Jatropha leaf yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003028955.1 |
| Isolate |
India: Katerniaghat Wildlife Sanctuary, Bahraich, UP |
| Release date |
2018/8/26 |
| Submitter |
Srivastava,A., Kumar,S., Jaidi,M., Raj,S.K., Snehi,S.K. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
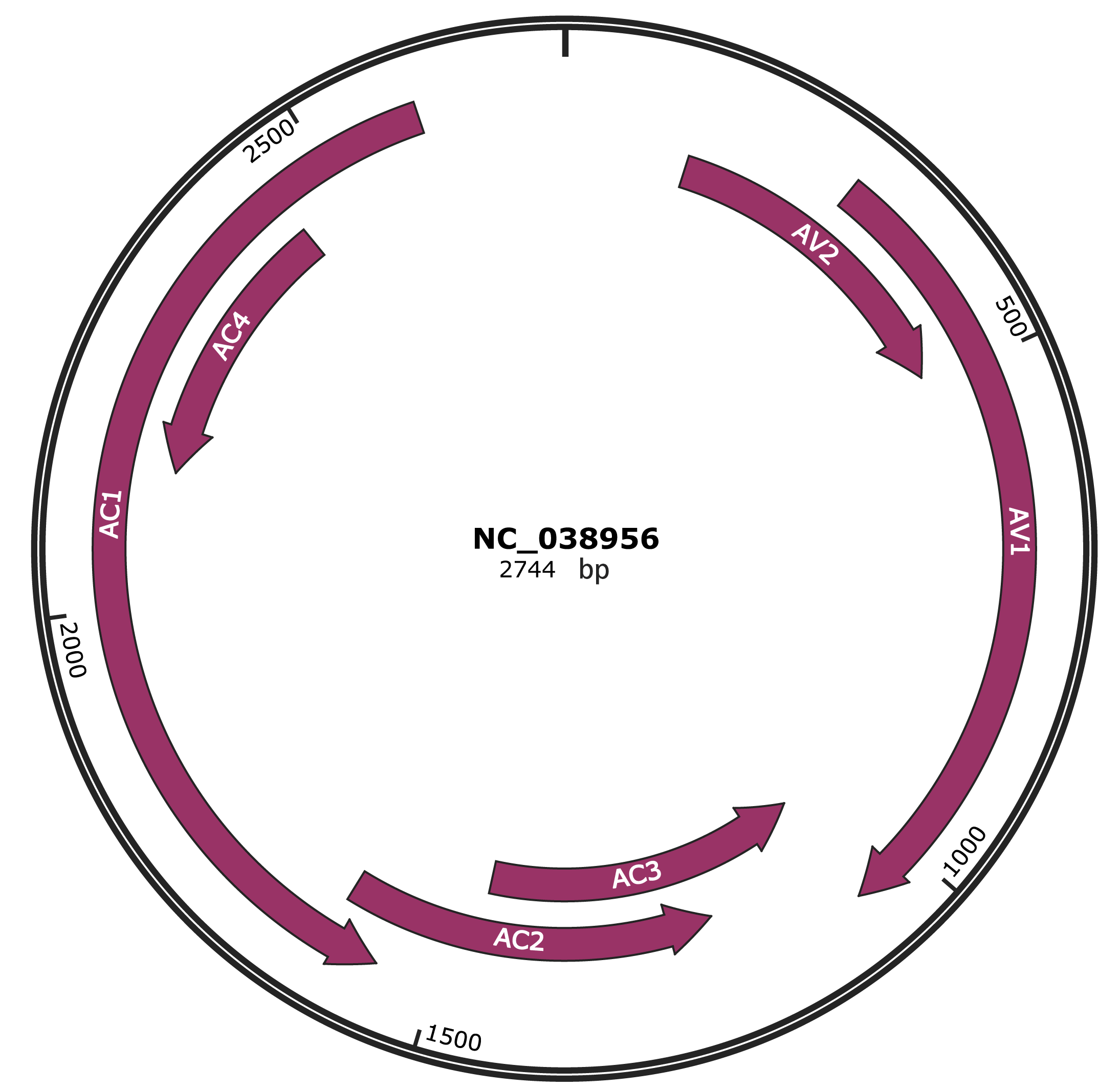
JBrowse
Genome
ACCGGATGGCCGCGCTCCCTGCTTTGTGGTTCCCCCCCCCCACGTGGAGTTGTCGCCCACTCAGAACGCTGCGTCAAGCTTCAATATTTGTGGTCCCTGTTTAAGTACTTCGTAAGCAAGTTGCTACTTGCAAAATGTGGGATCCACTACTTAAGAAATTCGCAGACTCCGTTCACGGTTTCCGTTGTATGCTAGCGCTGAAGTACCTTCAGCTCGTAGAAAGTACTTATTCCCCTGATACGCTCGGGTACGATCTAATCCGGGACCTGATTTCGGTTATCAGGGCCAGAAGCTATGCCGAAGCGACCAGCAGATATCATCATTTCAACTCCAGGCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCGTACAGCAACCGTGCAGCTGTCCCCACTGTCCGCGTCACAAAAAGGCAGGCCTGGTCGAACAGGCCCATGAACCGCAAGCCCAGGTTTTACAGGATGTACAGGAGTCCGGATGTGCCTAGAGGCTGTGAAGGCCCATGTAAGGTTCAGTCATTTGAGTCCAGGCACGATGTCGTGCATATAGGTAAGGTCATGTGCATCTCCGATGTCACTCGAGGTACCGGTCTTACTCATCGCGTGGGTAAGAGGTTTTGCGTCAAGTCAGTCTACATTCTGGGCAAGATTTGGATGGATGAGAACATAAAGACTAAGAATCACACCAATAGTGTGATGTTTTTCCTCGTCAGGGATCGTAGGCCTGTGGATAAGCCCCAGGACTTCGGGGAAGTCTTCAACATGTTCGATAATGAGCCCAGTACTGCAACTGTTAAAAACATGCATCGTGATCGCTACCAAGTGCTCAGGAAGTGGAGTGCTACGGTGACTGGTGGTCAGTACGCAAGCAAGGAGCAGGCTTTAGTTAGGCGTTTTTTTAGGGTCAATAATTATGTAATTTACAACCAGCAAGAGGCTGGCAAATATGAGAATCACGCTGAGAATGCGTTGATGCTCTACATGGCGTGTACTCACGCCTCCAACCCCGTGTATGCTACGCTCAAGATACGAATCTATTTTTATGACTCTGTATCAAATTAATAAACATTAATTTTTATTATACTGGCTTGCTCGATCCTGACAGTTTTTGTTAATACATTGTACATTACATGTTCTACAGCATTTACAACGGTATTTATGGAAATAACCCCTAGCATATCCAGGTATTTAAGTACTTGGTAACTAAATACTCTCAAGAAACGCCCAGCCTGAAGGTGTAGGGTTGTCCAGATCTTGGAATCCATCCACCACTGATGTAGTCCCAACGCTCTCCTCAGGTTGTGGTTGAACCGAATCTGGACGGTTTTTATGTCCCAGGTCATGTTGAACGGCAGGCGGTGGTGGTCTGTGATCTTGAAATAGAGGGGATTTGGAACTTCCCAGATAAACACGCCACTTGTCGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGGGATTCCATGGTTGGGGCAGTTGATGTGGAGATAGTACGAGCAGCCGCAGTTGAGGTCTATCCTCTTGCGCCTGATGGCCCTACTCTTAGCTGCCCTGTGGTTAATCTTGATTGGAACCTGAGTAGAGCGGCTGGTCGATGGTGACGAAGGACGCATTTTTTAATGCCCAAGCCCTTAGTGCCGTATTCTTCGGCTCATCTAGGAACTCTTTATAGCTGGAATTGGGCCCAGGATTGCAGAGGAAGATAGTGGGTATTCCCCCTTTAATTTGAACTGGCTTTCCGTACTTTGTGTTGCTTTGCCAGTCTCTCTGGGCCCCCATGAACTCTTTGAAGTGCTTTAGATAGTGCGGATCTACGTCATCAATGACGTTATACCAGGCATCATTGCTAAAGACTTTGGGACTGAGGTCCAGATGTCCACATAGGTAATTATGTGGACCCAATGCACGAGCCCACATAGTCTTACCTGTCCGACTATCGCCCTCGATTACGATTGACTTCGGTCTCAAAGGCCGCGCAGCGGCAACCAGGACATTTTCATGGTACCATACATCGAGTTCTTCTGGAACTCGATCAAATGTCGATAGACCAAAAGGACTCTCATAGACCGTAATAAGTGTTTTAAAAATTTTATCTAAATTCGCATTCAAATTATGAAACTGCAGGACGTAGTCTTTAGGAGCTAGCTCTCTAAGGATCTTAAGAGCCTCTGACTTACTGCCGCTGTTAATTGCGGCGGCGTATGCATCATTTGCCGACTGTTGACCTCCCCGTGCAGACCTGCCATCGATCTGGAATTCTCCCCATTCCAGAGTATCTCCGTCCTTGTCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTCGGGGATACCAGGTCGAAGAATCTCTTATTCTGGCATTTGAACTTGCCTTCGTACTGGACGAGCACATGCAGATGAGGTTCCCCATTTTCATGAAGTTCTCTGCAGATTTTAATGAATTTAGGGTTTGTAGGTGTTTCTAGGTTTTTAATTTGGGAAAGCGTCTCTTCTTTGGAGAGAGAGCATCTGGGATAAGTGAGGAAATAATTCTTGGCGTTTATAATAAAACGCTTAGGTGTTGACATGAGACCCGATTGACCGCTATTCAATCATTTATCCCCTATATTCGGGTCTCTATATATACATGAGACCCAAATGGCATAAATGGTAATTATGGGAATATAATTTGAATTTGAAAGCGGCCATCCGTATAATATTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508284.1
|
|
Location
|
135-491 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTACTTAAGAAATTCGCAGACTCCGTTCACGGTTTCCGTTGTATGCTAGCGCTGAAGTACCTTCAGCTCGTAGAAAGTACTTATTCCCCTGATACGCTCGGGTACGATCTAATCCGGGACCTGATTTCGGTTATCAGGGCCAGAAGCTATGCCGAAGCGACCAGCAGATATCATCATTTCAACTCCAGGCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCGTACAGCAACCGTGCAGCTGTCCCCACTGTCCGCGTCACAAAAAGGCAGGCCTGGTCGAACAGGCCCATGAACCGCAAGCCCAGGTTTTACAGGATGTACAGGAGTCCGGATGTGCCTAG |
|
Protein Sequence
|
MWDPLLKKFADSVHGFRCMLALKYLQLVESTYSPDTLGYDLIRDLISVIRARSYAEATSRYHHFNSRLESTSPSELRQPVQQPCSCPHCPRHKKAGLVEQAHEPQAQVLQDVQESGCA |
|
NCBI Accession
|
YP_009508285.1
|
|
Location
|
295-1065 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCGAAGCGACCAGCAGATATCATCATTTCAACTCCAGGCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCGTACAGCAACCGTGCAGCTGTCCCCACTGTCCGCGTCACAAAAAGGCAGGCCTGGTCGAACAGGCCCATGAACCGCAAGCCCAGGTTTTACAGGATGTACAGGAGTCCGGATGTGCCTAGAGGCTGTGAAGGCCCATGTAAGGTTCAGTCATTTGAGTCCAGGCACGATGTCGTGCATATAGGTAAGGTCATGTGCATCTCCGATGTCACTCGAGGTACCGGTCTTACTCATCGCGTGGGTAAGAGGTTTTGCGTCAAGTCAGTCTACATTCTGGGCAAGATTTGGATGGATGAGAACATAAAGACTAAGAATCACACCAATAGTGTGATGTTTTTCCTCGTCAGGGATCGTAGGCCTGTGGATAAGCCCCAGGACTTCGGGGAAGTCTTCAACATGTTCGATAATGAGCCCAGTACTGCAACTGTTAAAAACATGCATCGTGATCGCTACCAAGTGCTCAGGAAGTGGAGTGCTACGGTGACTGGTGGTCAGTACGCAAGCAAGGAGCAGGCTTTAGTTAGGCGTTTTTTTAGGGTCAATAATTATGTAATTTACAACCAGCAAGAGGCTGGCAAATATGAGAATCACGCTGAGAATGCGTTGATGCTCTACATGGCGTGTACTCACGCCTCCAACCCCGTGTATGCTACGCTCAAGATACGAATCTATTTTTATGACTCTGTATCAAATTAA |
|
Protein Sequence
|
MPKRPADIIISTPGSKVRRRLNFDSPYSNRAAVPTVRVTKRQAWSNRPMNRKPRFYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYILGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWSATVTGGQYASKEQALVRRFFRVNNYVIYNQQEAGKYENHAENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009508286.1
|
|
Location
|
1062-1466 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGAATCCCGCACAGGGGAACTCATCACTGCAGCTCAGGCGACAAGTGGCGTGTTTATCTGGGAAGTTCCAAATCCCCTCTATTTCAAGATCACAGACCACCACCGCCTGCCGTTCAACATGACCTGGGACATAAAAACCGTCCAGATTCGGTTCAACCACAACCTGAGGAGAGCGTTGGGACTACATCAGTGGTGGATGGATTCCAAGATCTGGACAACCCTACACCTTCAGGCTGGGCGTTTCTTGAGAGTATTTAGTTACCAAGTACTTAAATACCTGGATATGCTAGGGGTTATTTCCATAAATACCGTTGTAAATGCTGTAGAACATGTAATGTACAATGTATTAACAAAAACTGTCAGGATCGAGCAAGCCAGTATAATAAAAATTAATGTTTATTAA |
|
Protein Sequence
|
MESRTGELITAAQATSGVFIWEVPNPLYFKITDHHRLPFNMTWDIKTVQIRFNHNLRRALGLHQWWMDSKIWTTLHLQAGRFLRVFSYQVLKYLDMLGVISINTVVNAVEHVMYNVLTKTVRIEQASIIKINVY |
|
NCBI Accession
|
YP_009508287.1
|
|
Location
|
1207-1614 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGTCCTTCGTCACCATCGACCAGCCGCTCTACTCAGGTTCCAATCAAGATTAACCACAGGGCAGCTAAGAGTAGGGCCATCAGGCGCAAGAGGATAGACCTCAACTGCGGCTGCTCGTACTATCTCCACATCAACTGCCCCAACCATGGAATCCCGCACAGGGGAACTCATCACTGCAGCTCAGGCGACAAGTGGCGTGTTTATCTGGGAAGTTCCAAATCCCCTCTATTTCAAGATCACAGACCACCACCGCCTGCCGTTCAACATGACCTGGGACATAAAAACCGTCCAGATTCGGTTCAACCACAACCTGAGGAGAGCGTTGGGACTACATCAGTGGTGGATGGATTCCAAGATCTGGACAACCCTACACCTTCAGGCTGGGCGTTTCTTGAGAGTATTTAG |
|
Protein Sequence
|
MRPSSPSTSRSTQVPIKINHRAAKSRAIRRKRIDLNCGCSYYLHINCPNHGIPHRGTHHCSSGDKWRVYLGSSKSPLFQDHRPPPPAVQHDLGHKNRPDSVQPQPEESVGTTSVVDGFQDLDNPTPSGWAFLESI |
|
NCBI Accession
|
YP_009508288.1
|
|
Location
|
1559-2602 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGTCAACACCTAAGCGTTTTATTATAAACGCCAAGAATTATTTCCTCACTTATCCCAGATGCTCTCTCTCCAAAGAAGAGACGCTTTCCCAAATTAAAAACCTAGAAACACCTACAAACCCTAAATTCATTAAAATCTGCAGAGAACTTCATGAAAATGGGGAACCTCATCTGCATGTGCTCGTCCAGTACGAAGGCAAGTTCAAATGCCAGAATAAGAGATTCTTCGACCTGGTATCCCCGACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGATACTCTGGAATGGGGAGAATTCCAGATCGATGGCAGGTCTGCACGGGGAGGTCAACAGTCGGCAAATGATGCATACGCCGCCGCAATTAACAGCGGCAGTAAGTCAGAGGCTCTTAAGATCCTTAGAGAGCTAGCTCCTAAAGACTACGTCCTGCAGTTTCATAATTTGAATGCGAATTTAGATAAAATTTTTAAAACACTTATTACGGTCTATGAGAGTCCTTTTGGTCTATCGACATTTGATCGAGTTCCAGAAGAACTCGATGTATGGTACCATGAAAATGTCCTGGTTGCCGCTGCGCGGCCTTTGAGACCGAAGTCAATCGTAATCGAGGGCGATAGTCGGACAGGTAAGACTATGTGGGCTCGTGCATTGGGTCCACATAATTACCTATGTGGACATCTGGACCTCAGTCCCAAAGTCTTTAGCAATGATGCCTGGTATAACGTCATTGATGACGTAGATCCGCACTATCTAAAGCACTTCAAAGAGTTCATGGGGGCCCAGAGAGACTGGCAAAGCAACACAAAGTACGGAAAGCCAGTTCAAATTAAAGGGGGAATACCCACTATCTTCCTCTGCAATCCTGGGCCCAATTCCAGCTATAAAGAGTTCCTAGATGAGCCGAAGAATACGGCACTAAGGGCTTGGGCATTAAAAAATGCGTCCTTCGTCACCATCGACCAGCCGCTCTACTCAGGTTCCAATCAAGATTAA |
|
Protein Sequence
|
MSTPKRFIINAKNYFLTYPRCSLSKEETLSQIKNLETPTNPKFIKICRELHENGEPHLHVLVQYEGKFKCQNKRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDAYAAAINSGSKSEALKILRELAPKDYVLQFHNLNANLDKIFKTLITVYESPFGLSTFDRVPEELDVWYHENVLVAAARPLRPKSIVIEGDSRTGKTMWARALGPHNYLCGHLDLSPKVFSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEPKNTALRAWALKNASFVTIDQPLYSGSNQD |
|
NCBI Accession
|
YP_009508289.1
|
|
Location
|
2143-2445 |
|
Gene Name
|
AC4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCATGTGCTCGTCCAGTACGAAGGCAAGTTCAAATGCCAGAATAAGAGATTCTTCGACCTGGTATCCCCGACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGATACTCTGGAATGGGGAGAATTCCAGATCGATGGCAGGTCTGCACGGGGAGGTCAACAGTCGGCAAATGATGCATACGCCGCCGCAATTAACAGCGGCAGTAAGTCAGAGGCTCTTAAGATCCTTAGAGAGCTAG |
|
Protein Sequence
|
MGNLICMCSSSTKASSNARIRDSSTWYPRPGQHISIQTFRELNPAPTSSPISTRTEILWNGENSRSMAGLHGEVNSRQMMHTPPQLTAAVSQRLLRSLES |