Jatropha yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000881575.2 |
| Isolate |
India: Kathaupahadi, Tikamgarh, Madhya Pradesh |
| Release date |
2017/10/11 |
| Submitter |
Snehi,S.K., Raj,S.K., Khan,M.S., Prasad,V., Kumar,S. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
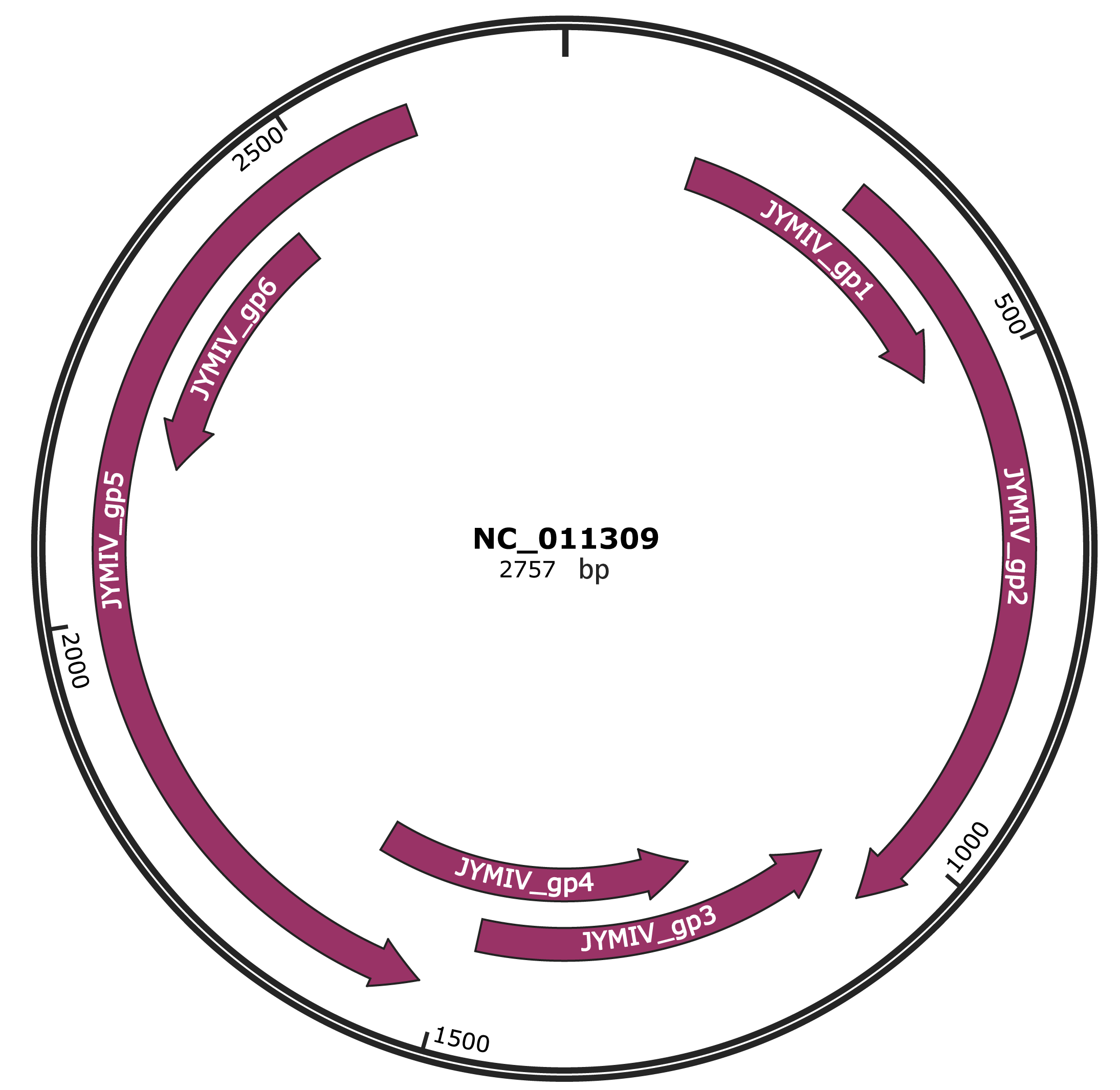
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTTTGGGCCCCTTAACGCATTAACTGACAAGGATAGGGGACCCCATCCCAAGGCGCGGTTAAAGGTTAAATGTTTTGTGGTCCCCCCTATAAACTTAGTCACCAAGTATTTATTCTCCAATATGTGGGATCCATTGTTGAATGAGTTTCCTGAAACCGTTCACGGTTTTAGGTGTATGCTAGCAGTTAAATATTTGCAATTAGTAGAAAAGACCTATTCCCCAGATACTCTGGGGTACGATTTAATTAGGGATTTGATTTCAGTAATAAGGGCTAGGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCTCATATGCGAGCCGTGTTGCTGCCCCCATTGTCCGCGTCAACAAAGCAAAAGCATGGGTGAACAGGCCGATGAACAGAAAGCCCAGGATGTACAGGCTGTTCAGAAGTCCGGATGTTCCTAAAGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAATCTAGACACGATGTAGTCCATATAGGGAAGGTCATGTGTATTAGTGATGTCACTCGCGGTACTGGGCTGACCCATAGAGTTGGTAAGCGTTTTTGTGTTAAGTCTGTTTACGTTTTGGGTAAAATATGGATGGATGAGAATATCAAGACCAGGAATCACACGAACAGTGTCCTGTTCTTTCTTGTTCGTGACCGTCGCCCTGTTGATAAGCCACAGGACTTTGGAGAGGTGTTCAATATGTTCGACAACGAGCCTAGCACTGCTACTGTTAAGAATATGCACAGAGATCGTTATCAGGTGTTGAGGAAGTGGCACGCAACTGTCACCGGTGGACAATACGCTTCAAAAGAACAGGCATTAGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGGAAGTATGAGAATCATACGGAGAATGCGTTGATGTTGTATATGGCGTGTACGCACGCCTCTAACCCTGTGTATGCTACGATGAAGATACGGATCTATTTCTATGATTCAGTATCGAATTAATAAAGACGAAATATTATTTCATTGCTTTGTTCAACATTTGCATCGTGATGCAGTACATTATACAATACATGATCTACAGCTCTAATTACAAGATTAATAGAAATTACACCTAATCTATCTAAATATCTAATAACTTGAGTCTTAAAGACTCGTAAGAAACTCCCAGTCGGAATCCGTGAACGAGTCCAGACTTTGAAGCTCAGGAAGCACTTGTGTATCTGTAGTGCTTGCCTGAGATTGTGATTGAATTGTATTTGGATGTGTATGATGTCCTGTTCCAGGTGGAAGGGCCTGCTCATGTGCACTGGGACGCGGAAGTATAGGGGATTTGGGACCGTCCAGATAAAGACGCCATTGTTGAAACGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTCGCGCAGGTTAATGACAGAAAATATGAACATCCGCACTTCAGATCAACTCCTCGCCGGATGGACCTCTTCTTCGCTATCCTGTGTTGGACCTTGATAGGTACCTGAGTATAGAGGTTCTGAGAGGAAGACGAACAAGACATTCTTAACCGCCCAGTTCTTTAATGCTGCGTTCCTATCTTCGTCTAAATACTCTTTATAGCTGGAAGTTGGCCCAGGATTGCAGAGGAAGATTGTCGGAATGCCCCCTTTAATTTGAACGGGCTTTCCATACTTGGTGTTACTTTGCCAGTCTCTCTGGGCCCCCATAAATTCCTTGAAGTGCTTTAGATAATGCGGATCAACATCATCAATGACGTTATACCATACGTCATTACTATAGACTCTTGGACTGAGATCCAAGTGACCGCATAAATAGTTGTGTGAACCCAATGACCTGGCCCACATTGTTTTCCCCGTCCTACTATTACCCTCTATGACTATACTCATGGGTCTCAAAGGCCGCGCAGCGGCATCCACCACATTCTCGGCAGCCCATTCCTCAAGTTCTGCCGGAACTTGATCGAAAGAAGAAGAAGAAAAAGGAGAAACATACTCCACAGGAGGCTCCTGTAAAAATCTATCTAAATTAGATTTTAAATTGTGAAATTGAAAAATATAATCTTTAGGAGACTTATTCTTTAATATATTGAGGGCCTCAATTTTTGACCCTGCGTTAATCGCTGTGGCGTAAGCGTCATTGGCTGATTGTTGTCCTCCTCGTGCAGATCTTCCATCGATCTGAAACTCTCCCCAGTCGATGGTGTCTCCGTCCTTCTCCATATAGGACTTGACGTCGCTGGAGCTTTTAGCTCCCTGGATGTTTGGATGGAATTGTGCTGACCTGGTTGGGGAGACCAGATCAAAGAATCGCTGATGTTGGCACTTGTATTTTCCTTCGAACTGGATAAGAACATGTAAGTGGGGTTCCCCATTTTCGTGAAGCTCTCTGCAGATTCTAATGAATTTTTTAGAAGTTGGTGTTTGGAGATTTAAGAATTGGGAAAGTGCTTCTTCTTTAGTGAGGGAGCACTTGGGATAAGTGAGAAAATAATTTTTTGCATTTAATTTAAACCGATTTGGGGCTGCCATGTTGACTTAGTCAATCGGTGTCTCTCAATTTGTTCTATGTATCGGTGTACTGGAGTCCTATATATATGGAGACTCTAATGGCATAATTGTAATAATAGAACTTTAATTTGAAATCCTCAAAATAAAATAAACGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_002261479.2
|
|
Location
|
143-499 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCATTGTTGAATGAGTTTCCTGAAACCGTTCACGGTTTTAGGTGTATGCTAGCAGTTAAATATTTGCAATTAGTAGAAAAGACCTATTCCCCAGATACTCTGGGGTACGATTTAATTAGGGATTTGATTTCAGTAATAAGGGCTAGGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCTCATATGCGAGCCGTGTTGCTGCCCCCATTGTCCGCGTCAACAAAGCAAAAGCATGGGTGAACAGGCCGATGAACAGAAAGCCCAGGATGTACAGGCTGTTCAGAAGTCCGGATGTTCCTAA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAVKYLQLVEKTYSPDTLGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPPSQLRQLICEPCCCPHCPRQQSKSMGEQADEQKAQDVQAVQKSGCS |
|
NCBI Accession
|
YP_002261480.1
|
|
Location
|
303-1073 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCTCATATGCGAGCCGTGTTGCTGCCCCCATTGTCCGCGTCAACAAAGCAAAAGCATGGGTGAACAGGCCGATGAACAGAAAGCCCAGGATGTACAGGCTGTTCAGAAGTCCGGATGTTCCTAAAGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAATCTAGACACGATGTAGTCCATATAGGGAAGGTCATGTGTATTAGTGATGTCACTCGCGGTACTGGGCTGACCCATAGAGTTGGTAAGCGTTTTTGTGTTAAGTCTGTTTACGTTTTGGGTAAAATATGGATGGATGAGAATATCAAGACCAGGAATCACACGAACAGTGTCCTGTTCTTTCTTGTTCGTGACCGTCGCCCTGTTGATAAGCCACAGGACTTTGGAGAGGTGTTCAATATGTTCGACAACGAGCCTAGCACTGCTACTGTTAAGAATATGCACAGAGATCGTTATCAGGTGTTGAGGAAGTGGCACGCAACTGTCACCGGTGGACAATACGCTTCAAAAGAACAGGCATTAGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGGAAGTATGAGAATCATACGGAGAATGCGTTGATGTTGTATATGGCGTGTACGCACGCCTCTAACCCTGTGTATGCTACGATGAAGATACGGATCTATTTCTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSSYASRVAAPIVRVNKAKAWVNRPMNRKPRMYRLFRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTRNHTNSVLFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATMKIRIYFYDSVSN |
|
NCBI Accession
|
YP_002261481.2
|
|
Location
|
1070-1474 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCGTTTCAACAATGGCGTCTTTATCTGGACGGTCCCAAATCCCCTATACTTCCGCGTCCCAGTGCACATGAGCAGGCCCTTCCACCTGGAACAGGACATCATACACATCCAAATACAATTCAATCACAATCTCAGGCAAGCACTACAGATACACAAGTGCTTCCTGAGCTTCAAAGTCTGGACTCGTTCACGGATTCCGACTGGGAGTTTCTTACGAGTCTTTAAGACTCAAGTTATTAGATATTTAGATAGATTAGGTGTAATTTCTATTAATCTTGTAATTAGAGCTGTAGATCATGTATTGTATAATGTACTGCATCACGATGCAAATGTTGAACAAAGCAATGAAATAATATTTCGTCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAARFNNGVFIWTVPNPLYFRVPVHMSRPFHLEQDIIHIQIQFNHNLRQALQIHKCFLSFKVWTRSRIPTGSFLRVFKTQVIRYLDRLGVISINLVIRAVDHVLYNVLHHDANVEQSNEIIFRLY |
|
NCBI Accession
|
YP_002261482.2
|
|
Location
|
1215-1619 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGTCTTGTTCGTCTTCCTCTCAGAACCTCTATACTCAGGTACCTATCAAGGTCCAACACAGGATAGCGAAGAAGAGGTCCATCCGGCGAGGAGTTGATCTGAAGTGCGGATGTTCATATTTTCTGTCATTAACCTGCGCGAATCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCGTTTCAACAATGGCGTCTTTATCTGGACGGTCCCAAATCCCCTATACTTCCGCGTCCCAGTGCACATGAGCAGGCCCTTCCACCTGGAACAGGACATCATACACATCCAAATACAATTCAATCACAATCTCAGGCAAGCACTACAGATACACAAGTGCTTCCTGAGCTTCAAAGTCTGGACTCGTTCACGGATTCCGACTGGGAGTTTCTTACGAGTCTTTAA |
|
Protein Sequence
|
MSCSSSSQNLYTQVPIKVQHRIAKKRSIRRGVDLKCGCSYFLSLTCANHGFTHRGTHHCSSFQQWRLYLDGPKSPILPRPSAHEQALPPGTGHHTHPNTIQSQSQASTTDTQVLPELQSLDSFTDSDWEFLTSL |
|
NCBI Accession
|
YP_002261483.2
|
|
Location
|
1522-2607 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGGCAGCCCCAAATCGGTTTAAATTAAATGCAAAAAATTATTTTCTCACTTATCCCAAGTGCTCCCTCACTAAAGAAGAAGCACTTTCCCAATTCTTAAATCTCCAAACACCAACTTCTAAAAAATTCATTAGAATCTGCAGAGAGCTTCACGAAAATGGGGAACCCCACTTACATGTTCTTATCCAGTTCGAAGGAAAATACAAGTGCCAACATCAGCGATTCTTTGATCTGGTCTCCCCAACCAGGTCAGCACAATTCCATCCAAACATCCAGGGAGCTAAAAGCTCCAGCGACGTCAAGTCCTATATGGAGAAGGACGGAGACACCATCGACTGGGGAGAGTTTCAGATCGATGGAAGATCTGCACGAGGAGGACAACAATCAGCCAATGACGCTTACGCCACAGCGATTAACGCAGGGTCAAAAATTGAGGCCCTCAATATATTAAAGAATAAGTCTCCTAAAGATTATATTTTTCAATTTCACAATTTAAAATCTAATTTAGATAGATTTTTACAGGAGCCTCCTGTGGAGTATGTTTCTCCTTTTTCTTCTTCTTCTTTCGATCAAGTTCCGGCAGAACTTGAGGAATGGGCTGCCGAGAATGTGGTGGATGCCGCTGCGCGGCCTTTGAGACCCATGAGTATAGTCATAGAGGGTAATAGTAGGACGGGGAAAACAATGTGGGCCAGGTCATTGGGTTCACACAACTATTTATGCGGTCACTTGGATCTCAGTCCAAGAGTCTATAGTAATGACGTATGGTATAACGTCATTGATGATGTTGATCCGCATTATCTAAAGCACTTCAAGGAATTTATGGGGGCCCAGAGAGACTGGCAAAGTAACACCAAGTATGGAAAGCCCGTTCAAATTAAAGGGGGCATTCCGACAATCTTCCTCTGCAATCCTGGGCCAACTTCCAGCTATAAAGAGTATTTAGACGAAGATAGGAACGCAGCATTAAAGAACTGGGCGGTTAAGAATGTCTTGTTCGTCTTCCTCTCAGAACCTCTATACTCAGGTACCTATCAAGGTCCAACACAGGATAGCGAAGAAGAGGTCCATCCGGCGAGGAGTTGA |
|
Protein Sequence
|
MAAPNRFKLNAKNYFLTYPKCSLTKEEALSQFLNLQTPTSKKFIRICRELHENGEPHLHVLIQFEGKYKCQHQRFFDLVSPTRSAQFHPNIQGAKSSSDVKSYMEKDGDTIDWGEFQIDGRSARGGQQSANDAYATAINAGSKIEALNILKNKSPKDYIFQFHNLKSNLDRFLQEPPVEYVSPFSSSSFDQVPAELEEWAAENVVDAAARPLRPMSIVIEGNSRTGKTMWARSLGSHNYLCGHLDLSPRVYSNDVWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPTSSYKEYLDEDRNAALKNWAVKNVLFVFLSEPLYSGTYQGPTQDSEEEVHPARS |
|
NCBI Accession
|
YP_002261484.2
|
|
Location
|
2157-2450 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCCCACTTACATGTTCTTATCCAGTTCGAAGGAAAATACAAGTGCCAACATCAGCGATTCTTTGATCTGGTCTCCCCAACCAGGTCAGCACAATTCCATCCAAACATCCAGGGAGCTAAAAGCTCCAGCGACGTCAAGTCCTATATGGAGAAGGACGGAGACACCATCGACTGGGGAGAGTTTCAGATCGATGGAAGATCTGCACGAGGAGGACAACAATCAGCCAATGACGCTTACGCCACAGCGATTAACGCAGGGTCAAAAATTGAGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGNPTYMFLSSSKENTSANISDSLIWSPQPGQHNSIQTSRELKAPATSSPIWRRTETPSTGESFRSMEDLHEEDNNQPMTLTPQRLTQGQKLRPSIY |