Jatropha mosaic India virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002822725.1 |
| Isolate |
India: U.P., Lucknow |
| Release date |
2018/8/25 |
| Submitter |
Snehi,S.K., Raj,S.K., Prasad,V. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
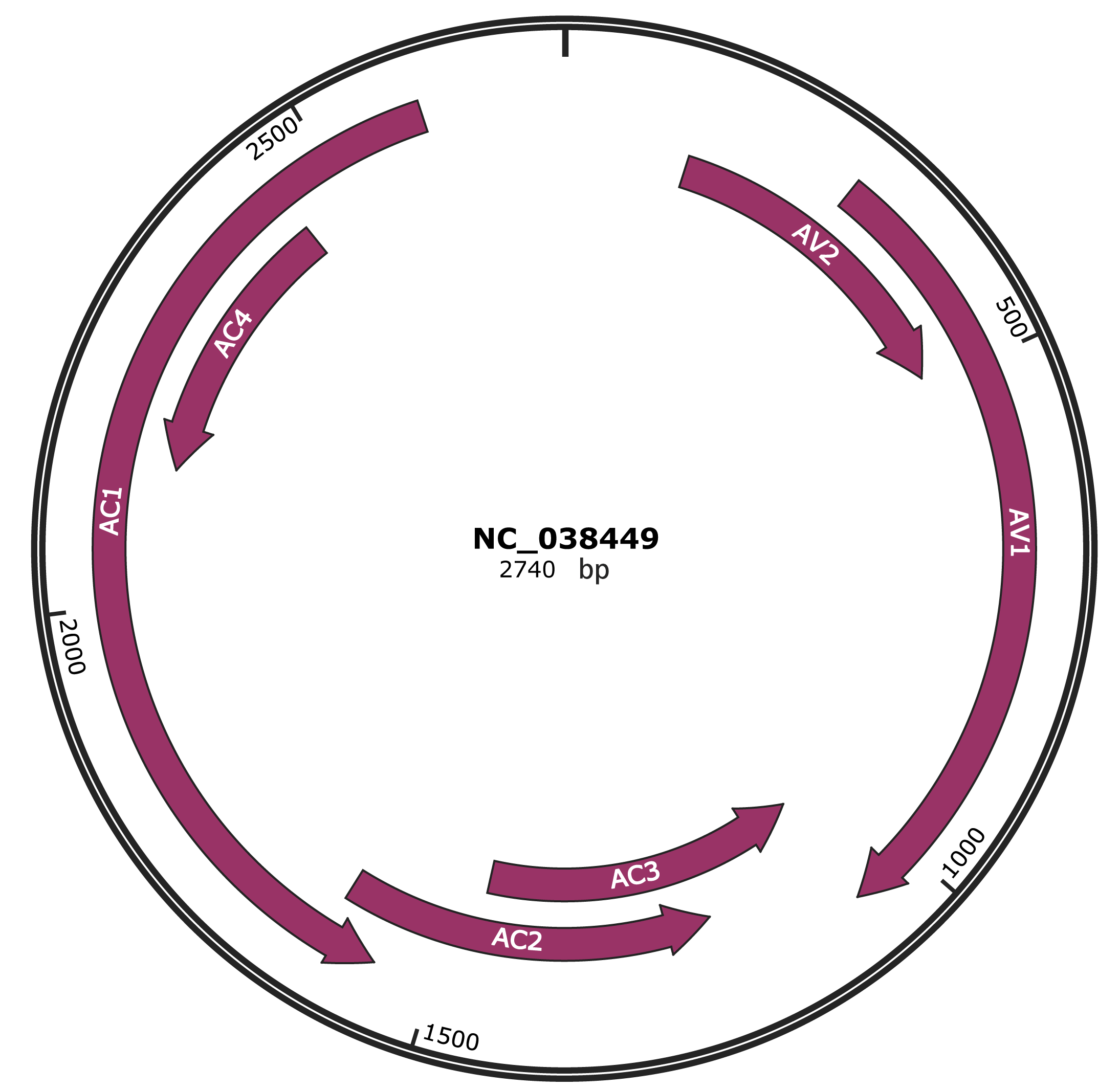
JBrowse
Genome
ACCGGATGGCCGCGCTCCCTGCTTTGTGGTTCCCCCCCCCCACGTGGAGTTGTCGCCCACTCAGAACGCTGCGTCAAGCTTGAATATCTGTGGTCCCTGTTTAAGTACTTCGTGAGCAAGTTAATACTTGCAAAATGTGGGATCCACTACTTAACGAGTTCCCAGACTCCGTTCACGGTTTCCGTTGTATGCTAGCGCTGAAGTACCTTCAGCTCGTCGAAAGTACTTATTCCCCTGATACGCTCGGTTACGATCTAATCCGGGACCTGATTTCTGTTATCAGGGCCAGAAGCTATGTCGAAGCGACCAGGAGATATCATCATTTCAACTCCCGCCTCGAAGGTACGTCGCCGTCTGATCTTCGACAGCTTATACAGCAGCCGTGCTTCTGTCTTCACTGTCCGCGTCACCAAAAGACAAGCCTGGACAAACAGGCCCATGAATCGGAAGCCCAGATGGTACAGGATGTTCAGAAGCCCAGATGTTCCTAGGGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGTCCAGACACGATGTGGTCCATATAGGTAAGGTAATGTGCATCTCTGATGTCACTCGTGGTGTTGGGCTAACTCATCGTGTGGGTAAGAGGTTTTGCGTTAAGTCCGTTTACATCCTGGGGAAGGTATGGATGGATGAAAATATCAAGACCAAGAATCACACTAATAGCGTGATGTTCTTCCTCGTTAGGGATCGTAGGCCTGTTGATAAGCCCCAGGATTTCGGTGAGGTGTTTAACATGTTTGATAATGAACCTAGTACAGCTACTGTGAAGAACATGCATCGTGATCGCTATCAAGTCCTCAGGAAGTGGAGTGCCACTGTCACTGGTGGTCAGTATGCTAGCAAGGAGCAGGCTTTAGTTAGACGTTTTTTTAGAGTTAATAATTATGTTGTGTATAATCAGCAAGAGGCTGGCAAGTATGAAAATCATACTGAGAATGCATTGATGCTGTACATGGCGTGTACTCACGCCTCTAATCCTGTATACGCTACGCTGAAGATTAGAATCTACTTCTACGATTCGGTCAGCAATTAATAAATTTTAAATTTTATTAAATTTGACTGCTCAATACTGTCAGTCCCTGTGAGTACACTGTACAATACATGTTCTACGGCGGTTAAAACCGTATTTATACATATGACCCCTAACATGTCCAGGTATTTGAGTACGTGGGTCTTAAATACCCTCAAGAAACGCAAGGTCTGAGGCCGTAAGGTCGTCCAGATTTTGAAATCCATCCAGCATTGATGTAGTCCCAACGCTTTCCTCAGGTTGTGGTTGAACCGTATCTGGACGGTTATTATGTCCATCGTCGTTCCGAACGGCCGGCTGCTGTGGTCTATGATCTTGAAATAGAGGGGATTTGGAACCTCCCAGGTATAGACGCCATTCATCGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTGATGTGCACGTAGTACGAGCACCCGCAGTTGAGGTCTACTCTCCGTCGCCGGATGGCCCTACGCTTAGCTGCCCTGTGTTTAACCTTGATCGGCACTGGAGTAGAGTGGCCCGTCGAGGGAGATGAAGGTCGCATTTCTTATTGCCCAAGCCTTCAATGCCGTATTCTTCGGCTCGTCAAGGAACTCTTTATAGCTGGAATTGGGCCCAGGATTGCACAGGAAGATAGTGGGTATCCCACCTTTAATTTGAACCGGCTTTCCGTATTTGGTGTTGCTTTGCCAGTCCTTCTGGGCCCCCATGAATTCCTTGAAGTGCTTTAGGTAGTGGGGATCTACGTCATCAATGACGTTGTACCACGCGTCGTTGCTGTAGACCCTAGGACTCAAGTCCAGATGTCCACATAGGTAATTATGTGGACCCAATGCACGAGCCCACATAGTCTTACCTGTCCGACTATCGCCCTCGATTACGATTGACTTCGGTCTCAAAGGCCGCGCAGCGGGATCCATGACATTTTCATGGAACCATACATCGAGTTCTTCTGGAACTCGATCAAATGTCGACAGACCAAAAGGACTCTCATAGATAGTTTCAGGTGTTGTAAAAATTTTATCCAAATTGGCATTCAAATTATGAAACTGCAGGACGTAGTCTTTAGGAGCTAGCTCTCTAAGGATCTTAAGAGCCTCTGACTTACTGCCGCTGTTAATTGCGGCGGCGTATGCATCATTTGCCGACTGTTGGCCTCCCCGTGCAGACCTGCCGTCGACCTGGAATTCTCCCCATTCCAGAGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCTCTTATTCTGGCATTTGAACTTGCCCTCGTACTGGACGAGCACATGCAGATGAGGTTCCCCATTCTCATGCAGTTCTCTGCAGATTTTAATGAATTTAGGGTTTGTAGGTGTTTCTAGGTTTTTAATTTGGGAAAGCGTCTCTTCTTTGGAGAGAGAGCATCTGGGATAAGTGAGGAAATAATTCTTGGCGTTTATAATAAAACGCTTAGGAGGTGACATTCTCTCTCCTCAATCGGTACTCAAACATTTAGCCCCTATATTAGGTACTCAATATATACATGAGACCCAAATGGCATATATGGTAATAATGGGAATATAATTTGAATTTGAAAGCGGCCATCCGTATAATATTTATAA
Gene Information
|
NCBI Accession
|
YP_009506422.1
|
|
Location
|
135-491 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTACTTAACGAGTTCCCAGACTCCGTTCACGGTTTCCGTTGTATGCTAGCGCTGAAGTACCTTCAGCTCGTCGAAAGTACTTATTCCCCTGATACGCTCGGTTACGATCTAATCCGGGACCTGATTTCTGTTATCAGGGCCAGAAGCTATGTCGAAGCGACCAGGAGATATCATCATTTCAACTCCCGCCTCGAAGGTACGTCGCCGTCTGATCTTCGACAGCTTATACAGCAGCCGTGCTTCTGTCTTCACTGTCCGCGTCACCAAAAGACAAGCCTGGACAAACAGGCCCATGAATCGGAAGCCCAGATGGTACAGGATGTTCAGAAGCCCAGATGTTCCTAG |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLALKYLQLVESTYSPDTLGYDLIRDLISVIRARSYVEATRRYHHFNSRLEGTSPSDLRQLIQQPCFCLHCPRHQKTSLDKQAHESEAQMVQDVQKPRCS |
|
NCBI Accession
|
YP_009506423.1
|
|
Location
|
295-1065 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATCATCATTTCAACTCCCGCCTCGAAGGTACGTCGCCGTCTGATCTTCGACAGCTTATACAGCAGCCGTGCTTCTGTCTTCACTGTCCGCGTCACCAAAAGACAAGCCTGGACAAACAGGCCCATGAATCGGAAGCCCAGATGGTACAGGATGTTCAGAAGCCCAGATGTTCCTAGGGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGTCCAGACACGATGTGGTCCATATAGGTAAGGTAATGTGCATCTCTGATGTCACTCGTGGTGTTGGGCTAACTCATCGTGTGGGTAAGAGGTTTTGCGTTAAGTCCGTTTACATCCTGGGGAAGGTATGGATGGATGAAAATATCAAGACCAAGAATCACACTAATAGCGTGATGTTCTTCCTCGTTAGGGATCGTAGGCCTGTTGATAAGCCCCAGGATTTCGGTGAGGTGTTTAACATGTTTGATAATGAACCTAGTACAGCTACTGTGAAGAACATGCATCGTGATCGCTATCAAGTCCTCAGGAAGTGGAGTGCCACTGTCACTGGTGGTCAGTATGCTAGCAAGGAGCAGGCTTTAGTTAGACGTTTTTTTAGAGTTAATAATTATGTTGTGTATAATCAGCAAGAGGCTGGCAAGTATGAAAATCATACTGAGAATGCATTGATGCTGTACATGGCGTGTACTCACGCCTCTAATCCTGTATACGCTACGCTGAAGATTAGAATCTACTTCTACGATTCGGTCAGCAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPASKVRRRLIFDSLYSSRASVFTVRVTKRQAWTNRPMNRKPRWYRMFRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGVGLTHRVGKRFCVKSVYILGKVWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWSATVTGGQYASKEQALVRRFFRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009506424.1
|
|
Location
|
1062-1466 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATAGACCACAGCAGCCGGCCGTTCGGAACGACGATGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAAATCTGGACGACCTTACGGCCTCAGACCTTGCGTTTCTTGAGGGTATTTAAGACCCACGTACTCAAATACCTGGACATGTTAGGGGTCATATGTATAAATACGGTTTTAACCGCCGTAGAACATGTATTGTACAGTGTACTCACAGGGACTGACAGTATTGAGCAGTCAAATTTAATAAAATTTAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAMNGVYTWEVPNPLYFKIIDHSSRPFGTTMDIITVQIRFNHNLRKALGLHQCWMDFKIWTTLRPQTLRFLRVFKTHVLKYLDMLGVICINTVLTAVEHVLYSVLTGTDSIEQSNLIKFKIY |
|
NCBI Accession
|
YP_009506425.1
|
|
Location
|
1207-1614 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGCGACCTTCATCTCCCTCGACGGGCCACTCTACTCCAGTGCCGATCAAGGTTAAACACAGGGCAGCTAAGCGTAGGGCCATCCGGCGACGGAGAGTAGACCTCAACTGCGGGTGCTCGTACTACGTGCACATCAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATAGACCACAGCAGCCGGCCGTTCGGAACGACGATGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAAATCTGGACGACCTTACGGCCTCAGACCTTGCGTTTCTTGAGGGTATTTAA |
|
Protein Sequence
|
MRPSSPSTGHSTPVPIKVKHRAAKRRAIRRRRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGDEWRLYLGGSKSPLFQDHRPQQPAVRNDDGHNNRPDTVQPQPEESVGTTSMLDGFQNLDDLTASDLAFLEGI |
|
NCBI Accession
|
YP_009506426.1
|
|
Location
|
1559-2602 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGTCACCTCCTAAGCGTTTTATTATAAACGCCAAGAATTATTTCCTCACTTATCCCAGATGCTCTCTCTCCAAAGAAGAGACGCTTTCCCAAATTAAAAACCTAGAAACACCTACAAACCCTAAATTCATTAAAATCTGCAGAGAACTGCATGAGAATGGGGAACCTCATCTGCATGTGCTCGTCCAGTACGAGGGCAAGTTCAAATGCCAGAATAAGAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACTCTGGAATGGGGAGAATTCCAGGTCGACGGCAGGTCTGCACGGGGAGGCCAACAGTCGGCAAATGATGCATACGCCGCCGCAATTAACAGCGGCAGTAAGTCAGAGGCTCTTAAGATCCTTAGAGAGCTAGCTCCTAAAGACTACGTCCTGCAGTTTCATAATTTGAATGCCAATTTGGATAAAATTTTTACAACACCTGAAACTATCTATGAGAGTCCTTTTGGTCTGTCGACATTTGATCGAGTTCCAGAAGAACTCGATGTATGGTTCCATGAAAATGTCATGGATCCCGCTGCGCGGCCTTTGAGACCGAAGTCAATCGTAATCGAGGGCGATAGTCGGACAGGTAAGACTATGTGGGCTCGTGCATTGGGTCCACATAATTACCTATGTGGACATCTGGACTTGAGTCCTAGGGTCTACAGCAACGACGCGTGGTACAACGTCATTGATGACGTAGATCCCCACTACCTAAAGCACTTCAAGGAATTCATGGGGGCCCAGAAGGACTGGCAAAGCAACACCAAATACGGAAAGCCGGTTCAAATTAAAGGTGGGATACCCACTATCTTCCTGTGCAATCCTGGGCCCAATTCCAGCTATAAAGAGTTCCTTGACGAGCCGAAGAATACGGCATTGAAGGCTTGGGCAATAAGAAATGCGACCTTCATCTCCCTCGACGGGCCACTCTACTCCAGTGCCGATCAAGGTTAA |
|
Protein Sequence
|
MSPPKRFIINAKNYFLTYPRCSLSKEETLSQIKNLETPTNPKFIKICRELHENGEPHLHVLVQYEGKFKCQNKRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGQQSANDAYAAAINSGSKSEALKILRELAPKDYVLQFHNLNANLDKIFTTPETIYESPFGLSTFDRVPEELDVWFHENVMDPAARPLRPKSIVIEGDSRTGKTMWARALGPHNYLCGHLDLSPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQKDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEPKNTALKAWAIRNATFISLDGPLYSSADQG |
|
NCBI Accession
|
YP_009506427.1
|
|
Location
|
2143-2445 |
|
Gene Name
|
AC4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCATGTGCTCGTCCAGTACGAGGGCAAGTTCAAATGCCAGAATAAGAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACTCTGGAATGGGGAGAATTCCAGGTCGACGGCAGGTCTGCACGGGGAGGCCAACAGTCGGCAAATGATGCATACGCCGCCGCAATTAACAGCGGCAGTAAGTCAGAGGCTCTTAAGATCCTTAGAGAGCTAG |
|
Protein Sequence
|
MGNLICMCSSSTRASSNARIRDSSTWYPQPGQHISIQTFRELNPAPTSSPTSTRTEILWNGENSRSTAGLHGEANSRQMMHTPPQLTAAVSQRLLRSLES |