Jatropha mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000919175.1 |
| Isolate |
Jamaica: Spanish Town |
| Release date |
2015/2/22 |
| Submitter |
Simmonds-Gordon,R., Collins-Fairclough,A., Stewart,C., Roye,M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
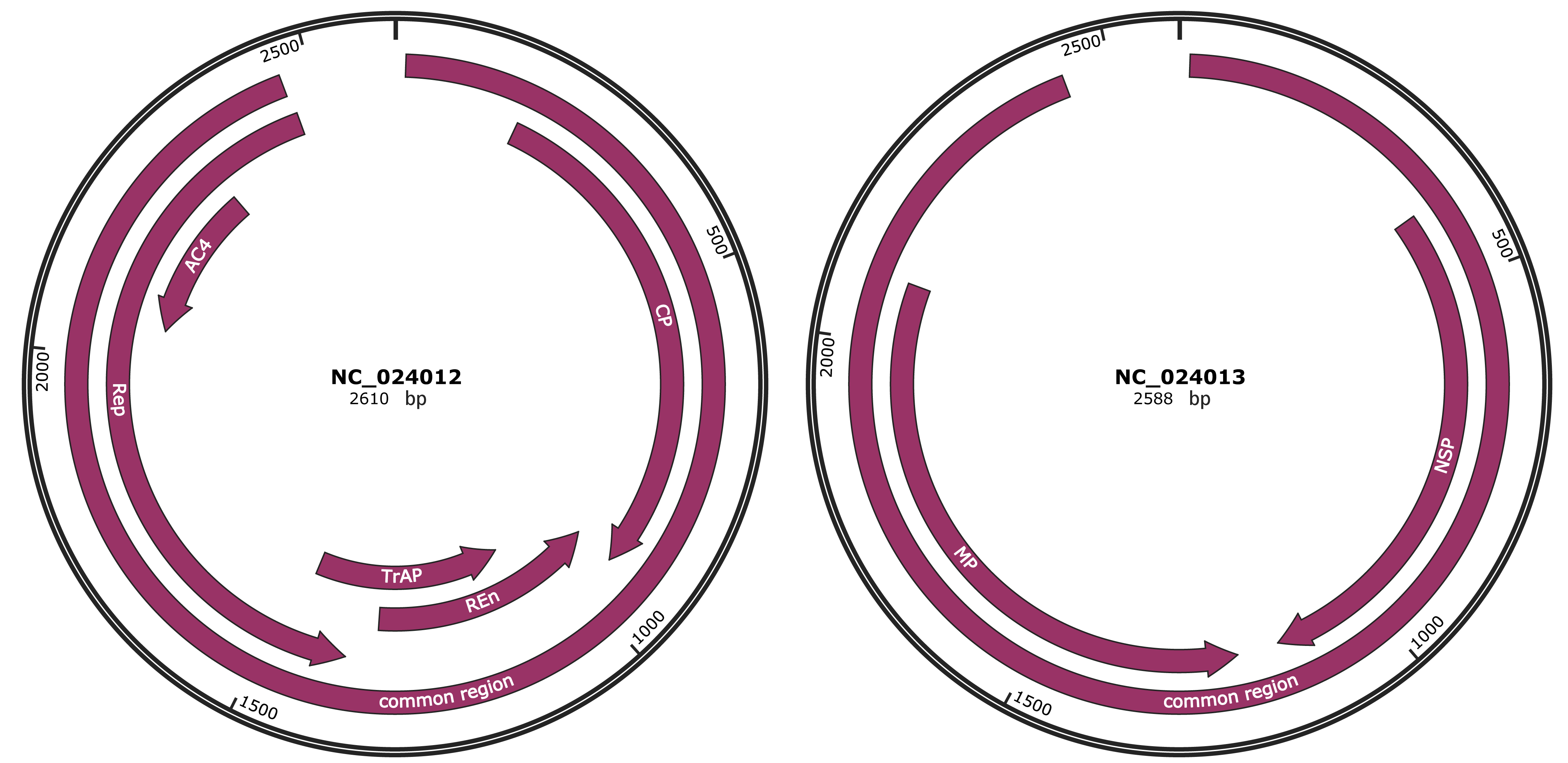
JBrowse
Genome
ACCGGATGGCCGCGCGCCCCCCCAGGTGCCGTACTACCATGCGCGCCACGTTTTGTCGTCATTCGCGAGTTGGGCCAATCACAGTGCGTCTGCCGCGTCTGTATATTTTGAACAACTTGGGCGCTAAGTTGTTGGGTGGTCTATAAAGGAAAGGACGATTGGCCCACTGTCTTTAACTCAAAATGCCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAACGTCCAAGGTTAGTCGCAATGCCAATTATTCTCCTCGATCAGGCATTACCCAGAAGTCCAGCAAGGCCCAGGAATGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTACCGGACGCTGAGGACGCCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGCAAGGTCCAGTCTTATGAACAGCGCCACGACATCTCACATGTGGGCAAGGTCATGTGCATATCTGACGTGACACGTGGTAGTGGCATTACCCATCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATATTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACTGCGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGCACGCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACGGTTAAGAACGATCTGCGTGATCGTTACCAGGTCATGCACCGGTTCTACGCCAAGGTCACGGGTGGACAGTATGCCAGCAACGAGCAGGCGATTGTTAAGCGGTTCTGGAAGGTCAACAATCATGTGGTCTACAACCACCAGGAGGCTGGCAAGTACGAGAACCACACCGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGGTCACCAATTAATAAATATTGAATTTTATTGAGTGATTTTCCAGTACATGATTTACATATGGTCTGTCTGTCGCGAAACGAACAGCTCTAATTACATTGTTAATGGAAATCACGCCTAATTGATCTAAGTACATATTGACTAAGTGCCTAAACCTAAGCAAATAAGTCGTTCCAGAAGCTGTCGTCGATGTCGTCCAGACTTGGAAGTTCAGGTAAGCCTTGTGGAGATCCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGATGTGGTATACTCGTGTCCTGGTGTATAGCATGTCCTCTACTCTGTATATTCTGAAATACAGGGGATTTTCTATCTCCCAGGTATACGCGCCATTCTCTGCCTGATGTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGTCCCCTGCAGTCGAGATGAACGTATATGGAGCACCCGCACTCTATATCAATGCGTCTCCTCCTGATGGCCCTCCTCTTGGCTTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGACGAAGATCGCATTCTTGATAGTCCAGTTCCTGAGTGATGAATTTTCCTCTTTGTCTAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAGAGCACGATTGCTGGGATGCCGCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTTTTTTTGGGCCCCCAGCAATTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACGTCGTTTGAGTAGACCCGGTGATTGAAGTCTAAGTGTCCACTGAGATAGTTATGTGGGCCTAACGCACGAGCCCACATCGTCTTCCCTGTCCGTGAATCACCTTCGACTATGACACTTATAGGTCTCTCCGGCCGCGCAGCGGAACCCCTTCCAAAATAATCATCCGCCCATTCTTGCATCTCGTCCGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGGACCCACGGTTCCGGAGCCTTTGCGAATATTCTTTCGAGATTGGAGCGGATGTTATGATTCTGCAAGACGAAATCTTTTGGCTGTTCTTCTTTTAAAATCGCCATGGCAGATTGAACAGAATCTGCATTTAACGCCTTGGCATATGAATCATTAGCAGATTGGCAGCCTCCCCTAGCACTTCGTCCGTCGATCTGGAATTCTCCCCATTCCAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTCGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCGTGTTGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCAGTTGTACTTCCCTTCGAACTGTATGAGCACATGGAGATGAGGCTGCCCATTCTCATGAAGCTCTCTGCAGATTTTGATGAACTTTTTGTTTATCGGAGTATTTAGGTTTTGTAATTGTGAAAGTGCTTCTTCTTTGGTAAGAGAGCACTGGGGATAAGTGAGGAAATAGTTTTTGGCTTTAATTGAGAAAGAACCCTTTCGTGGCATTTTTGTAAATATGGGATGTTCCCCCGATTGCTCCTCGCTCAAAACTCTCTATGAATTGGGGGAACTGGGGGAACATTTATACTAGAACCCTCAATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGCCCCCTATCCGTACACTCACACGCGCGCAATCCTCTTCATCGCTCGCGTTTTCGGCCAATCACAGTGCGTCTGCCGCGTCTGTATATTTGAACGACTTGGGCCCTAAGGGGTGGACTGGTCTATAAAGGAAAAGTCGATTGGCCCATCGTCTTTAATTCAAAATGCCTAAGCGGGACGCCCCATGGCCCGTTGTACTTGGTGATTGACGTGGCTTAAATTGGATCATGCTGCTGAGTCTATTTGCAGCTGATGGTGAAGGAGATATCTATATATTGGATTGGACGTGTAGGCTATGGTGTATGCGACTCAGCATTCTACCACGTTTGTATCGTTATTAATTACTTGTTCTGTTTATTCATTGTCTTCAACTGATAATGTATCCTATGAGGAATAAACGTGGTTTCTATTTTAGTCCACGTCGGTATTATCCACGTAATGCTGTGTTTAAGCGATCAACAACTTCGAAGAGATATGAGGGGAAACGACGACGTGTAGATGCTGGGAAGCCCAGTGATGAGCCGAAGATGCATGTTCAGTATGGGCCAGAGTTTGCCATGGCCCATAATTCAGCTATCTCGACCTATATCACCTACCCCAGCCTGGGTAAGACCGAGCCCAGTCGAAGCCGGTCCTATATTAAGTTGAGAGGGCTTCGTTTCAAAGGGACCGTGAAGATTGAACGTGTCCAAGCGGATGTGAACATGGACGGTTCGACGCCCAAGGTCGAAGGAGTGTTTTCTCTTGTCGTTGTCGTGGATCGCAAGCCTCACTTGGGTCCTTCTGGTTGCTTGCATACATTTGACGAGCTCTTCGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTGACTCCCTCTTTGAAGGAGCGTTACTATATACGCCACGTGTGCAAACGTGTATTGTCCGTGGAGAAGGACACGCTGATGGTAGACGTGGAAGGATCCATTTCTCTCTCTAACAGGCGTTTCAACTGTTGGTCTACGTTTAAGGACGTGGATCGTGAATCATGCAACGGTGTTTATGATAATATCAGCAAGAACGCTCTGTTAGTCTATTATTGTTGGATGTCTGATACTGTGTCTAAGGCGTCAACTTTTGTATCTTATGACCTTGATTATGTCGGATGATCAATAAATAATGTTTATGTAAAGCTCATTGTCTAAATATATGGAATGAAAAAAGTTTATATTTATTTTAACGACTTGGCCTGAGAAGGCTGACAATTATTATTAATACATTCTTGGACCGCAGTCCTAACTAGCTCATTCAACTGGCCCATTGACATTGTGATATTGGACTCGGCTCTTTGGGCCCCCACTATCGAAGCAGACTCTCCCGGATCTAGGACGCTGGTCCCAAGCCTGCTCAGGTGCCTGTATGGATGGAGTTCGTTTTCCATCTCTGAATCAGCGTCCGAATGACCAGCTCCTATTGTGCTCCTGGAAGCCCATGACTCTCCAGGCCTTATCTCGATTGGGCCTCTTAGCCCAACTCTGGACATGGACGCGCACCTGATGAGCTTCCTTTCCCATTTCCCATAGTCGACATGGGAGAAGTCCACGTCCTTGTCTGTGAACTGTTTGGATAGGATCTTCACTGTTGGTGCCCGGAAAGGGATGTCGACCGAGTGTTTTGCCGTGGACAACTTCAGCTTCCCTTTGAATTTGGCGAAGTGGGTCCTCTGATGGACATTGGTGTCGCATACTCGGTAGTATAGCTTCCATGGAATTGGGTCCTTTAGCGAGAAGAACGAAGCCGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGAAATGTCCATGATGCCTGCAATGATTCGTTGTCCGTCATTCGCTTGTCGTGGATCTCCACTATCACCGTTCCGGCGGCGTTGATCGGAACTTGTTGTCTGTATTCTATGACGCAATGGTCGATTTTCATGCAGCTACGACTGAGTCTAGCTGTTAATTGCGCCGCCGTGGAAGGGAATTGCAGTACTATCTCAGTTAGATCATGCGAAAGCTGGTATTCGTCCCGATGGGACTCTATGTAATTGAAGGCGTTCGGAGGATTTGCTAACTGAGAATCCATATAGAGAAAAATGGCCGCGCAGCGGAACCGATAGCTGACGATGAAGAAAGTGAAGAACTTTTGGTGAAGTTCTGTTGTTTATGCAGAGATGGGCTCTGCTAGAGGAATCAATTGATGGTGAACTGTGTTTTTGGGACAGTCAGGCTGACGATGAAGAAATTGAAGATTTTGTGGTCAATTTCTCTTGTTTATGCAGAGATGTGCTCTGCTAGAGGAATCAATTGCATAGGAAAATGATATGTTCTCTGTTTTGGGGTTTACTTGATGAACAGAGCAATTGTACTGCAAAAACTGTTTATGAATAAGAGATATGTATGATGGTGTTTATATAGAAACCCAGAAATAAGCGATGGCATTTTTGTAAATATGGGATGTTCCCCCGATTGCTCCTCGCTCAAAACTCTCTATGAATTGGGGGAACTGGGGGAACATTTATACTAGAACCCTCAATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009026400.1
|
|
Location
|
183-938 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAACGTCCAAGGTTAGTCGCAATGCCAATTATTCTCCTCGATCAGGCATTACCCAGAAGTCCAGCAAGGCCCAGGAATGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTACCGGACGCTGAGGACGCCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGCAAGGTCCAGTCTTATGAACAGCGCCACGACATCTCACATGTGGGCAAGGTCATGTGCATATCTGACGTGACACGTGGTAGTGGCATTACCCATCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATATTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACTGCGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGCACGCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACGGTTAAGAACGATCTGCGTGATCGTTACCAGGTCATGCACCGGTTCTACGCCAAGGTCACGGGTGGACAGTATGCCAGCAACGAGCAGGCGATTGTTAAGCGGTTCTGGAAGGTCAACAATCATGTGGTCTACAACCACCAGGAGGCTGGCAAGTACGAGAACCACACCGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGGTCACCAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRSGITQKSSKAQEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGSGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNCVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYAKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_009026401.1
|
|
Location
|
935-1333 |
|
Gene Name
|
REn |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCACATCAGGCAGAGAATGGCGCGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAGAATATACAGAGTAGAGGACATGCTATACACCAGGACACGAGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCTTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGAACGACTTATTTGCTTAGGTTTAGGCACTTAGTCAATATGTACTTAGATCAATTAGGCGTGATTTCCATTAACAATGTAATTAGAGCTGTTCGTTTCGCGACAGACAGACCATATGTAAATCATGTACTGGAAAATCACTCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAHQAENGAYTWEIENPLYFRIYRVEDMLYTRTRVYHIQIRFNHNLRRALDLHKAYLNFQVWTTSTTASGTTYLLRFRHLVNMYLDQLGVISINNVIRAVRFATDRPYVNHVLENHSIKFNIY |
|
NCBI Accession
|
YP_009026402.1
|
|
Location
|
1080-1469 |
|
Gene Name
|
TrAP |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGATCTTCGTCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGATATAGAGTGCGGGTGCTCCATATACGTTCATCTCGACTGCAGGGGACATGGATTCACGCACAGGGGAACCCATCACTGCACATCAGGCAGAGAATGGCGCGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAGAATATACAGAGTAGAGGACATGCTATACACCAGGACACGAGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCTTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGAACGACTTATTTGCTTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKKAHRQAKRRAIRRRRIDIECGCSIYVHLDCRGHGFTHRGTHHCTSGREWRVYLGDRKSPVFQNIQSRGHAIHQDTSIPHPDTVQPQPEESVGSPQGLPELPSLDDIDDSFWNDLFA |
|
NCBI Accession
|
YP_009026403.1
|
|
Location
|
1381-2466 |
|
Gene Name
|
Rep |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACGAAAGGGTTCTTTCTCAATTAAAGCCAAAAACTATTTCCTCACTTATCCCCAGTGCTCTCTTACCAAAGAAGAAGCACTTTCACAATTACAAAACCTAAATACTCCGATAAACAAAAAGTTCATCAAAATCTGCAGAGAGCTTCATGAGAATGGGCAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACACGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGACGAAGTGCTAGGGGAGGCTGCCAATCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCATGGCGATTTTAAAAGAAGAACAGCCAAAAGATTTCGTCTTGCAGAATCATAACATCCGCTCCAATCTCGAAAGAATATTCGCAAAGGCTCCGGAACCGTGGGTCCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGCAAGAATGGGCGGATGATTATTTTGGAAGGGGTTCCGCTGCGCGGCCGGAGAGACCTATAAGTGTCATAGTCGAAGGTGATTCACGGACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAACTATCTCAGTGGACACTTAGACTTCAATCACCGGGTCTACTCAAACGACGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAAACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGCGGCATCCCAGCAATCGTGCTCTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTAGACAAAGAGGAAAATTCATCACTCAGGAACTGGACTATCAAGAATGCGATCTTCGTCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGA |
|
Protein Sequence
|
MPRKGSFSIKAKNYFLTYPQCSLTKEEALSQLQNLNTPINKKFIKICRELHENGQPHLHVLIQFEGKYNCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQSANDSYAKALNADSVQSAMAILKEEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFPLSSFTNVPDEMQEWADDYFGRGSAARPERPISVIVEGDSRTGKTMWARALGPHNYLSGHLDFNHRVYSNDVEYNVIDDVAPHYLKLKHWKELLGAQKNWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLDKEENSSLRNWTIKNAIFVTLTAPLYQEGTQASQEEGHQEETH |
|
NCBI Accession
|
YP_009026404.1
|
|
Location
|
2052-2315 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAGAATGGGCAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACACGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGACGAAGTGCTAGGGGAGGCTGCCAATCTGCTAATGATTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MRMGSLISMCSYSSKGSTTARITDSSIWSPQHGQHISIRTYRELNRAPTSSPTSTRTEIHWNGENSRSTDEVLGEAANLLMIHMPRR |
|
NCBI Accession
|
YP_009026405.1
|
|
Location
|
392-1144 |
|
Gene Name
|
NSP |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCCTATGAGGAATAAACGTGGTTTCTATTTTAGTCCACGTCGGTATTATCCACGTAATGCTGTGTTTAAGCGATCAACAACTTCGAAGAGATATGAGGGGAAACGACGACGTGTAGATGCTGGGAAGCCCAGTGATGAGCCGAAGATGCATGTTCAGTATGGGCCAGAGTTTGCCATGGCCCATAATTCAGCTATCTCGACCTATATCACCTACCCCAGCCTGGGTAAGACCGAGCCCAGTCGAAGCCGGTCCTATATTAAGTTGAGAGGGCTTCGTTTCAAAGGGACCGTGAAGATTGAACGTGTCCAAGCGGATGTGAACATGGACGGTTCGACGCCCAAGGTCGAAGGAGTGTTTTCTCTTGTCGTTGTCGTGGATCGCAAGCCTCACTTGGGTCCTTCTGGTTGCTTGCATACATTTGACGAGCTCTTCGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTGACTCCCTCTTTGAAGGAGCGTTACTATATACGCCACGTGTGCAAACGTGTATTGTCCGTGGAGAAGGACACGCTGATGGTAGACGTGGAAGGATCCATTTCTCTCTCTAACAGGCGTTTCAACTGTTGGTCTACGTTTAAGGACGTGGATCGTGAATCATGCAACGGTGTTTATGATAATATCAGCAAGAACGCTCTGTTAGTCTATTATTGTTGGATGTCTGATACTGTGTCTAAGGCGTCAACTTTTGTATCTTATGACCTTGATTATGTCGGATGA |
|
Protein Sequence
|
MYPMRNKRGFYFSPRRYYPRNAVFKRSTTSKRYEGKRRRVDAGKPSDEPKMHVQYGPEFAMAHNSAISTYITYPSLGKTEPSRSRSYIKLRGLRFKGTVKIERVQADVNMDGSTPKVEGVFSLVVVVDRKPHLGPSGCLHTFDELFGARIHSHGNLSVTPSLKERYYIRHVCKRVLSVEKDTLMVDVEGSISLSNRRFNCWSTFKDVDRESCNGVYDNISKNALLVYYCWMSDTVSKASTFVSYDLDYVG |
|
NCBI Accession
|
YP_009026406.1
|
|
Location
|
1207-2088 |
|
Gene Name
|
MP |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCAGTTAGCAAATCCTCCGAACGCCTTCAATTACATAGAGTCCCATCGGGACGAATACCAGCTTTCGCATGATCTAACTGAGATAGTACTGCAATTCCCTTCCACGGCGGCGCAATTAACAGCTAGACTCAGTCGTAGCTGCATGAAAATCGACCATTGCGTCATAGAATACAGACAACAAGTTCCGATCAACGCCGCCGGAACGGTGATAGTGGAGATCCACGACAAGCGAATGACGGACAACGAATCATTGCAGGCATCATGGACATTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCGCTAAAGGACCCAATTCCATGGAAGCTATACTACCGAGTATGCGACACCAATGTCCATCAGAGGACCCACTTCGCCAAATTCAAAGGGAAGCTGAAGTTGTCCACGGCAAAACACTCGGTCGACATCCCTTTCCGGGCACCAACAGTGAAGATCCTATCCAAACAGTTCACAGACAAGGACGTGGACTTCTCCCATGTCGACTATGGGAAATGGGAAAGGAAGCTCATCAGGTGCGCGTCCATGTCCAGAGTTGGGCTAAGAGGCCCAATCGAGATAAGGCCTGGAGAGTCATGGGCTTCCAGGAGCACAATAGGAGCTGGTCATTCGGACGCTGATTCAGAGATGGAAAACGAACTCCATCCATACAGGCACCTGAGCAGGCTTGGGACCAGCGTCCTAGATCCGGGAGAGTCTGCTTCGATAGTGGGGGCCCAAAGAGCCGAGTCCAATATCACAATGTCAATGGGCCAGTTGAATGAGCTAGTTAGGACTGCGGTCCAAGAATGTATTAATAATAATTGTCAGCCTTCTCAGGCCAAGTCGTTAAAATAA |
|
Protein Sequence
|
MDSQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKLIRCASMSRVGLRGPIEIRPGESWASRSTIGAGHSDADSEMENELHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVRTAVQECINNNCQPSQAKSLK |