Jatropha leaf curl Gujarat virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029055.1 |
| Isolate |
India |
| Release date |
2018/8/26 |
| Submitter |
Agarwal,P., More,P., Agarwal,P.K. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
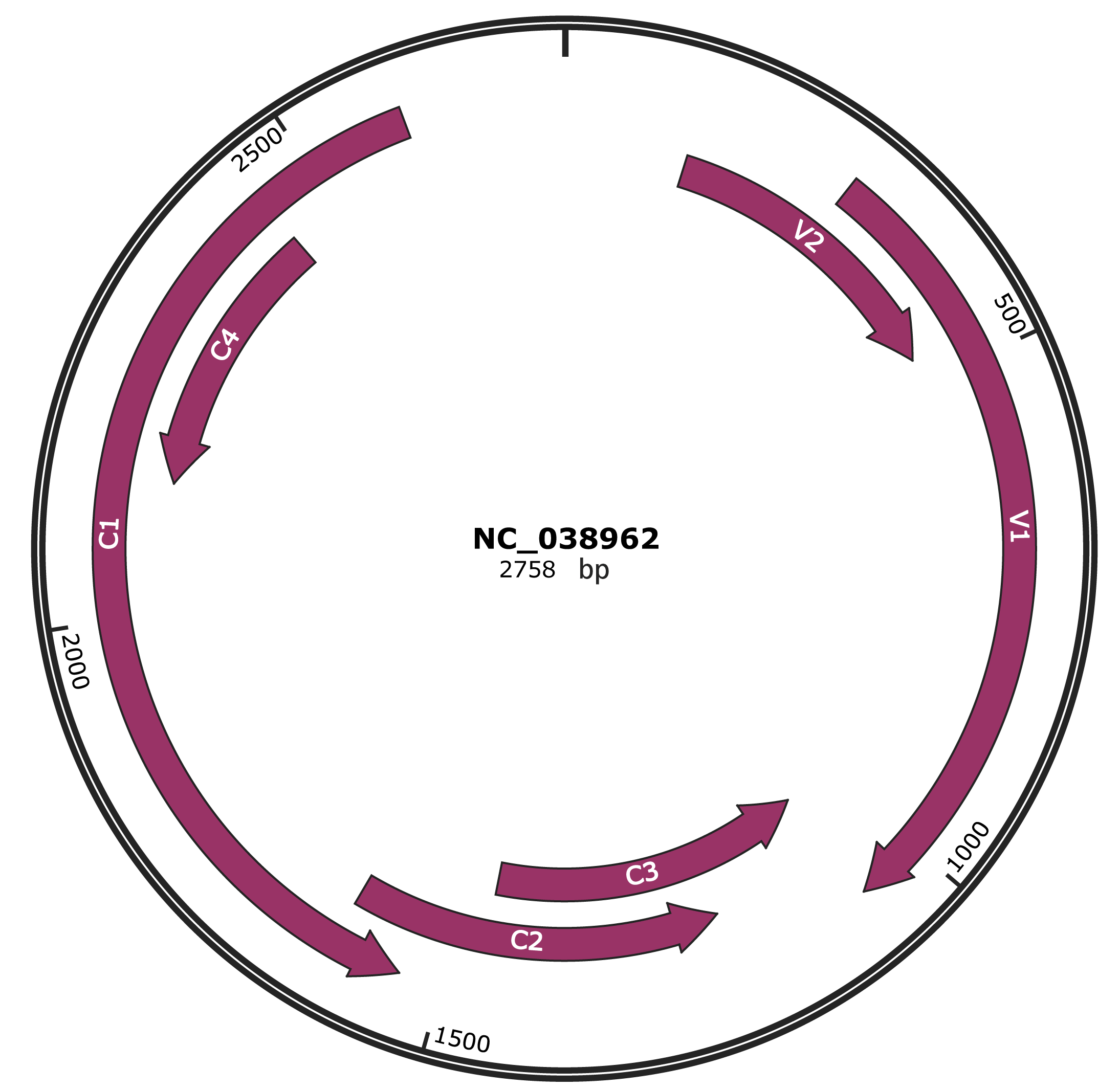
JBrowse
Genome
ACCGGATGGCCGCGCCCCGCTTTGTGGTGGGCCCCCCCACGTGGAGATGTCCCCCTATCAGAACACTCGCTGAAAGCTTTGATATTTGTGGTCCCCCTATAACAACTTGTCGCCCAAGTTGTTCATCTGCACAATGTGGGACCCTCTCCTCAACGAGTTCCCAGATTCCGTCCACGGTTTCCGGTGTATGCTTGCCGTGAAATACCTTCAGTTGGTGGAAGGTACCTATTCTCCTGACACTCTGGGTCACGAGTTAATCAGGGATCTCATATCTGTCATCAGGGCGAAGAATTATGCCGAAGCGACCAGCAGATATCATCATTTCCACACCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATATGCCAGCCGTGCAGCTGCCCCTACTGTCCGCGTCACAAGAAGTCAGGCCTGGACCAACAGGCCCATGAATCGCAAGCCCAAGTGGTACAGGATTTATAGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTTTGAGTCTAGACACGACGTCGTTCATATAGGTAAGGTCATGTGCATCTCAGATGTCACCCGTGGAACAGGGTTCACCCATCGCGTAGGTAAGAGGTTCTGCGTCAAGTCCGTGTACATCCTGGGCAAGATATGGATGGACGAAAACATCAAGACCAAGAACCACACGAACACTGTGATGTTCTTCCTCGTCAGGGATCGTAGGCCCGTGGACAAACCCCAGGATTTTGGTGAGGTGTTCAACATGTTCGATAACGAGCCCAGTACTGCTACGGTTAAAAACATGTACCGTGATCGGTACCAGGTGTTAAGGAAGTGGAGTTCCACTGTCACTGGTGGTCAGTATGCGAGCAAAGAGCAGGCAATAGTTAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAATCAGCAAGAGGCTGGTAAGTACGAAAACCATACGGAGAATGCATTGATGCTGTACATGGCGTGTACTCACGCCTCTAACCCCGTGTATGCTACGCTTAAGATACGGATCTACTTCTACGATTCAGTATCCAATTAATAAATTTTAAATTTTATTAAATTTGACTGCTCAACTGATTCAGTCCCTGTGAGTACACTGTACAATACATGCTCTACGGCTCTAACGACCGTATTTATACATATGACCCCTAACATGTCCAGGTATCTGAGTACCTGGTACCTAAAAACCCTCAAGAAACGCAAGGTCTGAGGCCGTAAGGTCGTCCAGATTTTGAAATCCATCCAGCATTGATGTAGTCCCAACGCTTTCCTCAGGTTGTGGTTGAACCGTATCTGGACGGTTATTATGTCGTGTTCCATCAGGAACGGCCGGCTGCTGTGGTCTATGATCTTGAAATAGAGGGGATTTGGAACCTCCCAGGTATAGACGCCATTCATCGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTGATGTGCACGTAGTACGAGCACCCGCAGTTGAGGTCTACTCTCCGTCGCCGGATGGCCCTACGCTTAGCTGCCCTGTGTTGAACCTTGATCGGCACTGGAGTAGAGTGGCCCGTCGAGGGAGATGAAGGTCGCATTTCTTATTGCCCAAGCCTTCAATGCCGTATTCTTCGGCTCGTCAAGGAACTCTTTATAGCTGGAATTGGGCCCAGGATTGCACAGGAAGATAGTGGGTATCCCACCTTTAATTTGAACCGGCTTTCCGTATTTGGTGTTGCTTTGCCAGTCCCTCTGGGCCCCCATGAATTCCTTGAAGTGCTTTAGGTAGTGGGGATCTACGTCATCAATGACGTTGTACCACGCGTCGTTTCTGTAGACCCTAGGACTCAAGTCCAGATGGCCACATAGGTAGTTATGTGGACCCAATGACCTAGCCCACATCGTCTTCCCCGTCCGACTATCGCCCTCTATGACAATACTATTAGGTCTCAAAGGCCGCGCAGCTGCATCCATGACGTTCTCTGACACCCACTGCTCAAGTTCATCTGGAACTTGGTCAAATGAAGATGATGAGAAGGGAGAAACGTACACCTCGGCGGGAGGTGTAAAAATCTTGTCCAGATTTGAGCTGATGTTATGGAAGTCCCTGACATAATCCCTAGGTGCTAATTCCCTAAGGATCCTAAGAGCCTCTGACTTACTTCCGCTGTTAATTGCTGCGGCGTAAGCGTCGTTCGCAGTCTGTTGACCCCCCCGTGCAGATCGCCCGTCGATCTGGAATGTGCCCCATTCAAGGGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCGCTGATTCTGGCATTTGTATTTTCCGTTGAATTGGATGAGCACATGCAGATGAGGCTCCCCATTCTCGTGTATCTCTCGGCAGATTTTGATGAATTTAGGGCTAGTGGGCGTTTGAAGCCCCCTAATTTGGGAAAGAGCCTCTTCTTTAGTGAGAGAGCACCGAGGATATGTGAGGAAATAATTCTTAGCGTTTATAATAAAACGCTTGGGTGGAGACATTTTCTCTCTCCTGAGACCCAATTGGTGCCTCTTCCATTTACTCCTGTAATCGGGTATAAGGTCTCAATATATATGATGATACCCAAATGGCACGGAGTGTAAATATGTGGAATATAATTTGAATTTCAAATTGACACGCGGCCATCCTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508299.1
|
|
Location
|
134-472 |
|
Gene Name
|
V2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGACCCTCTCCTCAACGAGTTCCCAGATTCCGTCCACGGTTTCCGGTGTATGCTTGCCGTGAAATACCTTCAGTTGGTGGAAGGTACCTATTCTCCTGACACTCTGGGTCACGAGTTAATCAGGGATCTCATATCTGTCATCAGGGCGAAGAATTATGCCGAAGCGACCAGCAGATATCATCATTTCCACACCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATATGCCAGCCGTGCAGCTGCCCCTACTGTCCGCGTCACAAGAAGTCAGGCCTGGACCAACAGGCCCATGAATCGCAAGCCCAAGTGGTACAGGATTTATAG |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLAVKYLQLVEGTYSPDTLGHELIRDLISVIRAKNYAEATSRYHHFHTRLEGSSPSELRQPICQPCSCPYCPRHKKSGLDQQAHESQAQVVQDL |
|
NCBI Accession
|
YP_009508300.1
|
|
Location
|
294-1064 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCGAAGCGACCAGCAGATATCATCATTTCCACACCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATATGCCAGCCGTGCAGCTGCCCCTACTGTCCGCGTCACAAGAAGTCAGGCCTGGACCAACAGGCCCATGAATCGCAAGCCCAAGTGGTACAGGATTTATAGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTTTGAGTCTAGACACGACGTCGTTCATATAGGTAAGGTCATGTGCATCTCAGATGTCACCCGTGGAACAGGGTTCACCCATCGCGTAGGTAAGAGGTTCTGCGTCAAGTCCGTGTACATCCTGGGCAAGATATGGATGGACGAAAACATCAAGACCAAGAACCACACGAACACTGTGATGTTCTTCCTCGTCAGGGATCGTAGGCCCGTGGACAAACCCCAGGATTTTGGTGAGGTGTTCAACATGTTCGATAACGAGCCCAGTACTGCTACGGTTAAAAACATGTACCGTGATCGGTACCAGGTGTTAAGGAAGTGGAGTTCCACTGTCACTGGTGGTCAGTATGCGAGCAAAGAGCAGGCAATAGTTAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAATCAGCAAGAGGCTGGTAAGTACGAAAACCATACGGAGAATGCATTGATGCTGTACATGGCGTGTACTCACGCCTCTAACCCCGTGTATGCTACGCTTAAGATACGGATCTACTTCTACGATTCAGTATCCAATTAA |
|
Protein Sequence
|
MPKRPADIIISTPGSKVRRRLNFDSPYASRAAAPTVRVTRSQAWTNRPMNRKPKWYRIYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGFTHRVGKRFCVKSVYILGKIWMDENIKTKNHTNTVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMYRDRYQVLRKWSSTVTGGQYASKEQAIVRRFFRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009508301.1
|
|
Location
|
1061-1465 |
|
Gene Name
|
C3 |
|
Protein Name
|
AL3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATAGACCACAGCAGCCGGCCGTTCCTGATGGAACACGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAAATCTGGACGACCTTACGGCCTCAGACCTTGCGTTTCTTGAGGGTTTTTAGGTACCAGGTACTCAGATACCTGGACATGTTAGGGGTCATATGTATAAATACGGTCGTTAGAGCCGTAGAGCATGTATTGTACAGTGTACTCACAGGGACTGAATCAGTTGAGCAGTCAAATTTAATAAAATTTAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAMNGVYTWEVPNPLYFKIIDHSSRPFLMEHDIITVQIRFNHNLRKALGLHQCWMDFKIWTTLRPQTLRFLRVFRYQVLRYLDMLGVICINTVVRAVEHVLYSVLTGTESVEQSNLIKFKIY |
|
NCBI Accession
|
YP_009508302.1
|
|
Location
|
1206-1613 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGCGACCTTCATCTCCCTCGACGGGCCACTCTACTCCAGTGCCGATCAAGGTTCAACACAGGGCAGCTAAGCGTAGGGCCATCCGGCGACGGAGAGTAGACCTCAACTGCGGGTGCTCGTACTACGTGCACATCAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATAGACCACAGCAGCCGGCCGTTCCTGATGGAACACGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAAATCTGGACGACCTTACGGCCTCAGACCTTGCGTTTCTTGAGGGTTTTTAG |
|
Protein Sequence
|
MRPSSPSTGHSTPVPIKVQHRAAKRRAIRRRRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGDEWRLYLGGSKSPLFQDHRPQQPAVPDGTRHNNRPDTVQPQPEESVGTTSMLDGFQNLDDLTASDLAFLEGF |
|
NCBI Accession
|
YP_009508303.1
|
|
Location
|
1543-2601 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGTCTCCACCCAAGCGTTTTATTATAAACGCTAAGAATTATTTCCTCACATATCCTCGGTGCTCTCTCACTAAAGAAGAGGCTCTTTCCCAAATTAGGGGGCTTCAAACGCCCACTAGCCCTAAATTCATCAAAATCTGCCGAGAGATACACGAGAATGGGGAGCCTCATCTGCATGTGCTCATCCAATTCAACGGAAAATACAAATGCCAGAATCAGCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACCCTTGAATGGGGCACATTCCAGATCGACGGGCGATCTGCACGGGGGGGTCAACAGACTGCGAACGACGCTTACGCCGCAGCAATTAACAGCGGAAGTAAGTCAGAGGCTCTTAGGATCCTTAGGGAATTAGCACCTAGGGATTATGTCAGGGACTTCCATAACATCAGCTCAAATCTGGACAAGATTTTTACACCTCCCGCCGAGGTGTACGTTTCTCCCTTCTCATCATCTTCATTTGACCAAGTTCCAGATGAACTTGAGCAGTGGGTGTCAGAGAACGTCATGGATGCAGCTGCGCGGCCTTTGAGACCTAATAGTATTGTCATAGAGGGCGATAGTCGGACGGGGAAGACGATGTGGGCTAGGTCATTGGGTCCACATAACTACCTATGTGGCCATCTGGACTTGAGTCCTAGGGTCTACAGAAACGACGCGTGGTACAACGTCATTGATGACGTAGATCCCCACTACCTAAAGCACTTCAAGGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACCAAATACGGAAAGCCGGTTCAAATTAAAGGTGGGATACCCACTATCTTCCTGTGCAATCCTGGGCCCAATTCCAGCTATAAAGAGTTCCTTGACGAGCCGAAGAATACGGCATTGAAGGCTTGGGCAATAAGAAATGCGACCTTCATCTCCCTCGACGGGCCACTCTACTCCAGTGCCGATCAAGGTTCAACACAGGGCAGCTAA |
|
Protein Sequence
|
MSPPKRFIINAKNYFLTYPRCSLTKEEALSQIRGLQTPTSPKFIKICREIHENGEPHLHVLIQFNGKYKCQNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGTFQIDGRSARGGQQTANDAYAAAINSGSKSEALRILRELAPRDYVRDFHNISSNLDKIFTPPAEVYVSPFSSSSFDQVPDELEQWVSENVMDAAARPLRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYRNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEPKNTALKAWAIRNATFISLDGPLYSSADQGSTQGS |
|
NCBI Accession
|
YP_009508304.1
|
|
Location
|
2142-2444 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTGCATGTGCTCATCCAATTCAACGGAAAATACAAATGCCAGAATCAGCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACCCTTGAATGGGGCACATTCCAGATCGACGGGCGATCTGCACGGGGGGGTCAACAGACTGCGAACGACGCTTACGCCGCAGCAATTAACAGCGGAAGTAAGTCAGAGGCTCTTAGGATCCTTAGGGAATTAG |
|
Protein Sequence
|
MGSLICMCSSNSTENTNARISDSSTWYPQPGQHISIRTYRELNPAPTSSPTSTRTEIPLNGAHSRSTGDLHGGVNRLRTTLTPQQLTAEVSQRLLGSLGN |