACGGAACCCCGTTAGCGTTGCCTGCACCTGCTGCCAGTGCCCAAGGCACCCGAAGACGACGATCATGGACAAACCGTCCGATGTACAGGAAGCCTCGTCTGTATCGTATGTATCGAAGCCCAGACGTCCCCCGCGGTTGTGAGGGCCCTTGTAAGGTTCAATCTTTTGAACAAAGGCATGATATTTCTCATGTGGGGAAAGTACTTTGTGTTTCTGACGTCACTCGTGGTGGTGGTATCACTCACCGAGTTGGCAAGCGTTTTTGCATTAAGTCTATCTATGTTTCAGGTAAAGTTTGGGTGGATGAAAACATCAAGCTCAAGAATCACACCAACAGTGTGCTATTCTGGTTGACTCGTGATAGGCGACCTTTTGGTACGCCAATGGATTTTGGTCAAGTTTTTAACATGTATGACAATGAGCCTAGTACTGCCACCGTGAAGAACGACCTACGTGATCGTTACCAGGTCCTGCATCGATGGAATGCCACCGTTACTGGTGGCCAATATGCCTGTAAGGAACAGGCGTTAATTAGGCGTTTTTATAAAGTTTATAATCATGTTGTGTATAATCATCAGGAAGCTGCAAAGTATGAAAACCATACTGAGAATGCTCTGTTGTTGTATATGGCATGTACTCATGCATCAAACCCAGTGTACGCAACATTGAAGATACGGATCTATTTTTACGATTCGATATCAAATTAATAAAGCTTGTATTGCACATTATGCTTGAGCGTTACATCATCAACATGTTCAAATACAGTAAACAATACATGCGAACACGCTTTTAATACAGTCGATAGACTAATAACTCCTAAATTATTAATATAACGTAATAATTGGTTCTTAAAAGTCGAGCAAATCCGCCCACTCGGCTGTATGAAACGATGGTAAATCGTCAAGTCCAGGAAGGCCTTGTGTATCCCCAACGCTTTCTTCAGAGAGTGGTTGAACATTATGCGGATTGTTGTCCGGAACTTTGGCCACTGGATGAGGTTGTGGTACCATACTCTGTCGTGGTCCATGATCTTGAAACTCAGGGGATTTGCTACCTCCCAAGTAAAGACGCCATTCTCTAGCTGAGCTGCAGTGATGCTCACCCCTGTGCGTAAATCCATGGTTGTAGCAGTTGATGTGTAGGTAGTAACTACACCCACACTTCAGGTCAATTCGTCTGCGTCGAATTGCACGTTTCTTGGCCAACCTGTGTTGCGCCTTGATTGGTGGTGGAGAACAGGGGTTCTGTGAGCGTGTAGAAGATAGCATTTTTTAAAGCCCACTCTTTGAGACTCGCATTATTCTCTTCGTCGAGGAACATTTTATAAGAGGATCTGGGTCCCGCATTACAGAGAAAGATGGTGGGGATGCCACCTTTAATTTGAGTGGGCTTTCCGTATTTCACGTTGCTTTGCCAGTCCTTTTGCGCGCCCATGAATTCTTTGAAATGTTTCAGATAATGCGGATCGACGTCATCGATTACGTTGTACCACGCATCATTTGAATAAACTTTGGCGCTTAGATCCAAATGGCCGCACAAATAATTGTGCCGACCGAGCGACCTCGCCCACATGGTTTTACCCGTACGTGACTCACCCTCAACCACTATACTAATAGGTCTGAATGGCCGCGCAGCGGGGCACACCACGTTTTCAGCTGCCCATGACGTCAATGTCTCAGGGACATTATTGAATGATTCAATACTGAATGGTGTTTCATACACTGTTGGCGGTGGTGCAAAAAGAAAGTTCAGATTGGCTCTGATATTGTGCAAATGGATTATGAAGTCTCTCGACGCTTTCTCCTTCAATATATTGAGGGCCGATGTTGTATCGCCTGAATTGATTGCTTCGGCATATGCGTCATTTGCACATTGAGAACCTCCTCTATTTGATCTCCCGTCGATCTGGAAAATTCCAAAATCTATGACGTCTCCGTCTTTCTCCATGTACTTTTTAACATCTGAGCTGCTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTTCGGATACGAGGTCGAAGAACCTTTCGTTGCGGCACTGGAATTTTCCTTCAAATTGAAGCAGAACATGGAGGTGAGGTTCCCCATTTTCATGGAACTCACGACAAACTCTGATGAATTTCTTGTTGACGTTAGTCTGAATATTCTGTAGCTGCTCTAGTGCTGCTTCTTTAGAGAGAGAACACCTTGGGTATGTGAGGAAGAAGTTTTTGGCATTAACCCGAAAACCCTTTGGTCTAGACATTATGTGAAGAGTTTCTCTCTCTTGACACCAATTGGGGTCGATTCATTTATCGCCCTAGTATTAGTGTCGCATATATAGTAGTGACACCAATGACGTGGAAAGCGGCCATCCGAATAATATT
ACCAGGACGCGCCCGGTGCCTTTGGTGCGGTGTGGTCCCCCCGCCCATGTGCTTTCAATCTCGTCCGCACGTTTTTTTTAGTCTTCGCGCGTGGTGTGAATGCGCCGTAATGCGCTTGCCGCAAATAACGTTATAACTGCTTTAATTTGAATTTCTTTAAATTATGTGGAATACCTGAAACACCCTTTGGTGTTATATGTATAACAGCTATACGTGCACTATGATTGTGCATATAGTAATTGTTATCAACCAATTACATTTCAACCGTTCAGGATTTTATTTTAAGCTATTTGCTACGATTTGTATGTGAGTGTTATTATAAACATGGTCTGTCCCTATAAAAGGGATTATGTTGATATTATATAACATGTGAAAGAAAATATACTTATTTTCAATGTTAGCCATGTTTACCCCTCGAGCAACCCCCCGTAATTATCCCCGTCGTGTCAGTGGGCAATTTAAGCGTAAATTACGCCCATACAATGGGGGTCTTAACACGTATCGTAAACTGCGTGTTGCTCGCAAGTTATCCTACGATCCATCTGTCCGTCCGTTCTCTATAAATACACTAGTTGAACGGCAACATGGTTCACATATGACCCTTGGAAGTAATTCGGATATTACTTCATTTGTTGAATATCCAGTTCGTGGTATTAATGGCGATGGTCGTTCAAGGGATTACATCAAATTGCTTCATTTATCAGCCTCAGGCGTTATTAACGTTAAGGTTGCCTCTTCGGATCAAGTAATGGATGGTGGTTCTCGTCACAACGGCGTATTTGTTATGTGTTTACTTCAGGACATGAAGCCGTTTTTACCTGACGGCGTCAATAGCTTGCCAACGTATGCCGAGTTATTCGGGCCTTATTCGTCTGCTTATGTTAATATGCATTTGTTGGATAGCCATAAACAGCGTTTTAGGATTTTAGGTAGCGTAAAAAAATTTGTAAGTTGTGGTTTGGATGCGGTAGACATCCCTTTCAAGTTAGACCTTAAGCTATCCAACGGGAGGTATCCATTGTGGGCGTCATTTAAAGACGCTGAAGAGGGTAATTGTGGGGGCAATTATAGAAATATTGCCAAAAATGCAATAATTGTAAGCTATGCATTTGTTTCATTGCATAGCCTTAAGTGTGAACCATTTGTACAATTTGAACTCCGTTACATGGGATAATAAAATGATGTTATTCATTTTGTGTGTTTAATTACAATGGTTTGGATACATTTGATCTCTGCGTAACCAAACACCTGTTAATGGTTGTTTCGATAATGCTCTCGATGTCCGCTCTTGTAACCGGATTGGTTTGCGCCTGTGAGACTGAGTCTCCCGGGTCTAATGACGACTCAGGTAATTTGTGCATGTGTTTTAGAGGAAATTCTGCGTCGGACGAGATTGTCCTGTGCTCAAGGCCCATTATATTGTTGTCTGGATACCGCATTGACGTGCTGCGTCCAATTGTGGACCGTGTGGCCCATGTCTCCCCAGGCTGTAATAACATGGGCCTTTGGCGCTGTAGCCCATCAGGACCACATCCTGGCGTTGGTGTTAATAGTCTTCTGATGGGTTTGGGCCTCTCGACAGACCAAAAGTCCACGCAATCCGCTGTGTAGTCTTTGGACAATATTTTTATTGTTGGCGGTTTGTATTTAATGTCTGTCGAATGTTTTGCCGCCGATAACTTCAACTTGCCCTTTATTTGGGCAAATGCTGTGCCGTCGTTGACGTTTGAGTCTTCTACTTTGTATAGAAGCTCCCATGGCGTCTCATCTTTGATGGAGAAAAATGAGGATGAAAAGTAATGCAGATCTACGTTACATCCAATGGGGAATGTGAAAGCTGCCTGTGCAGCCTGATCATCGCTTAATCTTGTGTCACGTATAGTGACGATGACACTTCCAGTTGCATTGTAAGGTACTTGGTTACGATACTCAATTACTATATGGTCAACCTTCATGCATTTTCCCAGCATTTTAACTGCTGCTTGTTCTATTGACGACGGAAATTGAAGAGTAATTGGAGTTTCGTTGTTTGTCAGACGGTATTCGCATCGCTTTGATTGAATATACTTGTTTGTGACCAGTGCTCCAGAGTATGTCTCCATGTGTAACACACACCCGTCTACAACTGAATAGTATAATGCGATTTTTGTTGACCTTGATCCTGCAAATATAAACTAATAATTTATTCTTAGTTGGCCGCGCAGCGGCATCATTCGGAGATTTATACTCCGATACAAGGCTAATTGCAATAAACAAAATAATGTGCACAACAAGTAGCTTCTTGACTATATGGCAACTGGAGAGCTGTTGCATGCTATGCAAAATAAGCAACTTAAAAACAAACCTGAATAGAGCAATATTCAGATACAAGTGTGGTTATCTTGCTTGGTAGAAGATTTTCAGTTCTCAAAATATTTTATAGTAAAAAAGTTAACTTAGGATCCATCCCTTATGCTTAAATAAGGGTATTCTTATTTAAGCCAGAAGCAAAGGCCTTGATAGTGTTGCAGCTGTTGGAATTCTAGAGAGAAGTTGGAGTTTCTCTCTCTAGCGACACCGATTGGGGTCAAATTCATTTATCCCCTAGTATTAGTGTCGCATATATACTTGTGACACCGATCTACGTGGCAGCTGATGTCATTCCCCCGACACGCGCGTCCTGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_001333676.1
|
|
Location
|
128-496 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCTTTGTTGAACGCCTTTCCGGACAGGTTGCATGGATTCCGCTGCATGTTAGCAGTGAAGTACTTGCACTTAGTGCTGCCAACATATCCCGAGAATACCGTAGGGTATTGGTTTTTGCGTGATTTGATACAGGTATTACGCTCCAAGGATCATGACAAAGCGGAATTTCGAGACGGCGTTCTCAAGTCCGATATCCTCGGCACGGCGGAGACTGAGCTACGGAACCCCGTTAGCGTTGCCTGCACCTGCTGCCAGTGCCCAAGGCACCCGAAGACGACGATCATGGACAAACCGTCCGATGTACAGGAAGCCTCGTCTGTATCGTATGTATCGAAGCCCAGACGTCCCCCGCGGTTGTGA |
|
Protein Sequence
|
MWDPLLNAFPDRLHGFRCMLAVKYLHLVLPTYPENTVGYWFLRDLIQVLRSKDHDKAEFRDGVLKSDILGTAETELRNPVSVACTCCQCPRHPKTTIMDKPSDVQEASSVSYVSKPRRPPRL |
|
NCBI Accession
|
YP_001333677.1
|
|
Location
|
288-1061 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGACAAAGCGGAATTTCGAGACGGCGTTCTCAAGTCCGATATCCTCGGCACGGCGGAGACTGAGCTACGGAACCCCGTTAGCGTTGCCTGCACCTGCTGCCAGTGCCCAAGGCACCCGAAGACGACGATCATGGACAAACCGTCCGATGTACAGGAAGCCTCGTCTGTATCGTATGTATCGAAGCCCAGACGTCCCCCGCGGTTGTGAGGGCCCTTGTAAGGTTCAATCTTTTGAACAAAGGCATGATATTTCTCATGTGGGGAAAGTACTTTGTGTTTCTGACGTCACTCGTGGTGGTGGTATCACTCACCGAGTTGGCAAGCGTTTTTGCATTAAGTCTATCTATGTTTCAGGTAAAGTTTGGGTGGATGAAAACATCAAGCTCAAGAATCACACCAACAGTGTGCTATTCTGGTTGACTCGTGATAGGCGACCTTTTGGTACGCCAATGGATTTTGGTCAAGTTTTTAACATGTATGACAATGAGCCTAGTACTGCCACCGTGAAGAACGACCTACGTGATCGTTACCAGGTCCTGCATCGATGGAATGCCACCGTTACTGGTGGCCAATATGCCTGTAAGGAACAGGCGTTAATTAGGCGTTTTTATAAAGTTTATAATCATGTTGTGTATAATCATCAGGAAGCTGCAAAGTATGAAAACCATACTGAGAATGCTCTGTTGTTGTATATGGCATGTACTCATGCATCAAACCCAGTGTACGCAACATTGAAGATACGGATCTATTTTTACGATTCGATATCAAATTAA |
|
Protein Sequence
|
MTKRNFETAFSSPISSARRRLSYGTPLALPAPAASAQGTRRRRSWTNRPMYRKPRLYRMYRSPDVPRGCEGPCKVQSFEQRHDISHVGKVLCVSDVTRGGGITHRVGKRFCIKSIYVSGKVWVDENIKLKNHTNSVLFWLTRDRRPFGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVLHRWNATVTGGQYACKEQALIRRFYKVYNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_001333678.1
|
|
Location
|
1058-1474 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGTGAGCATCACTGCAGCTCAGCTAGAGAATGGCGTCTTTACTTGGGAGGTAGCAAATCCCCTGAGTTTCAAGATCATGGACCACGACAGAGTATGGTACCACAACCTCATCCAGTGGCCAAAGTTCCGGACAACAATCCGCATAATGTTCAACCACTCTCTGAAGAAAGCGTTGGGGATACACAAGGCCTTCCTGGACTTGACGATTTACCATCGTTTCATACAGCCGAGTGGGCGGATTTGCTCGACTTTTAAGAACCAATTATTACGTTATATTAATAATTTAGGAGTTATTAGTCTATCGACTGTATTAAAAGCGTGTTCGCATGTATTGTTTACTGTATTTGAACATGTTGATGATGTAACGCTCAAGCATAATGTGCAATACAAGCTTTATTAA |
|
Protein Sequence
|
MDLRTGVSITAAQLENGVFTWEVANPLSFKIMDHDRVWYHNLIQWPKFRTTIRIMFNHSLKKALGIHKAFLDLTIYHRFIQPSGRICSTFKNQLLRYINNLGVISLSTVLKACSHVLFTVFEHVDDVTLKHNVQYKLY |
|
NCBI Accession
|
YP_001333679.1
|
|
Location
|
1203-1622 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCTATCTTCTACACGCTCACAGAACCCCTGTTCTCCACCACCAATCAAGGCGCAACACAGGTTGGCCAAGAAACGTGCAATTCGACGCAGACGAATTGACCTGAAGTGTGGGTGTAGTTACTACCTACACATCAACTGCTACAACCATGGATTTACGCACAGGGGTGAGCATCACTGCAGCTCAGCTAGAGAATGGCGTCTTTACTTGGGAGGTAGCAAATCCCCTGAGTTTCAAGATCATGGACCACGACAGAGTATGGTACCACAACCTCATCCAGTGGCCAAAGTTCCGGACAACAATCCGCATAATGTTCAACCACTCTCTGAAGAAAGCGTTGGGGATACACAAGGCCTTCCTGGACTTGACGATTTACCATCGTTTCATACAGCCGAGTGGGCGGATTTGCTCGACTTTTAA |
|
Protein Sequence
|
MLSSTRSQNPCSPPPIKAQHRLAKKRAIRRRRIDLKCGCSYYLHINCYNHGFTHRGEHHCSSAREWRLYLGGSKSPEFQDHGPRQSMVPQPHPVAKVPDNNPHNVQPLSEESVGDTQGLPGLDDLPSFHTAEWADLLDF |
|
NCBI Accession
|
YP_001333680.1
|
|
Location
|
1522-2610 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGTCTAGACCAAAGGGTTTTCGGGTTAATGCCAAAAACTTCTTCCTCACATACCCAAGGTGTTCTCTCTCTAAAGAAGCAGCACTAGAGCAGCTACAGAATATTCAGACTAACGTCAACAAGAAATTCATCAGAGTTTGTCGTGAGTTCCATGAAAATGGGGAACCTCACCTCCATGTTCTGCTTCAATTTGAAGGAAAATTCCAGTGCCGCAACGAAAGGTTCTTCGACCTCGTATCCGAAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGATGTTAAAAAGTACATGGAGAAAGACGGAGACGTCATAGATTTTGGAATTTTCCAGATCGACGGGAGATCAAATAGAGGAGGTTCTCAATGTGCAAATGACGCATATGCCGAAGCAATCAATTCAGGCGATACAACATCGGCCCTCAATATATTGAAGGAGAAAGCGTCGAGAGACTTCATAATCCATTTGCACAATATCAGAGCCAATCTGAACTTTCTTTTTGCACCACCGCCAACAGTGTATGAAACACCATTCAGTATTGAATCATTCAATAATGTCCCTGAGACATTGACGTCATGGGCAGCTGAAAACGTGGTGTGCCCCGCTGCGCGGCCATTCAGACCTATTAGTATAGTGGTTGAGGGTGAGTCACGTACGGGTAAAACCATGTGGGCGAGGTCGCTCGGTCGGCACAATTATTTGTGCGGCCATTTGGATCTAAGCGCCAAAGTTTATTCAAATGATGCGTGGTACAACGTAATCGATGACGTCGATCCGCATTATCTGAAACATTTCAAAGAATTCATGGGCGCGCAAAAGGACTGGCAAAGCAACGTGAAATACGGAAAGCCCACTCAAATTAAAGGTGGCATCCCCACCATCTTTCTCTGTAATGCGGGACCCAGATCCTCTTATAAAATGTTCCTCGACGAAGAGAATAATGCGAGTCTCAAAGAGTGGGCTTTAAAAAATGCTATCTTCTACACGCTCACAGAACCCCTGTTCTCCACCACCAATCAAGGCGCAACACAGGTTGGCCAAGAAACGTGCAATTCGACGCAGACGAATTGA |
|
Protein Sequence
|
MSRPKGFRVNAKNFFLTYPRCSLSKEAALEQLQNIQTNVNKKFIRVCREFHENGEPHLHVLLQFEGKFQCRNERFFDLVSETRSAHFHPNIQGAKSSSDVKKYMEKDGDVIDFGIFQIDGRSNRGGSQCANDAYAEAINSGDTTSALNILKEKASRDFIIHLHNIRANLNFLFAPPPTVYETPFSIESFNNVPETLTSWAAENVVCPAARPFRPISIVVEGESRTGKTMWARSLGRHNYLCGHLDLSAKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQKDWQSNVKYGKPTQIKGGIPTIFLCNAGPRSSYKMFLDEENNASLKEWALKNAIFYTLTEPLFSTTNQGATQVGQETCNSTQTN |
|
NCBI Accession
|
YP_001333681.1
|
|
Location
|
2277-2459 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCTCACCTCCATGTTCTGCTTCAATTTGAAGGAAAATTCCAGTGCCGCAACGAAAGGTTCTTCGACCTCGTATCCGAAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGATGTTAAAAAGTACATGGAGAAAGACGGAGACGTCATAG |
|
Protein Sequence
|
MKMGNLTSMFCFNLKENSSAATKGSSTSYPKPGQHISIRTFRELRAAQMLKSTWRKTETS |
|
NCBI Accession
|
YP_001333682.1
|
|
Location
|
395-1174 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP protein |
|
Coding Region
|
ATGTTAGCCATGTTTACCCCTCGAGCAACCCCCCGTAATTATCCCCGTCGTGTCAGTGGGCAATTTAAGCGTAAATTACGCCCATACAATGGGGGTCTTAACACGTATCGTAAACTGCGTGTTGCTCGCAAGTTATCCTACGATCCATCTGTCCGTCCGTTCTCTATAAATACACTAGTTGAACGGCAACATGGTTCACATATGACCCTTGGAAGTAATTCGGATATTACTTCATTTGTTGAATATCCAGTTCGTGGTATTAATGGCGATGGTCGTTCAAGGGATTACATCAAATTGCTTCATTTATCAGCCTCAGGCGTTATTAACGTTAAGGTTGCCTCTTCGGATCAAGTAATGGATGGTGGTTCTCGTCACAACGGCGTATTTGTTATGTGTTTACTTCAGGACATGAAGCCGTTTTTACCTGACGGCGTCAATAGCTTGCCAACGTATGCCGAGTTATTCGGGCCTTATTCGTCTGCTTATGTTAATATGCATTTGTTGGATAGCCATAAACAGCGTTTTAGGATTTTAGGTAGCGTAAAAAAATTTGTAAGTTGTGGTTTGGATGCGGTAGACATCCCTTTCAAGTTAGACCTTAAGCTATCCAACGGGAGGTATCCATTGTGGGCGTCATTTAAAGACGCTGAAGAGGGTAATTGTGGGGGCAATTATAGAAATATTGCCAAAAATGCAATAATTGTAAGCTATGCATTTGTTTCATTGCATAGCCTTAAGTGTGAACCATTTGTACAATTTGAACTCCGTTACATGGGATAA |
|
Protein Sequence
|
MLAMFTPRATPRNYPRRVSGQFKRKLRPYNGGLNTYRKLRVARKLSYDPSVRPFSINTLVERQHGSHMTLGSNSDITSFVEYPVRGINGDGRSRDYIKLLHLSASGVINVKVASSDQVMDGGSRHNGVFVMCLLQDMKPFLPDGVNSLPTYAELFGPYSSAYVNMHLLDSHKQRFRILGSVKKFVSCGLDAVDIPFKLDLKLSNGRYPLWASFKDAEEGNCGGNYRNIAKNAIIVSYAFVSLHSLKCEPFVQFELRYMG |
|
NCBI Accession
|
YP_001333683.1
|
|
Location
|
1206-2102 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP protein |
|
Coding Region
|
ATGGAGACATACTCTGGAGCACTGGTCACAAACAAGTATATTCAATCAAAGCGATGCGAATACCGTCTGACAAACAACGAAACTCCAATTACTCTTCAATTTCCGTCGTCAATAGAACAAGCAGCAGTTAAAATGCTGGGAAAATGCATGAAGGTTGACCATATAGTAATTGAGTATCGTAACCAAGTACCTTACAATGCAACTGGAAGTGTCATCGTCACTATACGTGACACAAGATTAAGCGATGATCAGGCTGCACAGGCAGCTTTCACATTCCCCATTGGATGTAACGTAGATCTGCATTACTTTTCATCCTCATTTTTCTCCATCAAAGATGAGACGCCATGGGAGCTTCTATACAAAGTAGAAGACTCAAACGTCAACGACGGCACAGCATTTGCCCAAATAAAGGGCAAGTTGAAGTTATCGGCGGCAAAACATTCGACAGACATTAAATACAAACCGCCAACAATAAAAATATTGTCCAAAGACTACACAGCGGATTGCGTGGACTTTTGGTCTGTCGAGAGGCCCAAACCCATCAGAAGACTATTAACACCAACGCCAGGATGTGGTCCTGATGGGCTACAGCGCCAAAGGCCCATGTTATTACAGCCTGGGGAGACATGGGCCACACGGTCCACAATTGGACGCAGCACGTCAATGCGGTATCCAGACAACAATATAATGGGCCTTGAGCACAGGACAATCTCGTCCGACGCAGAATTTCCTCTAAAACACATGCACAAATTACCTGAGTCGTCATTAGACCCGGGAGACTCAGTCTCACAGGCGCAAACCAATCCGGTTACAAGAGCGGACATCGAGAGCATTATCGAAACAACCATTAACAGGTGTTTGGTTACGCAGAGATCAAATGTATCCAAACCATTGTAA |
|
Protein Sequence
|
METYSGALVTNKYIQSKRCEYRLTNNETPITLQFPSSIEQAAVKMLGKCMKVDHIVIEYRNQVPYNATGSVIVTIRDTRLSDDQAAQAAFTFPIGCNVDLHYFSSSFFSIKDETPWELLYKVEDSNVNDGTAFAQIKGKLKLSAAKHSTDIKYKPPTIKILSKDYTADCVDFWSVERPKPIRRLLTPTPGCGPDGLQRQRPMLLQPGETWATRSTIGRSTSMRYPDNNIMGLEHRTISSDAEFPLKHMHKLPESSLDPGDSVSQAQTNPVTRADIESIIETTINRCLVTQRSNVSKPL |